 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Nets: What have they ever done for Vision?
May 10, 2018



This is an opinion paper about the strengths and weaknesses of Deep Nets. They are at the center of recent progress on Artificial Intelligence and are of growing importance in Cognitive Science and Neuroscience since they enable the development of computational models that can deal with a large range of visually realistic stimuli and visual tasks. They have clear limitations but they also have enormous successes. There is also gradual, though incomplete, understanding of their inner workings. It seems unlikely that Deep Nets in their current form will be the best long-term solution either for building general purpose intelligent machines or for understanding the mind/brain, but it is likely that many aspects of them will remain. At present Deep Nets do very well on specific types of visual tasks and on specific benchmarked datasets. But Deep Nets are much less general purpose, flexible, and adaptive than the human visual system. Moreover, methods like Deep Nets may run into fundamental difficulties when faced with the enormous complexity of natural images. To illustrate our main points, while keeping the references small, this paper is slightly biased towards work from our group.
Joint Shape Representation and Classification for Detecting PDAC
Apr 27, 2018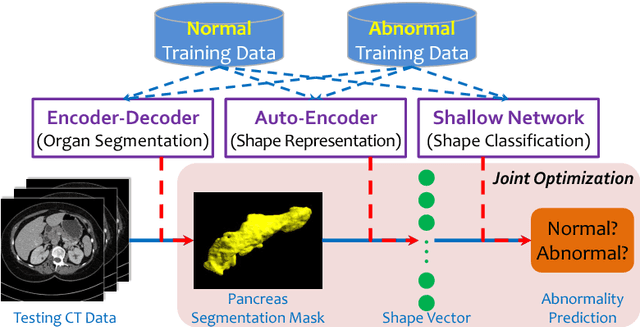
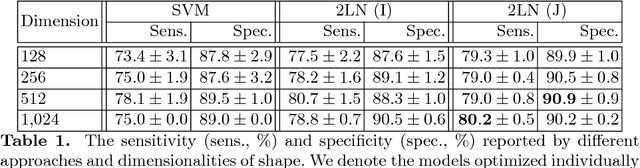
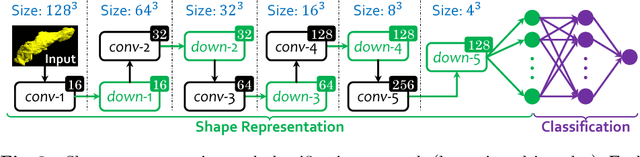
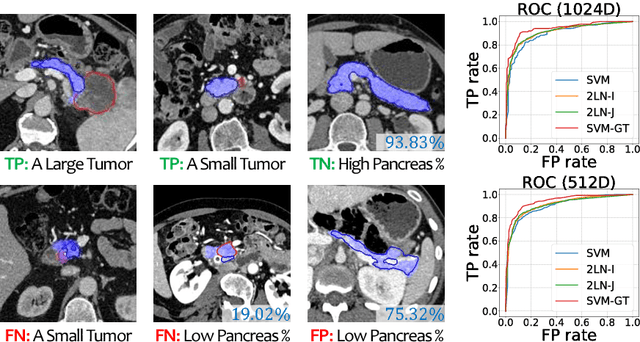
We aim to detect pancreatic ductal adenocarcinoma (PDAC) in abdominal CT scans, which sheds light on early diagnosis of pancreatic cancer. This is a 3D volume classification task with little training data. We propose a two-stage framework, which first segments the pancreas into a binary mask, then compresses the mask into a shape vector and performs abnormality classification. Shape representation and classification are performed in a {\em joint} manner, both to exploit the knowledge that PDAC often changes the {\bf shape} of the pancreas and to prevent over-fitting. Experiments are performed on $300$ normal scans and $156$ PDAC cases. We achieve a specificity of $90.2\%$ (false alarm occurs on less than $1/10$ normal cases) at a sensitivity of $80.2\%$ (less than $1/5$ PDAC cases are not detected), which show promise for clinical applications.
