 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexTransfer: Real World Multi-fingered Dexterous Grasping with Minimal Human Demonstrations
Sep 28, 2022

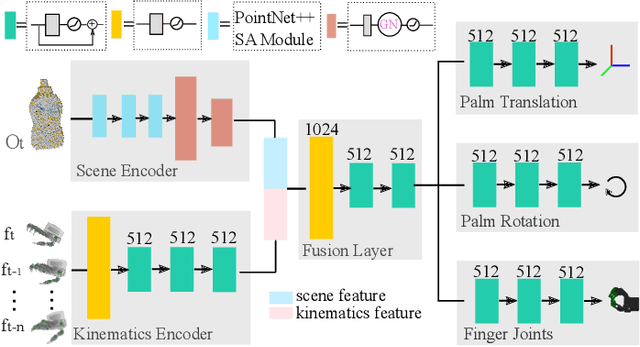
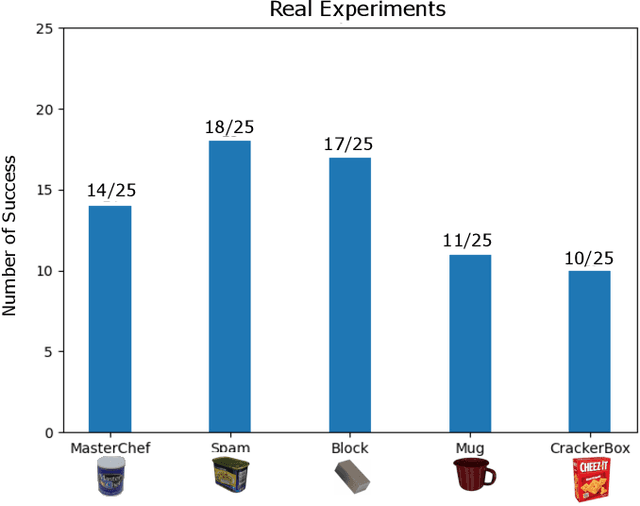
Teaching a multi-fingered dexterous robot to grasp objects in the real world has been a challenging problem due to its high dimensional state and action space. We propose a robot-learning system that can take a small number of human demonstrations and learn to grasp unseen object poses given partially occluded observations. Our system leverages a small motion capture dataset and generates a large dataset with diverse and successful trajectories for a multi-fingered robot gripper. By adding domain randomization, we show that our dataset provides robust grasping trajectories that can be transferred to a policy learner. We train a dexterous grasping policy that takes the point clouds of the object as input and predicts continuous actions to grasp objects from different initial robot states. We evaluate the effectiveness of our system on a 22-DoF floating Allegro Hand in simulation and a 23-DoF Allegro robot hand with a KUKA arm in real world. The policy learned from our dataset can generalize well on unseen object poses in both simulation and the real world
Metric Effects based on Fluctuations in values of k in Nearest Neighbor Regressor
Aug 24, 2022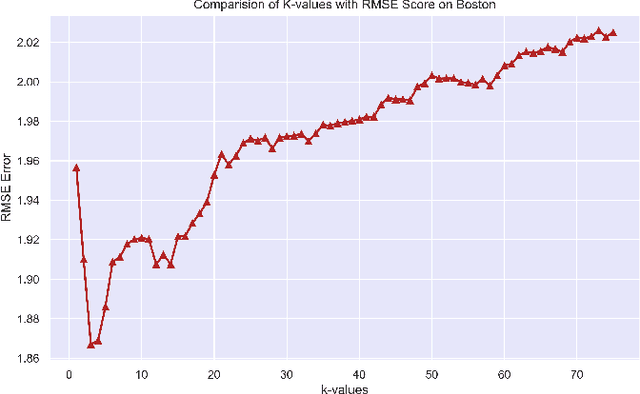
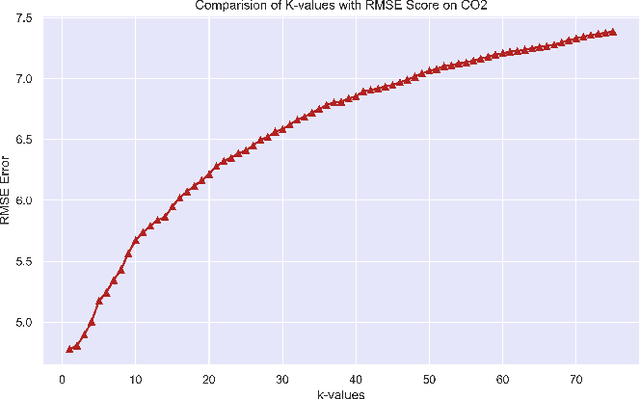
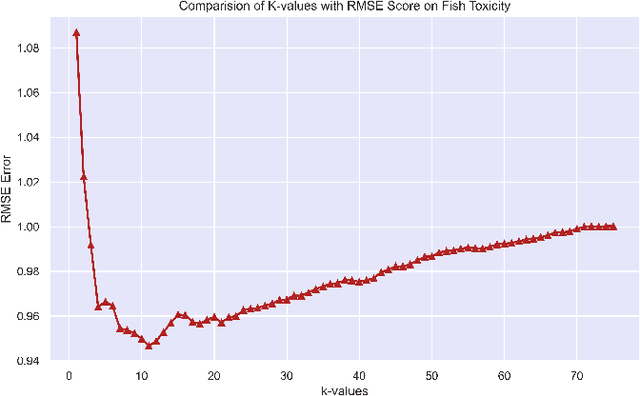
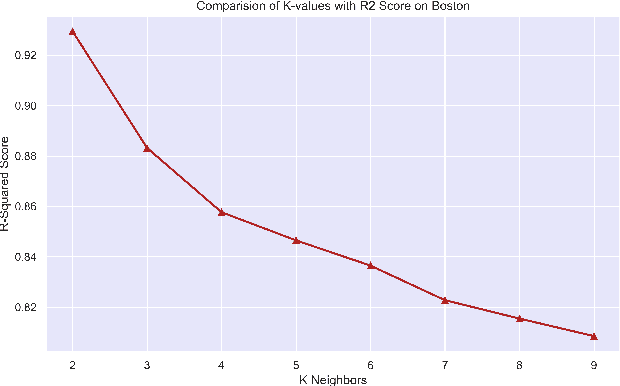
