 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculative Speech Recognition by Audio-Prefixed Low-Rank Adaptation of Language Models
Jul 05, 2024



This paper explores speculative speech recognition (SSR), where we empower conventional automatic speech recognition (ASR) with speculation capabilities, allowing the recognizer to run ahead of audio. We introduce a metric for measuring SSR performance and we propose a model which does SSR by combining a RNN-Transducer-based ASR system with an audio-prefixed language model (LM). The ASR system transcribes ongoing audio and feeds the resulting transcripts, along with an audio-dependent prefix, to the LM, which speculates likely completions for the transcriptions. We experiment with a variety of ASR datasets on which show the efficacy our method and the feasibility of SSR as a method of reducing ASR latency.
Speech Prefix-Tuning with RNNT Loss for Improving LLM Predictions
Jun 20, 2024



In this paper, we focus on addressing the constraints faced when applying LLMs to ASR. Recent works utilize prefixLM-type models, which directly apply speech as a prefix to LLMs for ASR. We have found that optimizing speech prefixes leads to better ASR performance and propose applying RNNT loss to perform speech prefix-tuning. This is a simple approach and does not increase the model complexity or alter the inference pipeline. We also propose language-based soft prompting to further improve with frozen LLMs. Empirical analysis on realtime testset from 10 Indic languages demonstrate that our proposed speech prefix-tuning yields improvements with both frozen and fine-tuned LLMs. Our recognition results on an average of 10 Indics show that the proposed prefix-tuning with RNNT loss results in a 12\% relative improvement in WER over the baseline with a fine-tuned LLM. Our proposed approches with the frozen LLM leads to a 31\% relative improvement over basic soft-prompting prefixLM.
O-1: Self-training with Oracle and 1-best Hypothesis
Aug 14, 2023



We introduce O-1, a new self-training objective to reduce training bias and unify training and evaluation metrics for speech recognition. O-1 is a faster variant of Expected Minimum Bayes Risk (EMBR), that boosts the oracle hypothesis and can accommodate both supervised and unsupervised data. We demonstrate the effectiveness of our approach in terms of recognition on publicly available SpeechStew datasets and a large-scale, in-house data set. On Speechstew, the O-1 objective closes the gap between the actual and oracle performance by 80\% relative compared to EMBR which bridges the gap by 43\% relative. O-1 achieves 13\% to 25\% relative improvement over EMBR on the various datasets that SpeechStew comprises of, and a 12\% relative gap reduction with respect to the oracle WER over EMBR training on the in-house dataset. Overall, O-1 results in a 9\% relative improvement in WER over EMBR, thereby speaking to the scalability of the proposed objective for large-scale datasets.
Robust Knowledge Distillation from RNN-T Models With Noisy Training Labels Using Full-Sum Loss
Mar 10, 2023This work studies knowledge distillation (KD) and addresses its constraints for recurrent neural network transducer (RNN-T) models. In hard distillation, a teacher model transcribes large amounts of unlabelled speech to train a student model. Soft distillation is another popular KD method that distills the output logits of the teacher model. Due to the nature of RNN-T alignments, applying soft distillation between RNN-T architectures having different posterior distributions is challenging. In addition, bad teachers having high word-error-rate (WER) reduce the efficacy of KD. We investigate how to effectively distill knowledge from variable quality ASR teachers, which has not been studied before to the best of our knowledge. We show that a sequence-level KD, full-sum distillation, outperforms other distillation methods for RNN-T models, especially for bad teachers. We also propose a variant of full-sum distillation that distills the sequence discriminative knowledge of the teacher leading to further improvement in WER. We conduct experiments on public datasets namely SpeechStew and LibriSpeech, and on in-house production data.
