 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNESTFUL: A Benchmark for Evaluating LLMs on Nested Sequences of API Calls
Sep 04, 2024Autonomous agent applications powered by large language models (LLMs) have recently risen to prominence as effective tools for addressing complex real-world tasks. At their core, agentic workflows rely on LLMs to plan and execute the use of tools and external Application Programming Interfaces (APIs) in sequence to arrive at the answer to a user's request. Various benchmarks and leaderboards have emerged to evaluate an LLM's capabilities for tool and API use; however, most of these evaluations only track single or multiple isolated API calling capabilities. In this paper, we present NESTFUL, a benchmark to evaluate LLMs on nested sequences of API calls, i.e., sequences where the output of one API call is passed as input to a subsequent call. NESTFUL has a total of 300 human annotated samples divided into two types - executable and non-executable. The executable samples are curated manually by crawling Rapid-APIs whereas the non-executable samples are hand picked by human annotators from data synthetically generated using an LLM. We evaluate state-of-the-art LLMs with function calling abilities on NESTFUL. Our results show that most models do not perform well on nested APIs in NESTFUL as compared to their performance on the simpler problem settings available in existing benchmarks.
Granite-Function Calling Model: Introducing Function Calling Abilities via Multi-task Learning of Granular Tasks
Jun 27, 2024



Large language models (LLMs) have recently shown tremendous promise in serving as the backbone to agentic systems, as demonstrated by their performance in multi-faceted, challenging benchmarks like SWE-Bench and Agent-Bench. However, to realize the true potential of LLMs as autonomous agents, they must learn to identify, call, and interact with external tools and application program interfaces (APIs) to complete complex tasks. These tasks together are termed function calling. Endowing LLMs with function calling abilities leads to a myriad of advantages, such as access to current and domain-specific information in databases and knowledge sources, and the ability to outsource tasks that can be reliably performed by tools, e.g., a Python interpreter or calculator. While there has been significant progress in function calling with LLMs, there is still a dearth of open models that perform on par with proprietary LLMs like GPT, Claude, and Gemini. Therefore, in this work, we introduce the GRANITE-20B-FUNCTIONCALLING model under an Apache 2.0 license. The model is trained using a multi-task training approach on seven fundamental tasks encompassed in function calling, those being Nested Function Calling, Function Chaining, Parallel Functions, Function Name Detection, Parameter-Value Pair Detection, Next-Best Function, and Response Generation. We present a comprehensive evaluation on multiple out-of-domain datasets comparing GRANITE-20B-FUNCTIONCALLING to more than 15 other best proprietary and open models. GRANITE-20B-FUNCTIONCALLING provides the best performance among all open models on the Berkeley Function Calling Leaderboard and fourth overall. As a result of the diverse tasks and datasets used for training our model, we show that GRANITE-20B-FUNCTIONCALLING has better generalizability on multiple tasks in seven different evaluation datasets.
Granite Code Models: A Family of Open Foundation Models for Code Intelligence
May 07, 2024



Large Language Models (LLMs) trained on code are revolutionizing the software development process. Increasingly, code LLMs are being integrated into software development environments to improve the productivity of human programmers, and LLM-based agents are beginning to show promise for handling complex tasks autonomously. Realizing the full potential of code LLMs requires a wide range of capabilities, including code generation, fixing bugs, explaining and documenting code, maintaining repositories, and more. In this work, we introduce the Granite series of decoder-only code models for code generative tasks, trained with code written in 116 programming languages. The Granite Code models family consists of models ranging in size from 3 to 34 billion parameters, suitable for applications ranging from complex application modernization tasks to on-device memory-constrained use cases. Evaluation on a comprehensive set of tasks demonstrates that Granite Code models consistently reaches state-of-the-art performance among available open-source code LLMs. The Granite Code model family was optimized for enterprise software development workflows and performs well across a range of coding tasks (e.g. code generation, fixing and explanation), making it a versatile all around code model. We release all our Granite Code models under an Apache 2.0 license for both research and commercial use.
