 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Text Injection to Improve Recognition of Personal Identifiers in Speech
Aug 14, 2023



Accurate recognition of specific categories, such as persons' names, dates or other identifiers is critical in many Automatic Speech Recognition (ASR) applications. As these categories represent personal information, ethical use of this data including collection, transcription, training and evaluation demands special care. One way of ensuring the security and privacy of individuals is to redact or eliminate Personally Identifiable Information (PII) from collection altogether. However, this results in ASR models that tend to have lower recognition accuracy of these categories. We use text-injection to improve the recognition of PII categories by including fake textual substitutes of PII categories in the training data using a text injection method. We demonstrate substantial improvement to Recall of Names and Dates in medical notes while improving overall WER. For alphanumeric digit sequences we show improvements to Character Error Rate and Sentence Accuracy.
Improving Joint Speech-Text Representations Without Alignment
Aug 11, 2023



The last year has seen astonishing progress in text-prompted image generation premised on the idea of a cross-modal representation space in which the text and image domains are represented jointly. In ASR, this idea has found application as joint speech-text encoders that can scale to the capacities of very large parameter models by being trained on both unpaired speech and text. While these methods show promise, they have required special treatment of the sequence-length mismatch inherent in speech and text, either by up-sampling heuristics or an explicit alignment model. In this work, we offer evidence that joint speech-text encoders naturally achieve consistent representations across modalities by disregarding sequence length, and argue that consistency losses could forgive length differences and simply assume the best alignment. We show that such a loss improves downstream WER in both a large-parameter monolingual and multilingual system.
Understanding Shared Speech-Text Representations
Apr 27, 2023Recently, a number of approaches to train speech models by incorpo-rating text into end-to-end models have been developed, with Mae-stro advancing state-of-the-art automatic speech recognition (ASR)and Speech Translation (ST) performance. In this paper, we expandour understanding of the resulting shared speech-text representationswith two types of analyses. First we examine the limits of speech-free domain adaptation, finding that a corpus-specific duration modelfor speech-text alignment is the most important component for learn-ing a shared speech-text representation. Second, we inspect the sim-ilarities between activations of unimodal (speech or text) encodersas compared to the activations of a shared encoder. We find that theshared encoder learns a more compact and overlapping speech-textrepresentation than the uni-modal encoders. We hypothesize that thispartially explains the effectiveness of the Maestro shared speech-textrepresentations.
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
Mar 03, 2023
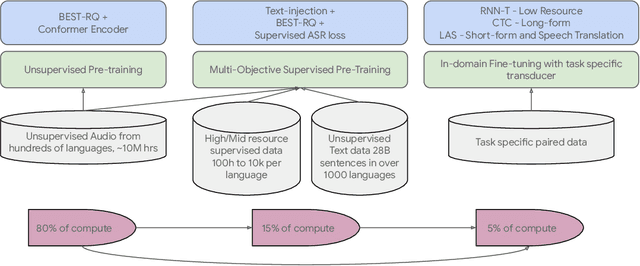
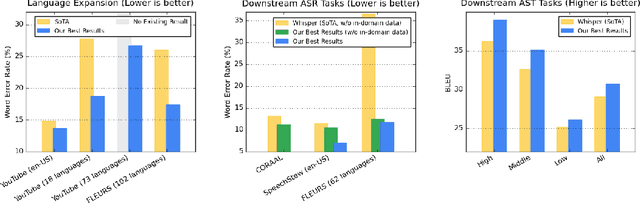

We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages.
JEIT: Joint End-to-End Model and Internal Language Model Training for Speech Recognition
Feb 16, 2023



We propose JEIT, a joint end-to-end (E2E) model and internal language model (ILM) training method to inject large-scale unpaired text into ILM during E2E training which improves rare-word speech recognition. With JEIT, the E2E model computes an E2E loss on audio-transcript pairs while its ILM estimates a cross-entropy loss on unpaired text. The E2E model is trained to minimize a weighted sum of E2E and ILM losses. During JEIT, ILM absorbs knowledge from unpaired text while the E2E training serves as regularization. Unlike ILM adaptation methods, JEIT does not require a separate adaptation step and avoids the need for Kullback-Leibler divergence regularization of ILM. We also show that modular hybrid autoregressive transducer (MHAT) performs better than HAT in the JEIT framework, and is much more robust than HAT during ILM adaptation. To push the limit of unpaired text injection, we further propose a combined JEIT and JOIST training (CJJT) that benefits from modality matching, encoder text injection and ILM training. Both JEIT and CJJT can foster a more effective LM fusion. With 100B unpaired sentences, JEIT/CJJT improves rare-word recognition accuracy by up to 16.4% over a model trained without unpaired text.
* 5 pages, 3 figures, in ICASSP 2023
Virtuoso: Massive Multilingual Speech-Text Joint Semi-Supervised Learning for Text-To-Speech
Oct 27, 2022