Abdominal multi-organ segmentation with organ-attention networks and statistical fusion
Apr 23, 2018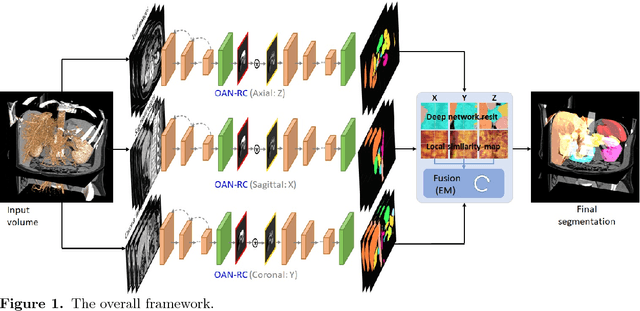
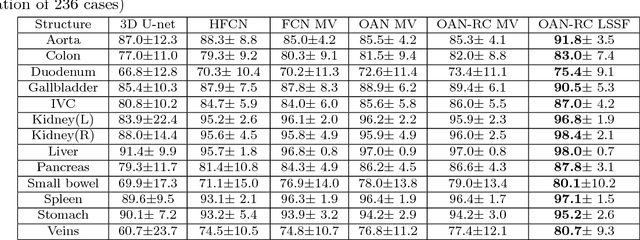
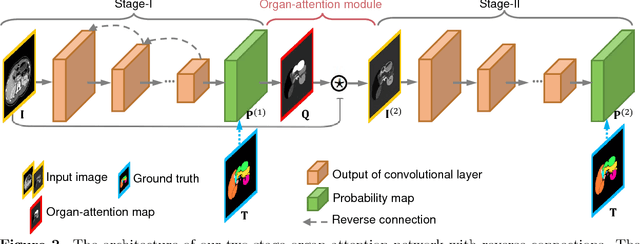
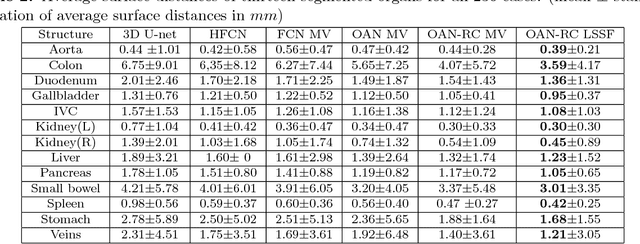
Accurate and robust segmentation of abdominal organs on CT is essential for many clinical applications such as computer-aided diagnosis and computer-aided surgery. But this task is challenging due to the weak boundaries of organs, the complexity of the background, and the variable sizes of different organs. To address these challenges, we introduce a novel framework for multi-organ segmentation by using organ-attention networks with reverse connections (OAN-RCs) which are applied to 2D views, of the 3D CT volume, and output estimates which are combined by statistical fusion exploiting structural similarity. OAN is a two-stage deep convolutional network, where deep network features from the first stage are combined with the original image, in a second stage, to reduce the complex background and enhance the discriminative information for the target organs. RCs are added to the first stage to give the lower layers semantic information thereby enabling them to adapt to the sizes of different organs. Our networks are trained on 2D views enabling us to use holistic information and allowing efficient computation. To compensate for the limited cross-sectional information of the original 3D volumetric CT, multi-sectional images are reconstructed from the three different 2D view directions. Then we combine the segmentation results from the different views using statistical fusion, with a novel term relating the structural similarity of the 2D views to the original 3D structure. To train the network and evaluate results, 13 structures were manually annotated by four human raters and confirmed by a senior expert on 236 normal cases. We tested our algorithm and computed Dice-Sorensen similarity coefficients and surface distances for evaluating our estimates of the 13 structures. Our experiments show that the proposed approach outperforms 2D- and 3D-patch based state-of-the-art methods.