Self-Refinement of Language Models from External Proxy Metrics Feedback
Feb 27, 2024



It is often desirable for Large Language Models (LLMs) to capture multiple objectives when providing a response. In document-grounded response generation, for example, agent responses are expected to be relevant to a user's query while also being grounded in a given document. In this paper, we introduce Proxy Metric-based Self-Refinement (ProMiSe), which enables an LLM to refine its own initial response along key dimensions of quality guided by external metrics feedback, yielding an overall better final response. ProMiSe leverages feedback on response quality through principle-specific proxy metrics, and iteratively refines its response one principle at a time. We apply ProMiSe to open source language models Flan-T5-XXL and Llama-2-13B-Chat, to evaluate its performance on document-grounded question answering datasets, MultiDoc2Dial and QuAC, demonstrating that self-refinement improves response quality. We further show that fine-tuning Llama-2-13B-Chat on the synthetic dialogue data generated by ProMiSe yields significant performance improvements over the zero-shot baseline as well as a supervised fine-tuned model on human annotated data.
API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs
Feb 23, 2024There is a growing need for Large Language Models (LLMs) to effectively use tools and external Application Programming Interfaces (APIs) to plan and complete tasks. As such, there is tremendous interest in methods that can acquire sufficient quantities of train and test data that involve calls to tools / APIs. Two lines of research have emerged as the predominant strategies for addressing this challenge. The first has focused on synthetic data generation techniques, while the second has involved curating task-adjacent datasets which can be transformed into API / Tool-based tasks. In this paper, we focus on the task of identifying, curating, and transforming existing datasets and, in turn, introduce API-BLEND, a large corpora for training and systematic testing of tool-augmented LLMs. The datasets mimic real-world scenarios involving API-tasks such as API / tool detection, slot filling, and sequencing of the detected APIs. We demonstrate the utility of the API-BLEND dataset for both training and benchmarking purposes.
BRAIn: Bayesian Reward-conditioned Amortized Inference for natural language generation from feedback
Feb 04, 2024



Following the success of Proximal Policy Optimization (PPO) for Reinforcement Learning from Human Feedback (RLHF), new techniques such as Sequence Likelihood Calibration (SLiC) and Direct Policy Optimization (DPO) have been proposed that are offline in nature and use rewards in an indirect manner. These techniques, in particular DPO, have recently become the tools of choice for LLM alignment due to their scalability and performance. However, they leave behind important features of the PPO approach. Methods such as SLiC or RRHF make use of the Reward Model (RM) only for ranking/preference, losing fine-grained information and ignoring the parametric form of the RM (eg., Bradley-Terry, Plackett-Luce), while methods such as DPO do not use even a separate reward model. In this work, we propose a novel approach, named BRAIn, that re-introduces the RM as part of a distribution matching approach.BRAIn considers the LLM distribution conditioned on the assumption of output goodness and applies Bayes theorem to derive an intractable posterior distribution where the RM is explicitly represented. BRAIn then distills this posterior into an amortized inference network through self-normalized importance sampling, leading to a scalable offline algorithm that significantly outperforms prior art in summarization and AntropicHH tasks. BRAIn also has interesting connections to PPO and DPO for specific RM choices.
Using Large Language Models to Automate Category and Trend Analysis of Scientific Articles: An Application in Ophthalmology
Aug 31, 2023Purpose: In this paper, we present an automated method for article classification, leveraging the power of Large Language Models (LLM). The primary focus is on the field of ophthalmology, but the model is extendable to other fields. Methods: We have developed a model based on Natural Language Processing (NLP) techniques, including advanced LLMs, to process and analyze the textual content of scientific papers. Specifically, we have employed zero-shot learning (ZSL) LLM models and compared against Bidirectional and Auto-Regressive Transformers (BART) and its variants, and Bidirectional Encoder Representations from Transformers (BERT), and its variant such as distilBERT, SciBERT, PubmedBERT, BioBERT. Results: The classification results demonstrate the effectiveness of LLMs in categorizing large number of ophthalmology papers without human intervention. Results: To evalute the LLMs, we compiled a dataset (RenD) of 1000 ocular disease-related articles, which were expertly annotated by a panel of six specialists into 15 distinct categories. The model achieved mean accuracy of 0.86 and mean F1 of 0.85 based on the RenD dataset. Conclusion: The proposed framework achieves notable improvements in both accuracy and efficiency. Its application in the domain of ophthalmology showcases its potential for knowledge organization and retrieval in other domains too. We performed trend analysis that enables the researchers and clinicians to easily categorize and retrieve relevant papers, saving time and effort in literature review and information gathering as well as identification of emerging scientific trends within different disciplines. Moreover, the extendibility of the model to other scientific fields broadens its impact in facilitating research and trend analysis across diverse disciplines.
