 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine-Learning Driven Load Shedding to Mitigate Instability Attacks in Power Grids
Sep 30, 2025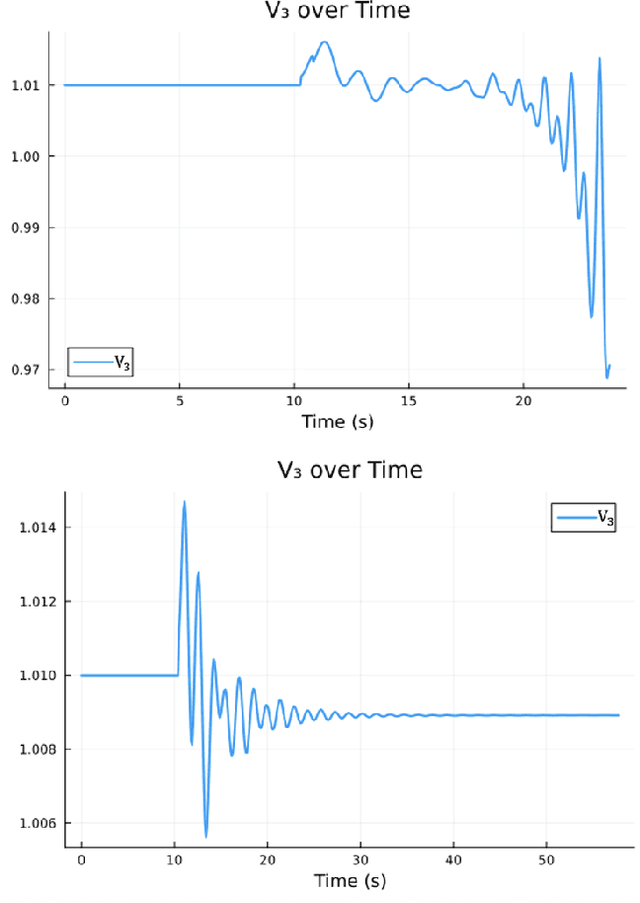
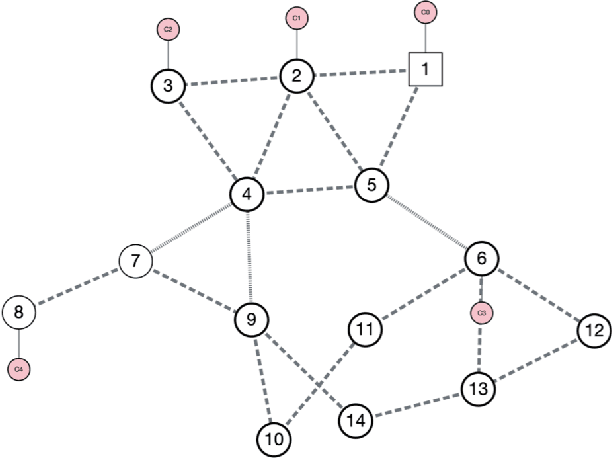
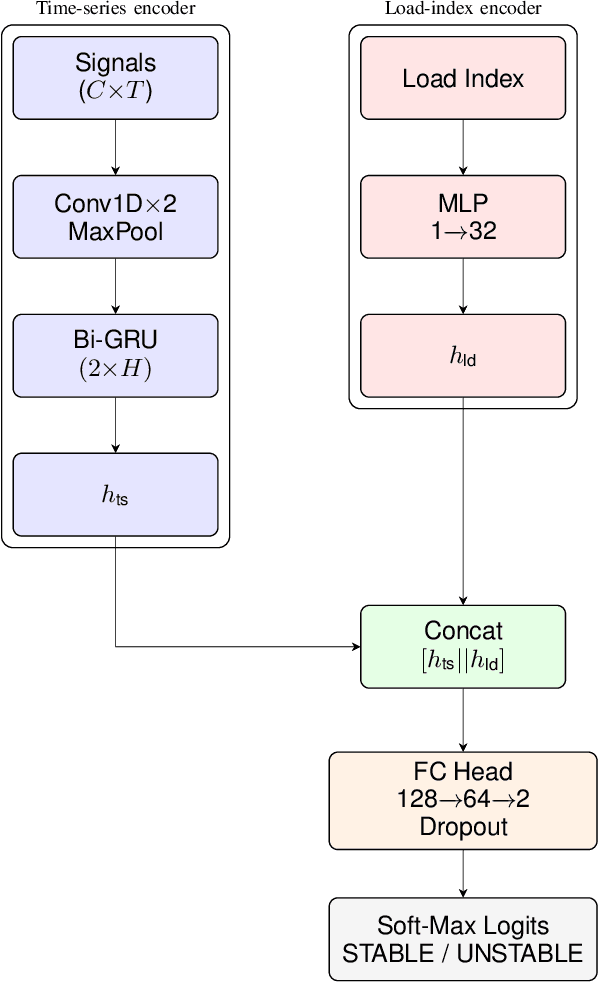
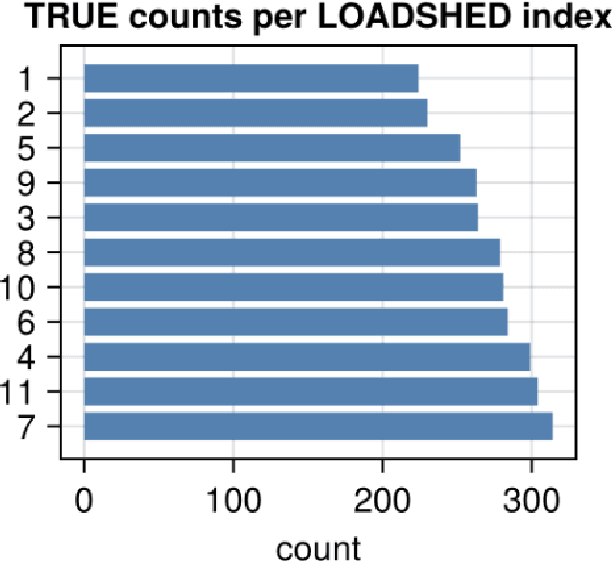
Every year critical infrastructure becomes more complex and we grow to rely on it more and more. With this reliance, it becomes an attractive target for cyberattacks from sophisticated actors, with one of the most attractive targets being the power grid. One class of attacks, instability attacks, is a newer type of attack that has relatively few protections developed. We present a cost effective, data-driven approach to training a supervised machine learning model to retrofit load shedding decision systems in power grids with the capacity to defend against instability attacks. We show a proof of concept on the IEEE 14 Bus System using the Achilles Heel Technologies Power Grid Analyzer, and show through an implementation of modified Prony analysis (MPA) that MPA is a viable method for detecting instability attacks and triggering defense mechanisms.
Hatching-Box: Monitoring the Rearing Process of Drosophila Using an Embedded Imaging and in-vial Detection System
Nov 23, 2024



In this paper we propose the Hatching-Box, a novel imaging and analysis system to automatically monitor and quantify the developmental behavior of Drosophila in standard rearing vials and during regular rearing routines, rendering explicit experiments obsolete. This is achieved by combining custom tailored imaging hardware with dedicated detection and tracking algorithms, enabling the quantification of larvae, filled/empty pupae and flies over multiple days. Given the affordable and reproducible design of the Hatching-Box in combination with our generic client/server-based software, the system can easily be scaled to monitor an arbitrary amount of rearing vials simultaneously. We evaluated our system on a curated image dataset comprising nearly 470,000 annotated objects and performed several studies on real world experiments. We successfully reproduced results from well-established circadian experiments by comparing the eclosion periods of wild type flies to the clock mutants $\textit{per}^{short}$, $\textit{per}^{long}$ and $\textit{per}^0$ without involvement of any manual labor. Furthermore we show, that the Hatching-Box is able to extract additional information about group behavior as well as to reconstruct the whole life-cycle of the individual specimens. These results not only demonstrate the applicability of our system for long-term experiments but also indicate its benefits for automated monitoring in the general cultivation process.
