 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Seek: Autonomous Source Seeking with Deep Reinforcement Learning Onboard a Nano Drone Microcontroller
Sep 29, 2019


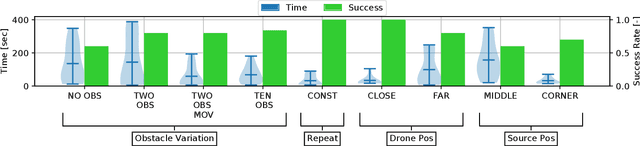
Fully autonomous navigation using nano drones has numerous applications in the real world, ranging from search and rescue to source seeking. Nano drones are well-suited for source seeking because of their agility, low price, and ubiquitous character. Unfortunately, their constrained form factor limits flight time, sensor payload, and compute capability. These challenges are a crucial limitation for the use of source-seeking nano drones in GPS-denied and highly cluttered environments. Hereby, we introduce a fully autonomous deep reinforcement learning-based light-seeking nano drone. The 33-gram nano drone performs all computation on-board the ultra-low-power microcontroller (MCU). We present the method for efficiently training, converting, and utilizing deep reinforcement learning policies. Our training methodology and novel quantization scheme allow fitting the trained policy in 3 kB of memory. The quantization scheme uses representative input data and input scaling to arrive at a full 8-bit model. Finally, we evaluate the approach in simulation and flight tests using a Bitcraze CrazyFlie, achieving 80% success rate on average in a highly cluttered and randomized test environment. Even more, the drone finds the light source in 29% fewer steps compared to a baseline simulation (obstacle avoidance without source information). To our knowledge, this is the first deep reinforcement learning method that enables source seeking within a highly constrained nano drone demonstrating robust flight behavior. Our general methodology is suitable for any (source seeking) highly constrained platform using deep reinforcement learning.
Zero-shot Imitation Learning from Demonstrations for Legged Robot Visual Navigation
Sep 27, 2019
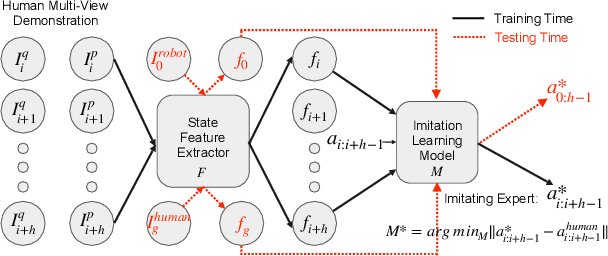
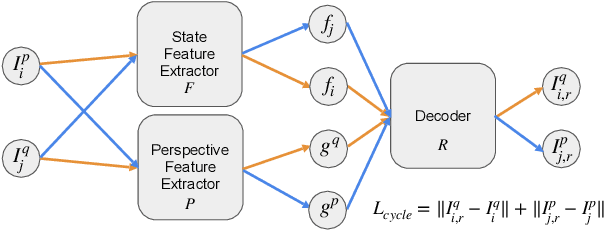
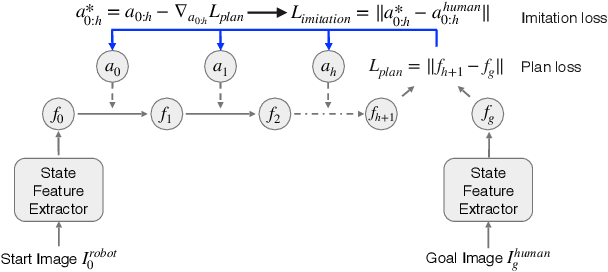
Imitation learning is a popular approach for training effective visual navigation policies. However, for legged robots collecting expert demonstrations is challenging as these robotic systems can be hard to control, move slowly, and cannot operate continuously for long periods of time. In this work, we propose a zero-shot imitation learning framework for training a visual navigation policy on a legged robot from only human demonstration (third-person perspective), allowing for high-quality navigation and cost-effective data collection. However, imitation learning from third-person perspective demonstrations raises unique challenges. First, these human demonstrations are captured from different camera perspectives, which we address via a feature disentanglement network~(FDN) that extracts perspective-agnostic state features. Second, as potential actions vary between systems, we reconstruct missing action labels by either building an inverse model of the robot's dynamics in the feature space and applying it to the demonstrations or developing an efficient Graphic User Interface (GUI) to label human demonstrations. To train a visual navigation policy we use a model-based imitation learning approach with the perspective-agnostic FDN and action-labeled demonstrations. We show that our framework can learn an effective policy for a legged robot, Laikago, from expert demonstrations in both simulated and real-world environments. Our approach is zero-shot as the robot never tries to navigate a given navigation path in the testing environment before the testing phase. We also justify our framework by performing an ablation study and comparing it with baselines.