Recurrent Saliency Transformation Network: Incorporating Multi-Stage Visual Cues for Small Organ Segmentation
Apr 08, 2018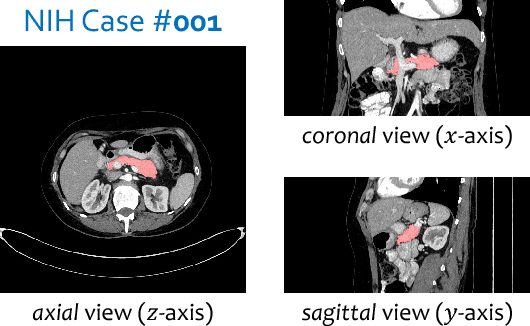
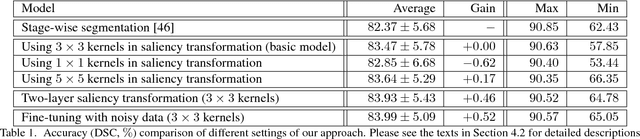
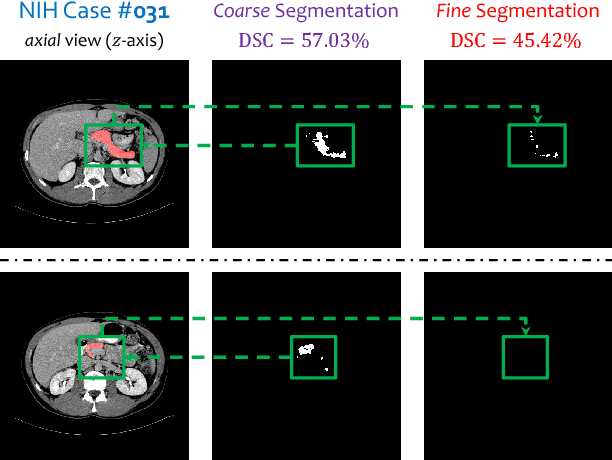
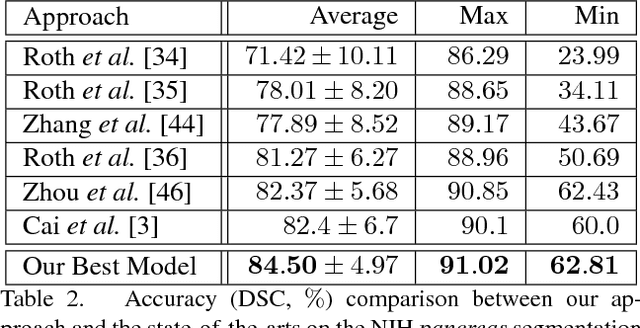
We aim at segmenting small organs (e.g., the pancreas) from abdominal CT scans. As the target often occupies a relatively small region in the input image, deep neural networks can be easily confused by the complex and variable background. To alleviate this, researchers proposed a coarse-to-fine approach, which used prediction from the first (coarse) stage to indicate a smaller input region for the second (fine) stage. Despite its effectiveness, this algorithm dealt with two stages individually, which lacked optimizing a global energy function, and limited its ability to incorporate multi-stage visual cues. Missing contextual information led to unsatisfying convergence in iterations, and that the fine stage sometimes produced even lower segmentation accuracy than the coarse stage. This paper presents a Recurrent Saliency Transformation Network. The key innovation is a saliency transformation module, which repeatedly converts the segmentation probability map from the previous iteration as spatial weights and applies these weights to the current iteration. This brings us two-fold benefits. In training, it allows joint optimization over the deep networks dealing with different input scales. In testing, it propagates multi-stage visual information throughout iterations to improve segmentation accuracy. Experiments in the NIH pancreas segmentation dataset demonstrate the state-of-the-art accuracy, which outperforms the previous best by an average of over 2%. Much higher accuracies are also reported on several small organs in a larger dataset collected by ourselves. In addition, our approach enjoys better convergence properties, making it more efficient and reliable in practice.
