 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen in Doubt, Summon the Titans: Efficient Inference with Large Models
Oct 19, 2021
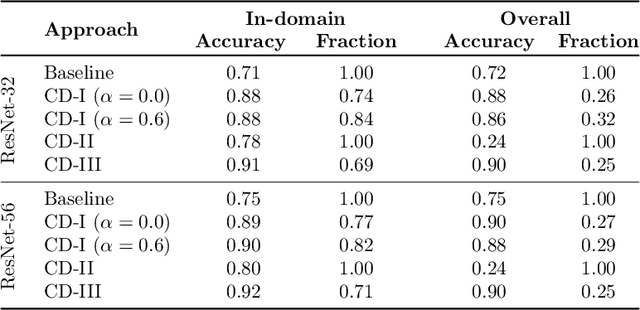
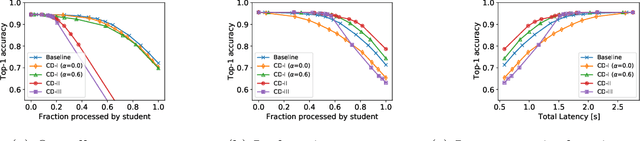
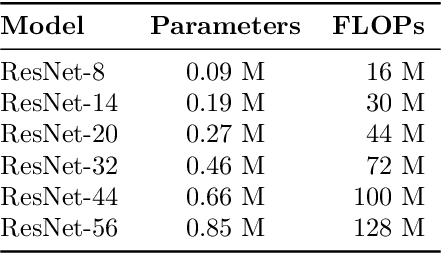
Scaling neural networks to "large" sizes, with billions of parameters, has been shown to yield impressive results on many challenging problems. However, the inference cost incurred by such large models often prevents their application in most real-world settings. In this paper, we propose a two-stage framework based on distillation that realizes the modelling benefits of the large models, while largely preserving the computational benefits of inference with more lightweight models. In a nutshell, we use the large teacher models to guide the lightweight student models to only make correct predictions on a subset of "easy" examples; for the "hard" examples, we fall-back to the teacher. Such an approach allows us to efficiently employ large models in practical scenarios where easy examples are much more frequent than rare hard examples. Our proposed use of distillation to only handle easy instances allows for a more aggressive trade-off in the student size, thereby reducing the amortized cost of inference and achieving better accuracy than standard distillation. Empirically, we demonstrate the benefits of our approach on both image classification and natural language processing benchmarks.
Hierarchically Regularized Deep Forecasting
Jun 14, 2021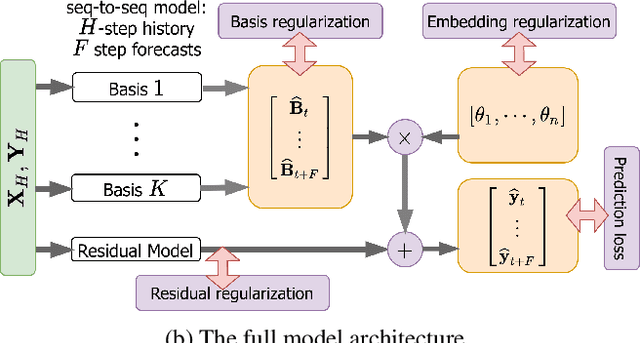
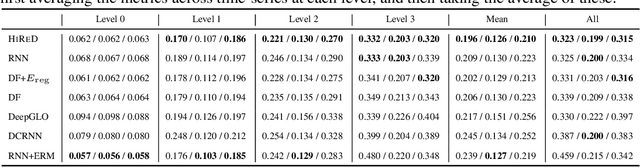
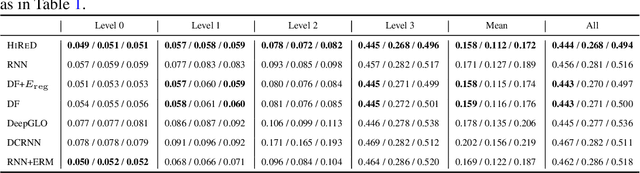

Hierarchical forecasting is a key problem in many practical multivariate forecasting applications - the goal is to simultaneously predict a large number of correlated time series that are arranged in a pre-specified aggregation hierarchy. The challenge is to exploit the hierarchical correlations to simultaneously obtain good prediction accuracy for time series at different levels of the hierarchy. In this paper, we propose a new approach for hierarchical forecasting based on decomposing the time series along a global set of basis time series and modeling hierarchical constraints using the coefficients of the basis decomposition for each time series. Unlike past methods, our approach is scalable at inference-time (forecasting for a specific time series only needs access to its own data) while (approximately) preserving coherence among the time series forecasts. We experiment on several publicly available datasets and demonstrate significantly improved overall performance on forecasts at different levels of the hierarchy, compared to existing state-of-the-art hierarchical reconciliation methods.