Lost in Tracking Translation: A Comprehensive Analysis of Visual SLAM in Human-Centered XR and IoT Ecosystems
Nov 11, 2024



Advancements in tracking algorithms have empowered nascent applications across various domains, from steering autonomous vehicles to guiding robots to enhancing augmented reality experiences for users. However, these algorithms are application-specific and do not work across applications with different types of motion; even a tracking algorithm designed for a given application does not work in scenarios deviating from highly standard conditions. For example, a tracking algorithm designed for robot navigation inside a building will not work for tracking the same robot in an outdoor environment. To demonstrate this problem, we evaluate the performance of the state-of-the-art tracking methods across various applications and scenarios. To inform our analysis, we first categorize algorithmic, environmental, and locomotion-related challenges faced by tracking algorithms. We quantitatively evaluate the performance using multiple tracking algorithms and representative datasets for a wide range of Internet of Things (IoT) and Extended Reality (XR) applications, including autonomous vehicles, drones, and humans. Our analysis shows that no tracking algorithm works across different applications and scenarios within applications. Ultimately, using the insights generated from our analysis, we discuss multiple approaches to improving the tracking performance using input data characterization, leveraging intermediate information, and output evaluation.
A Neurosymbolic Approach to Adaptive Feature Extraction in SLAM
Jul 09, 2024



Autonomous robots, autonomous vehicles, and humans wearing mixed-reality headsets require accurate and reliable tracking services for safety-critical applications in dynamically changing real-world environments. However, the existing tracking approaches, such as Simultaneous Localization and Mapping (SLAM), do not adapt well to environmental changes and boundary conditions despite extensive manual tuning. On the other hand, while deep learning-based approaches can better adapt to environmental changes, they typically demand substantial data for training and often lack flexibility in adapting to new domains. To solve this problem, we propose leveraging the neurosymbolic program synthesis approach to construct adaptable SLAM pipelines that integrate the domain knowledge from traditional SLAM approaches while leveraging data to learn complex relationships. While the approach can synthesize end-to-end SLAM pipelines, we focus on synthesizing the feature extraction module. We first devise a domain-specific language (DSL) that can encapsulate domain knowledge on the important attributes for feature extraction and the real-world performance of various feature extractors. Our neurosymbolic architecture then undertakes adaptive feature extraction, optimizing parameters via learning while employing symbolic reasoning to select the most suitable feature extractor. Our evaluations demonstrate that our approach, neurosymbolic Feature EXtraction (nFEX), yields higher-quality features. It also reduces the pose error observed for the state-of-the-art baseline feature extractors ORB and SIFT by up to 90% and up to 66%, respectively, thereby enhancing the system's efficiency and adaptability to novel environments.
Why Don't You Clean Your Glasses? Perception Attacks with Dynamic Optical Perturbations
Jul 27, 2023



Camera-based autonomous systems that emulate human perception are increasingly being integrated into safety-critical platforms. Consequently, an established body of literature has emerged that explores adversarial attacks targeting the underlying machine learning models. Adapting adversarial attacks to the physical world is desirable for the attacker, as this removes the need to compromise digital systems. However, the real world poses challenges related to the "survivability" of adversarial manipulations given environmental noise in perception pipelines and the dynamicity of autonomous systems. In this paper, we take a sensor-first approach. We present EvilEye, a man-in-the-middle perception attack that leverages transparent displays to generate dynamic physical adversarial examples. EvilEye exploits the camera's optics to induce misclassifications under a variety of illumination conditions. To generate dynamic perturbations, we formalize the projection of a digital attack into the physical domain by modeling the transformation function of the captured image through the optical pipeline. Our extensive experiments show that EvilEye's generated adversarial perturbations are much more robust across varying environmental light conditions relative to existing physical perturbation frameworks, achieving a high attack success rate (ASR) while bypassing state-of-the-art physical adversarial detection frameworks. We demonstrate that the dynamic nature of EvilEye enables attackers to adapt adversarial examples across a variety of objects with a significantly higher ASR compared to state-of-the-art physical world attack frameworks. Finally, we discuss mitigation strategies against the EvilEye attack.