Regression branch of Machine Learning purely focuses on prediction of continuous values. The supervised learning branch has many regression based methods with parametric and non-parametric learning models. In this paper we aim to target a very subtle point related to distance based regression model. The distance based model used is K-Nearest Neighbors Regressor which is a supervised non-parametric method. The point that we want to prove is the effect of k parameter of the model and its fluctuations affecting the metrics. The metrics that we use are Root Mean Squared Error and R-Squared Goodness of Fit with their visual representation of values with respect to k values.
Performance Comparison of Simple Transformer and Res-CNN-BiLSTM for Cyberbullying Classification
Jun 05, 2022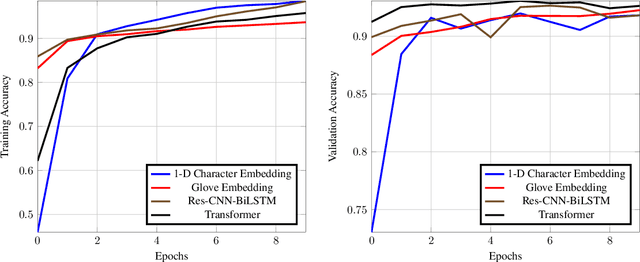
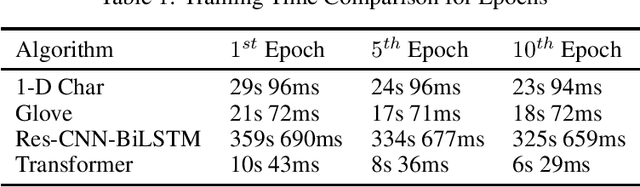
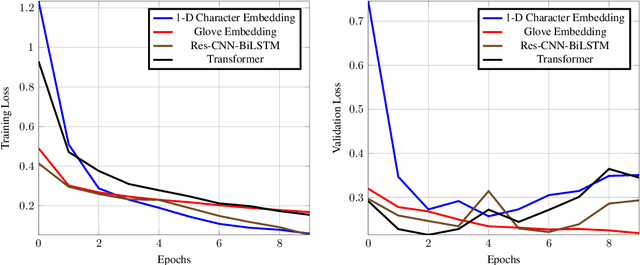
The task of text classification using Bidirectional based LSTM architectures is computationally expensive and time consuming to train. For this, transformers were discovered which effectively give good performance as compared to the traditional deep learning architectures. In this paper we present a performance based comparison between simple transformer based network and Res-CNN-BiLSTM based network for cyberbullying text classification problem. The results obtained show that transformer we trained with 0.65 million parameters has significantly being able to beat the performance of Res-CNN-BiLSTM with 48.82 million parameters for faster training speeds and more generalized metrics. The paper also compares the 1-dimensional character level embedding network and 100-dimensional glove embedding network with transformer.