RL-RRT: Kinodynamic Motion Planning via Learning Reachability Estimators from RL Policies
Jul 12, 2019

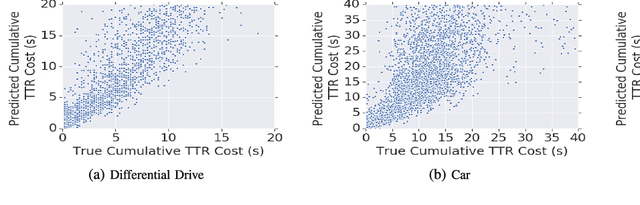

This paper addresses two challenges facing sampling-based kinodynamic motion planning: a way to identify good candidate states for local transitions and the subsequent computationally intractable steering between these candidate states. Through the combination of sampling-based planning, a Rapidly Exploring Randomized Tree (RRT) and an efficient kinodynamic motion planner through machine learning, we propose an efficient solution to long-range planning for kinodynamic motion planning. First, we use deep reinforcement learning to learn an obstacle-avoiding policy that maps a robot's sensor observations to actions, which is used as a local planner during planning and as a controller during execution. Second, we train a reachability estimator in a supervised manner, which predicts the RL policy's time to reach a state in the presence of obstacles. Lastly, we introduce RL-RRT that uses the RL policy as a local planner, and the reachability estimator as the distance function to bias tree-growth towards promising regions. We evaluate our method on three kinodynamic systems, including physical robot experiments. Results across all three robots tested indicate that RL-RRT outperforms state of the art kinodynamic planners in efficiency, and also provides a shorter path finish time than a steering function free method. The learned local planner policy and accompanying reachability estimator demonstrate transferability to the previously unseen experimental environments, making RL-RRT fast because the expensive computations are replaced with simple neural network inference. Video: https://youtu.be/dDMVMTOI8KY
* Accepted to Robotics and Automation Letters in June 2019
The Role of Compute in Autonomous Aerial Vehicles
Jun 24, 2019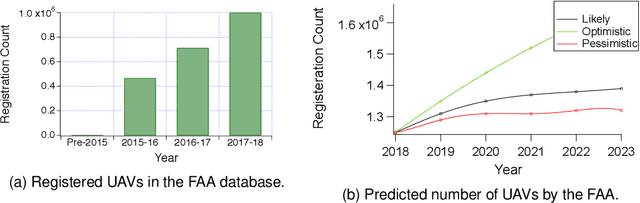
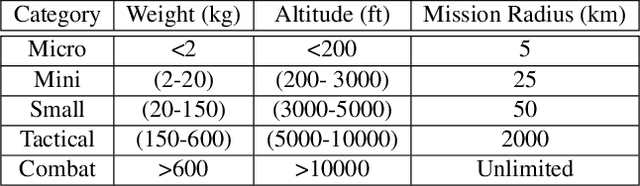

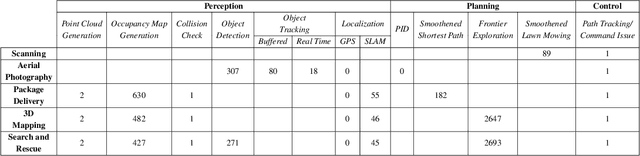
Autonomous-mobile cyber-physical machines are part of our future. Specifically, unmanned-aerial-vehicles have seen a resurgence in activity with use-cases such as package delivery. These systems face many challenges such as their low-endurance caused by limited onboard-energy, hence, improving the mission-time and energy are of importance. Such improvements traditionally are delivered through better algorithms. But our premise is that more powerful and efficient onboard-compute should also address the problem. This paper investigates how the compute subsystem, in a cyber-physical mobile machine, such as a Micro Aerial Vehicle, impacts mission-time and energy. Specifically, we pose the question as what is the role of computing for cyber-physical mobile robots? We show that compute