Single-Shot Object Detection with Enriched Semantics
Apr 08, 2018
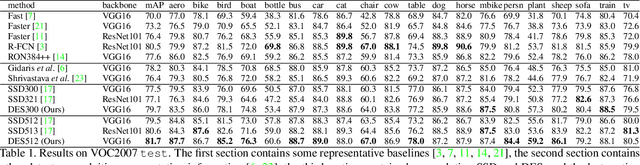
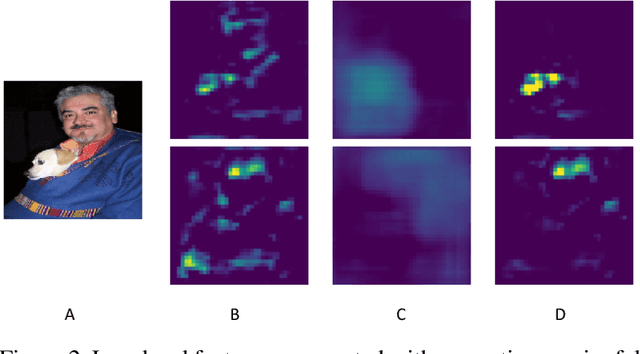
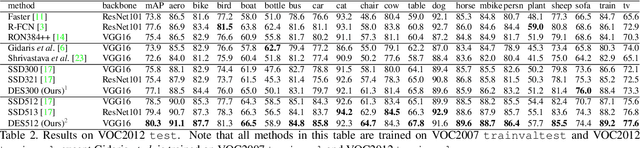
We propose a novel single shot object detection network named Detection with Enriched Semantics (DES). Our motivation is to enrich the semantics of object detection features within a typical deep detector, by a semantic segmentation branch and a global activation module. The segmentation branch is supervised by weak segmentation ground-truth, i.e., no extra annotation is required. In conjunction with that, we employ a global activation module which learns relationship between channels and object classes in a self-supervised manner. Comprehensive experimental results on both PASCAL VOC and MS COCO detection datasets demonstrate the effectiveness of the proposed method. In particular, with a VGG16 based DES, we achieve an mAP of 81.7 on VOC2007 test and an mAP of 32.8 on COCO test-dev with an inference speed of 31.5 milliseconds per image on a Titan Xp GPU. With a lower resolution version, we achieve an mAP of 79.7 on VOC2007 with an inference speed of 13.0 milliseconds per image.
Training Multi-organ Segmentation Networks with Sample Selection by Relaxed Upper Confident Bound
Apr 07, 2018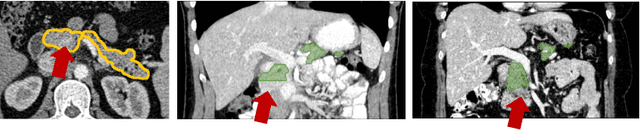
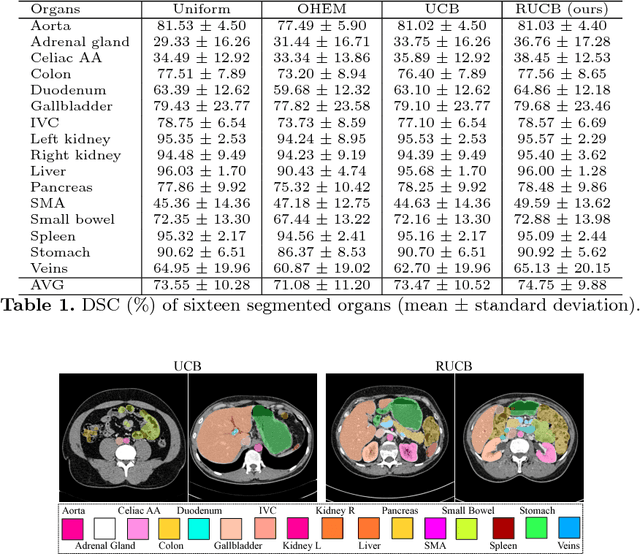
Deep convolutional neural networks (CNNs), especially fully convolutional networks, have been widely applied to automatic medical image segmentation problems, e.g., multi-organ segmentation. Existing CNN-based segmentation methods mainly focus on looking for increasingly powerful network architectures, but pay less attention to data sampling strategies for training networks more effectively. In this paper, we present a simple but effective sample selection method for training multi-organ segmentation networks. Sample selection exhibits an exploitation-exploration strategy, i.e., exploiting hard samples and exploring less frequently visited samples. Based on the fact that very hard samples might have annotation errors, we propose a new sample selection policy, named Relaxed Upper Confident Bound (RUCB). Compared with other sample selection policies, e.g., Upper Confident Bound (UCB), it exploits a range of hard samples rather than being stuck with a small set of very hard ones, which mitigates the influence of annotation errors during training. We apply this new sample selection policy to training a multi-organ segmentation network on a dataset containing 120 abdominal CT scans and show that it boosts segmentation performance significantly.
