 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInducing and Using Alignments for Transition-based AMR Parsing
May 03, 2022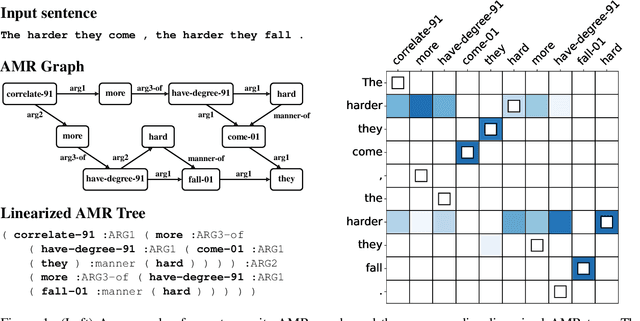
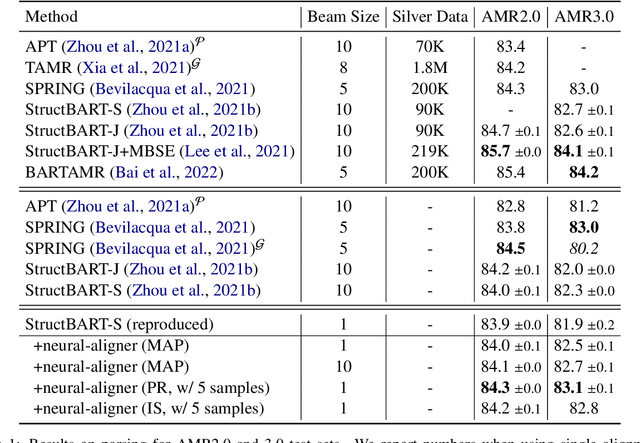
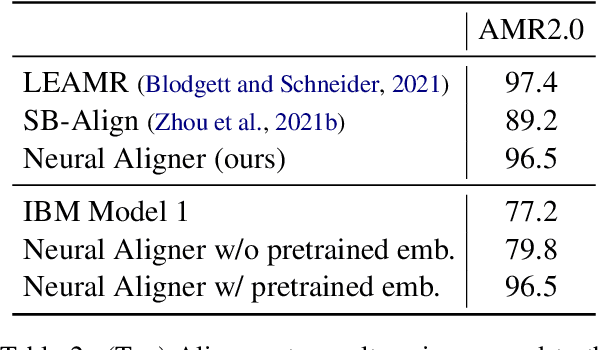
Transition-based parsers for Abstract Meaning Representation (AMR) rely on node-to-word alignments. These alignments are learned separately from parser training and require a complex pipeline of rule-based components, pre-processing, and post-processing to satisfy domain-specific constraints. Parsers also train on a point-estimate of the alignment pipeline, neglecting the uncertainty due to the inherent ambiguity of alignment. In this work we explore two avenues for overcoming these limitations. First, we propose a neural aligner for AMR that learns node-to-word alignments without relying on complex pipelines. We subsequently explore a tighter integration of aligner and parser training by considering a distribution over oracle action sequences arising from aligner uncertainty. Empirical results show this approach leads to more accurate alignments and generalization better from the AMR2.0 to AMR3.0 corpora. We attain a new state-of-the art for gold-only trained models, matching silver-trained performance without the need for beam search on AMR3.0.