Residual-Concatenate Neural Network with Deep Regularization Layers for Binary Classification
May 25, 2022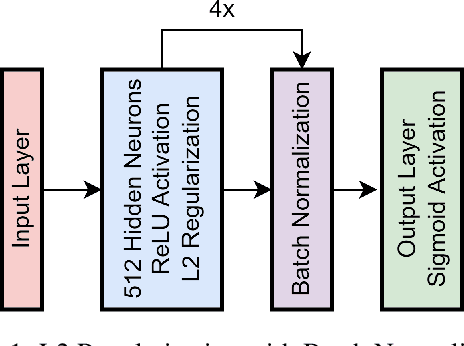

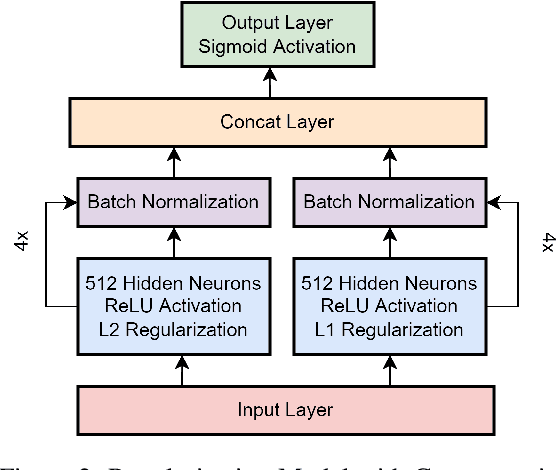
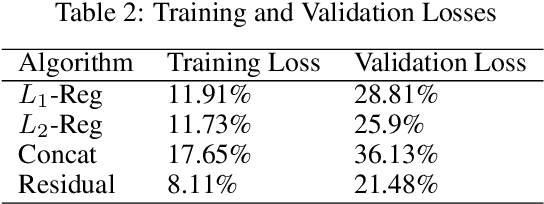
Many complex Deep Learning models are used with different variations for various prognostication tasks. The higher learning parameters not necessarily ensure great accuracy. This can be solved by considering changes in very deep models with many regularization based techniques. In this paper we train a deep neural network that uses many regularization layers with residual and concatenation process for best fit with Polycystic Ovary Syndrome Diagnosis prognostication. The network was built with improvements from every step of failure to meet the needs of the data and achieves an accuracy of 99.3% seamlessly.
Jack and Masters of All Trades: One-Pass Learning of a Set of Model Sets from Foundation Models
May 02, 2022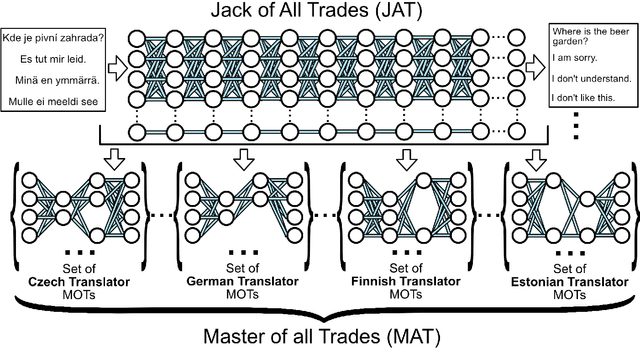
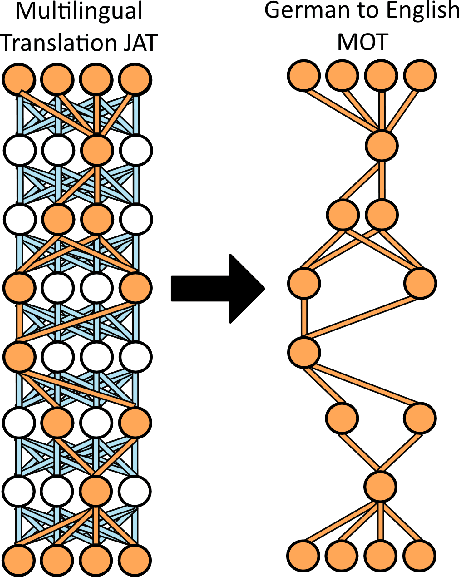
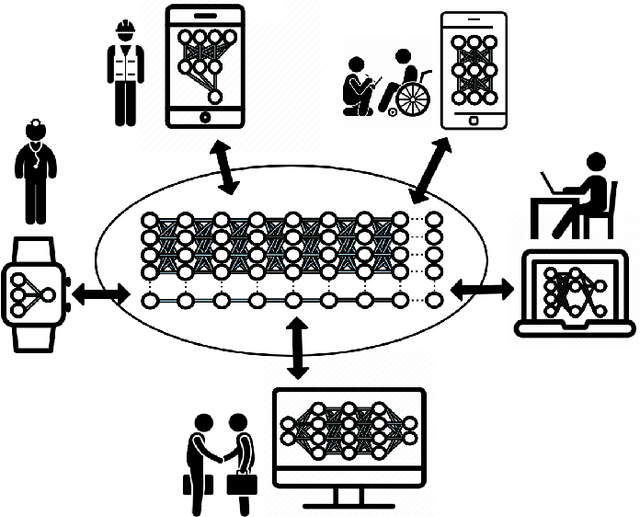
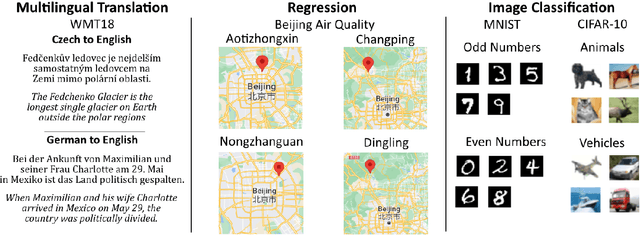
For deep learning, size is power. Massive neural nets trained on broad data for a spectrum of tasks are at the forefront of artificial intelligence. These foundation models or 'Jacks of All Trades' (JATs), when fine-tuned for downstream tasks, are gaining importance in driving deep learning advancements. However, environments with tight resource constraints, changing objectives and intentions, or varied task requirements, could limit the real-world utility of a singular JAT. Hence, in tandem with current trends towards building increasingly