 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Individual Counting and Tracking from Moving Drones: A Benchmark and Methods
Jan 18, 2026Counting and tracking dense crowds in large-scale scenes is highly challenging, yet existing methods mainly rely on datasets captured by fixed cameras, which provide limited spatial coverage and are inadequate for large-scale dense crowd analysis. To address this limitation, we propose a flexible solution using moving drones to capture videos and perform video-level crowd counting and tracking of unique pedestrians across entire scenes. We introduce MovingDroneCrowd++, the largest video-level dataset for dense crowd counting and tracking captured by moving drones, covering diverse and complex conditions with varying flight altitudes, camera angles, and illumination. Existing methods fail to achieve satisfactory performance on this dataset. To this end, we propose GD3A (Global Density Map Decomposition via Descriptor Association), a density map-based video individual counting method that avoids explicit localization. GD3A establishes pixel-level correspondences between pedestrian descriptors across consecutive frames via optimal transport with an adaptive dustbin score, enabling the decomposition of global density maps into shared, inflow, and outflow components. Building on this framework, we further introduce DVTrack, which converts descriptor-level matching into instance-level associations through a descriptor voting mechanism for pedestrian tracking. Experimental results show that our methods significantly outperform existing approaches under dense crowds and complex motion, reducing counting error by 47.4 percent and improving tracking performance by 39.2 percent.
Adversarial Distribution Matching for Diffusion Distillation Towards Efficient Image and Video Synthesis
Jul 24, 2025



Distribution Matching Distillation (DMD) is a promising score distillation technique that compresses pre-trained teacher diffusion models into efficient one-step or multi-step student generators. Nevertheless, its reliance on the reverse Kullback-Leibler (KL) divergence minimization potentially induces mode collapse (or mode-seeking) in certain applications. To circumvent this inherent drawback, we propose Adversarial Distribution Matching (ADM), a novel framework that leverages diffusion-based discriminators to align the latent predictions between real and fake score estimators for score distillation in an adversarial manner. In the context of extremely challenging one-step distillation, we further improve the pre-trained generator by adversarial distillation with hybrid discriminators in both latent and pixel spaces. Different from the mean squared error used in DMD2 pre-training, our method incorporates the distributional loss on ODE pairs collected from the teacher model, and thus providing a better initialization for score distillation fine-tuning in the next stage. By combining the adversarial distillation pre-training with ADM fine-tuning into a unified pipeline termed DMDX, our proposed method achieves superior one-step performance on SDXL compared to DMD2 while consuming less GPU time. Additional experiments that apply multi-step ADM distillation on SD3-Medium, SD3.5-Large, and CogVideoX set a new benchmark towards efficient image and video synthesis.
DiffusionEngine: Diffusion Model is Scalable Data Engine for Object Detection
Sep 07, 2023



Data is the cornerstone of deep learning. This paper reveals that the recently developed Diffusion Model is a scalable data engine for object detection. Existing methods for scaling up detection-oriented data often require manual collection or generative models to obtain target images, followed by data augmentation and labeling to produce training pairs, which are costly, complex, or lacking diversity. To address these issues, we presentDiffusionEngine (DE), a data scaling-up engine that provides high-quality detection-oriented training pairs in a single stage. DE consists of a pre-trained diffusion model and an effective Detection-Adapter, contributing to generating scalable, diverse and generalizable detection data in a plug-and-play manner. Detection-Adapter is learned to align the implicit semantic and location knowledge in off-the-shelf diffusion models with detection-aware signals to make better bounding-box predictions. Additionally, we contribute two datasets, i.e., COCO-DE and VOC-DE, to scale up existing detection benchmarks for facilitating follow-up research. Extensive experiments demonstrate that data scaling-up via DE can achieve significant improvements in diverse scenarios, such as various detection algorithms, self-supervised pre-training, data-sparse, label-scarce, cross-domain, and semi-supervised learning. For example, when using DE with a DINO-based adapter to scale up data, mAP is improved by 3.1% on COCO, 7.6% on VOC, and 11.5% on Clipart.
