 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaTT: A Global Tensor-Train Adapter for Parameter-Efficient Fine-Tuning
Jun 10, 2025



We present MetaTT, a unified Tensor Train (TT) adapter framework for global low-rank fine-tuning of pre-trained transformers. Unlike LoRA, which fine-tunes each weight matrix independently, MetaTT uses a single shared TT to factorize all transformer sub-modules -- query, key, value, projection, and feed-forward layers -- by indexing the structural axes like layer and matrix type, and optionally heads and tasks. For a given rank, while LoRA adds parameters proportional to the product across modes, MetaTT only adds parameters proportional to the sum across modes leading to a significantly compressed final adapter. Our benchmarks compare MetaTT with LoRA along with recent state-of-the-art matrix and tensor decomposition based fine-tuning schemes. We observe that when tested on standard language modeling benchmarks, MetaTT leads to the most reduction in the parameters while maintaining similar accuracy to LoRA and even outperforming other tensor-based methods. Unlike CP or other rank-factorizations, the TT ansatz benefits from mature optimization routines -- e.g., DMRG-style rank adaptive minimization in addition to Adam, which we find simplifies training. Because new modes can be appended cheaply, MetaTT naturally extends to shared adapters across many tasks without redesigning the core tensor.
A Unified Framework for Provably Efficient Algorithms to Estimate Shapley Values
Jun 05, 2025Shapley values have emerged as a critical tool for explaining which features impact the decisions made by machine learning models. However, computing exact Shapley values is difficult, generally requiring an exponential (in the feature dimension) number of model evaluations. To address this, many model-agnostic randomized estimators have been developed, the most influential and widely used being the KernelSHAP method (Lundberg & Lee, 2017). While related estimators such as unbiased KernelSHAP (Covert & Lee, 2021) and LeverageSHAP (Musco & Witter, 2025) are known to satisfy theoretical guarantees, bounds for KernelSHAP have remained elusive. We describe a broad and unified framework that encompasses KernelSHAP and related estimators constructed using both with and without replacement sampling strategies. We then prove strong non-asymptotic theoretical guarantees that apply to all estimators from our framework. This provides, to the best of our knowledge, the first theoretical guarantees for KernelSHAP and sheds further light on tradeoffs between existing estimators. Through comprehensive benchmarking on small and medium dimensional datasets for Decision-Tree models, we validate our approach against exact Shapley values, consistently achieving low mean squared error with modest sample sizes. Furthermore, we make specific implementation improvements to enable scalability of our methods to high-dimensional datasets. Our methods, tested on datasets such MNIST and CIFAR10, provide consistently better results compared to the KernelSHAP library.
Provably faster randomized and quantum algorithms for k-means clustering via uniform sampling
Apr 29, 2025
The $k$-means algorithm (Lloyd's algorithm) is a widely used method for clustering unlabeled data. A key bottleneck of the $k$-means algorithm is that each iteration requires time linear in the number of data points, which can be expensive in big data applications. This was improved in recent works proposing quantum and quantum-inspired classical algorithms to approximate the $k$-means algorithm locally, in time depending only logarithmically on the number of data points (along with data dependent parameters) [$q$-means: A quantum algorithm for unsupervised machine learning; Kerenidis, Landman, Luongo, and Prakash, NeurIPS 2019; Do you know what $q$-means?, Doriguello, Luongo, Tang]. In this work, we describe a simple randomized mini-batch $k$-means algorithm and a quantum algorithm inspired by the classical algorithm. We prove worse-case guarantees that significantly improve upon the bounds for previous algorithms. Our improvements are due to a careful use of uniform sampling, which preserves certain symmetries of the $k$-means problem that are not preserved in previous algorithms that use data norm-based sampling.
Sublinear Time Approximation of Text Similarity Matrices
Dec 17, 2021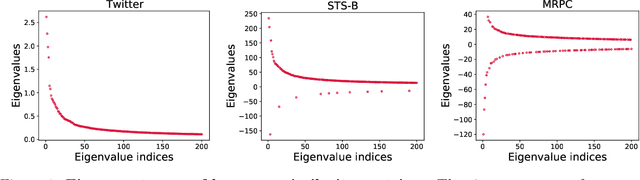
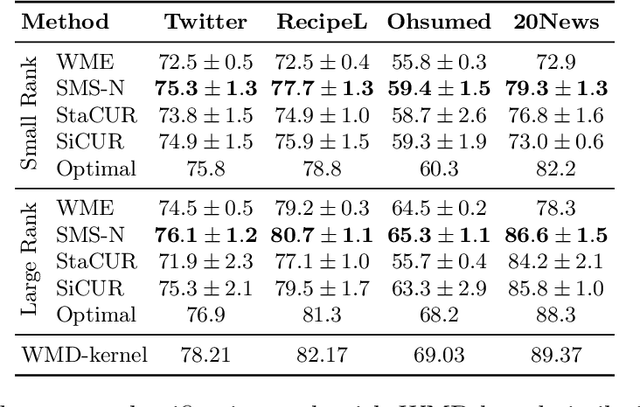
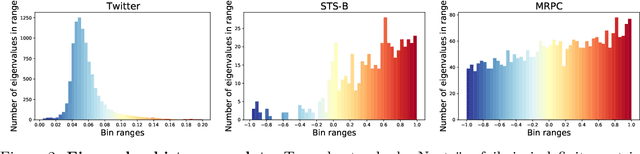
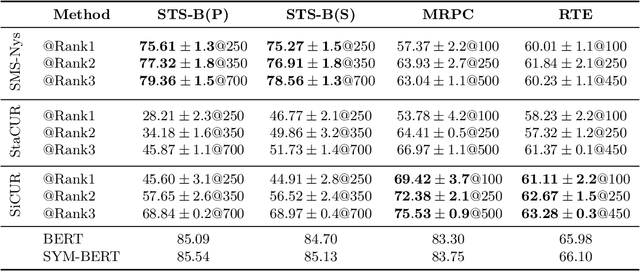
We study algorithms for approximating pairwise similarity matrices that arise in natural language processing. Generally, computing a similarity matrix for $n$ data points requires $\Omega(n^2)$ similarity computations. This quadratic scaling is a significant bottleneck, especially when similarities are computed via expensive functions, e.g., via transformer models. Approximation methods reduce this quadratic complexity, often by using a small subset of exactly computed similarities to approximate the remainder of the complete pairwise similarity matrix. Significant work focuses on the efficient approximation of positive semidefinite (PSD) similarity matrices, which arise e.g., in kernel methods. However, much less is understood about indefinite (non-PSD) similarity matrices, which often arise in NLP. Motivated by the observation that many of these matrices are still somewhat close to PSD, we introduce a generalization of the popular Nystr\"{o}m method to the indefinite setting. Our algorithm can be applied to any similarity matrix and runs in sublinear time in the size of the matrix, producing a rank-$s$ approximation with just $O(ns)$ similarity computations. We show that our method, along with a simple variant of CUR decomposition, performs very well in approximating a variety of similarity matrices arising in NLP tasks. We demonstrate high accuracy of the approximated similarity matrices in the downstream tasks of document classification, sentence similarity, and cross-document coreference.