Exact and Approximate Hierarchical Clustering Using A*
Apr 14, 2021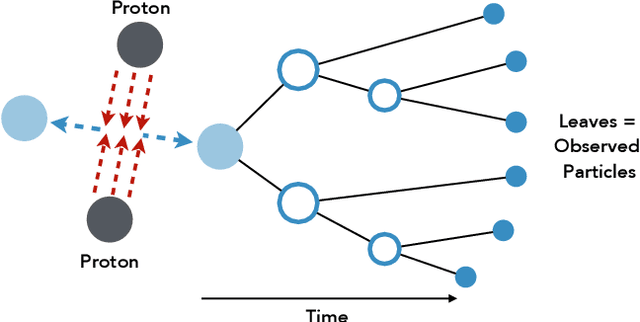
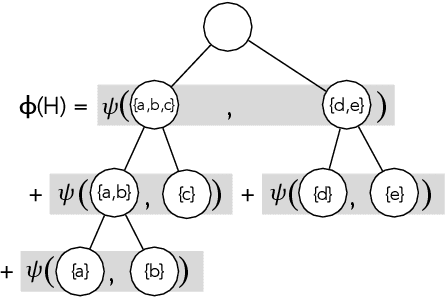
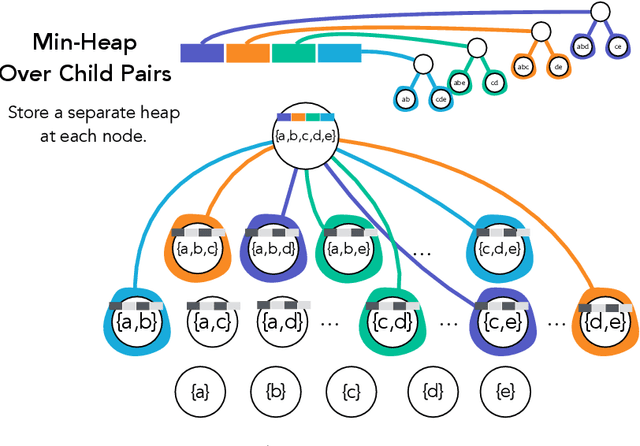
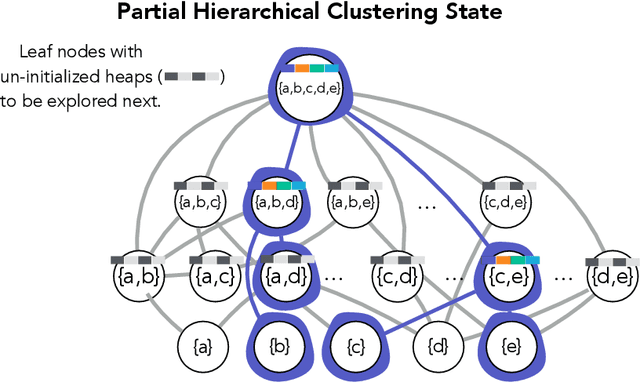
Hierarchical clustering is a critical task in numerous domains. Many approaches are based on heuristics and the properties of the resulting clusterings are studied post hoc. However, in several applications, there is a natural cost function that can be used to characterize the quality of the clustering. In those cases, hierarchical clustering can be seen as a combinatorial optimization problem. To that end, we introduce a new approach based on A* search. We overcome the prohibitively large search space by combining A* with a novel \emph{trellis} data structure. This combination results in an exact algorithm that scales beyond previous state of the art, from a search space with $10^{12}$ trees to $10^{15}$ trees, and an approximate algorithm that improves over baselines, even in enormous search spaces that contain more than $10^{1000}$ trees. We empirically demonstrate that our method achieves substantially higher quality results than baselines for a particle physics use case and other clustering benchmarks. We describe how our method provides significantly improved theoretical bounds on the time and space complexity of A* for clustering.
