 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGOOD: Exploring Geometric Cues for Detecting Objects in an Open World
Dec 24, 2022



We address the task of open-world class-agnostic object detection, i.e., detecting every object in an image by learning from a limited number of base object classes. State-of-the-art RGB-based models suffer from overfitting the training classes and often fail at detecting novel-looking objects. This is because RGB-based models primarily rely on appearance similarity to detect novel objects and are also prone to overfitting short-cut cues such as textures and discriminative parts. To address these shortcomings of RGB-based object detectors, we propose incorporating geometric cues such as depth and normals, predicted by general-purpose monocular estimators. Specifically, we use the geometric cues to train an object proposal network for pseudo-labeling unannotated novel objects in the training set. Our resulting Geometry-guided Open-world Object Detector (GOOD) significantly improves detection recall for novel object categories and already performs well with only a few training classes. Using a single "person" class for training on the COCO dataset, GOOD surpasses SOTA methods by 5.0% AR@100, a relative improvement of 24%.
Fast-SNARF: A Fast Deformer for Articulated Neural Fields
Dec 01, 2022



Neural fields have revolutionized the area of 3D reconstruction and novel view synthesis of rigid scenes. A key challenge in making such methods applicable to articulated objects, such as the human body, is to model the deformation of 3D locations between the rest pose (a canonical space) and the deformed space. We propose a new articulation module for neural fields, Fast-SNARF, which finds accurate correspondences between canonical space and posed space via iterative root finding. Fast-SNARF is a drop-in replacement in functionality to our previous work, SNARF, while significantly improving its computational efficiency. We contribute several algorithmic and implementation improvements over SNARF, yielding a speed-up of $150\times$. These improvements include voxel-based correspondence search, pre-computing the linear blend skinning function, and an efficient software implementation with CUDA kernels. Fast-SNARF enables efficient and simultaneous optimization of shape and skinning weights given deformed observations without correspondences (e.g. 3D meshes). Because learning of deformation maps is a crucial component in many 3D human avatar methods and since Fast-SNARF provides a computationally efficient solution, we believe that this work represents a significant step towards the practical creation of 3D virtual humans.
Unifying Flow, Stereo and Depth Estimation
Nov 10, 2022



We present a unified formulation and model for three motion and 3D perception tasks: optical flow, rectified stereo matching and unrectified stereo depth estimation from posed images. Unlike previous specialized architectures for each specific task, we formulate all three tasks as a unified dense correspondence matching problem, which can be solved with a single model by directly comparing feature similarities. Such a formulation calls for discriminative feature representations, which we achieve using a Transformer, in particular the cross-attention mechanism. We demonstrate that cross-attention enables integration of knowledge from another image via cross-view interactions, which greatly improves the quality of the extracted features. Our unified model naturally enables cross-task transfer since the model architecture and parameters are shared across tasks. We outperform RAFT with our unified model on the challenging Sintel dataset, and our final model that uses a few additional task-specific refinement steps outperforms or compares favorably to recent state-of-the-art methods on 10 popular flow, stereo and depth datasets, while being simpler and more efficient in terms of model design and inference speed.
NeRFPlayer: A Streamable Dynamic Scene Representation with Decomposed Neural Radiance Fields
Oct 28, 2022



Visually exploring in a real-world 4D spatiotemporal space freely in VR has been a long-term quest. The task is especially appealing when only a few or even single RGB cameras are used for capturing the dynamic scene. To this end, we present an efficient framework capable of fast reconstruction, compact modeling, and streamable rendering. First, we propose to decompose the 4D spatiotemporal space according to temporal characteristics. Points in the 4D space are associated with probabilities of belonging to three categories: static, deforming, and new areas. Each area is represented and regularized by a separate neural field. Second, we propose a hybrid representations based feature streaming scheme for efficiently modeling the neural fields. Our approach, coined NeRFPlayer, is evaluated on dynamic scenes captured by single hand-held cameras and multi-camera arrays, achieving comparable or superior rendering performance in terms of quality and speed comparable to recent state-of-the-art methods, achieving reconstruction in 10 seconds per frame and real-time rendering.
PlanT: Explainable Planning Transformers via Object-Level Representations
Oct 25, 2022