CBR-iKB: A Case-Based Reasoning Approach for Question Answering over Incomplete Knowledge Bases
Apr 18, 2022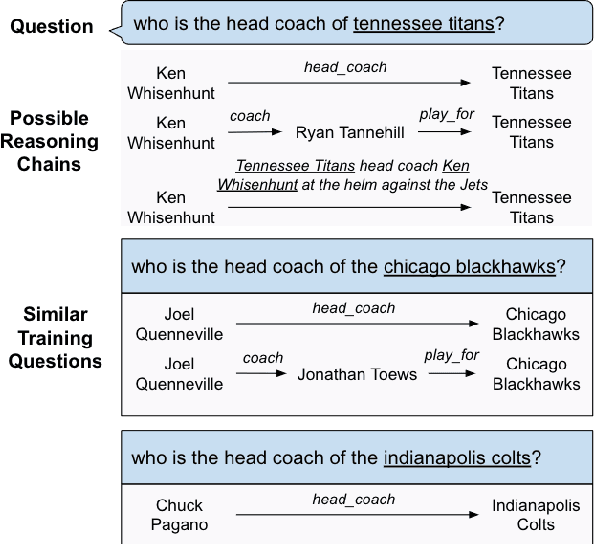
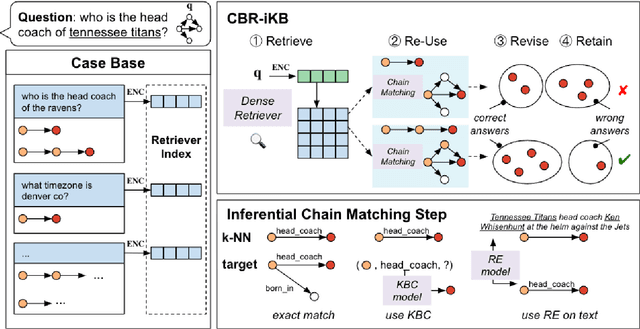
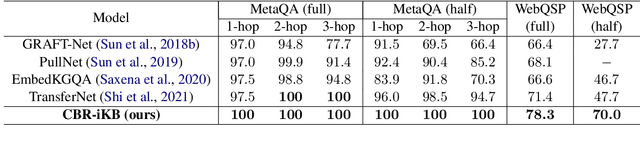
Knowledge bases (KBs) are often incomplete and constantly changing in practice. Yet, in many question answering applications coupled with knowledge bases, the sparse nature of KBs is often overlooked. To this end, we propose a case-based reasoning approach, CBR-iKB, for knowledge base question answering (KBQA) with incomplete-KB as our main focus. Our method ensembles decisions from multiple reasoning chains with a novel nonparametric reasoning algorithm. By design, CBR-iKB can seamlessly adapt to changes in KBs without any task-specific training or fine-tuning. Our method achieves 100% accuracy on MetaQA and establishes new state-of-the-art on multiple benchmarks. For instance, CBR-iKB achieves an accuracy of 70% on WebQSP under the incomplete-KB setting, outperforming the existing state-of-the-art method by 22.3%.
A Distant Supervision Corpus for Extracting Biomedical Relationships Between Chemicals, Diseases and Genes
Apr 13, 2022
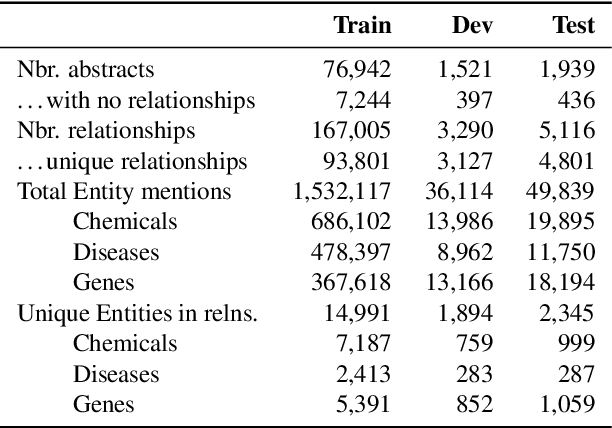

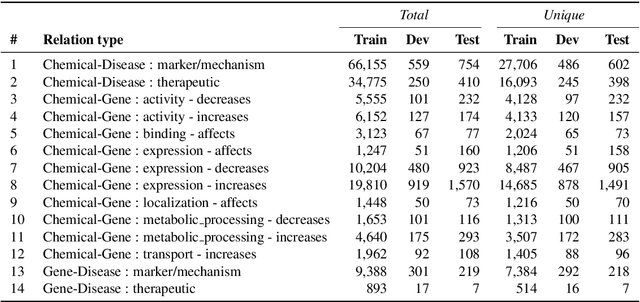
We introduce ChemDisGene, a new dataset for training and evaluating multi-class multi-label document-level biomedical relation extraction models. Our dataset contains 80k biomedical research abstracts labeled with mentions of chemicals, diseases, and genes, portions of which human experts labeled with 18 types of biomedical relationships between these entities (intended for evaluation), and the remainder of which (intended for training) has been distantly labeled via the CTD database with approximately 78\% accuracy. In comparison to similar preexisting datasets, ours is both substantially larger and cleaner; it also includes annotations linking mentions to their entities. We also provide three baseline deep neural network relation extraction models trained and evaluated on our new dataset.