A Review of Machine Learning Techniques for Applied Eye Fundus and Tongue Digital Image Processing with Diabetes Management System
Dec 30, 2020Diabetes is a global epidemic and it is increasing at an alarming rate. The International Diabetes Federation (IDF) projected that the total number of people with diabetes globally may increase by 48%, from 425 million (year 2017) to 629 million (year 2045). Moreover, diabetes had caused millions of deaths and the number is increasing drastically. Therefore, this paper addresses the background of diabetes and its complications. In addition, this paper investigates innovative applications and past researches in the areas of diabetes management system with applied eye fundus and tongue digital images. Different types of existing applied eye fundus and tongue digital image processing with diabetes management systems in the market and state-of-the-art machine learning techniques from previous literature have been reviewed. The implication of this paper is to have an overview in diabetic research and what new machine learning techniques can be proposed in solving this global epidemic.
Amazon SageMaker Autopilot: a white box AutoML solution at scale
Dec 16, 2020
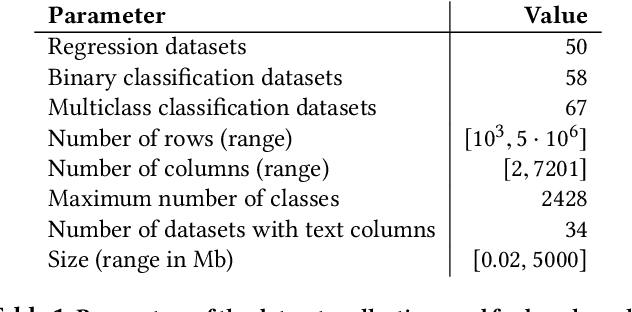
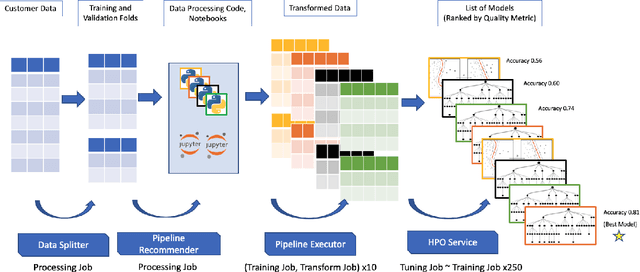
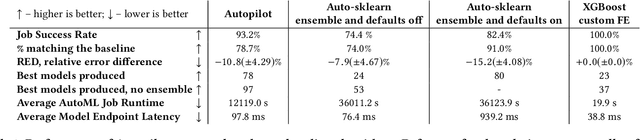
AutoML systems provide a black-box solution to machine learning problems by selecting the right way of processing features, choosing an algorithm and tuning the hyperparameters of the entire pipeline. Although these systems perform well on many datasets, there is still a non-negligible number of datasets for which the one-shot solution produced by each particular system would provide sub-par performance. In this paper, we present Amazon SageMaker Autopilot: a fully managed system providing an automated ML solution that can be modified when needed. Given a tabular dataset and the target column name, Autopilot identifies the problem type, analyzes the data and produces a diverse set of complete ML pipelines including feature preprocessing and ML algorithms, which are tuned to generate a leaderboard of candidate models. In the scenario where the performance is not satisfactory, a data scientist is able to view and edit the proposed ML pipelines in order to infuse their expertise and business knowledge without having to revert to a fully manual solution. This paper describes the different components of Autopilot, emphasizing the infrastructure choices that allow scalability, high quality models, editable ML pipelines, consumption of artifacts of offline meta-learning, and a convenient integration with the entire SageMaker suite allowing these trained models to be used in a production setting.