and motion are tightly intertwined, hence a close examination of cyber and physical processes and their impact on one another is necessary. We show different impact paths through which compute impacts mission-metrics and examine them using analytical models, simulation, and end-to-end benchmarking. To enable similar studies, we open sourced MAVBench, our tool-set consisting of a closed-loop simulator and a benchmark suite. Our investigations show cyber-physical co-design, a methodology where robot's cyber and physical processes/quantities are developed with one another consideration, similar to hardware-software co-design, is necessary for optimal robot design.
Air Learning: An AI Research Platform for Algorithm-Hardware Benchmarking of Autonomous Aerial Robots
Jun 09, 2019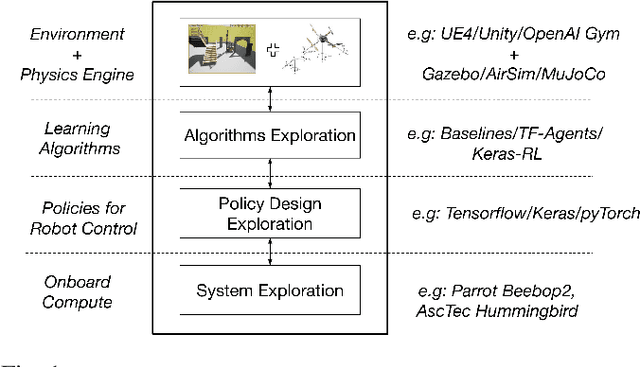
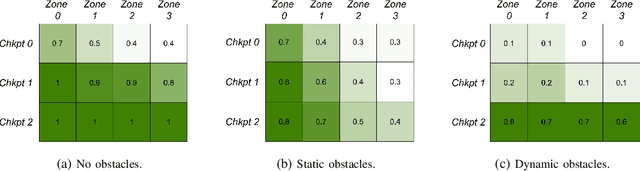
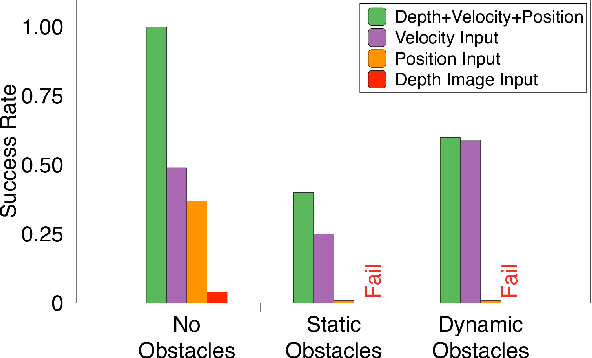
We introduce Air Learning, an AI research platform for benchmarking algorithm-hardware performance and energy efficiency trade-offs. We focus in particular on deep reinforcement learning (RL) interactions in autonomous unmanned aerial vehicles (UAVs). Equipped with a random environment generator, AirLearning exposes a UAV to a diverse set of challenging scenarios. Users can specify a task, train different RL policies and evaluate their performance and energy efficiency on a variety of hardware platforms. To show how Air Learning can be used, we seed it with Deep Q Networks (DQN) and Proximal Policy Optimization (PPO) to solve a point-to-point obstacle avoidance task in three different environments, generated using our configurable environment generator. We train the two algorithms using curriculum learning and non-curriculum-learning. Air Learning assesses the trained policies' performance, under a variety of quality-of-flight (QoF) metrics, such as the energy consumed, endurance and the average trajectory length, on resource-constrained embedded platforms like a Ras-Pi. We find that the trajectories on an embedded Ras-Pi are vastly different from those predicted on a high-end desktop system, resulting in up to 79.43% longer trajectories in one of the environments. To understand the source of such differences, we use Air Learning to artificially degrade desktop performance to mimic what happens on a low-end embedded system. QoF metrics with hardware-in-the-loop characterize those differences and expose how the choice of onboard compute affects the aerial robot's performance. We also conduct reliability studies to demonstrate how Air Learning can help understand how sensor failures affect the learned policies. All put together, Air Learning enables a broad class of RL studies on UAVs. More information and code for Air Learning can be found here: http://bit.ly/2JNAVb6.