Knowledge Base Question Answering by Case-based Reasoning over Subgraphs
Feb 22, 2022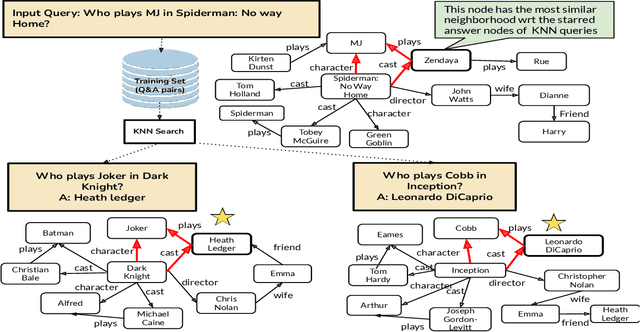
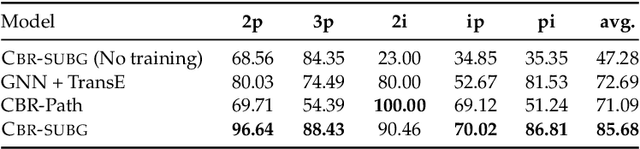
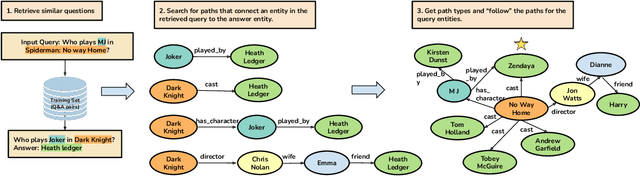
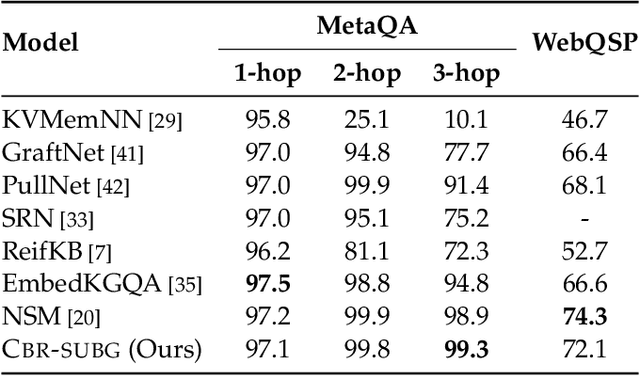
Question answering (QA) over real-world knowledge bases (KBs) is challenging because of the diverse (essentially unbounded) types of reasoning patterns needed. However, we hypothesize in a large KB, reasoning patterns required to answer a query type reoccur for various entities in their respective subgraph neighborhoods. Leveraging this structural similarity between local neighborhoods of different subgraphs, we introduce a semiparametric model with (i) a nonparametric component that for each query, dynamically retrieves other similar $k$-nearest neighbor (KNN) training queries along with query-specific subgraphs and (ii) a parametric component that is trained to identify the (latent) reasoning patterns from the subgraphs of KNN queries and then apply it to the subgraph of the target query. We also propose a novel algorithm to select a query-specific compact subgraph from within the massive knowledge graph (KG), allowing us to scale to full Freebase KG containing billions of edges. We show that our model answers queries requiring complex reasoning patterns more effectively than existing KG completion algorithms. The proposed model outperforms or performs competitively with state-of-the-art models on several KBQA benchmarks.