Multi-Scale Spatially-Asymmetric Recalibration for Image Classification
Apr 03, 2018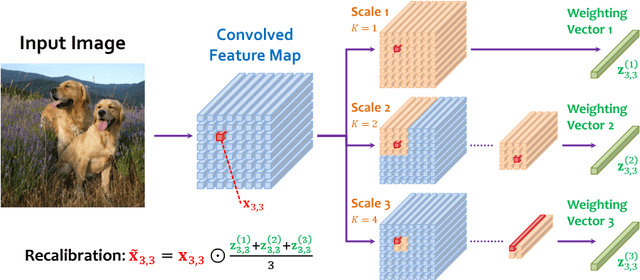
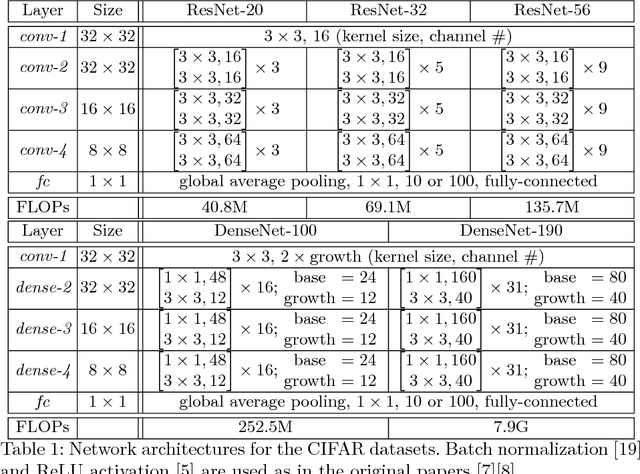
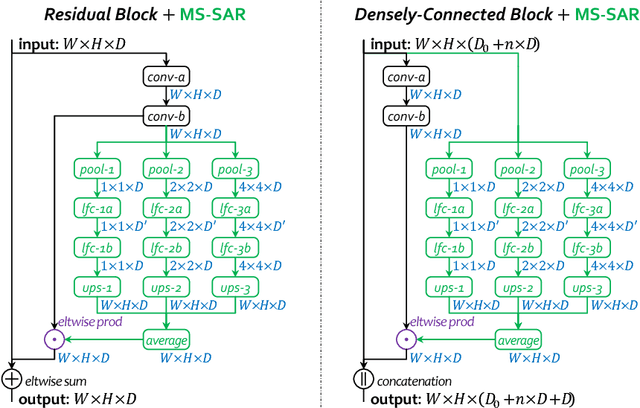
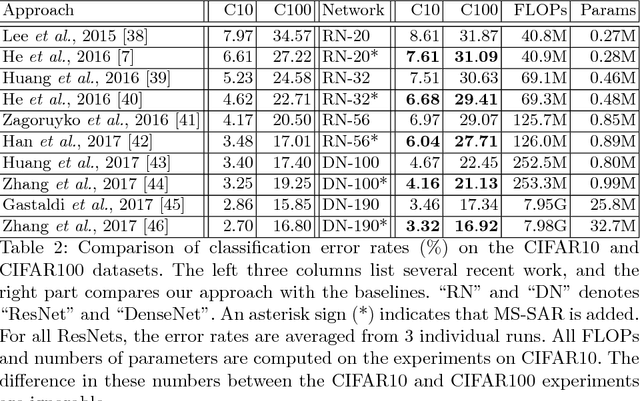
Convolution is spatially-symmetric, i.e., the visual features are independent of its position in the image, which limits its ability to utilize contextual cues for visual recognition. This paper addresses this issue by introducing a recalibration process, which refers to the surrounding region of each neuron, computes an importance value and multiplies it to the original neural response. Our approach is named multi-scale spatially-asymmetric recalibration (MS-SAR), which extracts visual cues from surrounding regions at multiple scales, and designs a weighting scheme which is asymmetric in the spatial domain. MS-SAR is implemented in an efficient way, so that only small fractions of extra parameters and computations are required. We apply MS-SAR to several popular building blocks, including the residual block and the densely-connected block, and demonstrate its superior performance in both CIFAR and ILSVRC2012 classification tasks.