MAVBench: Micro Aerial Vehicle Benchmarking
Jun 01, 2019
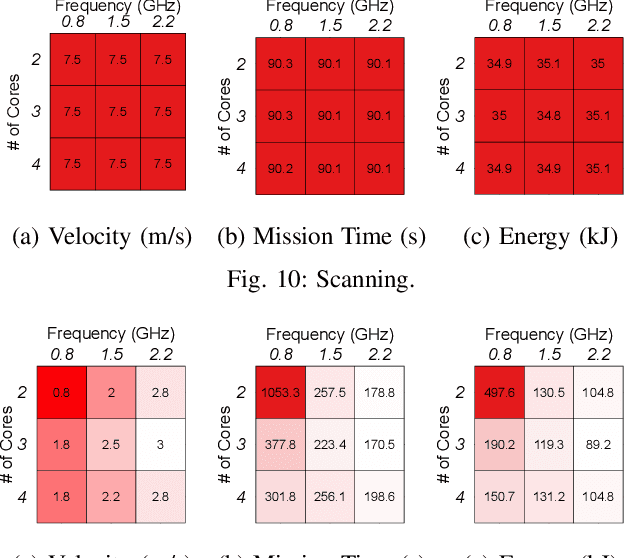
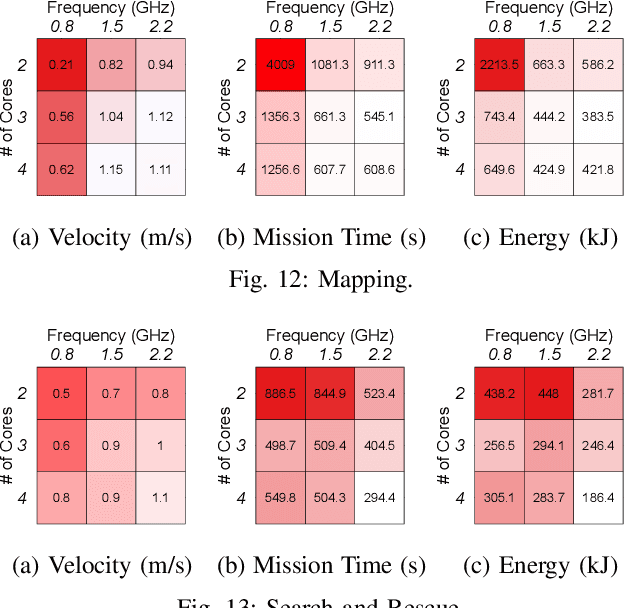
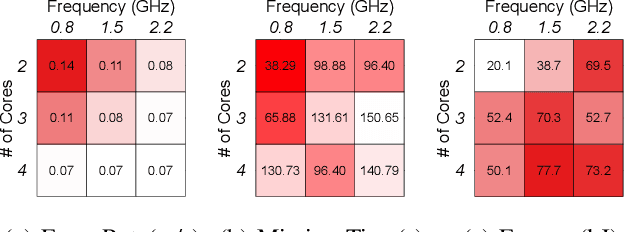
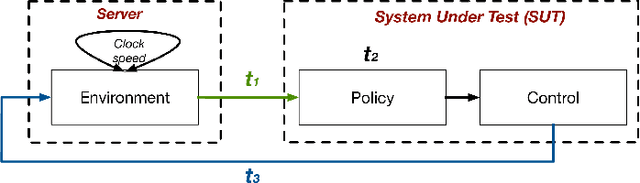
Unmanned Aerial Vehicles (UAVs) are getting closer to becoming ubiquitous in everyday life. Among them, Micro Aerial Vehicles (MAVs) have seen an outburst of attention recently, specifically in the area with a demand for autonomy. A key challenge standing in the way of making MAVs autonomous is that researchers lack the comprehensive understanding of how performance, power, and computational bottlenecks affect MAV applications. MAVs must operate under a stringent power budget, which severely limits their flight endurance time. As such, there is a need for new tools, benchmarks, and methodologies to foster the systematic development of autonomous MAVs. In this paper, we introduce the `MAVBench' framework which consists of a closed-loop simulator and an end-to-end application benchmark suite. A closed-loop simulation platform is needed to probe and understand the intra-system (application data flow) and inter-system (system and environment) interactions in MAV applications to pinpoint bottlenecks and identify opportunities for hardware and software co-design and optimization. In addition to the simulator, MAVBench provides a benchmark suite, the first of its kind, consisting of