Adversarial Feature Augmentation for Cross-domain Few-shot Classification
Aug 23, 2022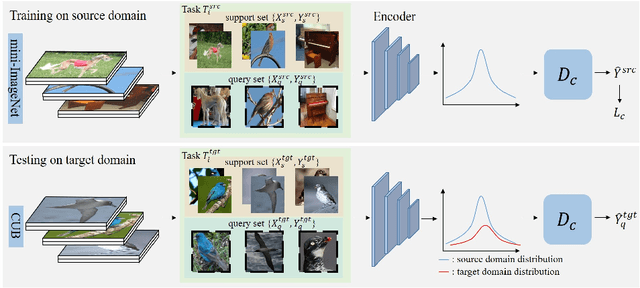
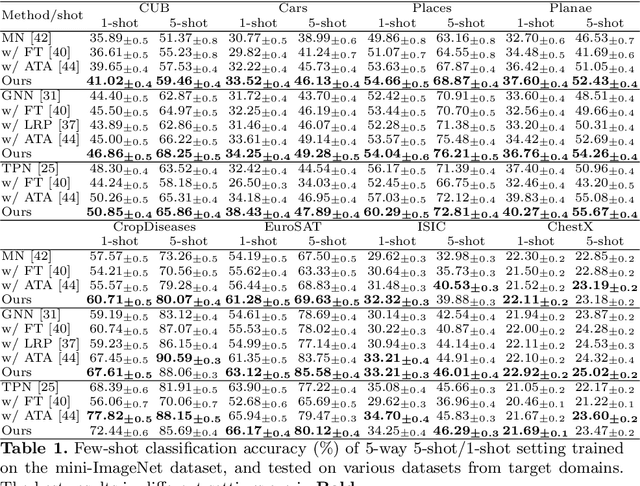
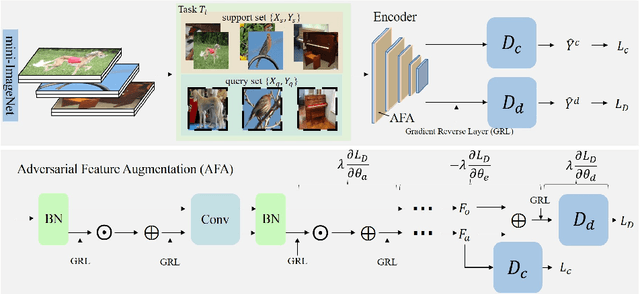
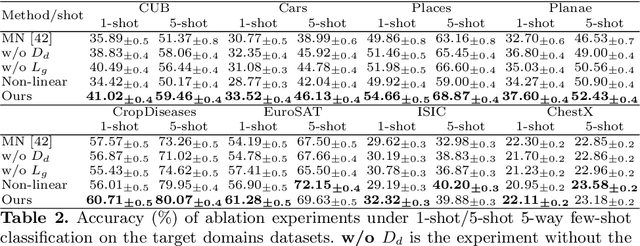
Existing methods based on meta-learning predict novel-class labels for (target domain) testing tasks via meta knowledge learned from (source domain) training tasks of base classes. However, most existing works may fail to generalize to novel classes due to the probably large domain discrepancy across domains. To address this issue, we propose a novel adversarial feature augmentation (AFA) method to bridge the domain gap in few-shot learning. The feature augmentation is designed to simulate distribution variations by maximizing the domain discrepancy. During adversarial training, the domain discriminator is learned by distinguishing the augmented features (unseen domain) from the original ones (seen domain), while the domain discrepancy is minimized to obtain the optimal feature encoder. The proposed method is a plug-and-play module that can be easily integrated into existing few-shot learning methods based on meta-learning. Extensive experiments on nine datasets demonstrate the superiority of our method for cross-domain few-shot classification compared with the state of the art. Code is available at https://github.com/youthhoo/AFA_For_Few_shot_learning
Suppressing Static Visual Cues via Normalizing Flows for Self-Supervised Video Representation Learning
Dec 08, 2021
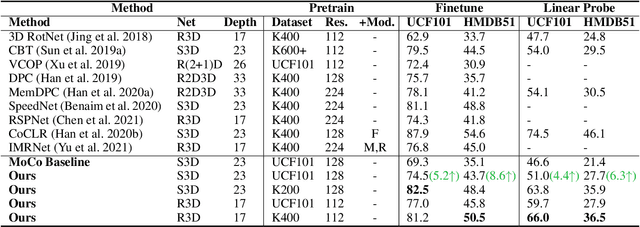

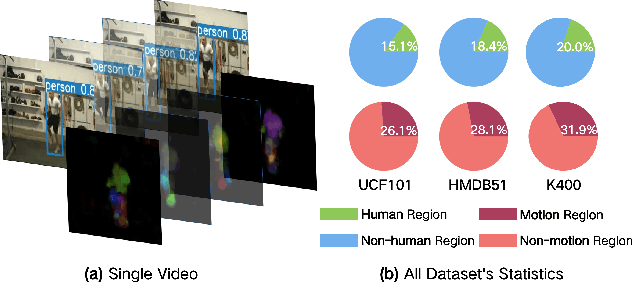
Despite the great progress in video understanding made by deep convolutional neural networks, feature representation learned by existing methods may be biased to static visual cues. To address this issue, we propose a novel method to suppress static visual cues (SSVC) based on probabilistic analysis for self-supervised video representation learning. In our method, video frames are first encoded to obtain latent variables under standard normal distribution via normalizing flows. By modelling static factors in a video as a random variable, the conditional distribution of each latent variable becomes shifted and scaled normal. Then, the less-varying latent