Learning Symbolic Rules over Abstract Meaning Representations for Textual Reinforcement Learning
Jul 05, 2023



Text-based reinforcement learning agents have predominantly been neural network-based models with embeddings-based representation, learning uninterpretable policies that often do not generalize well to unseen games. On the other hand, neuro-symbolic methods, specifically those that leverage an intermediate formal representation, are gaining significant attention in language understanding tasks. This is because of their advantages ranging from inherent interpretability, the lesser requirement of training data, and being generalizable in scenarios with unseen data. Therefore, in this paper, we propose a modular, NEuro-Symbolic Textual Agent (NESTA) that combines a generic semantic parser with a rule induction system to learn abstract interpretable rules as policies. Our experiments on established text-based game benchmarks show that the proposed NESTA method outperforms deep reinforcement learning-based techniques by achieving better generalization to unseen test games and learning from fewer training interactions.
LOA: Logical Optimal Actions for Text-based Interaction Games
Oct 21, 2021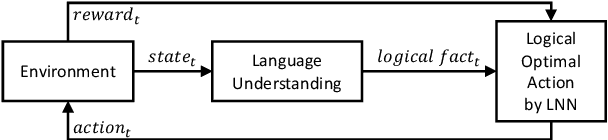
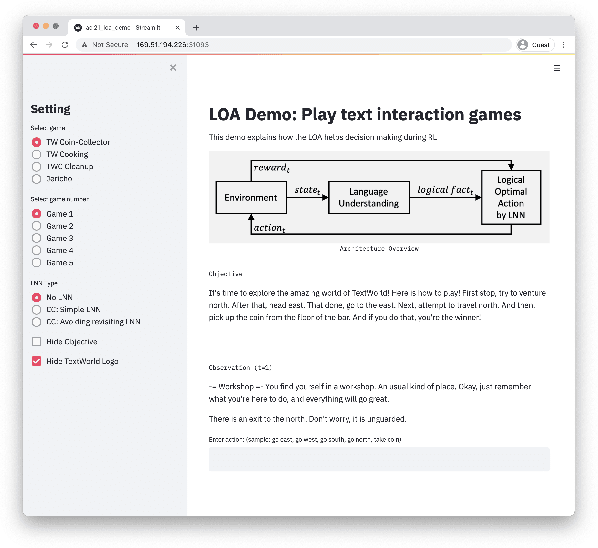
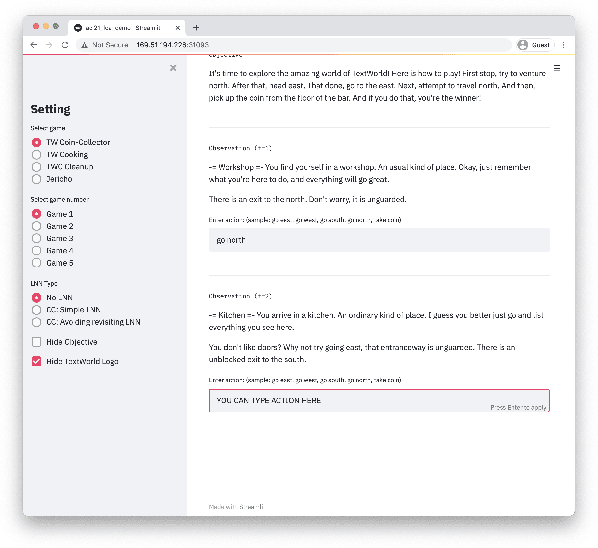
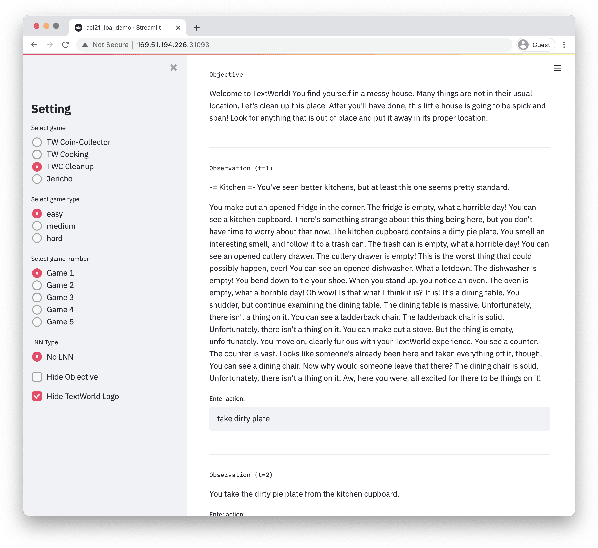
