 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Sampling from Language Models via Langevin Dynamics in Embedding Spaces
May 25, 2022
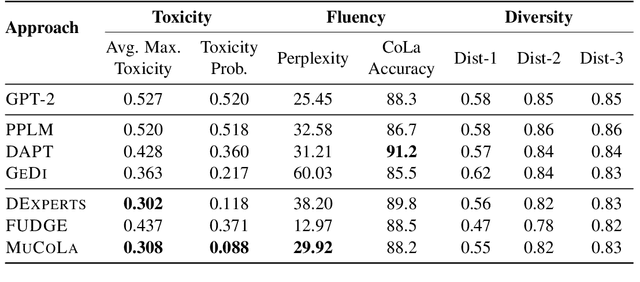
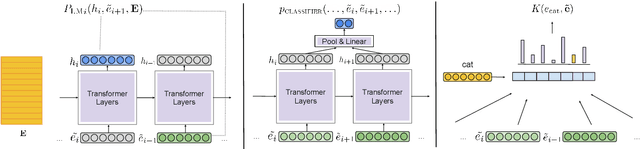
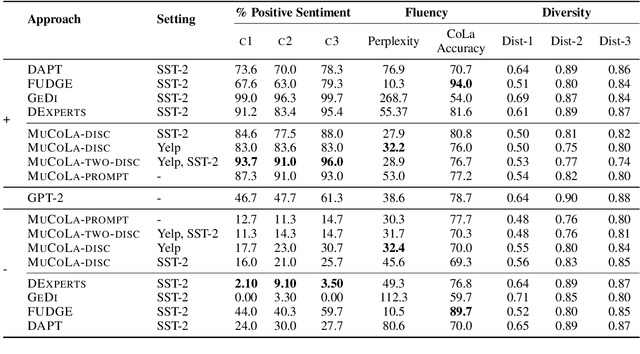
Large pre-trained language models are well-established for their ability to generate text seemingly indistinguishable from humans. In this work, we study the problem of constrained sampling from such language models. That is, generating text that satisfies user-defined constraints. Typical decoding strategies which generate samples left-to-right are not always conducive to imposing such constraints globally. Instead, we propose MuCoLa -- a sampling procedure that combines the log-likelihood of the language model with arbitrary differentiable constraints into a single energy function; and generates samples by initializing the entire output sequence with noise and following a Markov chain defined by Langevin Dynamics using the gradients of this energy. We evaluate our approach on different text generation tasks with soft and hard constraints as well as their combinations with competitive results for toxicity avoidance, sentiment control, and keyword-guided generation.
A Top-Down Approach to Hierarchically Coherent Probabilistic Forecasting
Apr 21, 2022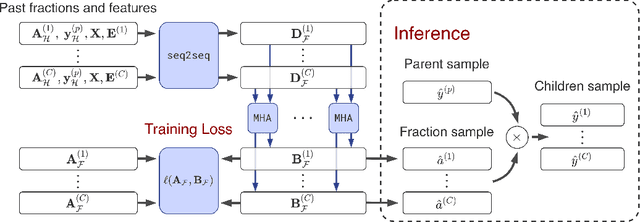


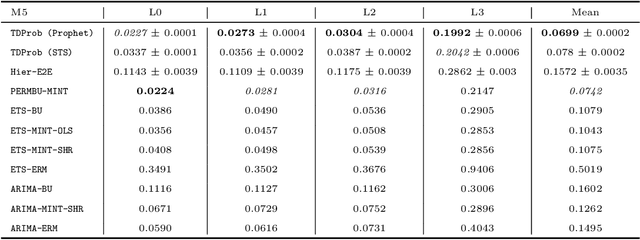
Hierarchical forecasting is a key problem in many practical multivariate forecasting applications - the goal is to obtain coherent predictions for a large number of correlated time series that are arranged in a pre-specified tree hierarchy. In this paper, we present a probabilistic top-down approach to hierarchical forecasting that uses a novel attention-based RNN model to learn the distribution of the proportions according to which each parent prediction is split among its children nodes at any point in time. These probabilistic proportions are then coupled with an independent univariate probabilistic forecasting model (such as Prophet or STS) for the root time series. The resulting forecasts are computed in a top-down fashion and are naturally coherent, and also support probabilistic predictions over all time series in the hierarchy. We provide theoretical justification for the superiority of our top-down approach compared to traditional bottom-up hierarchical modeling. Finally, we experiment on three public datasets and demonstrate significantly improved probabilistic forecasts, compared to state-of-the-art probabilistic hierarchical models.
