 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCentaur: Robust End-to-End Autonomous Driving with Test-Time Training
Mar 14, 2025



How can we rely on an end-to-end autonomous vehicle's complex decision-making system during deployment? One common solution is to have a ``fallback layer'' that checks the planned trajectory for rule violations and replaces it with a pre-defined safe action if necessary. Another approach involves adjusting the planner's decisions to minimize a pre-defined ``cost function'' using additional system predictions such as road layouts and detected obstacles. However, these pre-programmed rules or cost functions cannot learn and improve with new training data, often resulting in overly conservative behaviors. In this work, we propose Centaur (Cluster Entropy for Test-time trAining using Uncertainty) which updates a planner's behavior via test-time training, without relying on hand-engineered rules or cost functions. Instead, we measure and minimize the uncertainty in the planner's decisions. For this, we develop a novel uncertainty measure, called Cluster Entropy, which is simple, interpretable, and compatible with state-of-the-art planning algorithms. Using data collected at prior test-time time-steps, we perform an update to the model's parameters using a gradient that minimizes the Cluster Entropy. With only this sole gradient update prior to inference, Centaur exhibits significant improvements, ranking first on the navtest leaderboard with notable gains in safety-critical metrics such as time to collision. To provide detailed insights on a per-scenario basis, we also introduce navsafe, a challenging new benchmark, which highlights previously undiscovered failure modes of driving models.
Transforming Science with Large Language Models: A Survey on AI-assisted Scientific Discovery, Experimentation, Content Generation, and Evaluation
Feb 07, 2025



With the advent of large multimodal language models, science is now at a threshold of an AI-based technological transformation. Recently, a plethora of new AI models and tools has been proposed, promising to empower researchers and academics worldwide to conduct their research more effectively and efficiently. This includes all aspects of the research cycle, especially (1) searching for relevant literature; (2) generating research ideas and conducting experimentation; generating (3) text-based and (4) multimodal content (e.g., scientific figures and diagrams); and (5) AI-based automatic peer review. In this survey, we provide an in-depth overview over these exciting recent developments, which promise to fundamentally alter the scientific research process for good. Our survey covers the five aspects outlined above, indicating relevant datasets, methods and results (including evaluation) as well as limitations and scope for future research. Ethical concerns regarding shortcomings of these tools and potential for misuse (fake science, plagiarism, harms to research integrity) take a particularly prominent place in our discussion. We hope that our survey will not only become a reference guide for newcomers to the field but also a catalyst for new AI-based initiatives in the area of "AI4Science".
sshELF: Single-Shot Hierarchical Extrapolation of Latent Features for 3D Reconstruction from Sparse-Views
Feb 06, 2025



Reconstructing unbounded outdoor scenes from sparse outward-facing views poses significant challenges due to minimal view overlap. Previous methods often lack cross-scene understanding and their primitive-centric formulations overload local features to compensate for missing global context, resulting in blurriness in unseen parts of the scene. We propose sshELF, a fast, single-shot pipeline for sparse-view 3D scene reconstruction via hierarchal extrapolation of latent features. Our key insights is that disentangling information extrapolation from primitive decoding allows efficient transfer of structural patterns across training scenes. Our method: (1) learns cross-scene priors to generate intermediate virtual views to extrapolate to unobserved regions, (2) offers a two-stage network design separating virtual view generation from 3D primitive decoding for efficient training and modular model design, and (3) integrates a pre-trained foundation model for joint inference of latent features and texture, improving scene understanding and generalization. sshELF can reconstruct 360 degree scenes from six sparse input views and achieves competitive results on synthetic and real-world datasets. We find that sshELF faithfully reconstructs occluded regions, supports real-time rendering, and provides rich latent features for downstream applications. The code will be released.
Relightable Full-Body Gaussian Codec Avatars
Jan 24, 2025