Sublinear Time Approximation of Text Similarity Matrices
Dec 17, 2021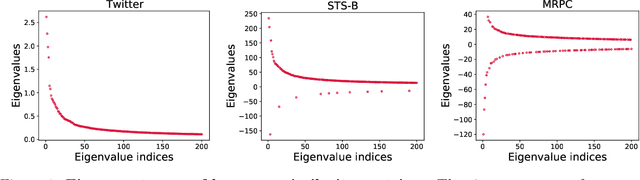
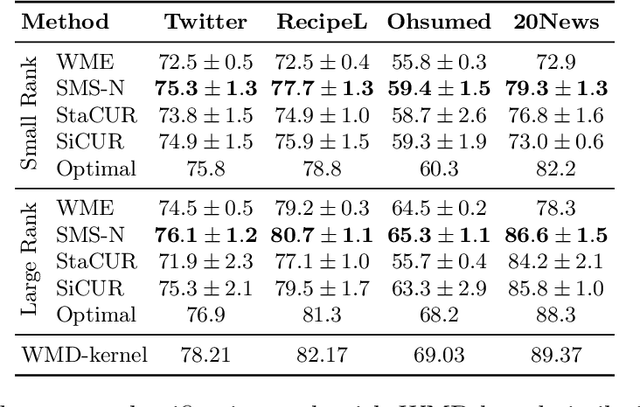
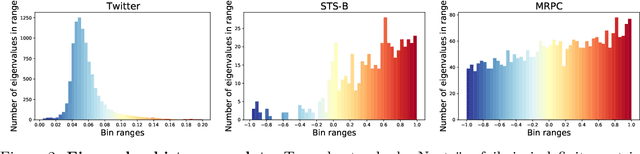
We study algorithms for approximating pairwise similarity matrices that arise in natural language processing. Generally, computing a similarity matrix for $n$ data points requires $\Omega(n^2)$ similarity computations. This quadratic scaling is a significant bottleneck, especially when similarities are computed via expensive functions, e.g., via transformer models. Approximation methods reduce this quadratic complexity, often by using a small subset of exactly computed similarities to approximate the remainder of the complete pairwise similarity matrix. Significant work focuses on the efficient approximation of positive semidefinite (PSD) similarity matrices, which arise e.g., in kernel methods. However, much less is understood about indefinite (non-PSD) similarity matrices, which often arise in NLP. Motivated by the observation that many of these matrices are still somewhat close to PSD, we introduce a generalization of the popular Nystr\"{o}m method to the indefinite setting. Our algorithm can be applied to any similarity matrix and runs in sublinear time in the size of the matrix, producing a rank-$s$ approximation with just $O(ns)$ similarity computations. We show that our method, along with a simple variant of CUR decomposition, performs very well in approximating a variety of similarity matrices arising in NLP tasks. We demonstrate high accuracy of the approximated similarity matrices in the downstream tasks of document classification, sentence similarity, and cross-document coreference.
Diverse Distributions of Self-Supervised Tasks for Meta-Learning in NLP
Nov 02, 2021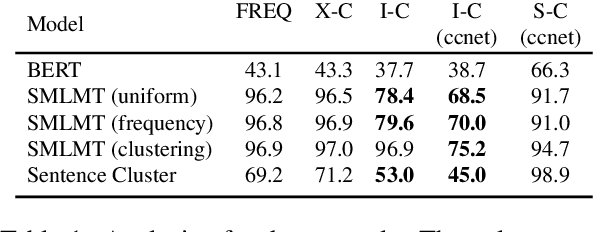
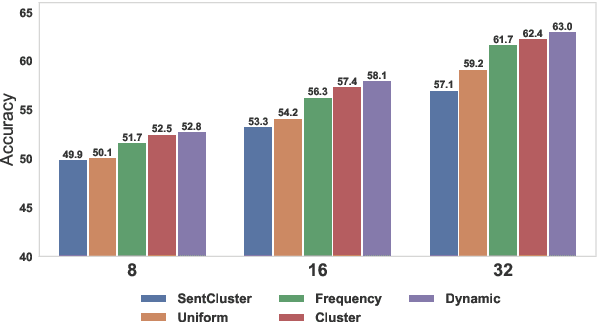
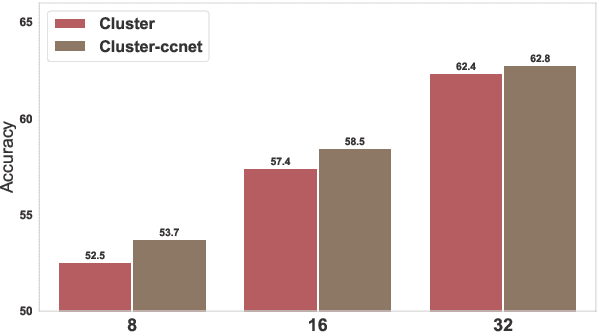
Meta-learning considers the problem of learning an efficient learning process that can leverage its past experience to accurately solve new tasks. However, the efficacy of meta-learning crucially depends on the distribution of tasks available for training, and this is often assumed to be known a priori or constructed from limited supervised datasets. In this work, we aim to provide task distributions for meta-learning by considering self-supervised tasks automatically proposed from unlabeled text, to enable large-scale meta-learning in NLP. We design multiple distributions of self-supervised tasks by considering important aspects of task diversity, difficulty, type, domain, and curriculum, and investigate how they affect meta-learning performance. Our analysis shows that all these factors meaningfully alter the task distribution, some inducing significant improvements in downstream few-shot accuracy of the meta-learned models. Empirically, results on 20 downstream tasks show significant improvements in few-shot learning -- adding up to +4.2% absolute accuracy (on average) to the previous unsupervised meta-learning method, and perform comparably to supervised methods on the FewRel 2.0 benchmark.