Amazon SageMaker Automatic Model Tuning: Scalable Black-box Optimization
Dec 15, 2020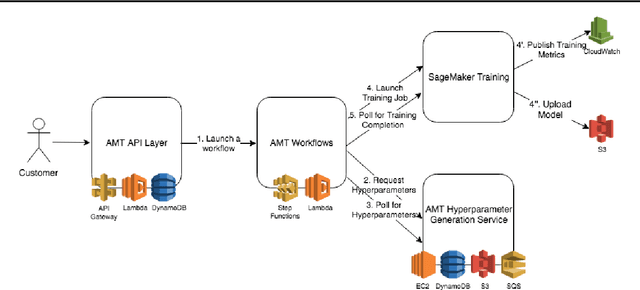
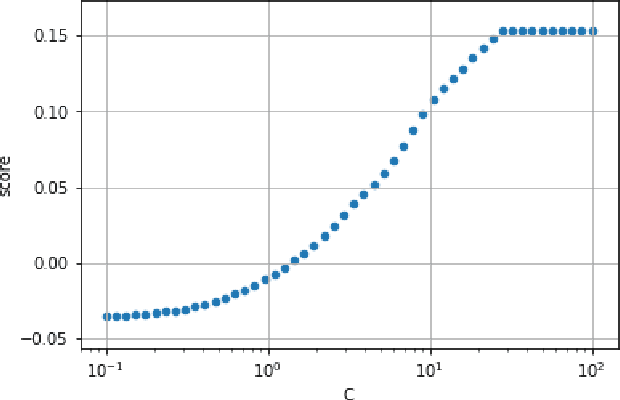
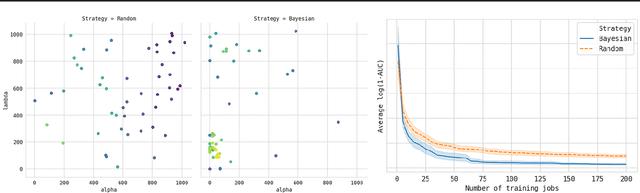
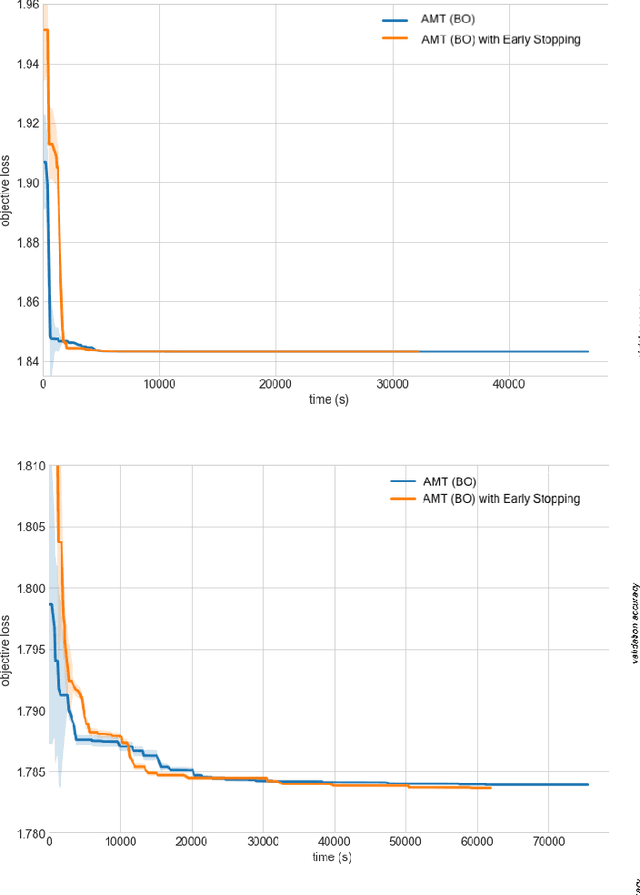
Tuning complex machine learning systems is challenging. Machine learning models typically expose a set of hyperparameters, be it regularization, architecture, or optimization parameters, whose careful tuning is critical to achieve good performance. To democratize access to such systems, it is essential to automate this tuning process. This paper presents Amazon SageMaker Automatic Model Tuning (AMT), a fully managed system for black-box optimization at scale. AMT finds the best version of a machine learning model by repeatedly training it with different hyperparameter configurations. It leverages either random search or Bayesian optimization to choose the hyperparameter values resulting in the best-performing model, as measured by the metric chosen by the user. AMT can be used with built-in algorithms, custom algorithms, and Amazon SageMaker pre-built containers for machine learning frameworks. We discuss the core functionality, system architecture and our design principles. We also describe some more advanced features provided by AMT, such as automated early stopping and warm-starting, demonstrating their benefits in experiments.