Eagle: End-to-end Deep Reinforcement Learning based Autonomous Control of PTZ Cameras
Apr 10, 2023



Existing approaches for autonomous control of pan-tilt-zoom (PTZ) cameras use multiple stages where object detection and localization are performed separately from the control of the PTZ mechanisms. These approaches require manual labels and suffer from performance bottlenecks due to error propagation across the multi-stage flow of information. The large size of object detection neural networks also makes prior solutions infeasible for real-time deployment in resource-constrained devices. We present an end-to-end deep reinforcement learning (RL) solution called Eagle to train a neural network policy that directly takes images as input to control the PTZ camera. Training reinforcement learning is cumbersome in the real world due to labeling effort, runtime environment stochasticity, and fragile experimental setups. We introduce a photo-realistic simulation framework for training and evaluation of PTZ camera control policies. Eagle achieves superior camera control performance by maintaining the object of interest close to the center of captured images at high resolution and has up to 17% more tracking duration than the state-of-the-art. Eagle policies are lightweight (90x fewer parameters than Yolo5s) and can run on embedded camera platforms such as Raspberry PI (33 FPS) and Jetson Nano (38 FPS), facilitating real-time PTZ tracking for resource-constrained environments. With domain randomization, Eagle policies trained in our simulator can be transferred directly to real-world scenarios.
Safety in the Emerging Holodeck Applications
Aug 17, 2022Technological advances in holography, robotics, and 3D printing are starting to realize the vision of a holodeck. These immersive 3D displays must address user safety from the start to be viable. A holodeck's safety challenges are novel because its applications will involve explicit physical interactions between humans and synthesized 3D objects and experiences in real-time. This pioneering paper first proposes research directions for modeling safety in future holodeck applications from traditional physical human-robot interaction modeling. Subsequently, we propose a test-bed to enable safety validation of physical human-robot interaction based on existing augmented reality and virtual simulation technology.
Automatic Concept Extraction for Concept Bottleneck-based Video Classification
Jun 21, 2022
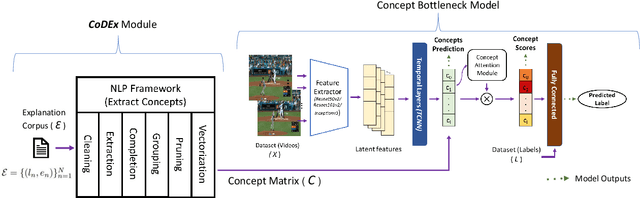
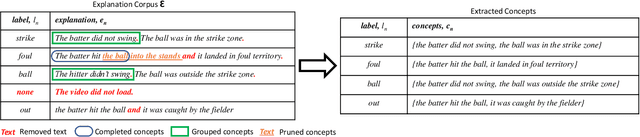

Recent efforts in interpretable deep learning models have shown that concept-based explanation methods achieve competitive accuracy with standard end-to-end models and enable reasoning and intervention about extracted high-level visual concepts from images, e.g., identifying the wing color and beak length for bird-species classification. However, these concept bottleneck models rely on a necessary and sufficient set of predefined concepts-which is intractable for complex tasks such as video classification. For complex tasks, the labels and the relationship between visual elements span many frames, e.g., identifying a bird flying or catching prey-necessitating concepts with various levels of abstraction. To this end, we present CoDEx, an automatic Concept Discovery and Extraction module that rigorously composes a necessary and sufficient set of concept abstractions for concept-based video classification. CoDEx identifies a rich set of complex concept abstractions from natural language explanations of videos-obviating the need to predefine the amorphous set of concepts. To demonstrate our method's viability, we construct two new public datasets that combine existing complex video classification datasets with short, crowd-sourced natural language explanations for their labels. Our method elicits inherent complex concept abstractions in natural language to generalize concept-bottleneck methods to complex tasks.