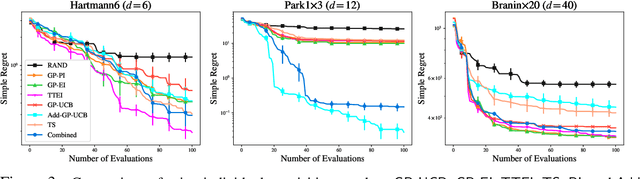
An Experimental Design Perspective on Model-Based Reinforcement Learning
Dec 09, 2021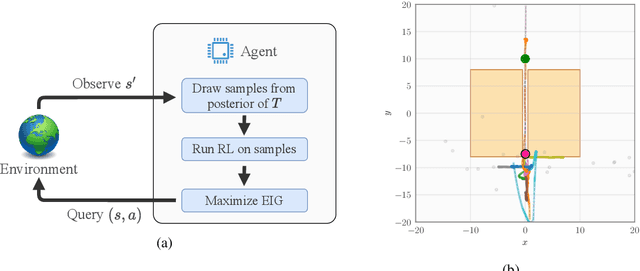
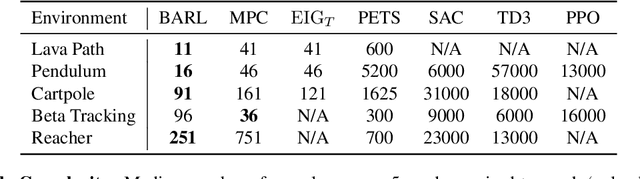

In many practical applications of RL, it is expensive to observe state transitions from the environment. For example, in the problem of plasma control for nuclear fusion, computing the next state for a given state-action pair requires querying an expensive transition function which can lead to many hours of computer simulation or dollars of scientific research. Such expensive data collection prohibits application of standard RL algorithms which usually require a large number of observations to learn. In this work, we address the problem of efficiently learning a policy while making a minimal number of state-action queries to the transition function. In particular, we leverage ideas from Bayesian optimal experimental design to guide the selection of state-action queries for efficient learning. We propose an acquisition function that quantifies how much information a state-action pair would provide about the optimal solution to a Markov decision process. At each iteration, our algorithm maximizes this acquisition function, to choose the most informative state-action pair to be queried, thus yielding a data-efficient RL approach. We experiment with a variety of simulated continuous control problems and show that our approach learns an optimal policy with up to $5$ -- $1,000\times$ less data than model-based RL baselines and $10^3$ -- $10^5\times$ less data than model-free RL baselines. We also provide several ablated comparisons which point to substantial improvements arising from the principled method of obtaining data.
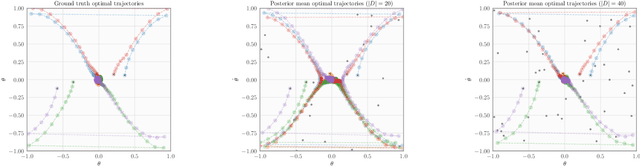
Hierarchically Regularized Deep Forecasting
Jun 14, 2021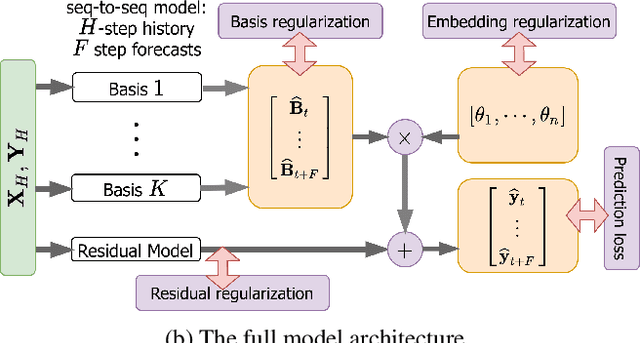
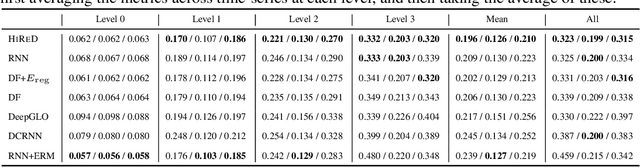
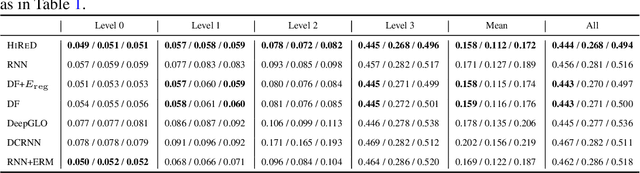

Hierarchical forecasting is a key problem in many practical multivariate forecasting applications - the goal is to simultaneously predict a large number of correlated time series that are arranged in a pre-specified aggregation hierarchy. The challenge is to exploit the hierarchical correlations to simultaneously obtain good prediction accuracy for time series at different levels of the hierarchy. In this paper, we propose a new approach for hierarchical forecasting based on decomposing the time series along a global set of basis time series and modeling hierarchical constraints using the coefficients of the basis decomposition for each time series. Unlike past methods, our approach is scalable at inference-time (forecasting for a specific time series only needs access to its own data) while (approximately) preserving coherence among the time series forecasts. We experiment on several publicly available datasets and demonstrate significantly improved overall performance on forecasts at different levels of the hierarchy, compared to existing state-of-the-art hierarchical reconciliation methods.
