 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigger, Regularized, Categorical: High-Capacity Value Functions are Efficient Multi-Task Learners
May 29, 2025Recent advances in language modeling and vision stem from training large models on diverse, multi-task data. This paradigm has had limited impact in value-based reinforcement learning (RL), where improvements are often driven by small models trained in a single-task context. This is because in multi-task RL sparse rewards and gradient conflicts make optimization of temporal difference brittle. Practical workflows for generalist policies therefore avoid online training, instead cloning expert trajectories or distilling collections of single-task policies into one agent. In this work, we show that the use of high-capacity value models trained via cross-entropy and conditioned on learnable task embeddings addresses the problem of task interference in online RL, allowing for robust and scalable multi-task training. We test our approach on 7 multi-task benchmarks with over 280 unique tasks, spanning high degree-of-freedom humanoid control and discrete vision-based RL. We find that, despite its simplicity, the proposed approach leads to state-of-the-art single and multi-task performance, as well as sample-efficient transfer to new tasks.
Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning
Mar 10, 2025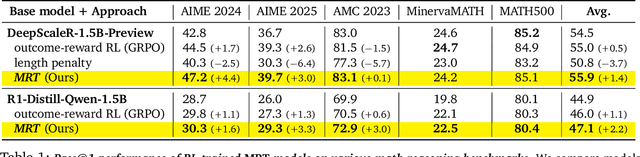
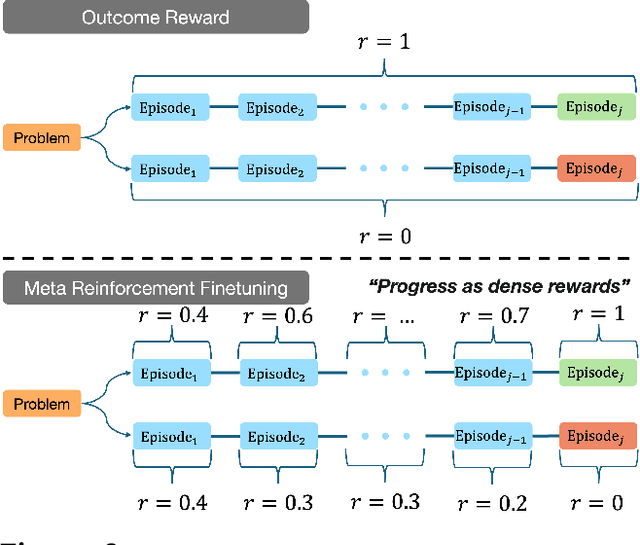
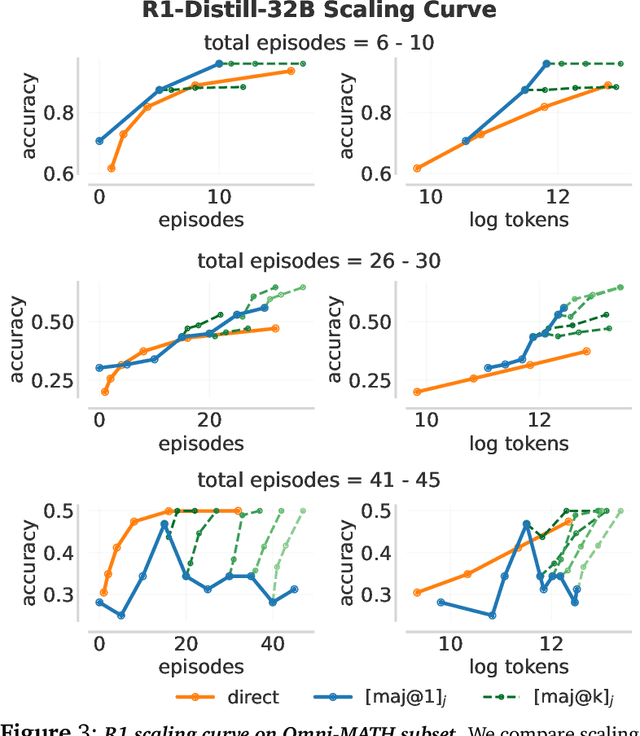
Training models to effectively use test-time compute is crucial for improving the reasoning performance of LLMs. Current methods mostly do so via fine-tuning on search traces or running RL with 0/1 outcome reward, but do these approaches efficiently utilize test-time compute? Would these approaches continue to scale as the budget improves? In this paper, we try to answer these questions. We formalize the problem of optimizing test-time compute as a meta-reinforcement learning (RL) problem, which provides a principled perspective on spending test-time compute. This perspective enables us to view the long output stream from the LLM as consisting of several episodes run at test time and leads us to use a notion of cumulative regret over output tokens as a way to measure the efficacy of test-time compute. Akin to how RL algorithms can best tradeoff exploration and exploitation over training, minimizing cumulative regret would also provide the best balance between exploration and exploitation in the token stream. While we show that state-of-the-art models do not minimize regret, one can do so by maximizing a dense reward bonus in conjunction with the outcome 0/1 reward RL. This bonus is the ''progress'' made by each subsequent block in the output stream, quantified by the change in the likelihood of eventual success. Using these insights, we develop Meta Reinforcement Fine-Tuning, or MRT, a new class of fine-tuning methods for optimizing test-time compute. MRT leads to a 2-3x relative gain in performance and roughly a 1.5x gain in token efficiency for math reasoning compared to outcome-reward RL.