DeepVoting: A Robust and Explainable Deep Network for Semantic Part Detection under Partial Occlusion
Mar 29, 2018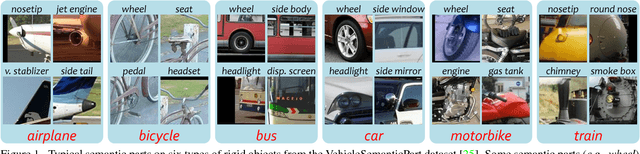
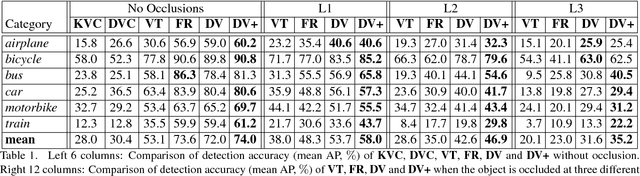
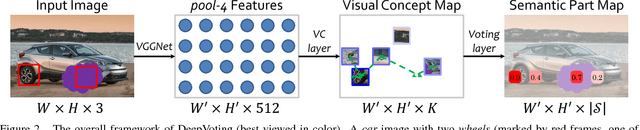
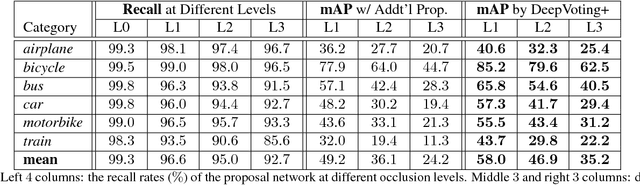
In this paper, we study the task of detecting semantic parts of an object, e.g., a wheel of a car, under partial occlusion. We propose that all models should be trained without seeing occlusions while being able to transfer the learned knowledge to deal with occlusions. This setting alleviates the difficulty in collecting an exponentially large dataset to cover occlusion patterns and is more essential. In this scenario, the proposal-based deep networks, like RCNN-series, often produce unsatisfactory results, because both the proposal extraction and classification stages may be confused by the irrelevant occluders. To address this, [25] proposed a voting mechanism that combines multiple local visual cues to detect semantic parts. The semantic parts can still be detected even though some visual cues are missing due to occlusions. However, this method is manually-designed, thus is hard to be optimized in an end-to-end manner. In this paper, we present DeepVoting, which incorporates the robustness shown by [25] into a deep network, so that the whole pipeline can be jointly optimized. Specifically, it adds two layers after the intermediate features of a deep network, e.g., the pool-4 layer of VGGNet. The first layer extracts the evidence of local visual cues, and the second layer performs a voting mechanism by utilizing the spatial relationship between visual cues and semantic parts. We also propose an improved version DeepVoting+ by learning visual cues from context outside objects. In experiments, DeepVoting achieves significantly better performance than several baseline methods, including Faster-RCNN, for semantic part detection under occlusion. In addition, DeepVoting enjoys explainability as the detection results can be diagnosed via looking up the voting cues.