variables along time are selected as static cues and suppressed to generate motion-preserved videos. Finally, positive pairs are constructed by motion-preserved videos for contrastive learning to alleviate the problem of representation bias to static cues. The less-biased video representation can be better generalized to various downstream tasks. Extensive experiments on publicly available benchmarks demonstrate that the proposed method outperforms the state of the art when only single RGB modality is used for pre-training.
Removing the Background by Adding the Background: Towards Background Robust Self-supervised Video Representation Learning
Sep 12, 2020
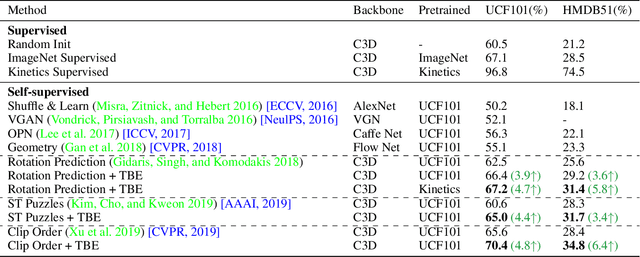
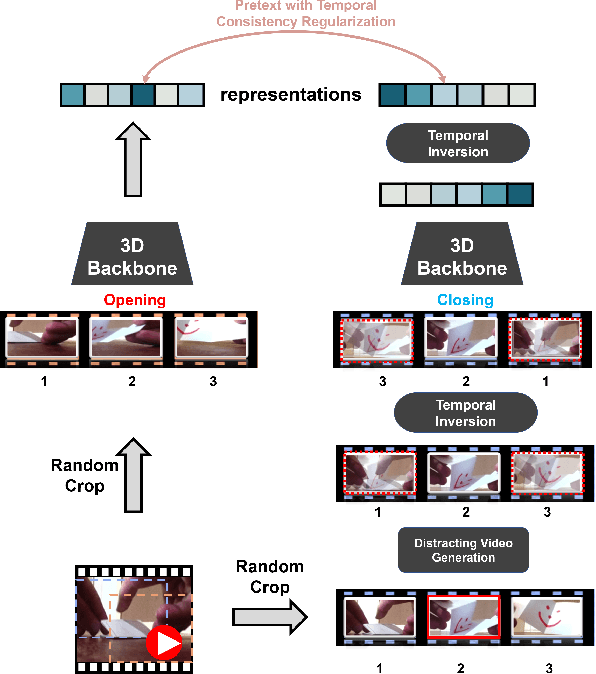
Self-supervised learning has shown great potentials in improving the video representation ability of deep neural networks by constructing surrogate supervision signals from the unlabeled data. However, some of the current methods tend to suffer from a background cheating problem, i.e., the prediction is highly dependent on the video background instead of the motion, making the model vulnerable to background changes. To alleviate the problem, we propose to remove the background impact by adding the background. That is, given a video, we randomly select a static frame and add it to every other frames to construct a distracting video sample. Then we force the model to pull the feature of the distracting video and the feature of the original video closer, so that the model is explicitly restricted to resist the background influence, focusing more on the motion changes. In addition, in order to prevent the static frame from disturbing the motion area too much, we restrict the feature being consistent with the temporally flipped feature of the reversed video, forcing the model to concentrate more on the motion. We term our method as Temporal-sensitive Background Erasing (TBE). Experiments on UCF101 and HMDB51 show that TBE brings about 6.4% and 4.8% improvements over the state-of-the-art method on the HMDB51 and UCF101 datasets respectively. And it is worth noting that the implementation of our method is so simple and neat and can be added as an additional regularization term to most of the SOTA methods without much efforts.