Planning an optimal route in a complex environment requires efficient reasoning about the surrounding scene. While human drivers prioritize important objects and ignore details not relevant to the decision, learning-based planners typically extract features from dense, high-dimensional grid representations containing all vehicle and road context information. In this paper, we propose PlanT, a novel approach for planning in the context of self-driving that uses a standard transformer architecture. PlanT is based on imitation learning with a compact object-level input representation. On the Longest6 benchmark for CARLA, PlanT outperforms all prior methods (matching the driving score of the expert) while being 5.3x faster than equivalent pixel-based planning baselines during inference. Combining PlanT with an off-the-shelf perception module provides a sensor-based driving system that is more than 10 points better in terms of driving score than the existing state of the art. Furthermore, we propose an evaluation protocol to quantify the ability of planners to identify relevant objects, providing insights regarding their decision-making. Our results indicate that PlanT can focus on the most relevant object in the scene, even when this object is geometrically distant.
ARAH: Animatable Volume Rendering of Articulated Human SDFs
Oct 18, 2022
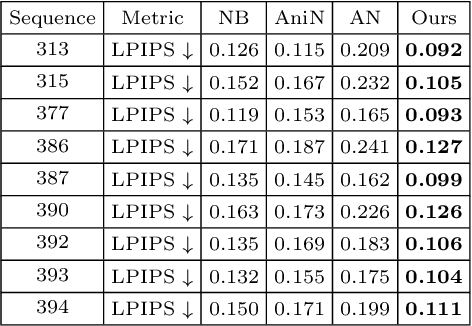
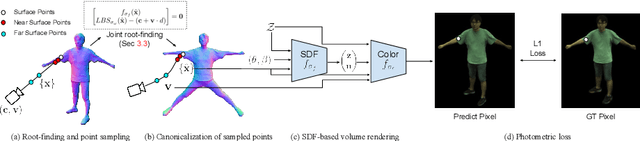
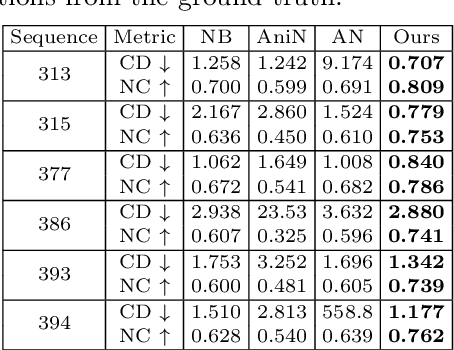
Combining human body models with differentiable rendering has recently enabled animatable avatars of clothed humans from sparse sets of multi-view RGB videos. While state-of-the-art approaches achieve realistic appearance with neural radiance fields (NeRF), the inferred geometry often lacks detail due to missing geometric constraints. Further, animating avatars in out-of-distribution poses is not yet possible because the mapping from observation space to canonical space does not generalize faithfully to unseen poses. In this work, we address these shortcomings and propose a model to create animatable clothed human avatars with detailed geometry that generalize well to out-of-distribution poses. To achieve detailed geometry, we combine an articulated implicit surface representation with volume rendering. For generalization, we propose a novel joint root-finding algorithm for simultaneous ray-surface intersection search and correspondence search. Our algorithm enables efficient point sampling and accurate point canonicalization while generalizing well to unseen poses. We demonstrate that our proposed pipeline can generate clothed avatars with high-quality pose-dependent geometry and appearance from a sparse set of multi-view RGB videos. Our method achieves state-of-the-art performance on geometry and appearance reconstruction while creating animatable avatars that generalize well to out-of-distribution poses beyond the small number of training poses.
VoxGRAF: Fast 3D-Aware Image Synthesis with Sparse Voxel Grids
Jun 17, 2022
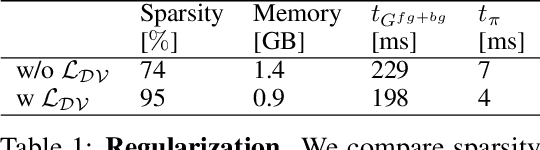
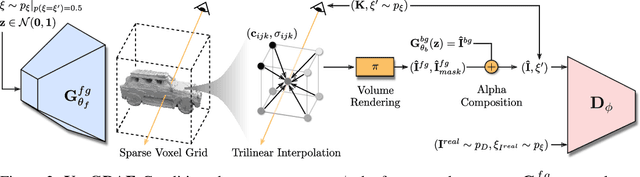