This paper proposes Virtuoso, a massively multilingual speech-text joint semi-supervised learning framework for text-to-speech synthesis (TTS) models. Existing multilingual TTS typically supports tens of languages, which are a small fraction of the thousands of languages in the world. One difficulty to scale multilingual TTS to hundreds of languages is collecting high-quality speech-text paired data in low-resource languages. This study extends Maestro, a speech-text joint pretraining framework for automatic speech recognition (ASR), to speech generation tasks. To train a TTS model from various types of speech and text data, different training schemes are designed to handle supervised (paired TTS and ASR data) and unsupervised (untranscribed speech and unspoken text) datasets. Experimental evaluation shows that 1) multilingual TTS models trained on Virtuoso can achieve significantly better naturalness and intelligibility than baseline ones in seen languages, and 2) they can synthesize reasonably intelligible and naturally sounding speech for unseen languages where no high-quality paired TTS data is available.
G-Augment: Searching For The Meta-Structure Of Data Augmentation Policies For ASR
Oct 19, 2022
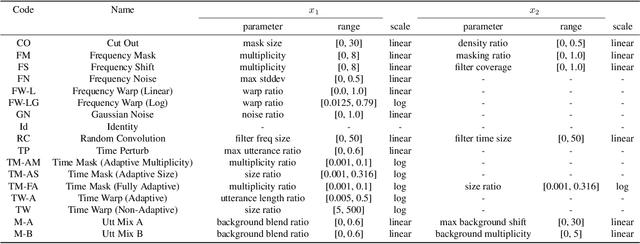
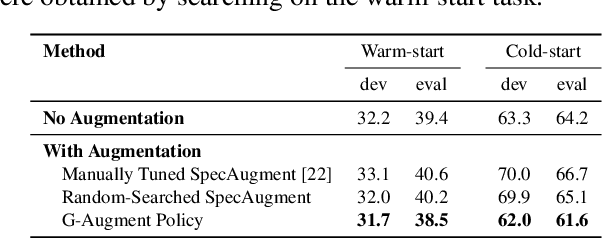
Data augmentation is a ubiquitous technique used to provide robustness to automatic speech recognition (ASR) training. However, even as so much of the ASR training process has become automated and more "end-to-end", the data augmentation policy (what augmentation functions to use, and how to apply them) remains hand-crafted. We present Graph-Augment, a technique to define the augmentation space as directed acyclic graphs (DAGs) and search over this space to optimize the augmentation policy itself. We show that given the same computational budget, policies produced by G-Augment are able to perform better than SpecAugment policies obtained by random search on fine-tuning tasks on CHiME-6 and AMI. G-Augment is also able to establish a new state-of-the-art ASR performance on the CHiME-6 evaluation set (30.7% WER). We further demonstrate that G-Augment policies show better transfer properties across warm-start to cold-start training and model size compared to random-searched SpecAugment policies.
Maestro-U: Leveraging joint speech-text representation learning for zero supervised speech ASR
Oct 18, 2022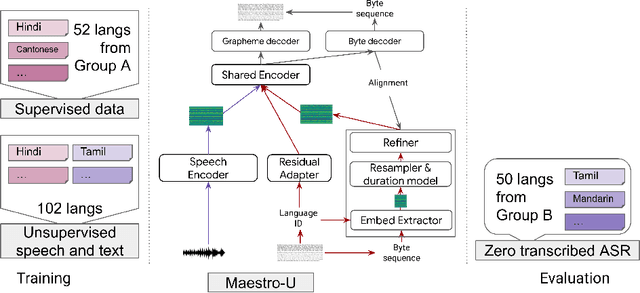
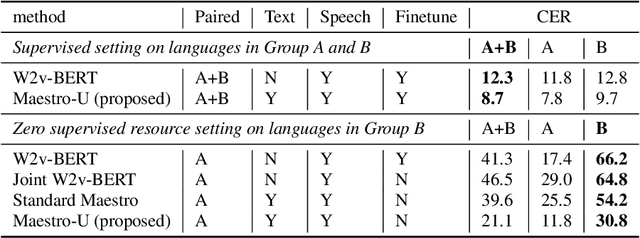
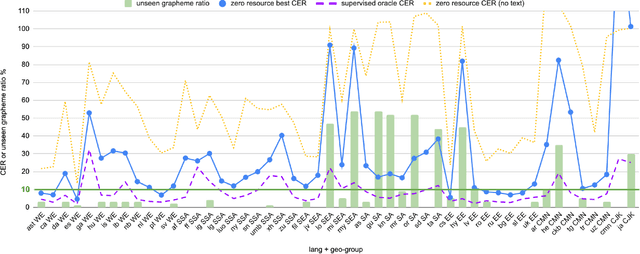
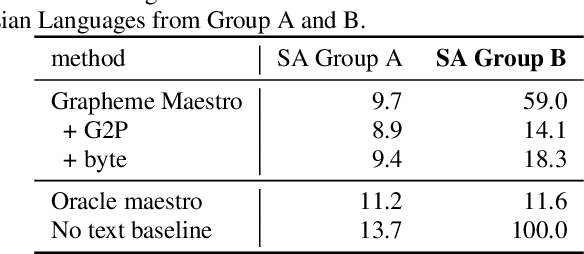
Training state-of-the-art Automated Speech Recognition (ASR) models typically requires a substantial amount of transcribed speech. In this work, we demonstrate that a modality-matched joint speech and text model can be leveraged to train a massively multilingual ASR model without any supervised (manually transcribed) speech for some languages. This paper explores the use of jointly learnt speech and text representations in a massively multilingual, zero supervised speech, real-world setting to expand the set of languages covered by ASR with only unlabeled speech and text in the target