Speaker adaptation for Wav2vec2 based dysarthric ASR
Apr 02, 2022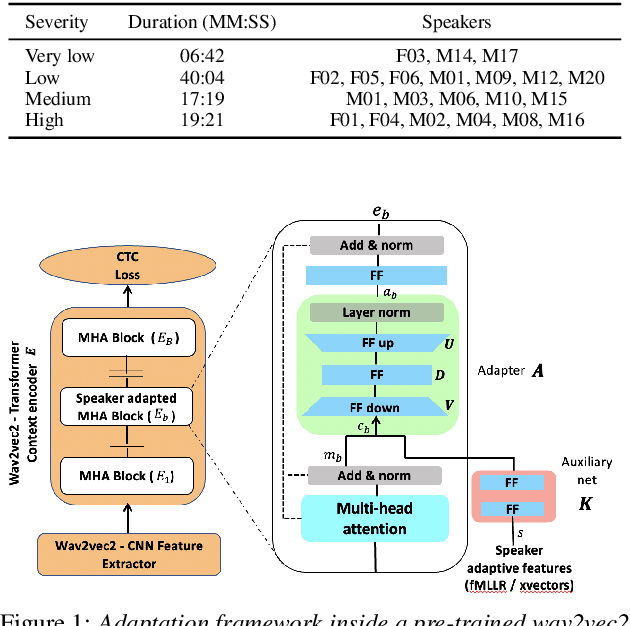
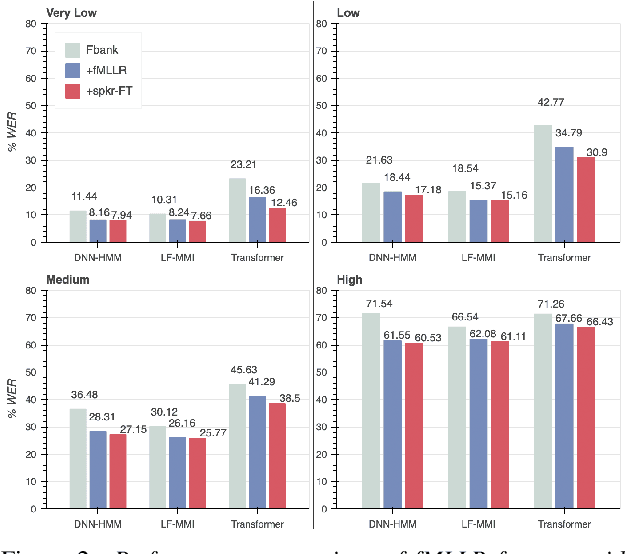
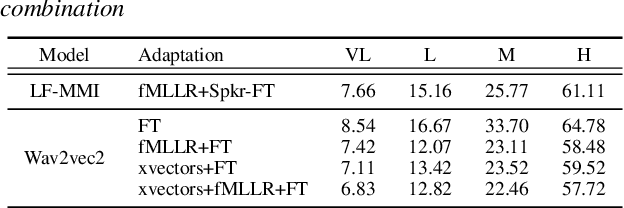
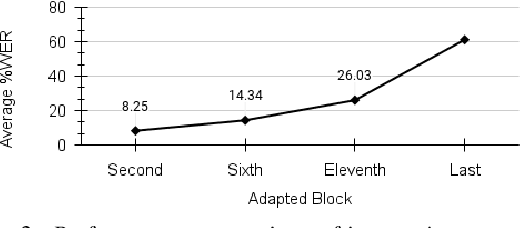
Dysarthric speech recognition has posed major challenges due to lack of training data and heavy mismatch in speaker characteristics. Recent ASR systems have benefited from readily available pretrained models such as wav2vec2 to improve the recognition performance. Speaker adaptation using fMLLR and xvectors have provided major gains for dysarthric speech with very little adaptation data. However, integration of wav2vec2 with fMLLR features or xvectors during wav2vec2 finetuning is yet to be explored. In this work, we propose a simple adaptation network for fine-tuning wav2vec2 using fMLLR features. The adaptation network is also flexible to handle other speaker adaptive features such as xvectors. Experimental analysis show steady improvements using our proposed approach across all impairment severity levels and attains 57.72\% WER for high severity in UASpeech dataset. We also performed experiments on German dataset to substantiate the consistency of our proposed approach across diverse domains.