A Dataset for Discourse Structure in Peer Review Discussions
Oct 16, 2021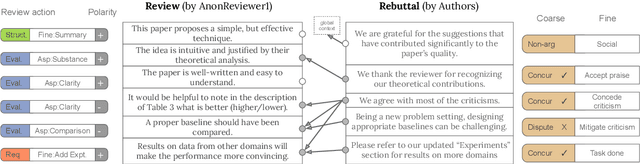
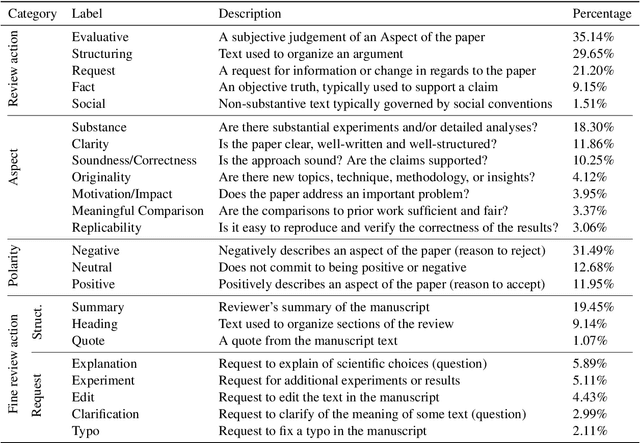

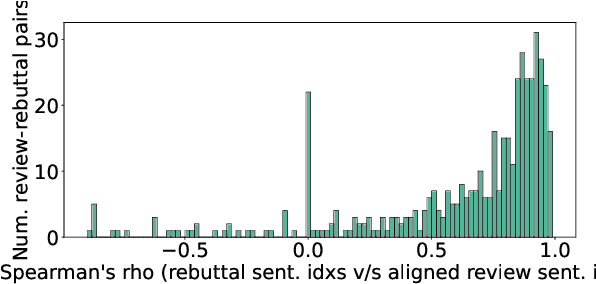
At the foundation of scientific evaluation is the labor-intensive process of peer review. This critical task requires participants to consume and interpret vast amounts of highly technical text. We show that discourse cues from rebuttals can shed light on the quality and interpretation of reviews. Further, an understanding of the argumentative strategies employed by the reviewers and authors provides useful signal for area chairs and other decision makers. This paper presents a new labeled dataset of 20k sentences contained in 506 review-rebuttal pairs in English, annotated by experts. While existing datasets annotate a subset of review sentences using various schemes, ours synthesizes existing label sets and extends them to include fine-grained annotation of the rebuttal sentences, characterizing the authors' stance towards the reviewers' criticisms and their commitment to addressing them. Further, we annotate \textit{every} sentence in both the review and the rebuttal, including a description of the context for each rebuttal sentence.