NS3: Neuro-Symbolic Semantic Code Search
May 21, 2022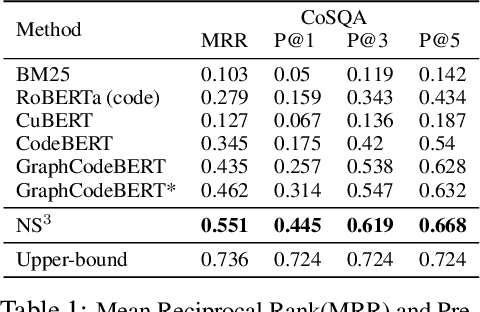
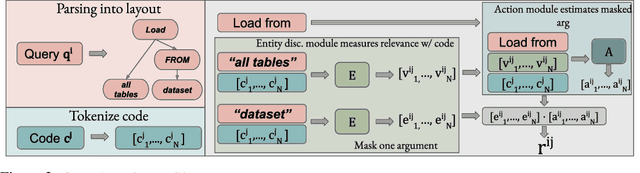
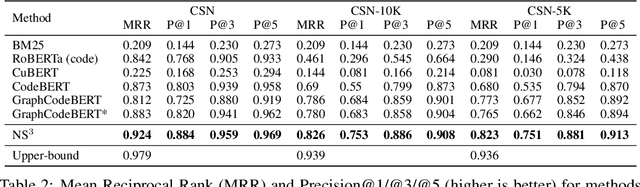
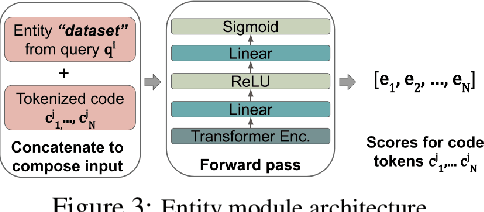
Semantic code search is the task of retrieving a code snippet given a textual description of its functionality. Recent work has been focused on using similarity metrics between neural embeddings of text and code. However, current language models are known to struggle with longer, compositional text, and multi-step reasoning. To overcome this limitation, we propose supplementing the query sentence with a layout of its semantic structure. The semantic layout is used to break down the final reasoning decision into a series of lower-level decisions. We use a Neural Module Network architecture to implement this idea. We compare our model - NS3 (Neuro-Symbolic Semantic Search) - to a number of baselines, including state-of-the-art semantic code retrieval methods, and evaluate on two datasets - CodeSearchNet and Code Search and Question Answering. We demonstrate that our approach results in more precise code retrieval, and we study the effectiveness of our modular design when handling compositional queries.