State-of-the-art 3D-aware generative models rely on coordinate-based MLPs to parameterize 3D radiance fields. While demonstrating impressive results, querying an MLP for every sample along each ray leads to slow rendering. Therefore, existing approaches often render low-resolution feature maps and process them with an upsampling network to obtain the final image. Albeit efficient, neural rendering often entangles viewpoint and content such that changing the camera pose results in unwanted changes of geometry or appearance. Motivated by recent results in voxel-based novel view synthesis, we investigate the utility of sparse voxel grid representations for fast and 3D-consistent generative modeling in this paper. Our results demonstrate that monolithic MLPs can indeed be replaced by 3D convolutions when combining sparse voxel grids with progressive growing, free space pruning and appropriate regularization. To obtain a compact representation of the scene and allow for scaling to higher voxel resolutions, our model disentangles the foreground object (modeled in 3D) from the background (modeled in 2D). In contrast to existing approaches, our method requires only a single forward pass to generate a full 3D scene. It hence allows for efficient rendering from arbitrary viewpoints while yielding 3D consistent results with high visual fidelity.
MonoSDF: Exploring Monocular Geometric Cues for Neural Implicit Surface Reconstruction
Jun 01, 2022
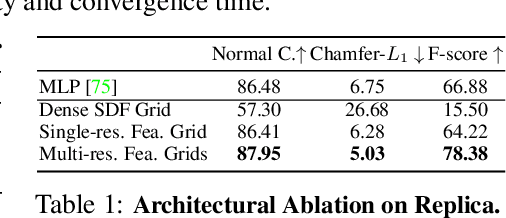
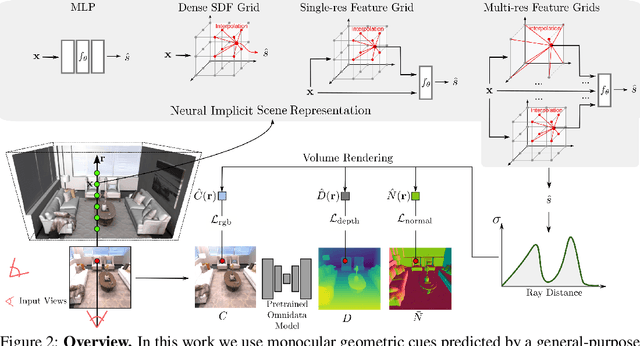
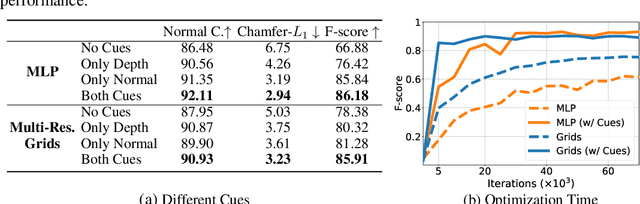
In recent years, neural implicit surface reconstruction methods have become popular for multi-view 3D reconstruction. In contrast to traditional multi-view stereo methods, these approaches tend to produce smoother and more complete reconstructions due to the inductive smoothness bias of neural networks. State-of-the-art neural implicit methods allow for high-quality reconstructions of simple scenes from many input views. Yet, their performance drops significantly for larger and more complex scenes and scenes captured from sparse viewpoints. This is caused primarily by the inherent ambiguity in the RGB reconstruction loss that does not provide enough constraints, in particular in less-observed and textureless areas. Motivated by recent advances in the area of monocular geometry prediction, we systematically explore the utility these cues provide for improving neural implicit surface reconstruction. We demonstrate that depth and normal cues, predicted by general-purpose monocular estimators, significantly improve reconstruction quality and optimization time. Further, we analyse and investigate multiple design choices for representing neural implicit surfaces, ranging from monolithic MLP models over single-grid to multi-resolution grid representations. We observe that geometric monocular priors improve performance both for small-scale single-object as well as large-scale multi-object scenes, independent of the choice of representation.
TransFuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving
May 31, 2022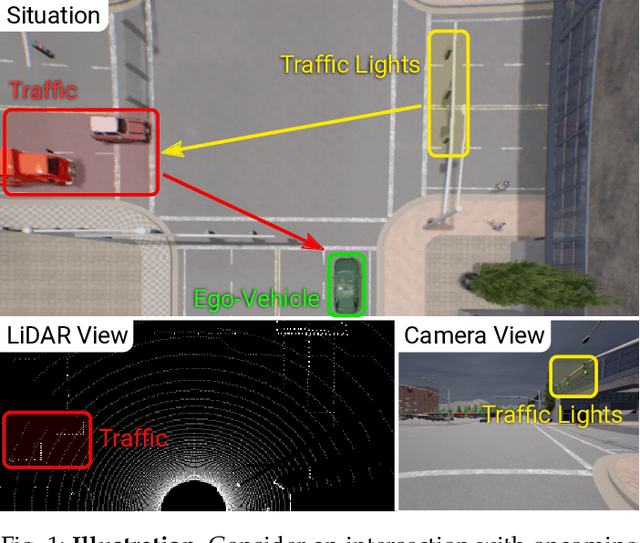
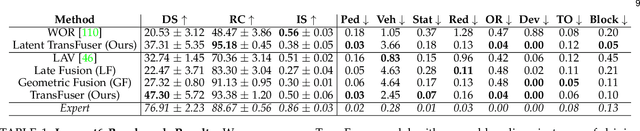
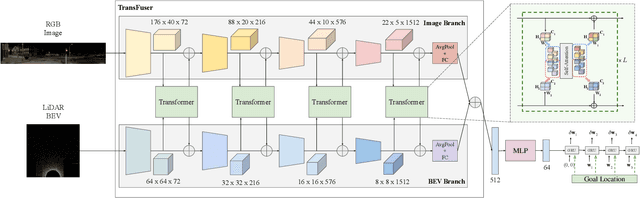
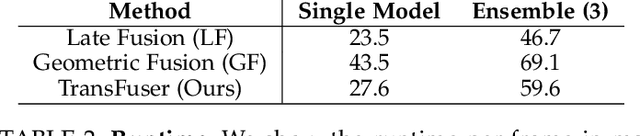
How should we integrate representations from complementary sensors for autonomous driving? Geometry-based fusion has shown promise for perception (e.g. object detection, motion forecasting). However, in the context of end-to-end driving, we find that imitation learning based on existing sensor fusion methods underperforms in complex driving scenarios with a high density of dynamic agents. Therefore, we propose TransFuser, a mechanism to integrate image and LiDAR representations using self-attention. Our approach uses transformer modules at multiple resolutions to fuse perspective view and bird's eye view feature maps. We experimentally validate its efficacy on a challenging new benchmark with long routes and dense traffic, as well as the official leaderboard of the CARLA urban driving simulator. At the time of submission, TransFuser outperforms all prior work on the CARLA leaderboard in terms of driving score by a large margin. Compared to geometry-based fusion, TransFuser reduces the average collisions per kilometer by 48%.
KING: Generating Safety-Critical Driving Scenarios for Robust Imitation via Kinematics Gradients
Apr 28, 2022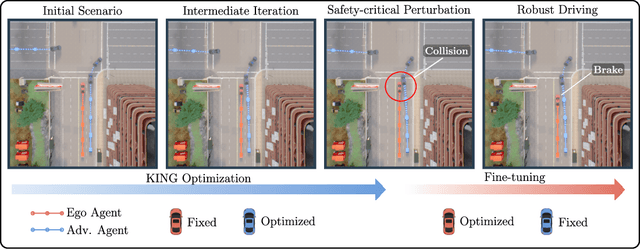

