 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffuBox: Refining 3D Object Detection with Point Diffusion
May 25, 2024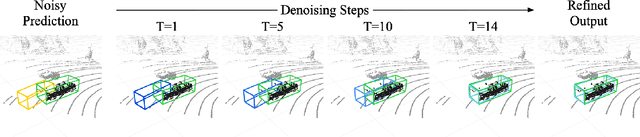
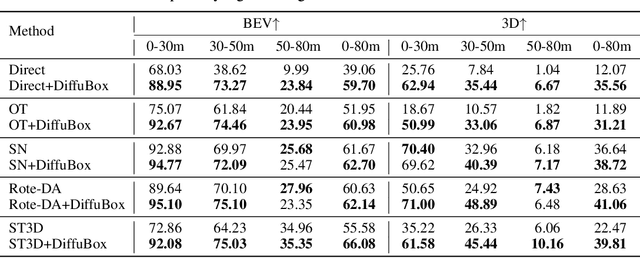
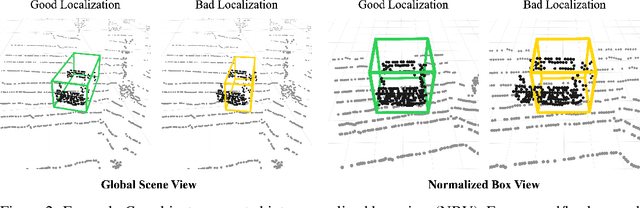
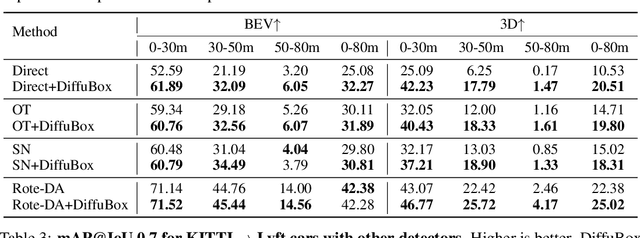
Ensuring robust 3D object detection and localization is crucial for many applications in robotics and autonomous driving. Recent models, however, face difficulties in maintaining high performance when applied to domains with differing sensor setups or geographic locations, often resulting in poor localization accuracy due to domain shift. To overcome this challenge, we introduce a novel diffusion-based box refinement approach. This method employs a domain-agnostic diffusion model, conditioned on the LiDAR points surrounding a coarse bounding box, to simultaneously refine the box's location, size, and orientation. We evaluate this approach under various domain adaptation settings, and our results reveal significant improvements across different datasets, object classes and detectors.
Learning to Detect and Segment Mobile Objects from Unlabeled Videos
May 23, 2024Embodied agents must detect and localize objects of interest, e.g. traffic participants for self-driving cars. Supervision in the form of bounding boxes for this task is extremely expensive. As such, prior work has looked at unsupervised object segmentation, but in the absence of annotated boxes, it is unclear how pixels must be grouped into objects and which objects are of interest. This results in over- / under-segmentation and irrelevant objects. Inspired both by the human visual system and by practical applications, we posit that the key missing cue is motion: objects of interest are typically mobile objects. We propose MOD-UV, a Mobile Object Detector learned from Unlabeled Videos only. We begin with pseudo-labels derived from motion segmentation, but introduce a novel training paradigm to progressively discover small objects and static-but-mobile objects that are missed by motion segmentation. As a result, though only learned from unlabeled videos, MOD-UV can detect and segment mobile objects from a single static image. Empirically, we achieve state-of-the-art performance in unsupervised mobile object detection on Waymo Open, nuScenes, and KITTI Dataset without using any external data or supervised models. Code is publicly available at https://github.com/YihongSun/MOD-UV.
Better Monocular 3D Detectors with LiDAR from the Past
Apr 09, 2024



Accurate 3D object detection is crucial to autonomous driving. Though LiDAR-based detectors have achieved impressive performance, the high cost of LiDAR sensors precludes their widespread adoption in affordable vehicles. Camera-based detectors are cheaper alternatives but often suffer inferior performance compared to their LiDAR-based counterparts due to inherent depth ambiguities in images. In this work, we seek to improve monocular 3D detectors by leveraging unlabeled historical LiDAR data. Specifically, at inference time, we assume that the camera-based detectors have access to multiple unlabeled LiDAR scans from past traversals at locations of interest (potentially from other high-end vehicles equipped with LiDAR sensors). Under this setup, we proposed a novel, simple, and end-to-end trainable framework, termed AsyncDepth, to effectively extract relevant features from asynchronous LiDAR traversals of the same location for monocular 3D detectors. We show consistent and significant performance gain (up to 9 AP) across multiple state-of-the-art models and datasets with a negligible additional latency of 9.66 ms and a small storage cost.
Remote Sensing Vision-Language Foundation Models without Annotations via Ground Remote Alignment
Dec 12, 2023We introduce a method to train vision-language models for remote-sensing images without using any textual annotations. Our key insight is to use co-located internet imagery taken on the ground as an intermediary for connecting remote-sensing images and language. Specifically, we train an image encoder for remote sensing images to align with the image encoder of CLIP using a large amount of paired internet and satellite images. Our unsupervised approach enables the training of a first-of-its-kind large-scale vision language model (VLM) for remote sensing images at two different resolutions. We show that these VLMs enable zero-shot, open-vocabulary image classification, retrieval, segmentation and visual question answering for satellite images. On each of these tasks, our VLM trained without textual annotations outperforms existing VLMs trained with supervision, with gains of up to 20% for classification and 80% for segmentation.
Accurate Differential Operators for Hybrid Neural Fields
Dec 10, 2023