Non-Stationary Latent Bandits
Dec 01, 2020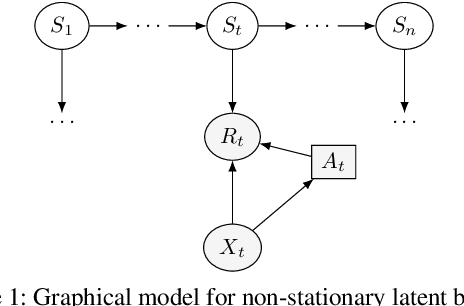
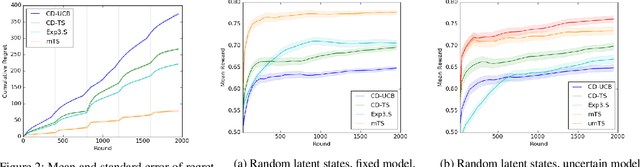
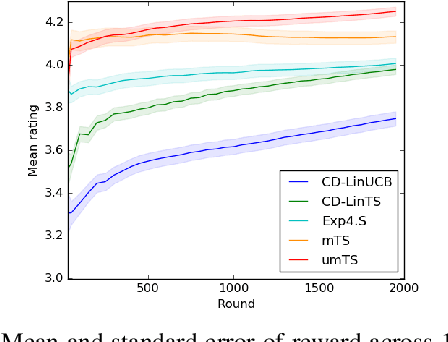
Users of recommender systems often behave in a non-stationary fashion, due to their evolving preferences and tastes over time. In this work, we propose a practical approach for fast personalization to non-stationary users. The key idea is to frame this problem as a latent bandit, where the prototypical models of user behavior are learned offline and the latent state of the user is inferred online from its interactions with the models. We call this problem a non-stationary latent bandit. We propose Thompson sampling algorithms for regret minimization in non-stationary latent bandits, analyze them, and evaluate them on a real-world dataset. The main strength of our approach is that it can be combined with rich offline-learned models, which can be misspecified, and are subsequently fine-tuned online using posterior sampling. In this way, we naturally combine the strengths of offline and online learning.