Improved Latent Tree Induction with Distant Supervision via Span Constraints
Sep 10, 2021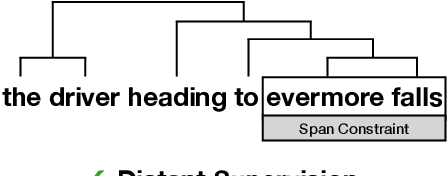

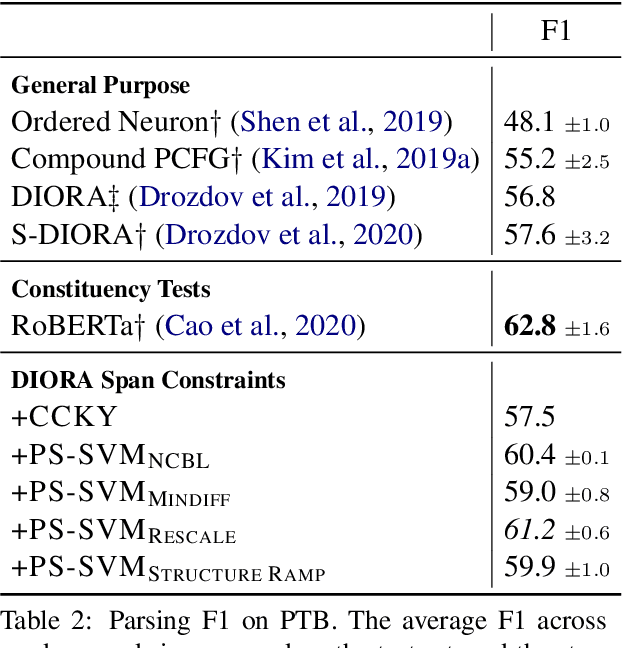
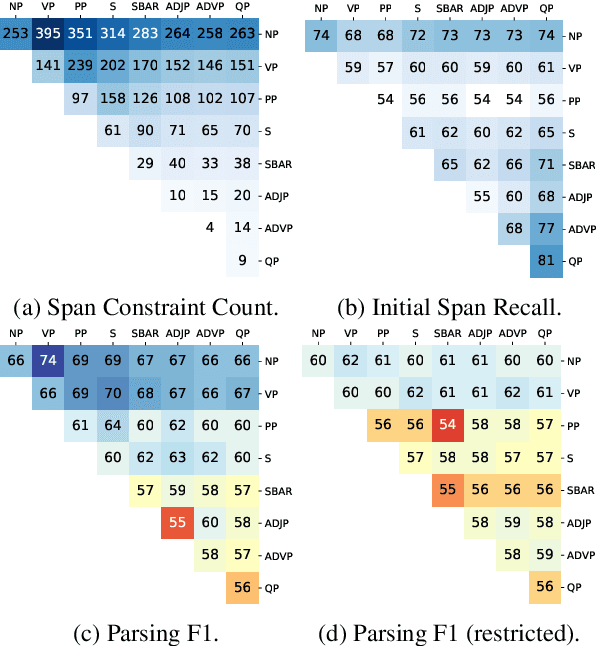
For over thirty years, researchers have developed and analyzed methods for latent tree induction as an approach for unsupervised syntactic parsing. Nonetheless, modern systems still do not perform well enough compared to their supervised counterparts to have any practical use as structural annotation of text. In this work, we present a technique that uses distant supervision in the form of span constraints (i.e. phrase bracketing) to improve performance in unsupervised constituency parsing. Using a relatively small number of span constraints we can substantially improve the output from DIORA, an already competitive unsupervised parsing system. Compared with full parse tree annotation, span constraints can be acquired with minimal effort, such as with a lexicon derived from Wikipedia, to find exact text matches. Our experiments show span constraints based on entities improves constituency parsing on English WSJ Penn Treebank by more than 5 F1. Furthermore, our method extends to any domain where span constraints are easily attainable, and as a case study we demonstrate its effectiveness by parsing biomedical text from the CRAFT dataset.