Ask2Mask: Guided Data Selection for Masked Speech Modeling
Feb 24, 2022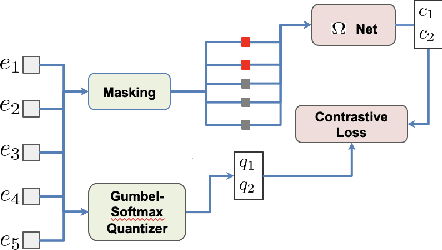
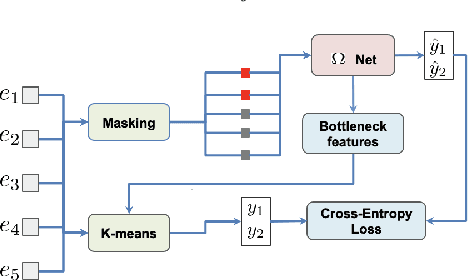
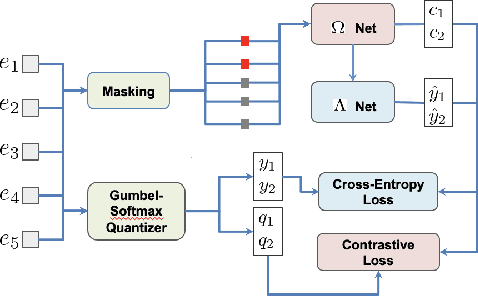
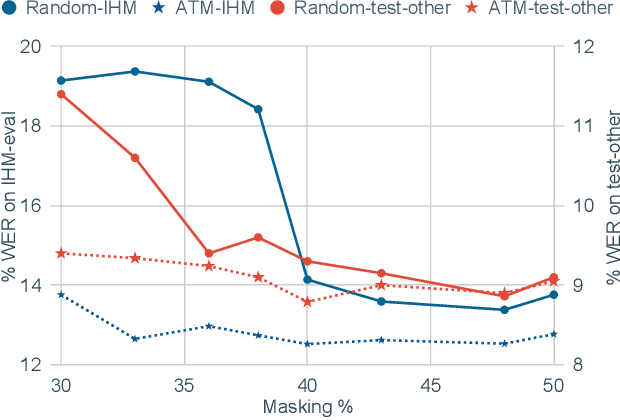
Masked speech modeling (MSM) methods such as wav2vec2 or w2v-BERT learn representations over speech frames which are randomly masked within an utterance. While these methods improve performance of Automatic Speech Recognition (ASR) systems, they have one major limitation. They treat all unsupervised speech samples with equal weight, which hinders learning as not all samples have relevant information to learn meaningful representations. In this work, we address this limitation. We propose ask2mask (ATM), a novel approach to focus on specific samples during MSM pre-training. ATM employs an external ASR model or \textit{scorer} to weight unsupervised input samples in two different ways: 1) A fine-grained data selection is performed by masking over the highly confident input frames as chosen by the scorer. This allows the model to learn meaningful representations. 2) ATM is further extended to focus at utterance-level by weighting the final MSM loss with the utterance-level confidence score. We conduct fine-tuning experiments on two well-benchmarked corpora: LibriSpeech (matching the pre-training data) and Commonvoice, TED-LIUM, AMI and CHiME-6 (not matching the pre-training data). The results substantiate the efficacy of ATM on significantly improving the recognition performance under mismatched conditions (up to 11.6\% relative over published results and upto 4.46\% relative over our internal baseline) while still yielding modest improvements under matched conditions.
