 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Lifecycle Toolkit (ALTK): Reusable Middleware Components for Robust AI Agents
Mar 16, 2026As AI agents move from demos into enterprise deployments, their failure modes become consequential: a misinterpreted tool argument can corrupt production data, a silent reasoning error can go undetected until damage is done, and outputs that violate organizational policy can create legal or compliance risk. Yet, most agent frameworks leave builders to handle these failure modes ad hoc, resulting in brittle, one-off safeguards that are hard to reuse or maintain. We present the Agent Lifecycle Toolkit (ALTK), an open-source collection of modular middleware components that systematically address these gaps across the full agent lifecycle. Across the agent lifecycle, we identify opportunities to intervene and improve, namely, post-user-request, pre-LLM prompt conditioning, post-LLM output processing, pre-tool validation, post-tool result checking, and pre-response assembly. ALTK provides modular middleware that detects, repairs, and mitigates common failure modes. It offers consistent interfaces that fit naturally into existing pipelines. It is compatible with low-code and no-code tools such as the ContextForge MCP Gateway and Langflow. Finally, it significantly reduces the effort of building reliable, production-grade agents.
Trajectory-Informed Memory Generation for Self-Improving Agent Systems
Mar 11, 2026LLM-powered agents face a persistent challenge: learning from their execution experiences to improve future performance. While agents can successfully complete many tasks, they often repeat inefficient patterns, fail to recover from similar errors, and miss opportunities to apply successful strategies from past executions. We present a novel framework for automatically extracting actionable learnings from agent execution trajectories and utilizing them to improve future performance through contextual memory retrieval. Our approach comprises four components: (1) a Trajectory Intelligence Extractor that performs semantic analysis of agent reasoning patterns, (2) a Decision Attribution Analyzer that identifies which decisions and reasoning steps led to failures, recoveries, or inefficiencies, (3) a Contextual Learning Generator that produces three types of guidance -- strategy tips from successful patterns, recovery tips from failure handling, and optimization tips from inefficient but successful executions, and (4) an Adaptive Memory Retrieval System that injects relevant learnings into agent prompts based on multi-dimensional similarity. Unlike existing memory systems that store generic conversational facts, our framework understands execution patterns, extracts structured learnings with provenance, and retrieves guidance tailored to specific task contexts. Evaluation on the AppWorld benchmark demonstrates consistent improvements, with up to 14.3 percentage point gains in scenario goal completion on held-out tasks and particularly strong benefits on complex tasks (28.5~pp scenario goal improvement, a 149\% relative increase).
VOILA: Value-of-Information Guided Fidelity Selection for Cost-Aware Multimodal Question Answering
Feb 03, 2026Despite significant costs from retrieving and processing high-fidelity visual inputs, most multimodal vision-language systems operate at fixed fidelity levels. We introduce VOILA, a framework for Value-Of-Information-driven adaptive fidelity selection in Visual Question Answering (VQA) that optimizes what information to retrieve before model execution. Given a query, VOILA uses a two-stage pipeline: a gradient-boosted regressor estimates correctness likelihood at each fidelity from question features alone, then an isotonic calibrator refines these probabilities for reliable decision-making. The system selects the minimum-cost fidelity maximizing expected utility given predicted accuracy and retrieval costs. We evaluate VOILA across three deployment scenarios using five datasets (VQA-v2, GQA, TextVQA, LoCoMo, FloodNet) and six Vision-Language Models (VLMs) with 7B-235B parameters. VOILA consistently achieves 50-60% cost reductions while retaining 90-95% of full-resolution accuracy across diverse query types and model architectures, demonstrating that pre-retrieval fidelity selection is vital to optimize multimodal inference under resource constraints.
FLOW-BENCH: Towards Conversational Generation of Enterprise Workflows
May 16, 2025Business process automation (BPA) that leverages Large Language Models (LLMs) to convert natural language (NL) instructions into structured business process artifacts is becoming a hot research topic. This paper makes two technical contributions -- (i) FLOW-BENCH, a high quality dataset of paired natural language instructions and structured business process definitions to evaluate NL-based BPA tools, and support bourgeoning research in this area, and (ii) FLOW-GEN, our approach to utilize LLMs to translate natural language into an intermediate representation with Python syntax that facilitates final conversion into widely adopted business process definition languages, such as BPMN and DMN. We bootstrap FLOW-BENCH by demonstrating how it can be used to evaluate the components of FLOW-GEN across eight LLMs of varying sizes. We hope that FLOW-GEN and FLOW-BENCH catalyze further research in BPA making it more accessible to novice and expert users.
OptiSeq: Optimizing Example Ordering for In-Context Learning
Jan 25, 2025Developers using LLMs in their applications and agents have provided plenty of anecdotal evidence that in-context-learning (ICL) is fragile. In addition to the quantity and quality of examples, we show that the order in which the in-context examples are listed in the prompt affects the output of the LLM and, consequently, their performance. In this paper, we present OptiSeq, which introduces a score based on log probabilities of LLM outputs to prune the universe of possible example orderings in few-shot ICL and recommend the best order(s) by distinguishing between correct and incorrect outputs resulting from different order permutations. Through a detailed empirical evaluation on multiple LLMs, datasets and prompts, we demonstrate that OptiSeq improves accuracy by 6 - 10.5 percentage points across multiple tasks.
API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs
Feb 23, 2024There is a growing need for Large Language Models (LLMs) to effectively use tools and external Application Programming Interfaces (APIs) to plan and complete tasks. As such, there is tremendous interest in methods that can acquire sufficient quantities of train and test data that involve calls to tools / APIs. Two lines of research have emerged as the predominant strategies for addressing this challenge. The first has focused on synthetic data generation techniques, while the second has involved curating task-adjacent datasets which can be transformed into API / Tool-based tasks. In this paper, we focus on the task of identifying, curating, and transforming existing datasets and, in turn, introduce API-BLEND, a large corpora for training and systematic testing of tool-augmented LLMs. The datasets mimic real-world scenarios involving API-tasks such as API / tool detection, slot filling, and sequencing of the detected APIs. We demonstrate the utility of the API-BLEND dataset for both training and benchmarking purposes.
FedGen: Generalizable Federated Learning
Nov 03, 2022Existing federated learning models that follow the standard risk minimization paradigm of machine learning often fail to generalize in the presence of spurious correlations in the training data. In many real-world distributed settings, spurious correlations exist due to biases and data sampling issues on distributed devices or clients that can erroneously influence models. Current generalization approaches are designed for centralized training and attempt to identify features that have an invariant causal relationship with the target, thereby reducing the effect of spurious features. However, such invariant risk minimization approaches rely on apriori knowledge of training data distributions which is hard to obtain in many applications. In this work, we present a generalizable federated learning framework called FedGen, which allows clients to identify and distinguish between spurious and invariant features in a collaborative manner without prior knowledge of training distributions. We evaluate our approach on real-world datasets from different domains and show that FedGen results in models that achieve significantly better generalization than current federated learning approaches.
A Case for Business Process-Specific Foundation Models
Oct 26, 2022