We present Logical Optimal Actions (LOA), an action decision architecture of reinforcement learning applications with a neuro-symbolic framework which is a combination of neural network and symbolic knowledge acquisition approach for natural language interaction games. The demonstration for LOA experiments consists of a web-based interactive platform for text-based games and visualization for acquired knowledge for improving interpretability for trained rules. This demonstration also provides a comparison module with other neuro-symbolic approaches as well as non-symbolic state-of-the-art agent models on the same text-based games. Our LOA also provides open-sourced implementation in Python for the reinforcement learning environment to facilitate an experiment for studying neuro-symbolic agents. Code: https://github.com/ibm/loa
Neuro-Symbolic Reinforcement Learning with First-Order Logic
Oct 21, 2021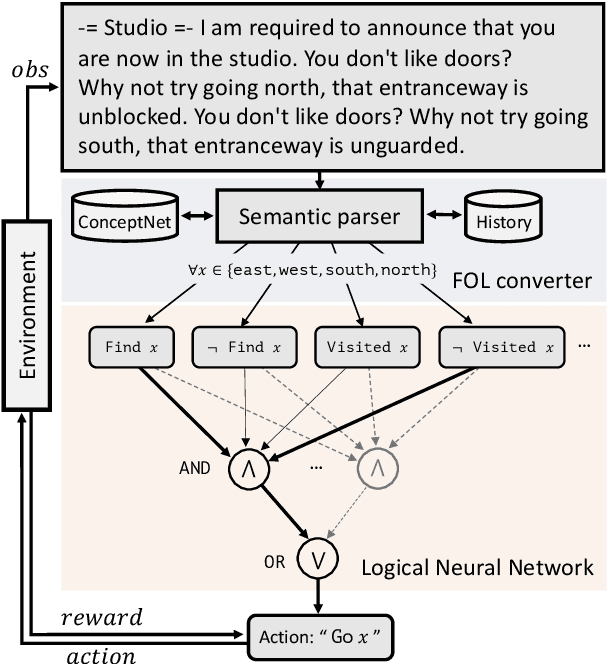
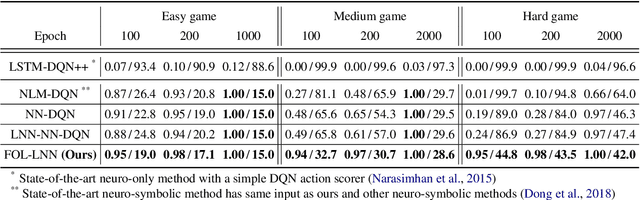
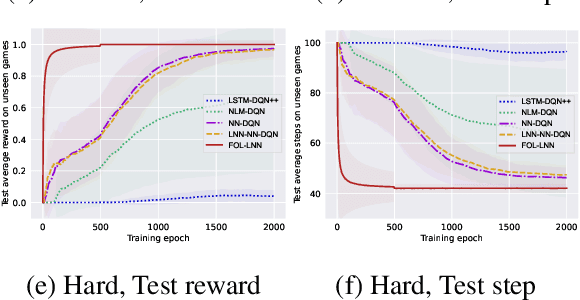
Deep reinforcement learning (RL) methods often require many trials before convergence, and no direct interpretability of trained policies is provided. In order to achieve fast convergence and interpretability for the policy in RL, we propose a novel RL method for text-based games with a recent neuro-symbolic framework called Logical Neural Network, which can learn symbolic and interpretable rules in their differentiable network. The method is first to extract first-order logical facts from text observation and external word meaning network (ConceptNet), then train a policy in the network with directly interpretable logical operators. Our experimental results show RL training with the proposed method converges significantly faster than other state-of-the-art neuro-symbolic methods in a TextWorld benchmark.