 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Oct 22, 2020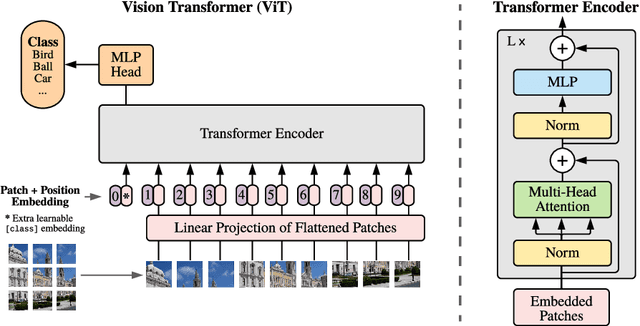

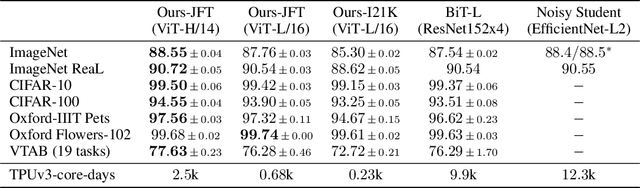
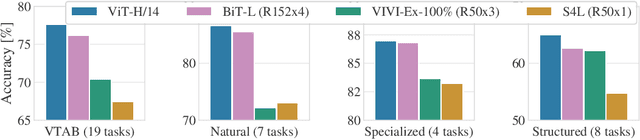
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections
Aug 13, 2020
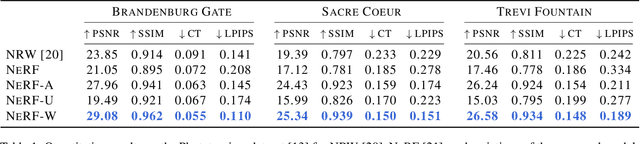

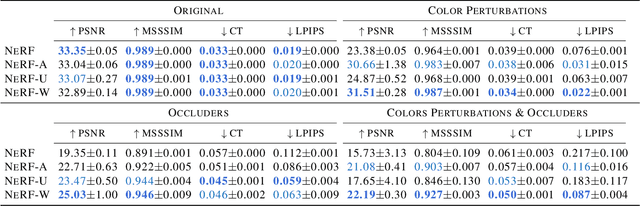
We present a learning-based method for synthesizing novel views of complex outdoor scenes using only unstructured collections of in-the-wild photographs. We build on neural radiance fields (NeRF), which uses the weights of a multilayer perceptron to implicitly model the volumetric density and color of a scene. While NeRF works well on images of static subjects captured under controlled settings, it is incapable of modeling many ubiquitous, real-world phenomena in uncontrolled images, such as variable illumination or transient occluders. In this work, we introduce a series of extensions to NeRF to address these issues, thereby allowing for accurate reconstructions from unstructured image collections taken from the internet. We apply our system, which we dub NeRF-W, to internet photo collections of famous landmarks, thereby producing photorealistic, spatially consistent scene representations despite unknown and confounding factors, resulting in significant improvement over the state of the art.
Object-Centric Learning with Slot Attention
Jun 26, 2020Learning object-centric representations of complex scenes is a promising step towards enabling efficient abstract reasoning from low-level perceptual features. Yet, most deep learning approaches learn distributed representations that do not capture the compositional properties of natural scenes. In this paper, we present the Slot Attention module, an architectural component that interfaces with perceptual representations such as the output of a convolutional neural network and produces a set of task-dependent abstract representations which we call slots. These slots are exchangeable and can bind to any object in the input by specializing through a competitive procedure over multiple rounds of attention. We empirically demonstrate that Slot Attention can extract object-centric representations that enable generalization to unseen compositions when trained on unsupervised object discovery and supervised property prediction tasks.