Scaling Test-Time Compute Without Verification or RL is Suboptimal
Feb 18, 2025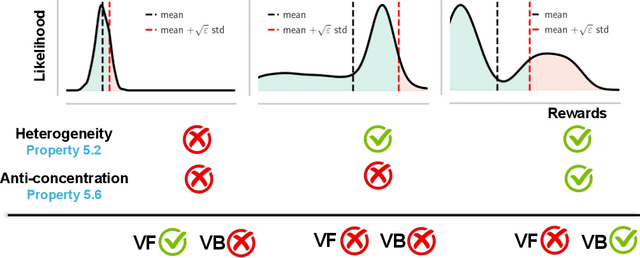
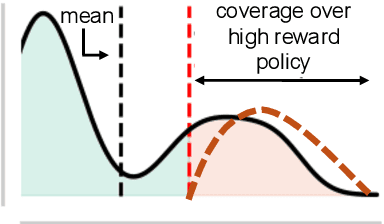
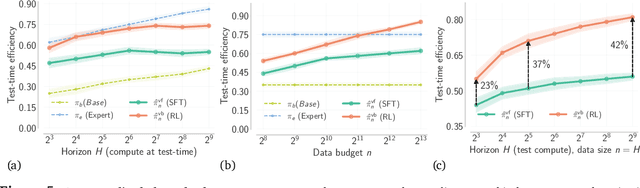
Despite substantial advances in scaling test-time compute, an ongoing debate in the community is how it should be scaled up to enable continued and efficient improvements with scaling. There are largely two approaches: first, distilling successful search or thinking traces; and second, using verification (e.g., 0/1 outcome rewards, reward models, or verifiers) to guide reinforcement learning (RL) and search algorithms. In this paper, we prove that finetuning LLMs with verifier-based (VB) methods based on RL or search is far superior to verifier-free (VF) approaches based on distilling or cloning search traces, given a fixed amount of compute/data budget. Further, we show that as we scale test-time compute (measured as the output token length) and training data, suboptimality of VF methods scales poorly compared to VB when the base pre-trained LLM presents a heterogeneous distribution over correct solution traces (e.g., different lengths, styles, etc.) and admits a non-sharp distribution over rewards on traces sampled from it. We formalize this condition using anti-concentration [Erd\H{o}s, 1945]. This implies a stronger result that VB methods scale better asymptotically, with the performance gap between VB and VF methods widening as test-time budget grows. We corroborate our theory empirically on both didactic and math reasoning problems with 3/8/32B-sized pre-trained LLMs, where we find verification is crucial for scaling test-time compute.
Value-Based Deep RL Scales Predictably
Feb 06, 2025Scaling data and compute is critical to the success of machine learning. However, scaling demands predictability: we want methods to not only perform well with more compute or data, but also have their performance be predictable from small-scale runs, without running the large-scale experiment. In this paper, we show that value-based off-policy RL methods are predictable despite community lore regarding their pathological behavior. First, we show that data and compute requirements to attain a given performance level lie on a Pareto frontier, controlled by the updates-to-data (UTD) ratio. By estimating this frontier, we can predict this data requirement when given more compute, and this compute requirement when given more data. Second, we determine the optimal allocation of a total resource budget across data and compute for a given performance and use it to determine hyperparameters that maximize performance for a given budget. Third, this scaling behavior is enabled by first estimating predictable relationships between hyperparameters, which is used to manage effects of overfitting and plasticity loss unique to RL. We validate our approach using three algorithms: SAC, BRO, and PQL on DeepMind Control, OpenAI gym, and IsaacGym, when extrapolating to higher levels of data, compute, budget, or performance.