Neural fields have become widely used in various fields, from shape representation to neural rendering, and for solving partial differential equations (PDEs). With the advent of hybrid neural field representations like Instant NGP that leverage small MLPs and explicit representations, these models train quickly and can fit large scenes. Yet in many applications like rendering and simulation, hybrid neural fields can cause noticeable and unreasonable artifacts. This is because they do not yield accurate spatial derivatives needed for these downstream applications. In this work, we propose two ways to circumvent these challenges. Our first approach is a post hoc operator that uses local polynomial-fitting to obtain more accurate derivatives from pre-trained hybrid neural fields. Additionally, we also propose a self-supervised fine-tuning approach that refines the neural field to yield accurate derivatives directly while preserving the initial signal. We show the application of our method on rendering, collision simulation, and solving PDEs. We observe that using our approach yields more accurate derivatives, reducing artifacts and leading to more accurate simulations in downstream applications.
Reward Finetuning for Faster and More Accurate Unsupervised Object Discovery
Nov 05, 2023



Recent advances in machine learning have shown that Reinforcement Learning from Human Feedback (RLHF) can improve machine learning models and align them with human preferences. Although very successful for Large Language Models (LLMs), these advancements have not had a comparable impact in research for autonomous vehicles -- where alignment with human expectations can be imperative. In this paper, we propose to adapt similar RL-based methods to unsupervised object discovery, i.e. learning to detect objects from LiDAR points without any training labels. Instead of labels, we use simple heuristics to mimic human feedback. More explicitly, we combine multiple heuristics into a simple reward function that positively correlates its score with bounding box accuracy, i.e., boxes containing objects are scored higher than those without. We start from the detector's own predictions to explore the space and reinforce boxes with high rewards through gradient updates. Empirically, we demonstrate that our approach is not only more accurate, but also orders of magnitudes faster to train compared to prior works on object discovery.
Dynamo-Depth: Fixing Unsupervised Depth Estimation for Dynamical Scenes
Oct 29, 2023Unsupervised monocular depth estimation techniques have demonstrated encouraging results but typically assume that the scene is static. These techniques suffer when trained on dynamical scenes, where apparent object motion can equally be explained by hypothesizing the object's independent motion, or by altering its depth. This ambiguity causes depth estimators to predict erroneous depth for moving objects. To resolve this issue, we introduce Dynamo-Depth, an unifying approach that disambiguates dynamical motion by jointly learning monocular depth, 3D independent flow field, and motion segmentation from unlabeled monocular videos. Specifically, we offer our key insight that a good initial estimation of motion segmentation is sufficient for jointly learning depth and independent motion despite the fundamental underlying ambiguity. Our proposed method achieves state-of-the-art performance on monocular depth estimation on Waymo Open and nuScenes Dataset with significant improvement in the depth of moving objects. Code and additional results are available at https://dynamo-depth.github.io.
Pre-Training LiDAR-Based 3D Object Detectors Through Colorization
Oct 23, 2023Accurate 3D object detection and understanding for self-driving cars heavily relies on LiDAR point clouds, necessitating large amounts of labeled data to train. In this work, we introduce an innovative pre-training approach, Grounded Point Colorization (GPC), to bridge the gap between data and labels by teaching the model to colorize LiDAR point clouds, equipping it with valuable semantic cues. To tackle challenges arising from color variations and selection bias, we incorporate color as "context" by providing ground-truth colors as hints during colorization. Experimental results on the KITTI and Waymo datasets demonstrate GPC's remarkable effectiveness. Even with limited labeled data, GPC significantly improves fine-tuning performance; notably, on just 20% of the KITTI dataset, GPC outperforms training from scratch with the entire dataset. In sum, we introduce a fresh perspective on pre-training for 3D object detection, aligning the objective with the model's intended role and ultimately advancing the accuracy and efficiency of 3D object detection for autonomous vehicles.
RealFill: Reference-Driven Generation for Authentic Image Completion
Sep 28, 2023Recent advances in generative imagery have brought forth outpainting and inpainting models that can produce high-quality, plausible image content in unknown regions, but the content these models hallucinate is necessarily inauthentic, since the models lack sufficient context about the true scene. In this work, we propose RealFill, a novel generative approach for image completion that fills in missing regions of an image with the content that should have been there. RealFill is a generative inpainting model that is personalized using only a few reference images of a scene. These reference images do not have to be aligned with the target image, and can be taken with drastically varying viewpoints, lighting conditions, camera apertures, or image styles. Once personalized, RealFill is able to complete a target image with visually compelling contents that are faithful to the original scene. We evaluate RealFill on a new image completion benchmark that covers a set of diverse and challenging scenarios, and find that it outperforms existing approaches by a large margin. See more results on our project page: https://realfill.github.io
Unsupervised Domain Adaptation for Self-Driving from Past Traversal Features
Sep 21, 2023The rapid development of 3D object detection systems for self-driving cars has significantly improved accuracy. However, these systems struggle to generalize across diverse driving environments, which can lead to safety-critical failures in detecting traffic participants. To address this, we propose a method that utilizes unlabeled repeated traversals of multiple locations to adapt object detectors to new driving environments. By incorporating statistics computed from repeated LiDAR scans, we guide the adaptation process effectively. Our approach enhances LiDAR-based detection models using spatial quantized historical features and introduces a lightweight regression head to leverage the statistics for feature regularization. Additionally, we leverage the statistics for a novel self-training process to stabilize the training. The framework is detector model-agnostic and experiments on real-world datasets demonstrate significant improvements, achieving up to a 20-point performance gain, especially in detecting pedestrians and distant objects. Code is available at https://github.com/zhangtravis/Hist-DA.