Minimizing FLOPs to Learn Efficient Sparse Representations
Apr 12, 2020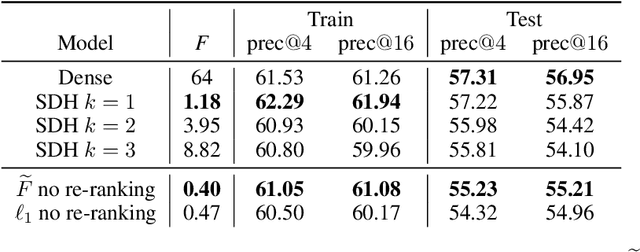

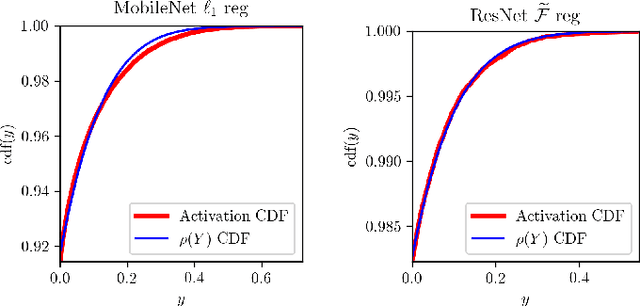
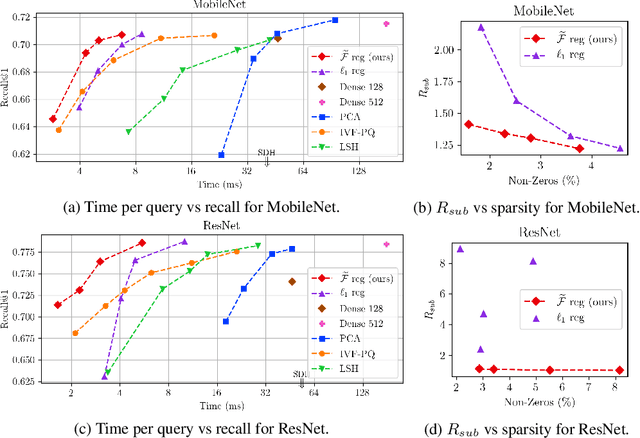
Deep representation learning has become one of the most widely adopted approaches for visual search, recommendation, and identification. Retrieval of such representations from a large database is however computationally challenging. Approximate methods based on learning compact representations, have been widely explored for this problem, such as locality sensitive hashing, product quantization, and PCA. In this work, in contrast to learning compact representations, we propose to learn high dimensional and sparse representations that have similar representational capacity as dense embeddings while being more efficient due to sparse matrix multiplication operations which can be much faster than dense multiplication. Following the key insight that the number of operations decreases quadratically with the sparsity of embeddings provided the non-zero entries are distributed uniformly across dimensions, we propose a novel approach to learn such distributed sparse embeddings via the use of a carefully constructed regularization function that directly minimizes a continuous relaxation of the number of floating-point operations (FLOPs) incurred during retrieval. Our experiments show that our approach is competitive to the other baselines and yields a similar or better speed-vs-accuracy tradeoff on practical datasets.