Scalable Bottom-Up Hierarchical Clustering
Nov 04, 2020
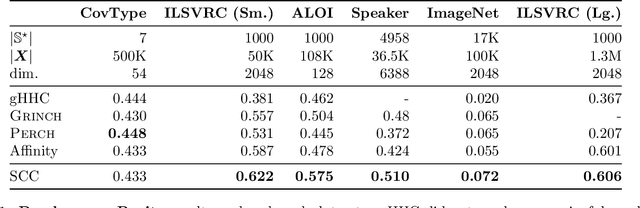

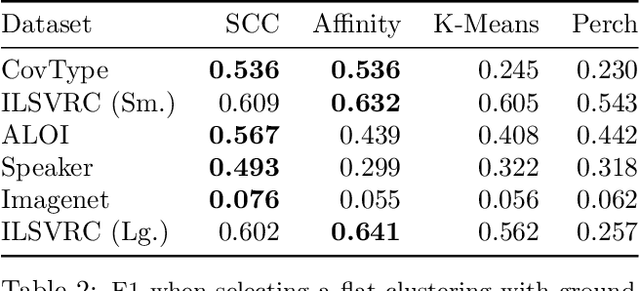
Bottom-up algorithms such as the classic hierarchical agglomerative clustering, are highly effective for hierarchical as well as flat clustering. However, the large number of rounds and their sequential nature limit the scalability of agglomerative clustering. In this paper, we present an alternative round-based bottom-up hierarchical clustering, the Sub-Cluster Component Algorithm (SCC), that scales gracefully to massive datasets. Our method builds many sub-clusters in parallel in a given round and requires many fewer rounds -- usually an order of magnitude smaller than classic agglomerative clustering. Our theoretical analysis shows that, under a modest separability assumption, SCC will contain the optimal flat clustering. SCC also provides a 2-approx solution to the DP-means objective, thereby introducing a novel application of hierarchical clustering methods. Empirically, SCC finds better hierarchies and flat clusterings even when the data does not satisfy the separability assumption. We demonstrate the scalability of our method by applying it to a dataset of 30 billion points and showing that SCC produces higher quality clusterings than the state-of-the-art.
Unsupervised Abstractive Dialogue Summarization for Tete-a-Tetes
Sep 15, 2020
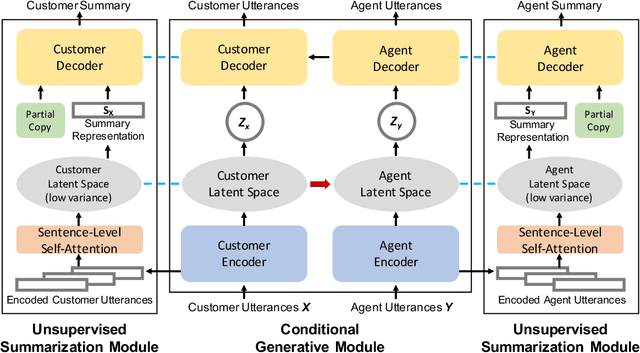
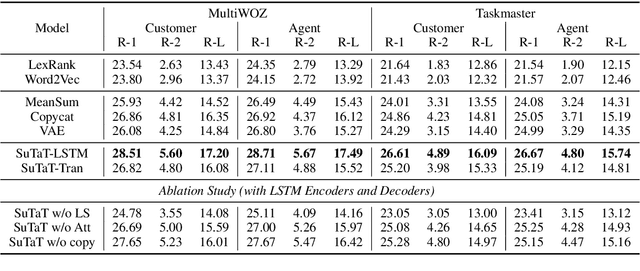
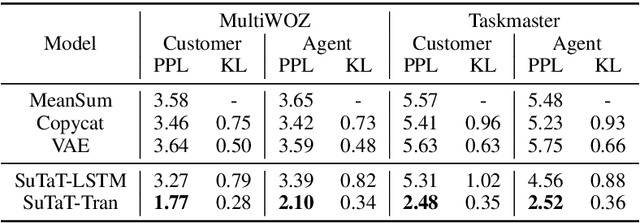
High-quality dialogue-summary paired data is expensive to produce and domain-sensitive, making abstractive dialogue summarization a challenging task. In this work, we propose the first unsupervised abstractive dialogue summarization model for tete-a-tetes (SuTaT). Unlike standard text summarization, a dialogue summarization method should consider the multi-speaker scenario where the speakers have different roles, goals, and language styles. In a tete-a-tete, such as a customer-agent conversation, SuTaT aims to summarize for each speaker by modeling the customer utterances and the agent utterances separately while retaining their correlations. SuTaT consists of a conditional generative module and two unsupervised summarization modules. The conditional generative module contains two encoders and two decoders in a variational autoencoder framework where the dependencies between two latent spaces are captured. With the same encoders and decoders, two unsupervised summarization modules equipped with sentence-level self-attention mechanisms generate summaries without using any annotations. Experimental results show that SuTaT is superior on unsupervised dialogue summarization for both automatic and human evaluations, and is capable of dialogue classification and single-turn conversation generation.