EAT: Enhanced ASR-TTS for Self-supervised Speech Recognition
Apr 13, 2021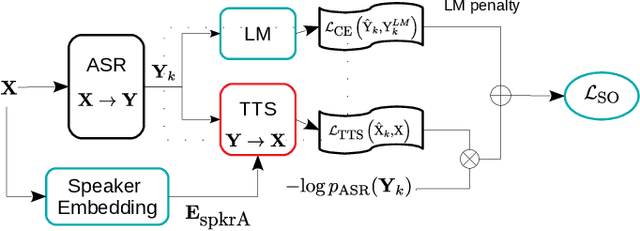
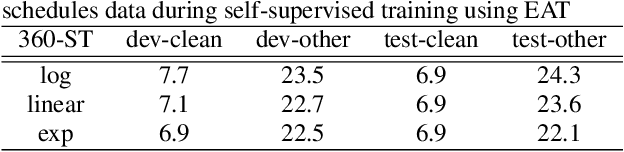
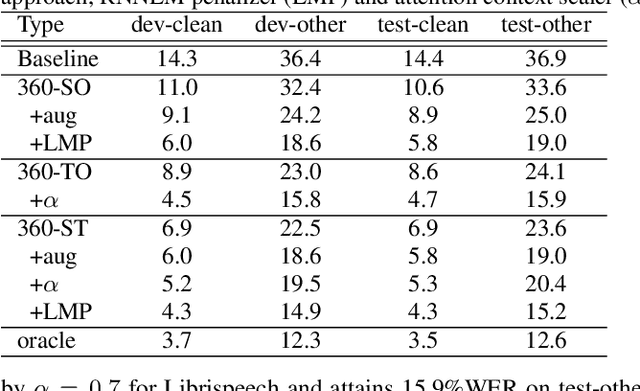
Self-supervised ASR-TTS models suffer in out-of-domain data conditions. Here we propose an enhanced ASR-TTS (EAT) model that incorporates two main features: 1) The ASR$\rightarrow$TTS direction is equipped with a language model reward to penalize the ASR hypotheses before forwarding it to TTS. 2) In the TTS$\rightarrow$ASR direction, a hyper-parameter is introduced to scale the attention context from synthesized speech before sending it to ASR to handle out-of-domain data. Training strategies and the effectiveness of the EAT model are explored under out-of-domain data conditions. The results show that EAT reduces the performance gap between supervised and self-supervised training significantly by absolute 2.6\% and 2.7\% on Librispeech and BABEL respectively.
BUT Opensat 2019 Speech Recognition System
Jan 30, 2020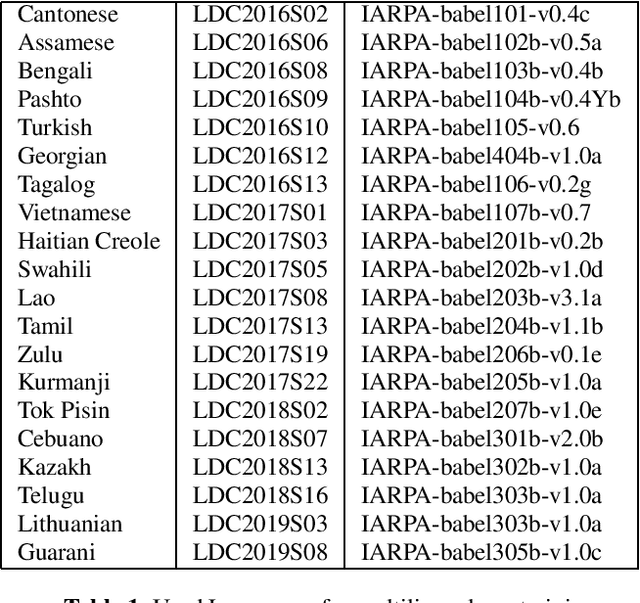
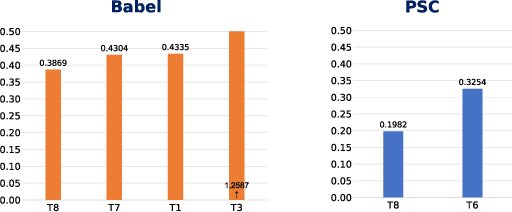


The paper describes the BUT Automatic Speech Recognition (ASR) systems submitted for OpenSAT evaluations under two domain categories such as low resourced languages and public safety communications. The first was challenging due to lack of training data, therefore various architectures and multilingual approaches were employed. The combination led to superior performance. The second domain was challenging due to recording in extreme conditions such as specific channel, speaker under stress and high levels of noise. Data augmentation process was inevitable to get reasonably good performance.