We propose Relightable Full-Body Gaussian Codec Avatars, a new approach for modeling relightable full-body avatars with fine-grained details including face and hands. The unique challenge for relighting full-body avatars lies in the large deformations caused by body articulation and the resulting impact on appearance caused by light transport. Changes in body pose can dramatically change the orientation of body surfaces with respect to lights, resulting in both local appearance changes due to changes in local light transport functions, as well as non-local changes due to occlusion between body parts. To address this, we decompose the light transport into local and non-local effects. Local appearance changes are modeled using learnable zonal harmonics for diffuse radiance transfer. Unlike spherical harmonics, zonal harmonics are highly efficient to rotate under articulation. This allows us to learn diffuse radiance transfer in a local coordinate frame, which disentangles the local radiance transfer from the articulation of the body. To account for non-local appearance changes, we introduce a shadow network that predicts shadows given precomputed incoming irradiance on a base mesh. This facilitates the learning of non-local shadowing between the body parts. Finally, we use a deferred shading approach to model specular radiance transfer and better capture reflections and highlights such as eye glints. We demonstrate that our approach successfully models both the local and non-local light transport required for relightable full-body avatars, with a superior generalization ability under novel illumination conditions and unseen poses.
Prometheus: 3D-Aware Latent Diffusion Models for Feed-Forward Text-to-3D Scene Generation
Dec 30, 2024In this work, we introduce Prometheus, a 3D-aware latent diffusion model for text-to-3D generation at both object and scene levels in seconds. We formulate 3D scene generation as multi-view, feed-forward, pixel-aligned 3D Gaussian generation within the latent diffusion paradigm. To ensure generalizability, we build our model upon pre-trained text-to-image generation model with only minimal adjustments, and further train it using a large number of images from both single-view and multi-view datasets. Furthermore, we introduce an RGB-D latent space into 3D Gaussian generation to disentangle appearance and geometry information, enabling efficient feed-forward generation of 3D Gaussians with better fidelity and geometry. Extensive experimental results demonstrate the effectiveness of our method in both feed-forward 3D Gaussian reconstruction and text-to-3D generation. Project page: https://freemty.github.io/project-prometheus/
Level-Set Parameters: Novel Representation for 3D Shape Analysis
Dec 18, 2024



3D shape analysis has been largely focused on traditional 3D representations of point clouds and meshes, but the discrete nature of these data makes the analysis susceptible to variations in input resolutions. Recent development of neural fields brings in level-set parameters from signed distance functions as a novel, continuous, and numerical representation of 3D shapes, where the shape surfaces are defined as zero-level-sets of those functions. This motivates us to extend shape analysis from the traditional 3D data to these novel parameter data. Since the level-set parameters are not Euclidean like point clouds, we establish correlations across different shapes by formulating them as a pseudo-normal distribution, and learn the distribution prior from the respective dataset. To further explore the level-set parameters with shape transformations, we propose to condition a subset of these parameters on rotations and translations, and generate them with a hypernetwork. This simplifies the pose-related shape analysis compared to using traditional data. We demonstrate the promise of the novel representations through applications in shape classification (arbitrary poses), retrieval, and 6D object pose estimation. Code and data in this research are provided at https://github.com/EnyaHermite/LevelSetParamData.
Hidden Biases of End-to-End Driving Datasets
Dec 12, 2024



End-to-end driving systems have made rapid progress, but have so far not been applied to the challenging new CARLA Leaderboard 2.0. Further, while there is a large body of literature on end-to-end architectures and training strategies, the impact of the training dataset is often overlooked. In this work, we make a first attempt at end-to-end driving for Leaderboard 2.0. Instead of investigating architectures, we systematically analyze the training dataset, leading to new insights: (1) Expert style significantly affects downstream policy performance. (2) In complex data sets, the frames should not be weighted on the basis of simplistic criteria such as class frequencies. (3) Instead, estimating whether a frame changes the target labels compared to previous frames can reduce the size of the dataset without removing important information. By incorporating these findings, our model ranks first and second respectively on the map and sensors tracks of the 2024 CARLA Challenge, and sets a new state-of-the-art on the Bench2Drive test routes. Finally, we uncover a design flaw in the current evaluation metrics and propose a modification for future challenges. Our dataset, code, and pre-trained models are publicly available at https://github.com/autonomousvision/carla_garage.
HUGSIM: A Real-Time, Photo-Realistic and Closed-Loop Simulator for Autonomous Driving
Dec 02, 2024