Box Embeddings: An open-source library for representation learning using geometric structures
Sep 10, 2021
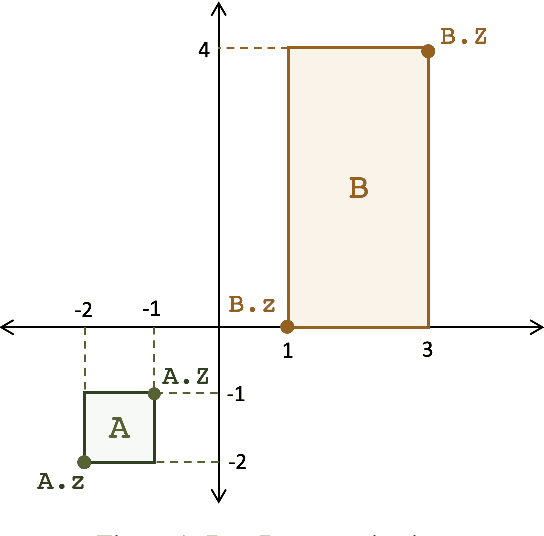
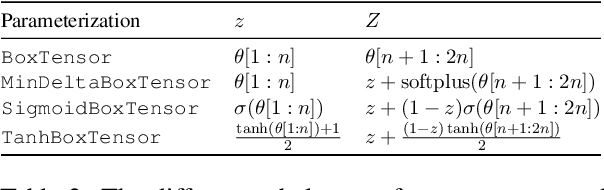
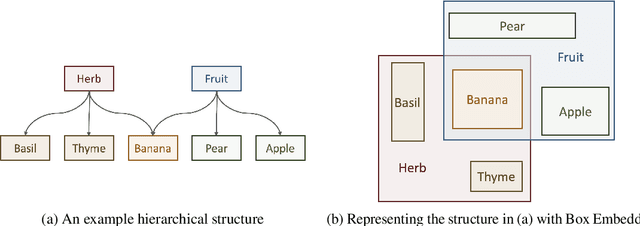
A major factor contributing to the success of modern representation learning is the ease of performing various vector operations. Recently, objects with geometric structures (eg. distributions, complex or hyperbolic vectors, or regions such as cones, disks, or boxes) have been explored for their alternative inductive biases and additional representational capacities. In this work, we introduce Box Embeddings, a Python library that enables researchers to easily apply and extend probabilistic box embeddings.
Entity Linking and Discovery via Arborescence-based Supervised Clustering
Sep 02, 2021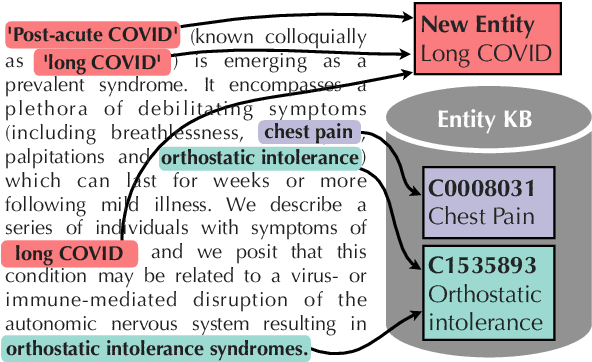
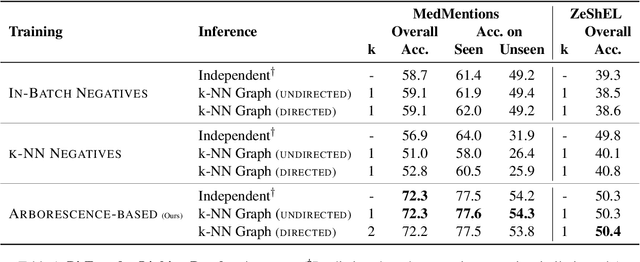
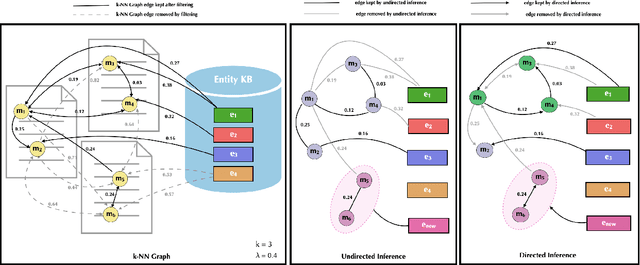

Previous work has shown promising results in performing entity linking by measuring not only the affinities between mentions and entities but also those amongst mentions. In this paper, we present novel training and inference procedures that fully utilize mention-to-mention affinities by building minimum arborescences (i.e., directed spanning trees) over mentions and entities across documents in order to make linking decisions. We also show that this method gracefully extends to entity discovery, enabling the clustering of mentions that do not have an associated entity in the knowledge base. We evaluate our approach on the Zero-Shot Entity Linking dataset and MedMentions, the largest publicly available biomedical dataset, and show significant improvements in performance for both entity linking and discovery compared to identically parameterized models. We further show significant efficiency improvements with only a small loss in accuracy over previous work, which use more computationally expensive models.