Self-supervised Sequence-to-sequence ASR using Unpaired Speech and Text
Apr 30, 2019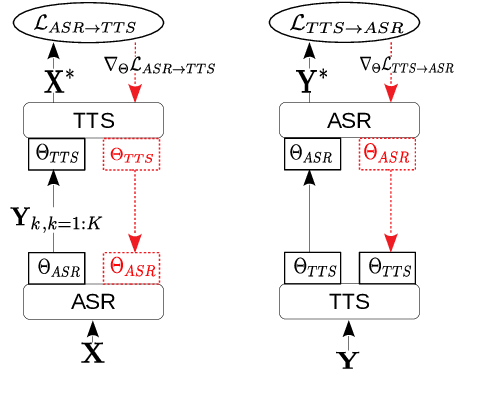
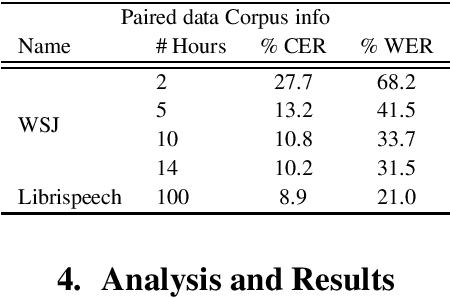
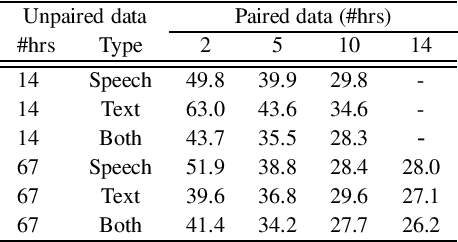
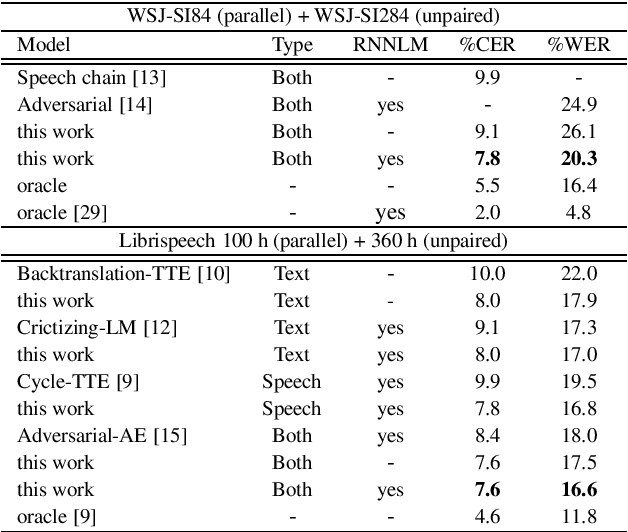
Sequence-to-sequence ASR models require large quantities of data to attain high performance. For this reason, there has been a recent surge in interest for self-supervised and supervised training in such models. This work builds upon recent results showing notable improvements in self-supervised training using cycle-consistency and related techniques. Such techniques derive training procedures and losses able to leverage unpaired speech and/or text data by combining ASR with text-to-speech (TTS) models. In particular, this work proposes a new self-supervised loss combining an end-to-end differentiable ASR$\rightarrow$TTS loss with a point estimate TTS$\rightarrow$ASR loss. The method is able to leverage both unpaired speech and text data to outperform recently proposed related techniques in terms of \%WER. We provide extensive results analyzing the impact of data quantity and speech and text modalities and show consistent gains across WSJ and Librispeech corpora. Our code is provided to reproduce the experiments.