Big Bird: Transformers for Longer Sequences
Jul 28, 2020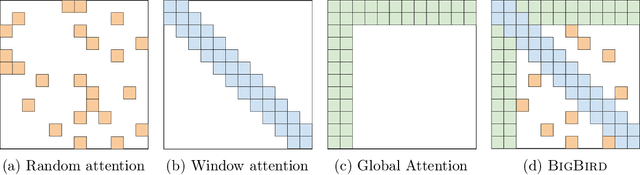
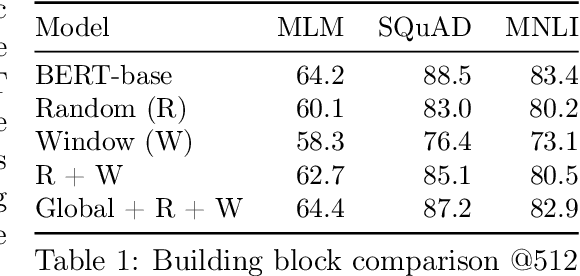

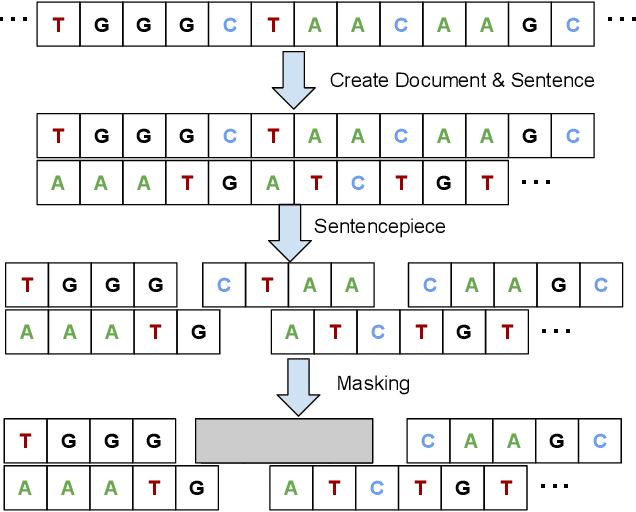
Transformers-based models, such as BERT, have been one of the most successful deep learning models for NLP. Unfortunately, one of their core limitations is the quadratic dependency (mainly in terms of memory) on the sequence length due to their full attention mechanism. To remedy this, we propose, BigBird, a sparse attention mechanism that reduces this quadratic dependency to linear. We show that BigBird is a universal approximator of sequence functions and is Turing complete, thereby preserving these properties of the quadratic, full attention model. Along the way, our theoretical analysis reveals some of the benefits of having $O(1)$ global tokens (such as CLS), that attend to the entire sequence as part of the sparse attention mechanism. The proposed sparse attention can handle sequences of length up to 8x of what was previously possible using similar hardware. As a consequence of the capability to handle longer context, BigBird drastically improves performance on various NLP tasks such as question answering and summarization. We also propose novel applications to genomics data.