a variety of MAV applications designed to enable computer architects to perform characterization and develop future aerial computing systems. Using our open source, end-to-end experimental platform, we uncover a hidden, and thus far unexpected compute to total system energy relationship in MAVs. Furthermore, we explore the role of compute by presenting three case studies targeting performance, energy and reliability. These studies confirm that an efficient system design can improve MAV's battery consumption by up to 1.8X.
Evolving Rewards to Automate Reinforcement Learning
May 18, 2019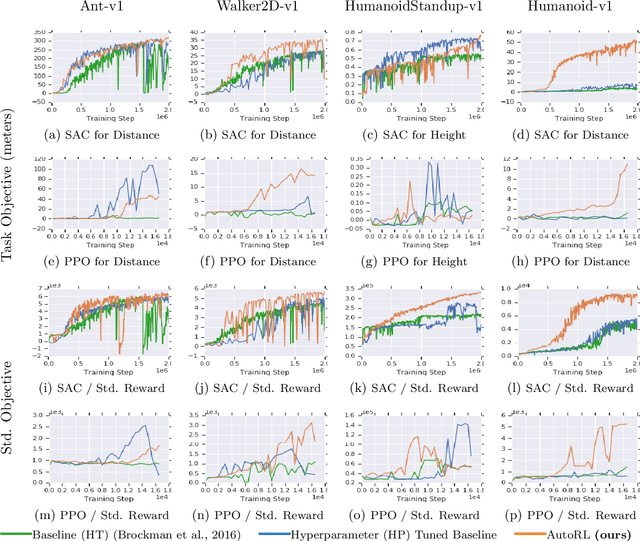

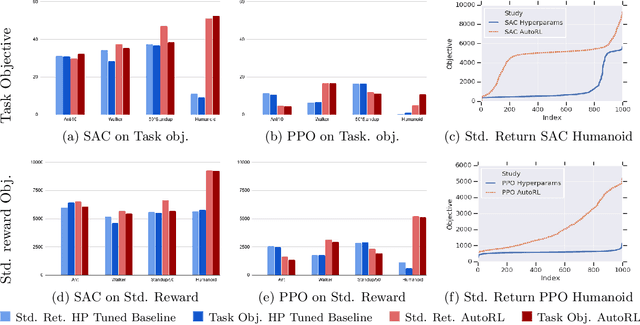

Many continuous control tasks have easily formulated objectives, yet using them directly as a reward in reinforcement learning (RL) leads to suboptimal policies. Therefore, many classical control tasks guide RL training using complex rewards, which require tedious hand-tuning. We automate the reward search with AutoRL, an evolutionary layer over standard RL that treats reward tuning as hyperparameter optimization and trains a population of RL agents to find a reward that maximizes the task objective. AutoRL, evaluated on four Mujoco continuous control tasks over two RL algorithms, shows improvements over baselines, with the the biggest uplift for more complex tasks. The video can be found at: \url{https://youtu.be/svdaOFfQyC8}.