Tuning Hyperparameters without Grad Students: Scalable and Robust Bayesian Optimisation with Dragonfly
Mar 15, 2019
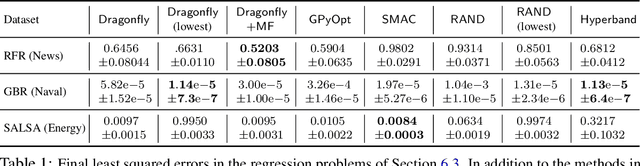
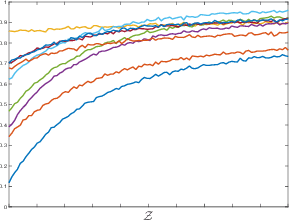
Bayesian Optimisation (BO), refers to a suite of techniques for global optimisation of expensive black box functions, which use introspective Bayesian models of the function to efficiently find the optimum. While BO has been applied successfully in many applications, modern optimisation tasks usher in new challenges where conventional methods fail spectacularly. In this work, we present Dragonfly, an open source Python library for scalable and robust BO. Dragonfly incorporates multiple recently developed methods that allow BO to be applied in challenging real world settings; these include better methods for handling higher dimensional domains, methods for handling multi-fidelity evaluations when cheap approximations of an expensive function are available, methods for optimising over structured combinatorial spaces, such as the space of neural network architectures, and methods for handling parallel evaluations. Additionally, we develop new methodological improvements in BO for selecting the Bayesian model, selecting the acquisition function, and optimising over complex domains with different variable types and additional constraints. We compare Dragonfly to a suite of other packages and algorithms for global optimisation and demonstrate that when the above methods are integrated, they enable significant improvements in the performance of BO. The Dragonfly library is available at dragonfly.github.io.
A Flexible Framework for Multi-Objective Bayesian Optimization using Random Scalarizations
Oct 22, 2018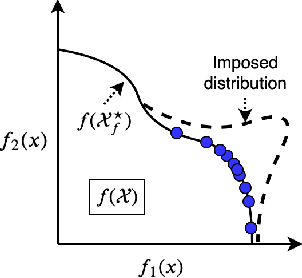
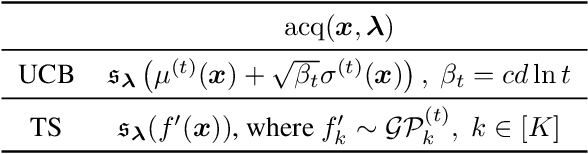
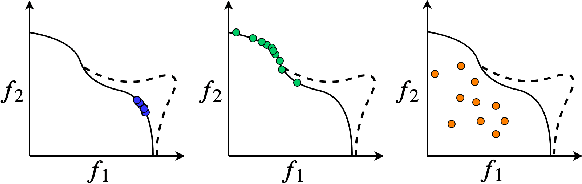
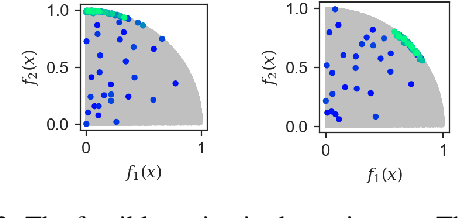
Many real world applications can be framed as multi-objective optimization problems, where we wish to simultaneously optimize for multiple criteria. Bayesian optimization techniques for the multi-objective setting are pertinent when the evaluation of the functions in question are expensive. Traditional methods for multi-objective optimization, both Bayesian and otherwise, are aimed at recovering the Pareto front of these objectives. However, in certain cases a practitioner might desire to identify Pareto optimal points only in a particular region of the Pareto front due to external considerations. In this work, we propose a strategy based on random scalarizations of the objectives that addresses this problem. While being computationally similar or cheaper than other approaches, our approach is flexible enough to sample from specified subsets of the Pareto front or the whole of it. We also introduce a novel notion of regret in the multi-objective setting and show that our strategy achieves sublinear regret. We experiment with both synthetic and real-life problems, and demonstrate superior performance of our proposed algorithm in terms of flexibility, scalability and regret.