The inception of large language models has helped advance state-of-the-art performance on numerous natural language tasks. This has also opened the door for the development of foundation models for other domains and data modalities such as images, code, and music. In this paper, we argue that business process data representations have unique characteristics that warrant the development of a new class of foundation models to handle tasks like process mining, optimization, and decision making. These models should also tackle the unique challenges of applying AI to business processes which include data scarcity, multi-modal representations, domain specific terminology, and privacy concerns.
A No-Code Low-Code Paradigm for Authoring Business Automations Using Natural Language
Jul 15, 2022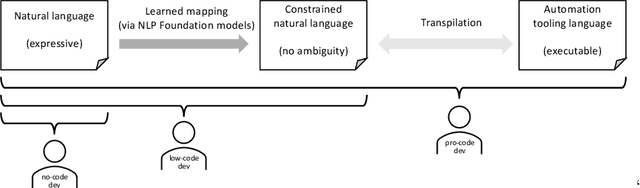
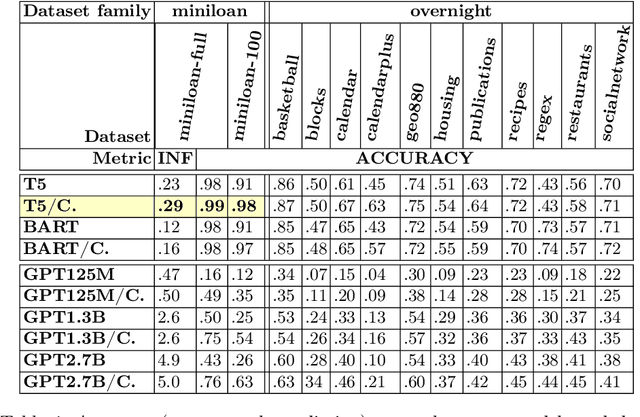


Most business process automation is still developed using traditional automation technologies such as workflow engines. These systems provide domain specific languages that require both business knowledge and programming skills to effectively use. As such, business users often lack adequate programming skills to fully leverage these code oriented environments. We propose a paradigm for the construction of business automations using natural language. The approach applies a large language model to translate business rules and automations described in natural language, into a domain specific language interpretable by a business rule engine. We compare the performance of various language model configurations, across various target domains, and explore the use of constrained decoding to ensure syntactically correct generation of output.
Extending LIME for Business Process Automation
Aug 09, 2021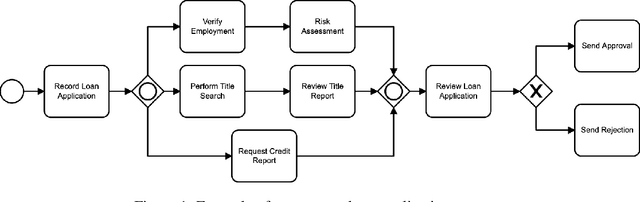

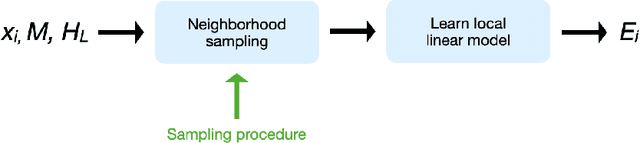
AI business process applications automate high-stakes business decisions where there is an increasing demand to justify or explain the rationale behind algorithmic decisions. Business process applications have ordering or constraints on tasks and feature values that cause lightweight, model-agnostic, existing explanation methods like LIME to fail. In response, we propose a local explanation framework extending LIME for explaining AI business process applications. Empirical evaluation of our extension underscores the advantage of our approach in the business process setting.