Long-Range Indoor Navigation with PRM-RL
Feb 25, 2019
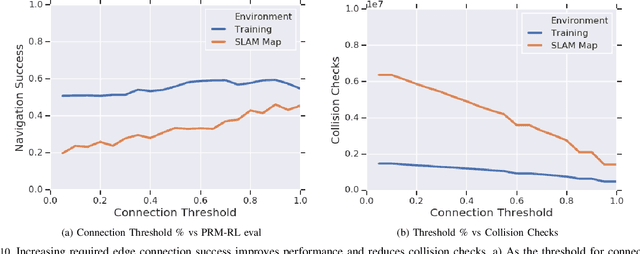
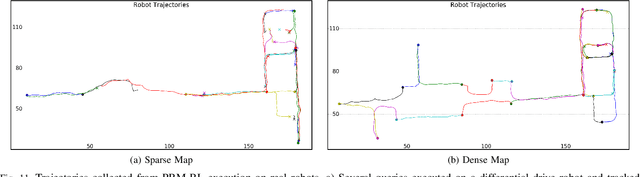
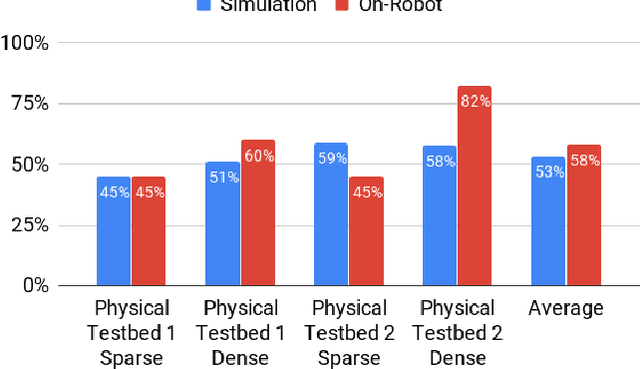
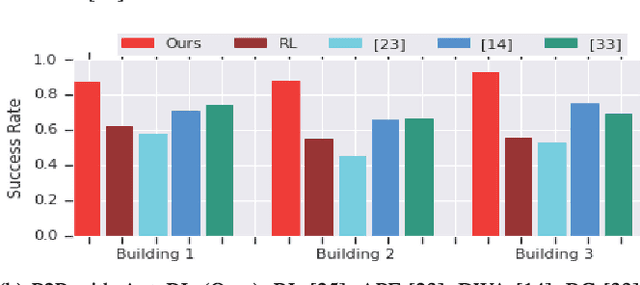
Long-range indoor navigation requires guiding robots with noisy sensors and controls through cluttered environments along paths that span a variety of buildings. We achieve this with PRM-RL, a hierarchical robot navigation method in which reinforcement learning agents that map noisy sensors to robot controls learn to solve short-range obstacle avoidance tasks, and then sampling-based planners map where these agents can reliably navigate in simulation; these roadmaps and agents are then deployed on-robot, guiding the robot along the shortest path where the agents are likely to succeed. Here we use Probabilistic Roadmaps (PRMs) as the sampling-based planner and AutoRL as the reinforcement learning method in the indoor navigation context. We evaluate the method in simulation for kinematic differential drive and kinodynamic car-like robots in several environments, and on-robot for differential-drive robots at two physical sites. Our results show PRM-RL with AutoRL is more successful than several baselines, is robust to noise, and can guide robots over hundreds of meters in the face of noise and obstacles in both simulation and on-robot, including over 3.3 kilometers of physical robot navigation.