NDDR-CNN: Layer-wise Feature Fusing in Multi-Task CNN by Neural Discriminative Dimensionality Reduction
Mar 13, 2018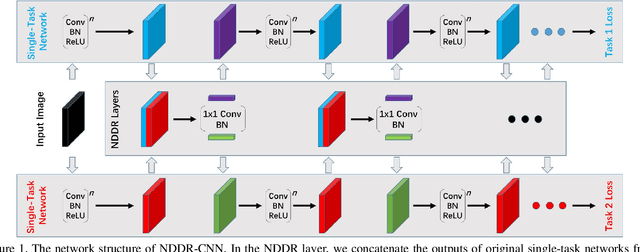
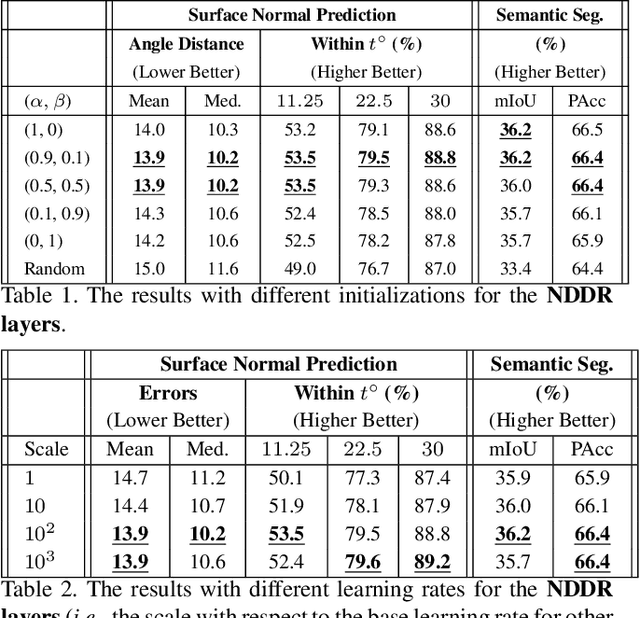
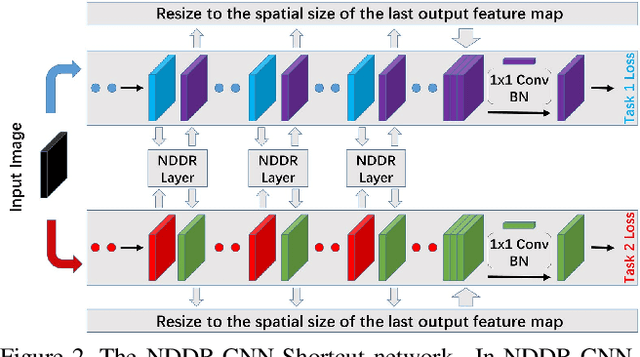
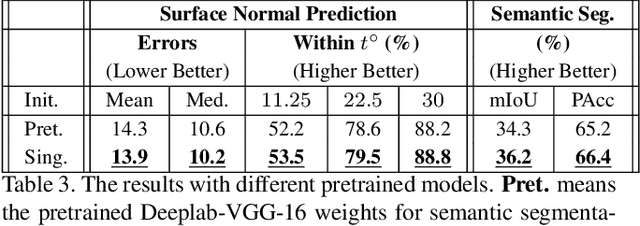
State-of-the-art Convolutional Neural Network (CNN) benefits much from multi-task learning (MTL), which learns multiple related tasks simultaneously to obtain shared or mutually related representations for different tasks. The most widely used MTL CNN structure is based on an empirical or heuristic split on a specific layer (e.g., the last convolutional layer) to minimize multiple task-specific losses. However, this heuristic sharing/splitting strategy may be harmful to the final performance of one or multiple tasks. In this paper, we propose a novel CNN structure for MTL, which enables automatic feature fusing at every layer. Specifically, we first concatenate features from different tasks according to their channel dimension, and then formulate the feature fusing problem as discriminative dimensionality reduction. We show that this discriminative dimensionality reduction can be fulfilled by 1x1 Convolution, Batch Normalization, and Weight Decay in one CNN, which we refer to as Neural Discriminative Dimensionality Reduction (NDDR). We perform detailed ablation analysis for different configurations in training the proposed NDDR-CNN network. The experiments carried out on different network structures and different task sets demonstrate the promising performance and desirable generalizability of our proposed method.