Self-supervised Temporal Discriminative Learning for Video Representation Learning
Aug 05, 2020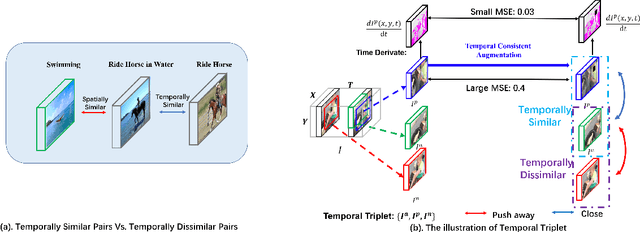
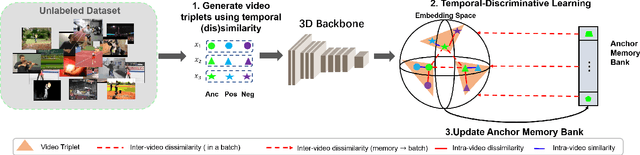
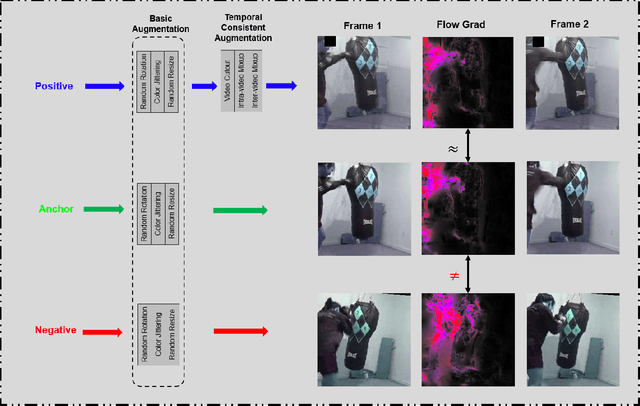
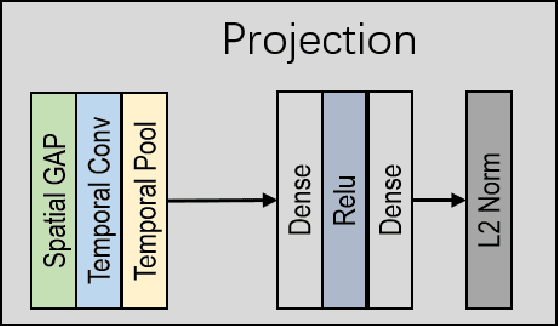
Temporal cues in videos provide important information for recognizing actions accurately. However, temporal-discriminative features can hardly be extracted without using an annotated large-scale video action dataset for training. This paper proposes a novel Video-based Temporal-Discriminative Learning (VTDL) framework in self-supervised manner. Without labelled data for network pretraining, temporal triplet is generated for each anchor video by using segment of the same or different time interval so as to enhance the capacity for temporal feature representation. Measuring temporal information by time derivative, Temporal Consistent Augmentation (TCA) is designed to ensure that the time derivative (in any order) of the augmented positive is invariant except for a scaling constant. Finally, temporal-discriminative features are learnt by minimizing the distance between each anchor and its augmented positive, while the distance between each anchor and its augmented negative as well as other videos saved in the memory bank is maximized to enrich the representation diversity. In the downstream action recognition task, the proposed method significantly outperforms existing related works. Surprisingly, the proposed self-supervised approach is better than fully-supervised methods on UCF101 and HMDB51 when a small-scale video dataset (with only thousands of videos) is used for pre-training. The code has been made publicly available on https://github.com/FingerRec/Self-Supervised-Temporal-Discriminative-Representation-Learning-for-Video-Action-Recognition.