Analysis of Multilingual Sequence-to-Sequence speech recognition systems
Nov 07, 2018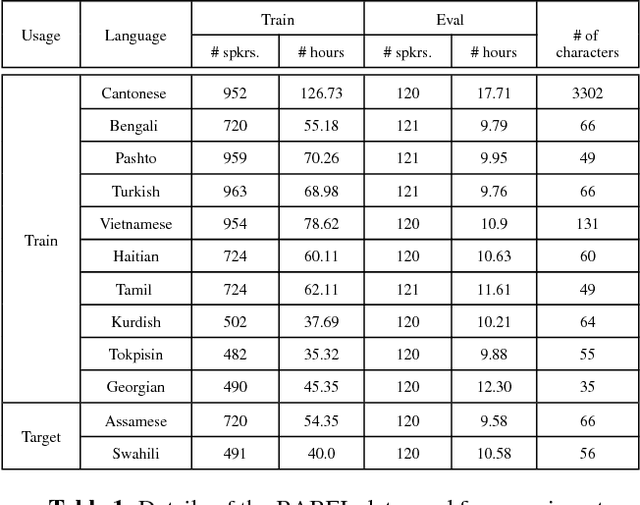
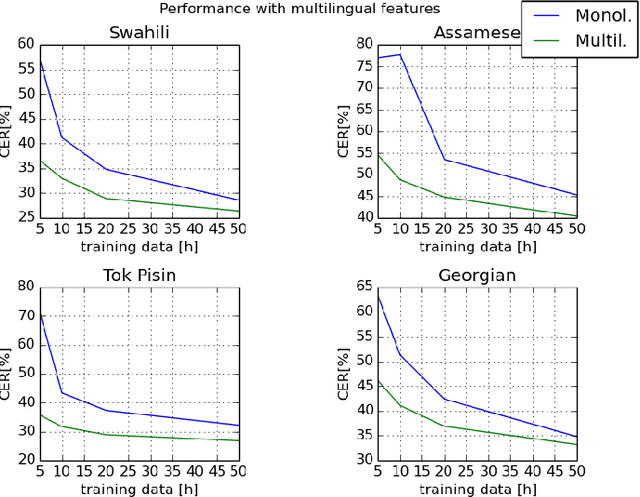
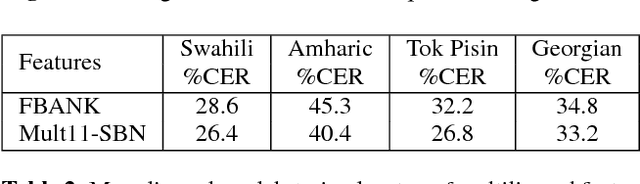
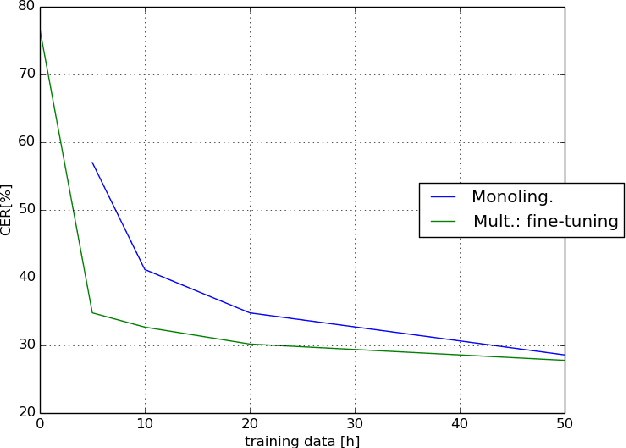
This paper investigates the applications of various multilingual approaches developed in conventional hidden Markov model (HMM) systems to sequence-to-sequence (seq2seq) automatic speech recognition (ASR). On a set composed of Babel data, we first show the effectiveness of multi-lingual training with stacked bottle-neck (SBN) features. Then we explore various architectures and training strategies of multi-lingual seq2seq models based on CTC-attention networks including combinations of output layer, CTC and/or attention component re-training. We also investigate the effectiveness of language-transfer learning in a very low resource scenario when the target language is not included in the original multi-lingual training data. Interestingly, we found multilingual features superior to multilingual models, and this finding suggests that we can efficiently combine the benefits of the HMM system with the seq2seq system through these multilingual feature techniques.