A Neural Architecture Mimicking Humans End-to-End for Natural Language Inference
Jan 27, 2017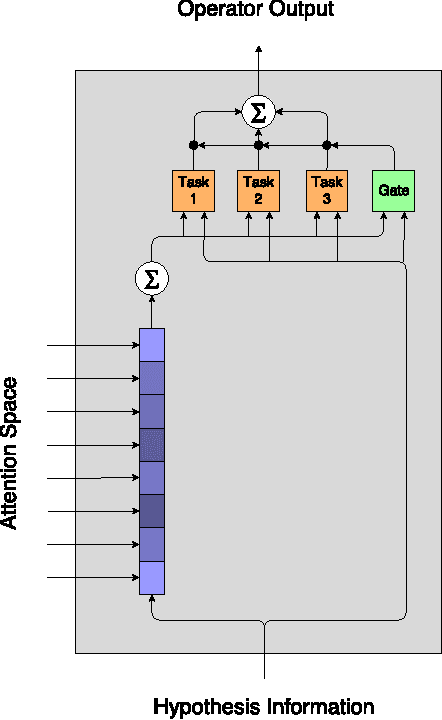
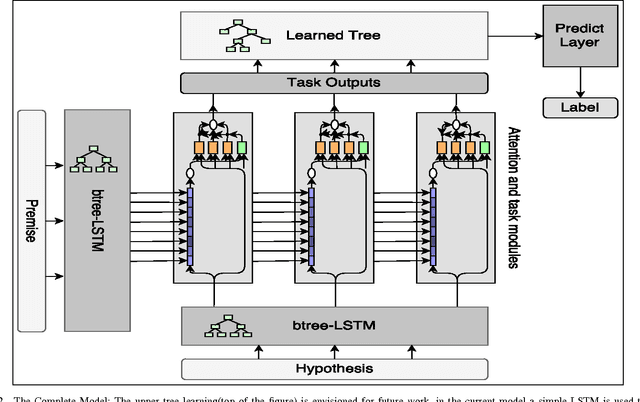

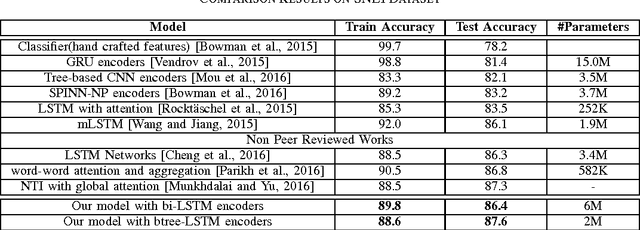
In this work we use the recent advances in representation learning to propose a neural architecture for the problem of natural language inference. Our approach is aligned to mimic how a human does the natural language inference process given two statements. The model uses variants of Long Short Term Memory (LSTM), attention mechanism and composable neural networks, to carry out the task. Each part of our model can be mapped to a clear functionality humans do for carrying out the overall task of natural language inference. The model is end-to-end differentiable enabling training by stochastic gradient descent. On Stanford Natural Language Inference(SNLI) dataset, the proposed model achieves better accuracy numbers than all published models in literature.
Visualization Regularizers for Neural Network based Image Recognition
Jan 03, 2017
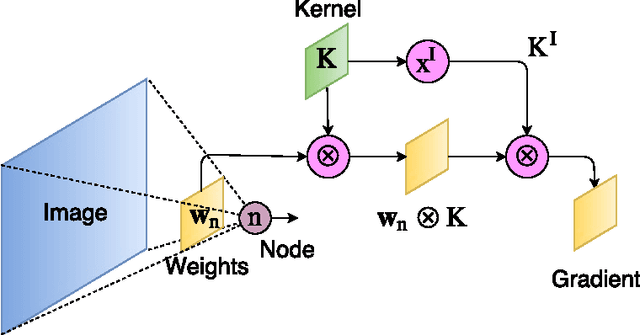

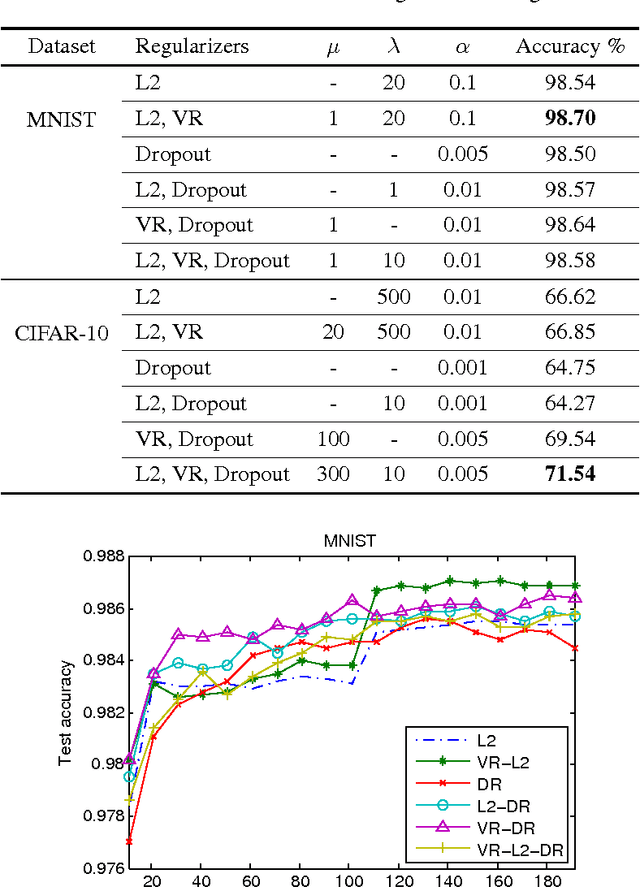
The success of deep neural networks is mostly due their ability to learn meaningful features from the data. Features learned in the hidden layers of deep neural networks trained in computer vision tasks have been shown to be similar to mid-level vision features. We leverage this fact in this work and propose the visualization regularizer for image tasks. The proposed regularization technique enforces smoothness of the features learned by hidden nodes and turns out to be a special case of Tikhonov regularization. We achieve higher classification accuracy as compared to existing regularizers such as the L2 norm regularizer and dropout, on benchmark datasets without changing the training computational complexity.