languages. Using the FLEURS dataset, we define the task to cover $102$ languages, where transcribed speech is available in $52$ of these languages and can be used to improve end-to-end ASR quality on the remaining $50$. First, we show that by combining speech representations with byte-level text representations and use of language embeddings, we can dramatically reduce the Character Error Rate (CER) on languages with no supervised speech from 64.8\% to 30.8\%, a relative reduction of 53\%. Second, using a subset of South Asian languages we show that Maestro-U can promote knowledge transfer from languages with supervised speech even when there is limited to no graphemic overlap. Overall, Maestro-U closes the gap to oracle performance by 68.5\% relative and reduces the CER of 19 languages below 15\%.
Non-Parallel Voice Conversion for ASR Augmentation
Sep 15, 2022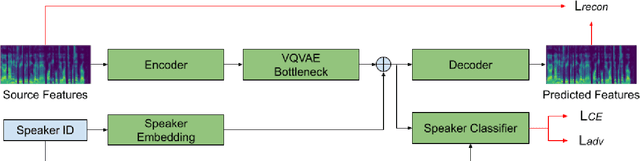
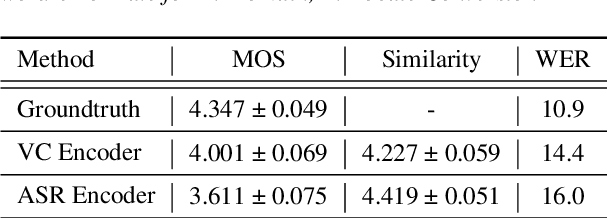
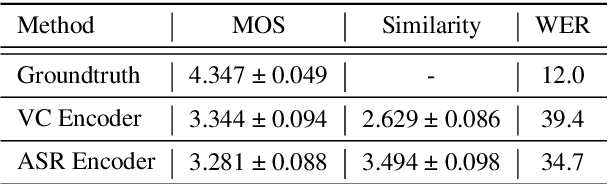
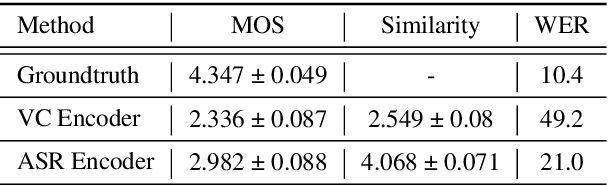
Automatic speech recognition (ASR) needs to be robust to speaker differences. Voice Conversion (VC) modifies speaker characteristics of input speech. This is an attractive feature for ASR data augmentation. In this paper, we demonstrate that voice conversion can be used as a data augmentation technique to improve ASR performance, even on LibriSpeech, which contains 2,456 speakers. For ASR augmentation, it is necessary that the VC model be robust to a wide range of input speech. This motivates the use of a non-autoregressive, non-parallel VC model, and the use of a pretrained ASR encoder within the VC model. This work suggests that despite including many speakers, speaker diversity may remain a limitation to ASR quality. Finally, interrogation of our VC performance has provided useful metrics for objective evaluation of VC quality.
Accented Speech Recognition: Benchmarking, Pre-training, and Diverse Data
May 16, 2022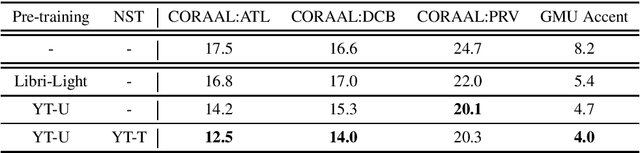

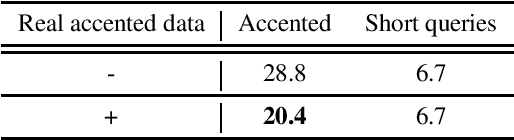
Building inclusive speech recognition systems is a crucial step towards developing technologies that speakers of all language varieties can use. Therefore, ASR systems must work for everybody independently of the way they speak. To accomplish this goal, there should be available data sets representing language varieties, and also an understanding of model configuration that is the most helpful in achieving robust understanding of all types of speech. However, there are not enough data sets for accented speech, and for the ones that are already available, more training approaches need to be explored to improve the quality of accented speech recognition. In this paper, we discuss recent progress towards developing more inclusive ASR systems, namely, the importance of building new data sets representing linguistic diversity, and exploring novel training approaches to improve performance for all users. We address recent directions within benchmarking ASR systems for accented speech, measure the effects of wav2vec 2.0 pre-training on accented speech recognition, and highlight corpora relevant for diverse ASR evaluations.