Learning Depth via Interaction
Mar 02, 2020

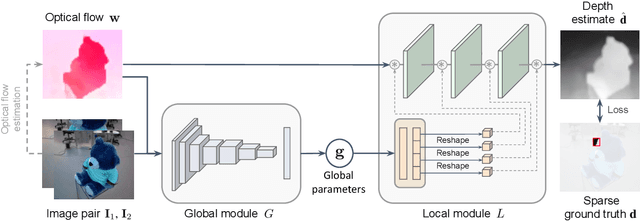

Motivated by the astonishing capabilities of natural intelligent agents and inspired by theories from psychology, this paper explores the idea that perception gets coupled to 3D properties of the world via interaction with the environment. Existing works for depth estimation require either massive amounts of annotated training data or some form of hard-coded geometrical constraint. This paper explores a new approach to learning depth perception requiring neither of those. Specifically, we train a specialized global-local network architecture with what would be available to a robot interacting with the environment: from extremely sparse depth measurements down to even a single pixel per image. From a pair of consecutive images, our proposed network outputs a latent representation of the observer's motion between the images and a dense depth map. Experiments on several datasets show that, when ground truth is available even for just one of the image pixels, the proposed network can learn monocular dense depth estimation up to 22.5% more accurately than state-of-the-art approaches. We believe that this work, despite its scientific interest, lays the foundations to learn depth from extremely sparse supervision, which can be valuable to all robotic systems acting under severe bandwidth or sensing constraints.
The Visual Task Adaptation Benchmark
Oct 01, 2019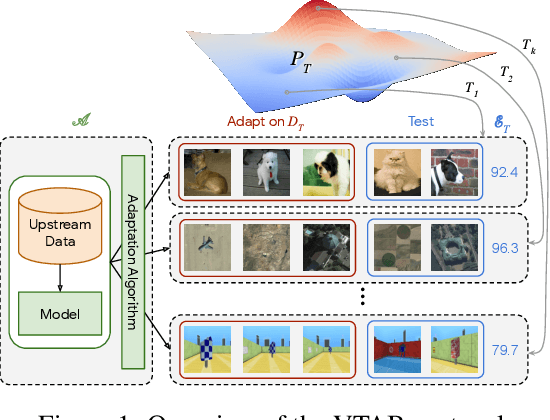
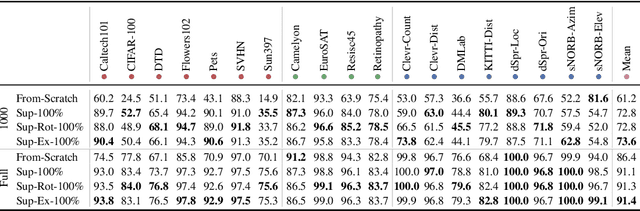
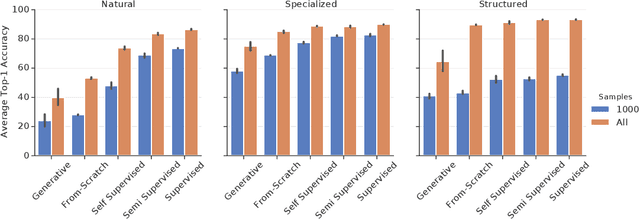
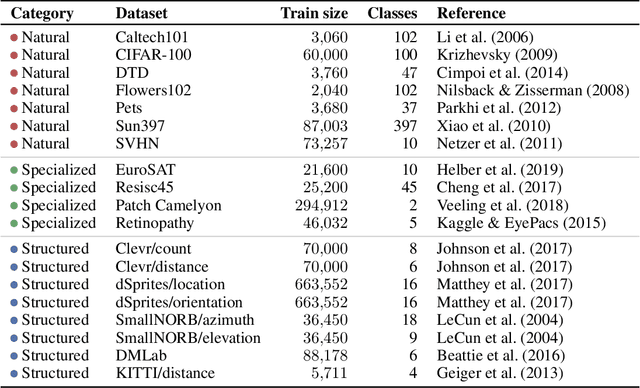
Representation learning promises to unlock deep learning for the long tail of vision tasks without expansive labelled datasets. Yet, the absence of a unified yardstick to evaluate general visual representations hinders progress. Many sub-fields promise representations, but each has different evaluation protocols that are either too constrained (linear classification), limited in scope (ImageNet, CIFAR, Pascal-VOC), or only loosely related to representation quality (generation). We present the Visual Task Adaptation Benchmark (VTAB): a diverse, realistic, and challenging benchmark to evaluate representations. VTAB embodies one principle: good representations adapt to unseen tasks with few examples. We run a large VTAB study of popular algorithms, answering questions like: How effective are ImageNet representation on non-standard datasets? Are generative models competitive? Is self-supervision useful if one already has labels?