PhysioGAN: Training High Fidelity Generative Model for Physiological Sensor Readings
Apr 25, 2022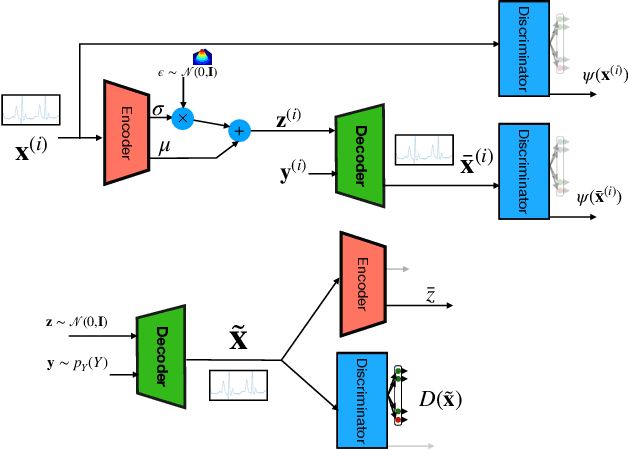
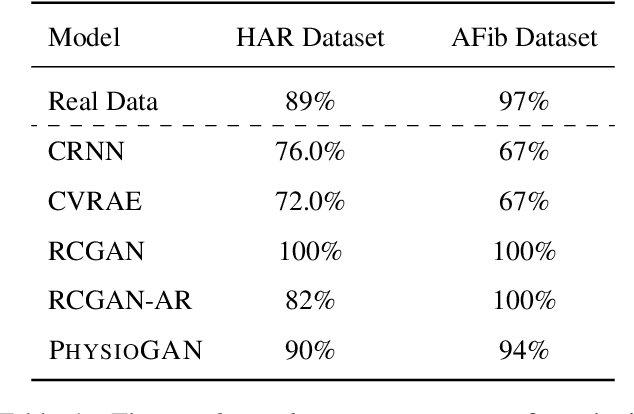
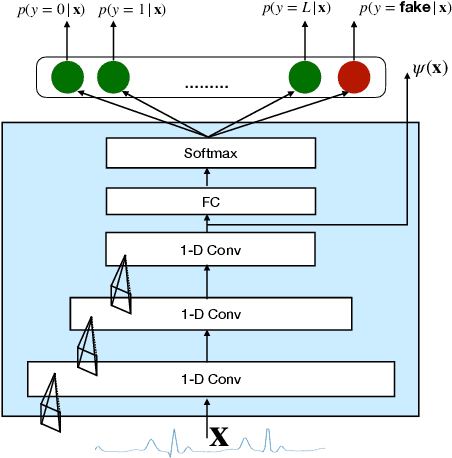
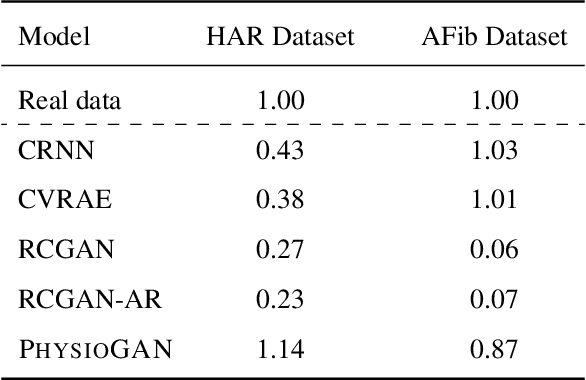
Generative models such as the variational autoencoder (VAE) and the generative adversarial networks (GAN) have proven to be incredibly powerful for the generation of synthetic data that preserves statistical properties and utility of real-world datasets, especially in the context of image and natural language text. Nevertheless, until now, there has no successful demonstration of how to apply either method for generating useful physiological sensory data. The state-of-the-art techniques in this context have achieved only limited success. We present PHYSIOGAN, a generative model to produce high fidelity synthetic physiological sensor data readings. PHYSIOGAN consists of an encoder, decoder, and a discriminator. We evaluate PHYSIOGAN against the state-of-the-art techniques using two different real-world datasets: ECG classification and activity recognition from motion sensors datasets. We compare PHYSIOGAN to the baseline models not only the accuracy of class conditional generation but also the sample diversity and sample novelty of the synthetic datasets. We prove that PHYSIOGAN generates samples with higher utility than other generative models by showing that classification models trained on only synthetic data generated by PHYSIOGAN have only 10% and 20% decrease in their classification accuracy relative to classification models trained on the real data. Furthermore, we demonstrate the use of PHYSIOGAN for sensor data imputation in creating plausible results.