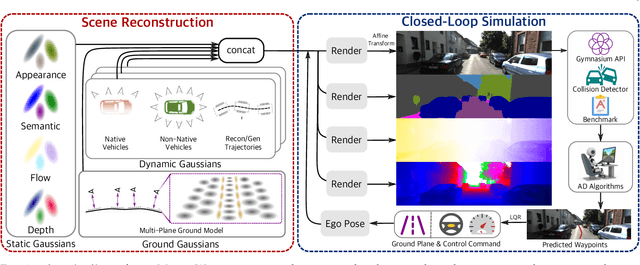
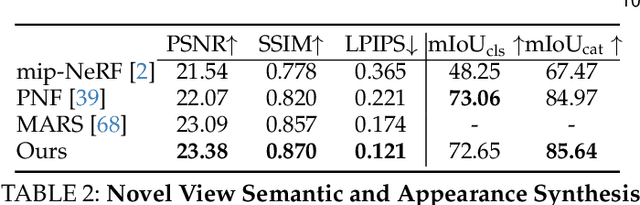
In the past few decades, autonomous driving algorithms have made significant progress in perception, planning, and control. However, evaluating individual components does not fully reflect the performance of entire systems, highlighting the need for more holistic assessment methods. This motivates the development of HUGSIM, a closed-loop, photo-realistic, and real-time simulator for evaluating autonomous driving algorithms. We achieve this by lifting captured 2D RGB images into the 3D space via 3D Gaussian Splatting, improving the rendering quality for closed-loop scenarios, and building the closed-loop environment. In terms of rendering, We tackle challenges of novel view synthesis in closed-loop scenarios, including viewpoint extrapolation and 360-degree vehicle rendering. Beyond novel view synthesis, HUGSIM further enables the full closed simulation loop, dynamically updating the ego and actor states and observations based on control commands. Moreover, HUGSIM offers a comprehensive benchmark across more than 70 sequences from KITTI-360, Waymo, nuScenes, and PandaSet, along with over 400 varying scenarios, providing a fair and realistic evaluation platform for existing autonomous driving algorithms. HUGSIM not only serves as an intuitive evaluation benchmark but also unlocks the potential for fine-tuning autonomous driving algorithms in a photorealistic closed-loop setting.
UrbanCAD: Towards Highly Controllable and Photorealistic 3D Vehicles for Urban Scene Simulation
Nov 28, 2024Photorealistic 3D vehicle models with high controllability are essential for autonomous driving simulation and data augmentation. While handcrafted CAD models provide flexible controllability, free CAD libraries often lack the high-quality materials necessary for photorealistic rendering. Conversely, reconstructed 3D models offer high-fidelity rendering but lack controllability. In this work, we introduce UrbanCAD, a framework that pushes the frontier of the photorealism-controllability trade-off by generating highly controllable and photorealistic 3D vehicle digital twins from a single urban image and a collection of free 3D CAD models and handcrafted materials. These digital twins enable realistic 360-degree rendering, vehicle insertion, material transfer, relighting, and component manipulation such as opening doors and rolling down windows, supporting the construction of long-tail scenarios. To achieve this, we propose a novel pipeline that operates in a retrieval-optimization manner, adapting to observational data while preserving flexible controllability and fine-grained handcrafted details. Furthermore, given multi-view background perspective and fisheye images, we approximate environment lighting using fisheye images and reconstruct the background with 3DGS, enabling the photorealistic insertion of optimized CAD models into rendered novel view backgrounds. Experimental results demonstrate that UrbanCAD outperforms baselines based on reconstruction and retrieval in terms of photorealism. Additionally, we show that various perception models maintain their accuracy when evaluated on UrbanCAD with in-distribution configurations but degrade when applied to realistic out-of-distribution data generated by our method. This suggests that UrbanCAD is a significant advancement in creating photorealistic, safety-critical driving scenarios for downstream applications.
EMPERROR: A Flexible Generative Perception Error Model for Probing Self-Driving Planners
Nov 12, 2024



To handle the complexities of real-world traffic, learning planners for self-driving from data is a promising direction. While recent approaches have shown great progress, they typically assume a setting in which the ground-truth world state is available as input. However, when deployed, planning needs to be robust to the long-tail of errors incurred by a noisy perception system, which is often neglected in evaluation. To address this, previous work has proposed drawing adversarial samples from a perception error model (PEM) mimicking the noise characteristics of a target object detector. However, these methods use simple PEMs that fail to accurately capture all failure modes of detection. In this paper, we present EMPERROR, a novel transformer-based generative PEM, apply it to stress-test an imitation learning (IL)-based planner and show that it imitates modern detectors more faithfully than previous work. Furthermore, it is able to produce realistic noisy inputs that increase the planner's collision rate by up to 85%, demonstrating its utility as a valuable tool for a more complete evaluation of self-driving planners.