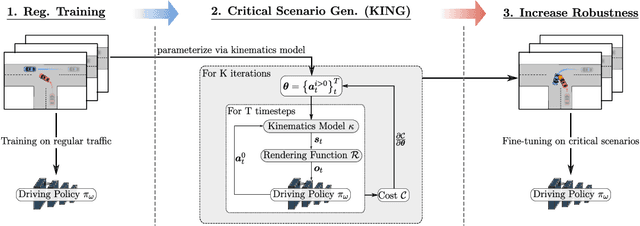
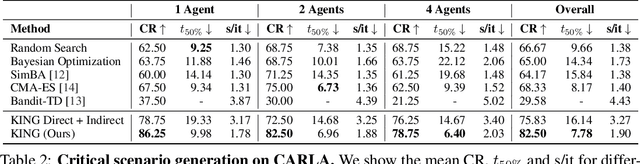
Simulators offer the possibility of safe, low-cost development of self-driving systems. However, current driving simulators exhibit na\"ive behavior models for background traffic. Hand-tuned scenarios are typically added during simulation to induce safety-critical situations. An alternative approach is to adversarially perturb the background traffic trajectories. In this paper, we study this approach to safety-critical driving scenario generation using the CARLA simulator. We use a kinematic bicycle model as a proxy to the simulator's true dynamics and observe that gradients through this proxy model are sufficient for optimizing the background traffic trajectories. Based on this finding, we propose KING, which generates safety-critical driving scenarios with a 20% higher success rate than black-box optimization. By solving the scenarios generated by KING using a privileged rule-based expert algorithm, we obtain training data for an imitation learning policy. After fine-tuning on this new data, we show that the policy becomes better at avoiding collisions. Importantly, our generated data leads to reduced collisions on both held-out scenarios generated via KING as well as traditional hand-crafted scenarios, demonstrating improved robustness.