Generating Multiple Diverse Hypotheses for Human 3D Pose Consistent with 2D Joint Detections
Aug 20, 2017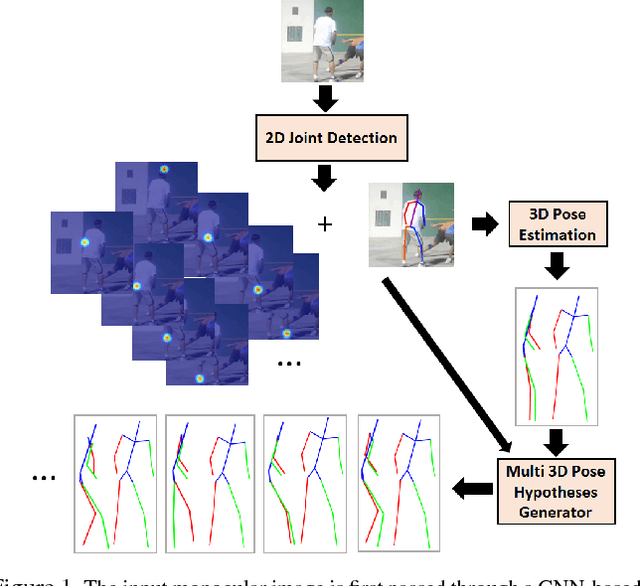
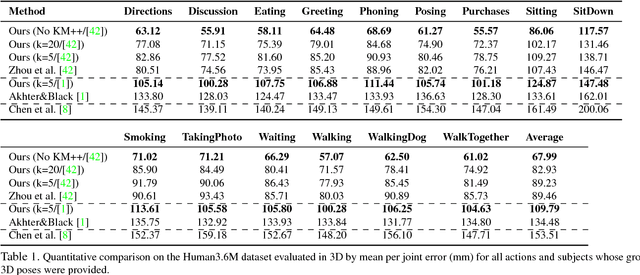
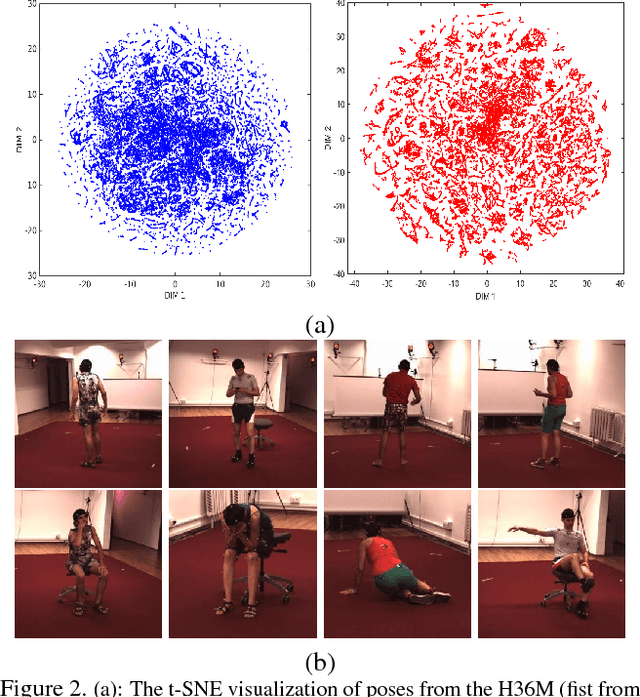
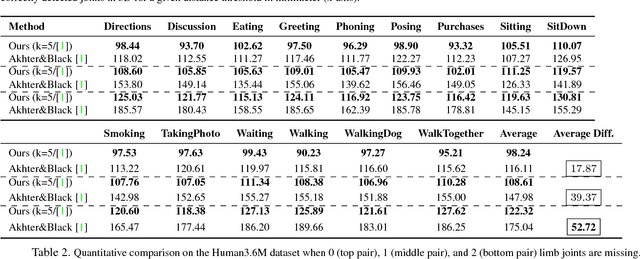
We propose a method to generate multiple diverse and valid human pose hypotheses in 3D all consistent with the 2D detection of joints in a monocular RGB image. We use a novel generative model uniform (unbiased) in the space of anatomically plausible 3D poses. Our model is compositional (produces a pose by combining parts) and since it is restricted only by anatomical constraints it can generalize to every plausible human 3D pose. Removing the model bias intrinsically helps to generate more diverse 3D pose hypotheses. We argue that generating multiple pose hypotheses is more reasonable than generating only a single 3D pose based on the 2D joint detection given the depth ambiguity and the uncertainty due to occlusion and imperfect 2D joint detection. We hope that the idea of generating multiple consistent pose hypotheses can give rise to a new line of future work that has not received much attention in the literature. We used the Human3.6M dataset for empirical evaluation.