Deep Drone Racing: From Simulation to Reality with Domain Randomization
May 21, 2019
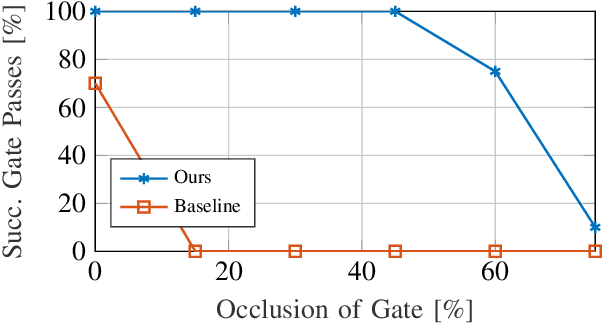
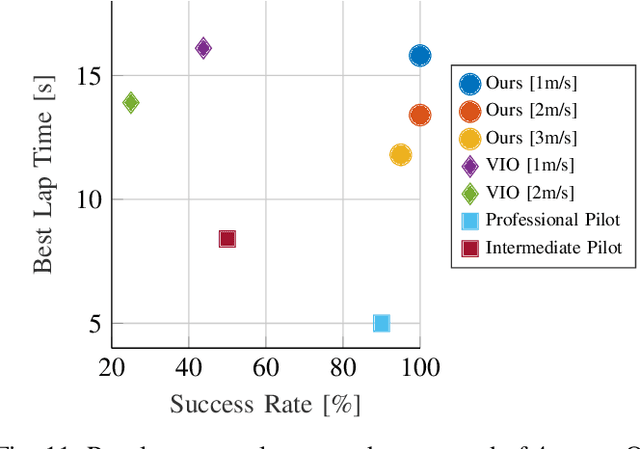

Dynamically changing environments, unreliable state estimation, and operation under severe resource constraints are fundamental challenges for robotics, which still limit the deployment of small autonomous drones. We address these challenges in the context of autonomous, vision-based drone racing in dynamic environments. A racing drone must traverse a track with possibly moving gates at high speed. We enable this functionality by combining the performance of a state-of-the-art path-planning and control system with the perceptual awareness of a convolutional neural network (CNN). The CNN directly maps raw images to a desired waypoint and speed. Given the CNN output, the planner generates a short minimum-jerk trajectory segment that is tracked by a model-based controller to actuate the drone towards the waypoint. The resulting modular system has several desirable features: (i) it can run fully on-board, (ii) it does not require globally consistent state estimation, and (iii) it is both platform and domain independent. We extensively test the precision and robustness of our system, both in simulation and on a physical platform. In both domains, our method significantly outperforms the prior state of the art. In order to understand the limits of our approach, we additionally compare against professional human drone pilots with different skill levels.
