 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReady from Day 1: Population-Aware Coordination for Large-Scale Constrained Multi-Agent Systems
May 12, 2026In large-scale multi-agent systems with shared resource constraints, an upstream planner must iteratively evaluate candidate resource plans -- assessing feasibility, aggregate response, and marginal cost -- before committing to one. Lagrangian relaxation separates local decisions through a broadcast cost signal, but the planner still needs the cost-to-utilization response map to explore plan space, and this map depends on population composition that changes across planning cycles. We propose \emph{population-aware coordination interfaces}: learned primal and dual maps, conditioned on compact population summaries, that the planner queries inside its iterative loop. The primal map predicts aggregate utilization under a proposed cost trajectory; the dual map predicts the cost trajectory for a target plan. By encoding response-relevant population structure, these maps remain reliable across evolving populations without per-cycle retraining, and support coordination of large populations from compact subsamples. We additionally cast Sim2Real transfer as a backtestable procedure, enabling evaluation before deployment. In a supply-chain capacity-control case study, population-aware interfaces reduce forecast error by 16--19\% and capacity violations by 20--51\% relative to population-unaware baselines under composition shift; 20K-agent cohorts support accurate coordination of 500K-agent populations; and simulator-trained primal maps achieve 11.1\% MAPE on real observations versus 13--24\% for baselines.
Structure-Informed Deep Reinforcement Learning for Inventory Management
Jul 29, 2025


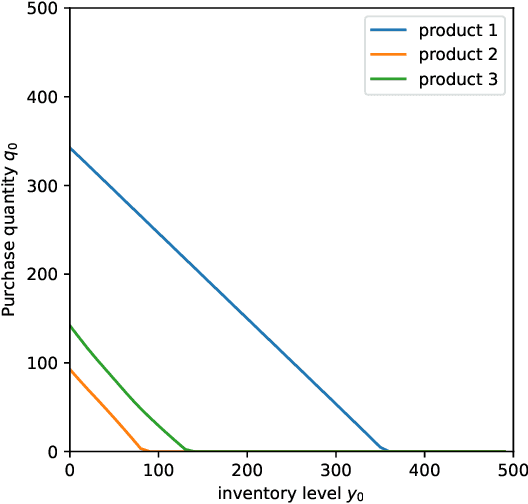
This paper investigates the application of Deep Reinforcement Learning (DRL) to classical inventory management problems, with a focus on practical implementation considerations. We apply a DRL algorithm based on DirectBackprop to several fundamental inventory management scenarios including multi-period systems with lost sales (with and without lead times), perishable inventory management, dual sourcing, and joint inventory procurement and removal. The DRL approach learns policies across products using only historical information that would be available in practice, avoiding unrealistic assumptions about demand distributions or access to distribution parameters. We demonstrate that our generic DRL implementation performs competitively against or outperforms established benchmarks and heuristics across these diverse settings, while requiring minimal parameter tuning. Through examination of the learned policies, we show that the DRL approach naturally captures many known structural properties of optimal policies derived from traditional operations research methods. To further improve policy performance and interpretability, we propose a Structure-Informed Policy Network technique that explicitly incorporates analytically-derived characteristics of optimal policies into the learning process. This approach can help interpretability and add robustness to the policy in out-of-sample performance, as we demonstrate in an example with realistic demand data. Finally, we provide an illustrative application of DRL in a non-stationary setting. Our work bridges the gap between data-driven learning and analytical insights in inventory management while maintaining practical applicability.
ORL: Reinforcement Learning Benchmarks for Online Stochastic Optimization Problems
Dec 01, 2019
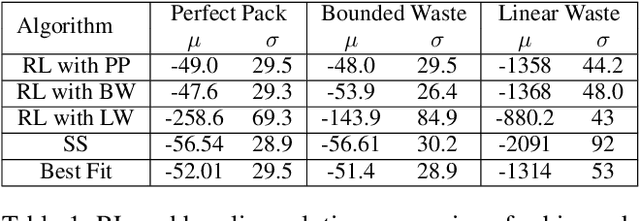
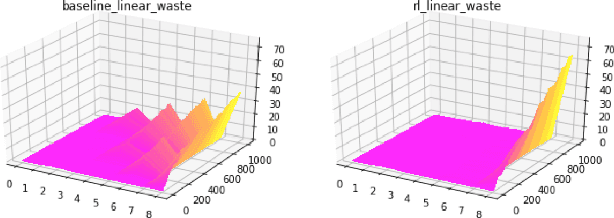
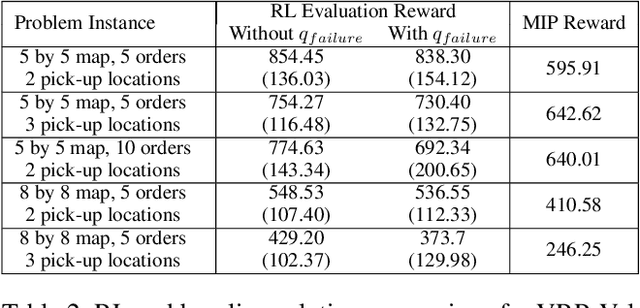
Reinforcement Learning (RL) has achieved state-of-the-art results in domains such as robotics and games. We build on this previous work by applying RL algorithms to a selection of canonical online stochastic optimization problems with a range of practical applications: Bin Packing, Newsvendor, and Vehicle Routing. While there is a nascent literature that applies RL to these problems, there are no commonly accepted benchmarks which can be used to compare proposed approaches rigorously in terms of performance, scale, or generalizability. This paper aims to fill that gap. For each problem we apply both standard approaches as well as newer RL algorithms and analyze results. In each case, the performance of the trained RL policy is competitive with or superior to the corresponding baselines, while not requiring much in the way of domain knowledge. This highlights the potential of RL in real-world dynamic resource allocation problems.