Inference-Aware Fine-Tuning for Best-of-N Sampling in Large Language Models
Dec 18, 2024



Recent studies have indicated that effectively utilizing inference-time compute is crucial for attaining better performance from large language models (LLMs). In this work, we propose a novel inference-aware fine-tuning paradigm, in which the model is fine-tuned in a manner that directly optimizes the performance of the inference-time strategy. We study this paradigm using the simple yet effective Best-of-N (BoN) inference strategy, in which a verifier selects the best out of a set of LLM-generated responses. We devise the first imitation learning and reinforcement learning~(RL) methods for BoN-aware fine-tuning, overcoming the challenging, non-differentiable argmax operator within BoN. We empirically demonstrate that our BoN-aware models implicitly learn a meta-strategy that interleaves best responses with more diverse responses that might be better suited to a test-time input -- a process reminiscent of the exploration-exploitation trade-off in RL. Our experiments demonstrate the effectiveness of BoN-aware fine-tuning in terms of improved performance and inference-time compute. In particular, we show that our methods improve the Bo32 performance of Gemma 2B on Hendrycks MATH from 26.8% to 30.8%, and pass@32 from 60.0% to 67.0%, as well as the pass@16 on HumanEval from 61.6% to 67.1%.
Efficient Online Reinforcement Learning Fine-Tuning Need Not Retain Offline Data
Dec 10, 2024



The modern paradigm in machine learning involves pre-training on diverse data, followed by task-specific fine-tuning. In reinforcement learning (RL), this translates to learning via offline RL on a diverse historical dataset, followed by rapid online RL fine-tuning using interaction data. Most RL fine-tuning methods require continued training on offline data for stability and performance. However, this is undesirable because training on diverse offline data is slow and expensive for large datasets, and in principle, also limit the performance improvement possible because of constraints or pessimism on offline data. In this paper, we show that retaining offline data is unnecessary as long as we use a properly-designed online RL approach for fine-tuning offline RL initializations. To build this approach, we start by analyzing the role of retaining offline data in online fine-tuning. We find that continued training on offline data is mostly useful for preventing a sudden divergence in the value function at the onset of fine-tuning, caused by a distribution mismatch between the offline data and online rollouts. This divergence typically results in unlearning and forgetting the benefits of offline pre-training. Our approach, Warm-start RL (WSRL), mitigates the catastrophic forgetting of pre-trained initializations using a very simple idea. WSRL employs a warmup phase that seeds the online RL run with a very small number of rollouts from the pre-trained policy to do fast online RL. The data collected during warmup helps ``recalibrate'' the offline Q-function to the online distribution, allowing us to completely discard offline data without destabilizing the online RL fine-tuning. We show that WSRL is able to fine-tune without retaining any offline data, and is able to learn faster and attains higher performance than existing algorithms irrespective of whether they retain offline data or not.
Policy Agnostic RL: Offline RL and Online RL Fine-Tuning of Any Class and Backbone
Dec 09, 2024Recent advances in learning decision-making policies can largely be attributed to training expressive policy models, largely via imitation learning. While imitation learning discards non-expert data, reinforcement learning (RL) can still learn from suboptimal data. However, instantiating RL training of a new policy class often presents a different challenge: most deep RL machinery is co-developed with assumptions on the policy class and backbone, resulting in poor performance when the policy class changes. For instance, SAC utilizes a low-variance reparameterization policy gradient for Gaussian policies, but this is unstable for diffusion policies and intractable for autoregressive categorical policies. To address this issue, we develop an offline RL and online fine-tuning approach called policy-agnostic RL (PA-RL) that can effectively train multiple policy classes, with varying architectures and sizes. We build off the basic idea that a universal supervised learning loss can replace the policy improvement step in RL, as long as it is applied on "optimized" actions. To obtain these optimized actions, we first sample multiple actions from a base policy, and run global optimization (i.e., re-ranking multiple action samples using the Q-function) and local optimization (i.e., running gradient steps on an action sample) to maximize the critic on these candidates. PA-RL enables fine-tuning diffusion and transformer policies with either autoregressive tokens or continuous action outputs, at different sizes, entirely via actor-critic RL. Moreover, PA-RL improves the performance and sample-efficiency by up to 2 times compared to existing offline RL and online fine-tuning methods. We show the first result that successfully fine-tunes OpenVLA, a 7B generalist robot policy, autonomously with Cal-QL, an online RL fine-tuning algorithm, improving from 40% to 70% in the real world in 40 minutes.