Learning Navigation Behaviors End-to-End with AutoRL
Feb 01, 2019

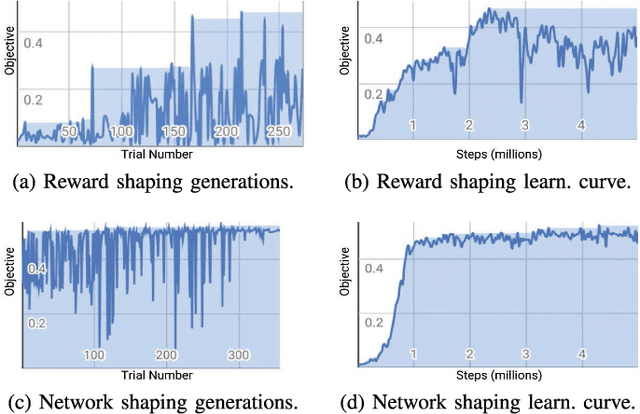
We learn end-to-end point-to-point and path-following navigation behaviors that avoid moving obstacles. These policies receive noisy lidar observations and output robot linear and angular velocities. The policies are trained in small, static environments with AutoRL, an evolutionary automation layer around Reinforcement Learning (RL) that searches for a deep RL reward and neural network architecture with large-scale hyper-parameter optimization. AutoRL first finds a reward that maximizes task completion, and then finds a neural network architecture that maximizes the cumulative of the found reward. Empirical evaluations, both in simulation and on-robot, show that AutoRL policies do not suffer from the catastrophic forgetfulness that plagues many other deep reinforcement learning algorithms, generalize to new environments and moving obstacles, are robust to sensor, actuator, and localization noise, and can serve as robust building blocks for larger navigation tasks. Our path-following and point-to-point policies are respectively 23% and 26% more successful than comparison methods across new environments. Video at: https://youtu.be/0UwkjpUEcbI
Lyapunov-based Safe Policy Optimization for Continuous Control
Jan 28, 2019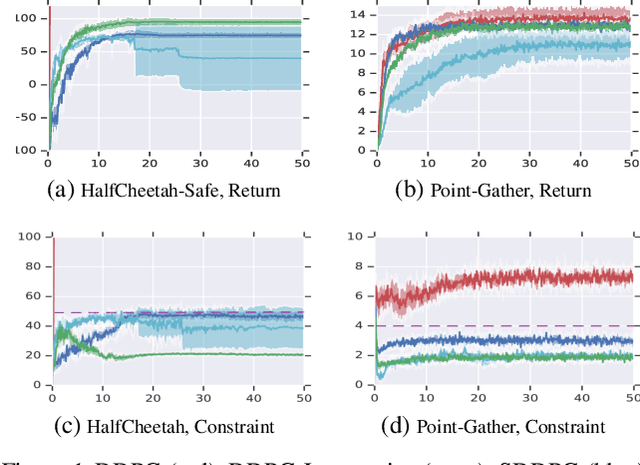
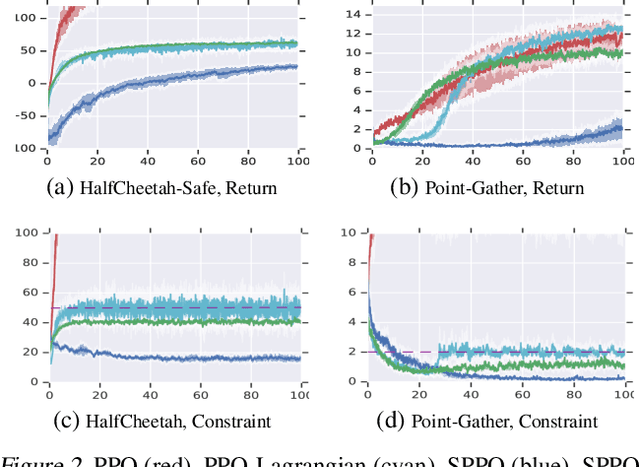
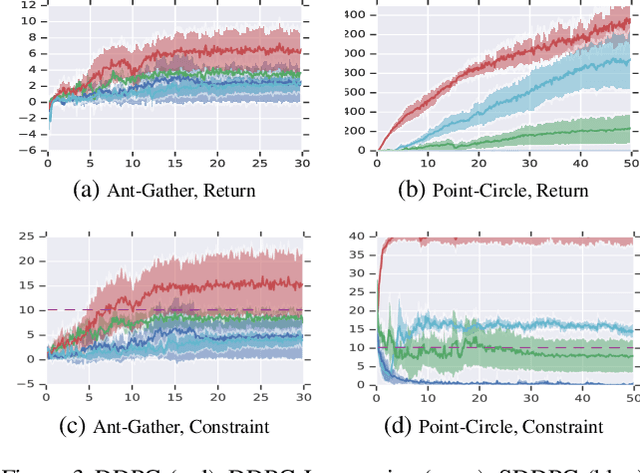
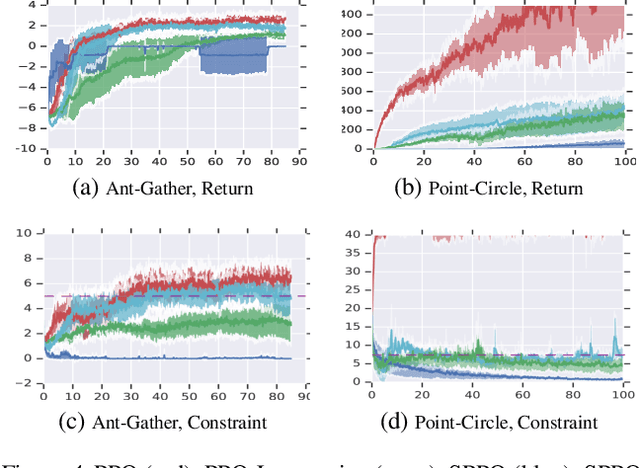