Benchmarking Classic and Learned Navigation in Complex 3D Environments
Mar 28, 2019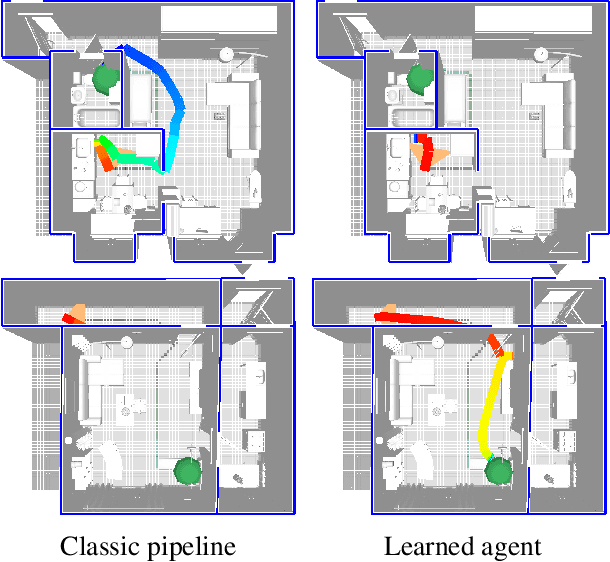
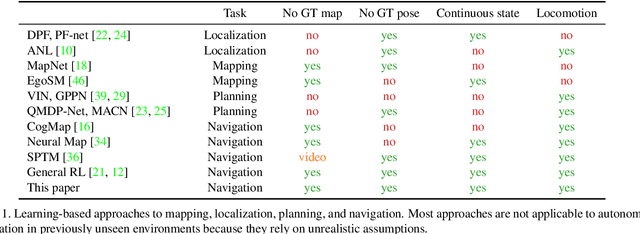
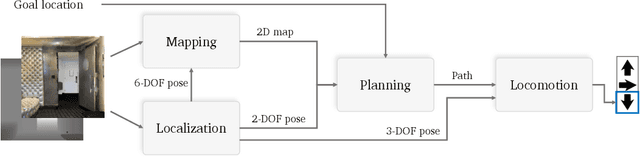
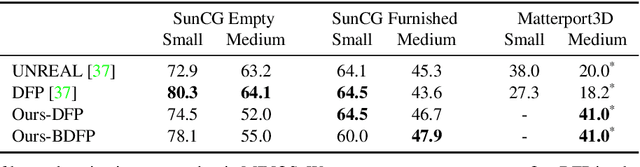
Navigation research is attracting renewed interest with the advent of learning-based methods. However, this new line of work is largely disconnected from well-established classic navigation approaches. In this paper, we take a step towards coordinating these two directions of research. We set up classic and learning-based navigation systems in common simulated environments and thoroughly evaluate them in indoor spaces of varying complexity, with access to different sensory modalities. Additionally, we measure human performance in the same environments. We find that a classic pipeline, when properly tuned, can perform very well in complex cluttered environments. On the other hand, learned systems can operate more robustly with a limited sensor suite. Overall, both approaches are still far from human-level performance.
Beauty and the Beast: Optimal Methods Meet Learning for Drone Racing
Mar 01, 2019


Autonomous micro aerial vehicles still struggle with fast and agile maneuvers, dynamic environments, imperfect sensing, and state estimation drift. Autonomous drone racing brings these challenges to the fore. Human pilots can fly a previously unseen track after a handful of practice runs. In contrast, state-of-the-art autonomous navigation algorithms require either a precise metric map of the environment or a large amount of training data collected in the track of interest. To bridge this gap, we propose an approach that can fly a new track in a previously unseen environment without a precise map or expensive data collection. Our approach represents the global track layout with coarse gate locations, which can be easily estimated from a single demonstration flight. At test time, a convolutional network predicts the poses of the closest gates along with their uncertainty. These predictions are incorporated by an extended Kalman filter to maintain optimal maximum-a-posteriori estimates of gate locations. This allows the framework to cope with misleading high-variance estimates that could stem from poor observability or lack of visible gates. Given the estimated gate poses, we use model predictive control to quickly and accurately navigate through the track. We conduct extensive experiments in the physical world, demonstrating agile and robust flight through complex and diverse previously-unseen race tracks. The presented approach was used to win the IROS 2018 Autonomous Drone Race Competition, outracing the second-placing team by a factor of two.