What Do Learning Dynamics Reveal About Generalization in LLM Reasoning?
Nov 12, 2024



Despite the remarkable capabilities of modern large language models (LLMs), the mechanisms behind their problem-solving abilities remain elusive. In this work, we aim to better understand how the learning dynamics of LLM finetuning shapes downstream generalization. Our analysis focuses on reasoning tasks, whose problem structure allows us to distinguish between memorization (the exact replication of reasoning steps from the training data) and performance (the correctness of the final solution). We find that a model's generalization behavior can be effectively characterized by a training metric we call pre-memorization train accuracy: the accuracy of model samples on training queries before they begin to copy the exact reasoning steps from the training set. On the dataset level, this metric is able to reliably predict test accuracy, achieving $R^2$ of around or exceeding 0.9 across various models (Llama3 8, Gemma2 9B), datasets (GSM8k, MATH), and training configurations. On a per-example level, this metric is also indicative of whether individual model predictions are robust to perturbations in the training query. By connecting a model's learning behavior to its generalization, pre-memorization train accuracy can guide targeted improvements to training strategies. We focus on data curation as an example, and show that prioritizing examples with low pre-memorization accuracy leads to 1.5-2x improvements in data efficiency compared to i.i.d. data scaling, and outperforms other standard data curation techniques.
Steering Your Generalists: Improving Robotic Foundation Models via Value Guidance
Oct 17, 2024



Large, general-purpose robotic policies trained on diverse demonstration datasets have been shown to be remarkably effective both for controlling a variety of robots in a range of different scenes, and for acquiring broad repertoires of manipulation skills. However, the data that such policies are trained on is generally of mixed quality -- not only are human-collected demonstrations unlikely to perform the task perfectly, but the larger the dataset is, the harder it is to curate only the highest quality examples. It also remains unclear how optimal data from one embodiment is for training on another embodiment. In this paper, we present a general and broadly applicable approach that enhances the performance of such generalist robot policies at deployment time by re-ranking their actions according to a value function learned via offline RL. This approach, which we call Value-Guided Policy Steering (V-GPS), is compatible with a wide range of different generalist policies, without needing to fine-tune or even access the weights of the policy. We show that the same value function can improve the performance of five different state-of-the-art policies with different architectures, even though they were trained on distinct datasets, attaining consistent performance improvement on multiple robotic platforms across a total of 12 tasks. Code and videos can be found at: https://nakamotoo.github.io/V-GPS
Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning
Oct 10, 2024



A promising approach for improving reasoning in large language models is to use process reward models (PRMs). PRMs provide feedback at each step of a multi-step reasoning trace, potentially improving credit assignment over outcome reward models (ORMs) that only provide feedback at the final step. However, collecting dense, per-step human labels is not scalable, and training PRMs from automatically-labeled data has thus far led to limited gains. To improve a base policy by running search against a PRM or using it as dense rewards for reinforcement learning (RL), we ask: "How should we design process rewards?". Our key insight is that, to be effective, the process reward for a step should measure progress: a change in the likelihood of producing a correct response in the future, before and after taking the step, corresponding to the notion of step-level advantages in RL. Crucially, this progress should be measured under a prover policy distinct from the base policy. We theoretically characterize the set of good provers and our results show that optimizing process rewards from such provers improves exploration during test-time search and online RL. In fact, our characterization shows that weak prover policies can substantially improve a stronger base policy, which we also observe empirically. We validate our claims by training process advantage verifiers (PAVs) to predict progress under such provers, and show that compared to ORMs, test-time search against PAVs is $>8\%$ more accurate, and $1.5-5\times$ more compute-efficient. Online RL with dense rewards from PAVs enables one of the first results with $5-6\times$ gain in sample efficiency, and $>6\%$ gain in accuracy, over ORMs.