Forward Stagewise Additive Model for Collaborative Multiview Boosting
Aug 05, 2016
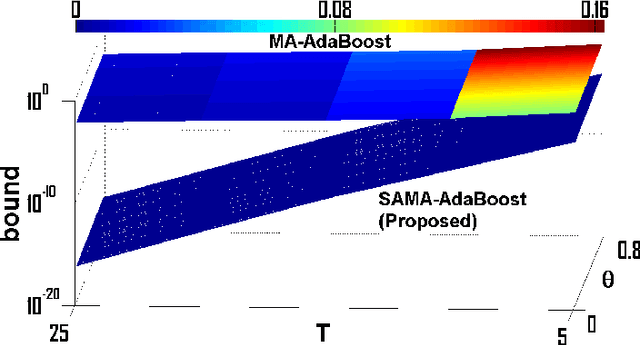
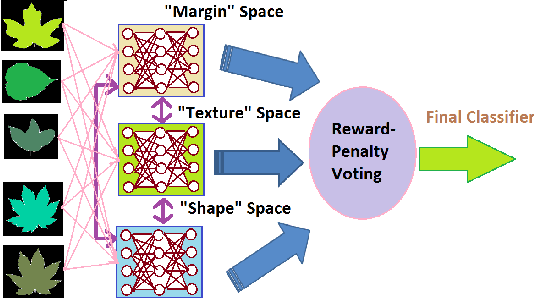
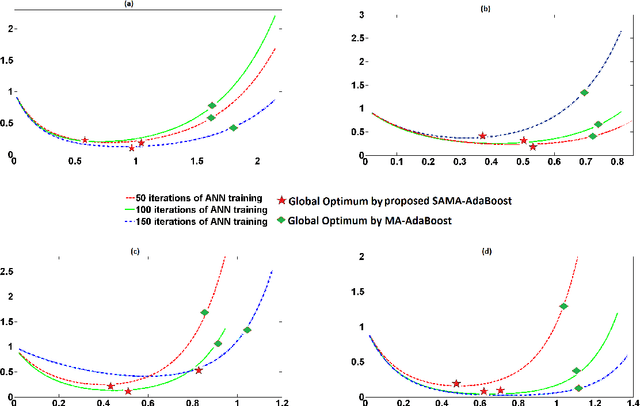
Multiview assisted learning has gained significant attention in recent years in supervised learning genre. Availability of high performance computing devices enables learning algorithms to search simultaneously over multiple views or feature spaces to obtain an optimum classification performance. The paper is a pioneering attempt of formulating a mathematical foundation for realizing a multiview aided collaborative boosting architecture for multiclass classification. Most of the present algorithms apply multiview learning heuristically without exploring the fundamental mathematical changes imposed on traditional boosting. Also, most of the algorithms are restricted to two class or view setting. Our proposed mathematical framework enables collaborative boosting across any finite dimensional view spaces for multiclass learning. The boosting framework is based on forward stagewise additive model which minimizes a novel exponential loss function. We show that the exponential loss function essentially captures difficulty of a training sample space instead of the traditional `1/0' loss. The new algorithm restricts a weak view from over learning and thereby preventing overfitting. The model is inspired by our earlier attempt on collaborative boosting which was devoid of mathematical justification. The proposed algorithm is shown to converge much nearer to global minimum in the exponential loss space and thus supersedes our previous algorithm. The paper also presents analytical and numerical analysis of convergence and margin bounds for multiview boosting algorithms and we show that our proposed ensemble learning manifests lower error bound and higher margin compared to our previous model. Also, the proposed model is compared with traditional boosting and recent multiview boosting algorithms.