* 6 pages (+1 references)
Frequency-Aware Model Predictive Control
Feb 08, 2019
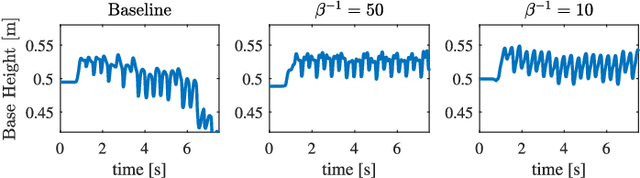
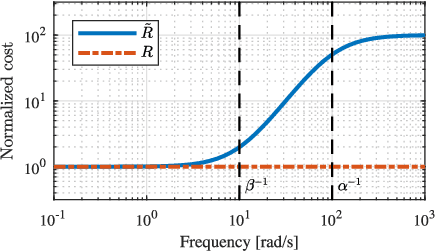
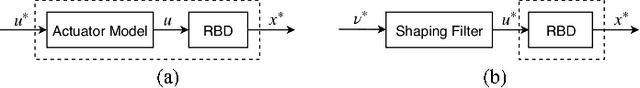
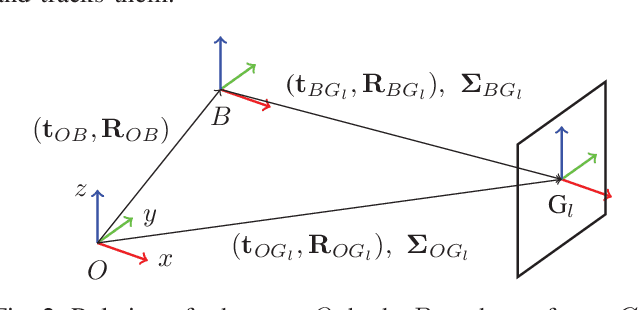
Transferring solutions found by trajectory optimization to robotic hardware remains a challenging task. When the optimization fully exploits the provided model to perform dynamic tasks, the presence of unmodeled dynamics renders the motion infeasible on the real system. Model errors can be a result of model simplifications, but also naturally arise when deploying the robot in unstructured and nondeterministic environments. Predominantly, compliant contacts and actuator dynamics lead to bandwidth limitations. While classical control methods provide tools to synthesize controllers that are robust to a class of model errors, such a notion is missing in modern trajectory optimization, which is solved in the time domain. We propose frequency-shaped cost functions to achieve robust solutions in the context of optimal control for legged robots. Through simulation and hardware experiments we show that motion plans can be made compatible with bandwidth limits set by actuators and contact dynamics. The smoothness of the model predictive solutions can be continuously tuned without compromising the feasibility of the problem. Experiments with the quadrupedal robot ANYmal, which is driven by highly-compliant series elastic actuators, showed significantly improved tracking performance of the planned motion, torque, and force trajectories and enabled the machine to walk robustly on terrain with unmodeled compliance.
Learning agile and dynamic motor skills for legged robots
Jan 24, 2019Legged robots pose one of the greatest challenges in robotics. Dynamic and agile maneuvers of animals cannot be imitated by existing methods that are crafted by humans. A compelling alternative is reinforcement learning, which requires minimal craftsmanship and promotes the natural evolution of a control policy. However, so far, reinforcement learning research for legged robots is mainly limited to simulation, and only few and comparably simple examples have been deployed on real systems. The primary reason is that training with real robots, particularly with dynamically balancing systems, is complicated and expensive. In the present work, we introduce a method for training a neural network policy in simulation and transferring it to a state-of-the-art legged system, thereby leveraging fast, automated, and cost-effective data generation schemes. The approach is applied to the ANYmal robot, a sophisticated medium-dog-sized quadrupedal system. Using policies trained in simulation, the quadrupedal machine achieves locomotion skills that go beyond what had been achieved with prior methods: ANYmal is capable of precisely and energy-efficiently following high-level body velocity commands, running faster than before, and recovering from falling even in complex configurations.