We study continuous action reinforcement learning problems in which it is crucial that the agent interacts with the environment only through {\em safe} policies, i.e.,~policies that do not take the agent to undesirable situations. We formulate these problems as {\em constrained} Markov decision processes (CMDPs) and present safe policy optimization algorithms that are based on a {\em Lyapunov} approach to solve them. Our algorithms can use any standard policy gradient (PG) method, such as deep deterministic policy gradient (DDPG) or proximal policy optimization (PPO), to train a neural network policy, while guaranteeing near-constraint satisfaction for every policy update by projecting either the policy parameter or the action onto the set of feasible solutions induced by the state-dependent linearized Lyapunov constraints. Compared to the existing constrained PG algorithms, ours are more data efficient as they are able to utilize both on-policy and off-policy data. Moreover, our action-projection algorithm often leads to less conservative policy updates and allows for natural integration into an end-to-end PG training pipeline. We evaluate our algorithms and compare them with the state-of-the-art baselines on several simulated (MuJoCo) tasks, as well as a real-world indoor robot navigation problem, demonstrating their effectiveness in terms of balancing performance and constraint satisfaction. Videos of the experiments can be found in the following link: https://drive.google.com/file/d/1pzuzFqWIE710bE2U6DmS59AfRzqK2Kek/view?usp=sharing .