Self-supervised learning using consistency regularization of spatio-temporal data augmentation for action recognition
Aug 05, 2020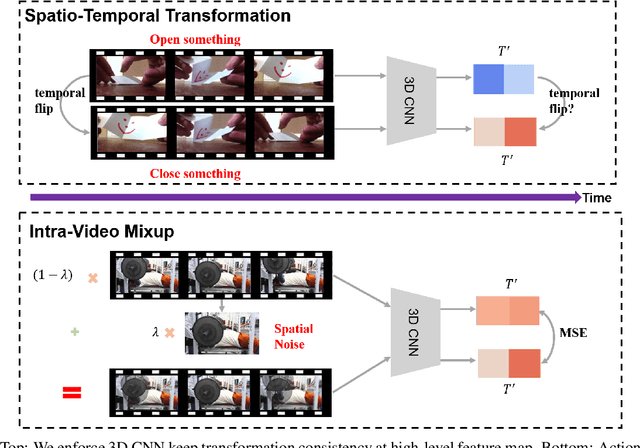

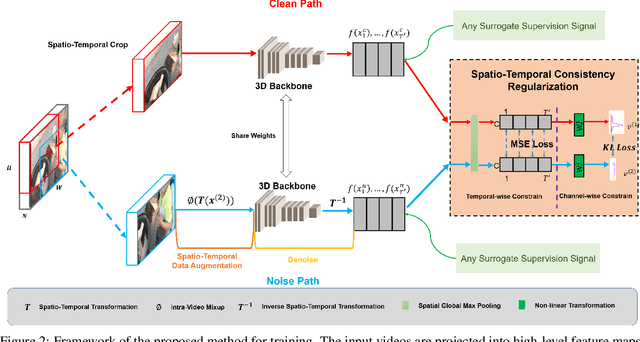
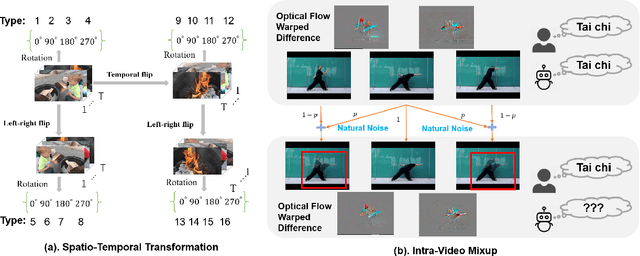
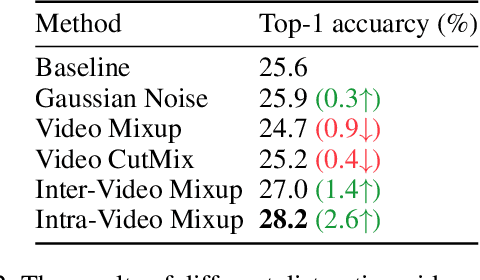
Self-supervised learning has shown great potentials in improving the deep learning model in an unsupervised manner by constructing surrogate supervision signals directly from the unlabeled data. Different from existing works, we present a novel way to obtain the surrogate supervision signal based on high-level feature maps under consistency regularization. In this paper, we propose a Spatio-Temporal Consistency Regularization between different output features generated from a siamese network including a clean path fed with original video and a noise path fed with the corresponding augmented video. Based on the Spatio-Temporal characteristics of video, we develop two video-based data augmentation methods, i.e., Spatio-Temporal Transformation and Intra-Video Mixup. Consistency of the former one is proposed to model transformation consistency of features, while the latter one aims at retaining spatial invariance to extract action-related features. Extensive experiments demonstrate that our method achieves substantial improvements compared with state-of-the-art self-supervised learning methods for action recognition. When using our method as an additional regularization term and combine with current surrogate supervision signals, we achieve 22% relative improvement over the previous state-of-the-art on HMDB51 and 7% on UCF101.