large JATs, this paper conducts an initial exploration into concepts underlying the creation of a diverse set of compact machine learning model sets. Composed of many smaller and specialized models, we formulate the Set of Sets to simultaneously fulfil many task settings and environmental conditions. A means to arrive at such a set tractably in one pass of a neuroevolutionary multitasking algorithm is presented for the first time, bringing us closer to models that are collectively 'Masters of All Trades'.
Res-CNN-BiLSTM Network for overcoming Mental Health Disturbances caused due to Cyberbullying through Social Media
Apr 20, 2022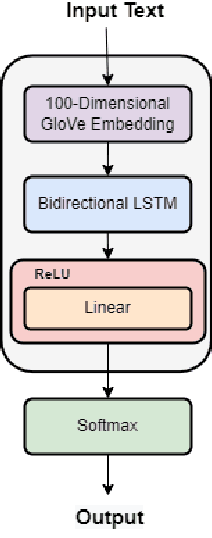
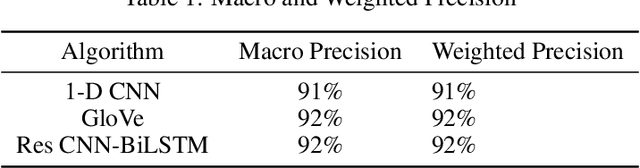

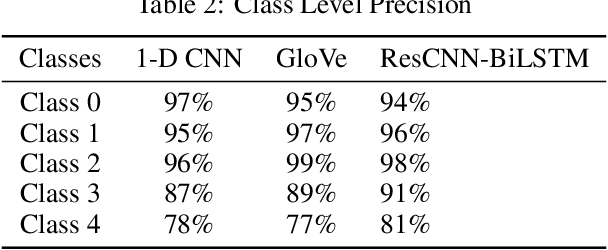
Mental Health Disturbance has many reasons and cyberbullying is one of the major causes that does exploitation using social media as an instrument. The cyberbullying is done on the basis of Religion, Ethnicity, Age and Gender which is a sensitive psychological issue. This can be addressed using Natural Language Processing with Deep Learning, since social media is the medium and it generates massive form of data in textual form. Such data can be leveraged to find the semantics and derive what type of cyberbullying is done and who are the people involved for early measures. Since deriving semantics is essential we proposed a Hybrid Deep Learning Model named 1-Dimensional CNN-Bidirectional-LSTMs with Residuals shortly known as Res-CNN-BiLSTM. In this paper we have proposed the architecture and compared its performance with different approaches of Embedding Deep Learning Algorithms.
Detection of Tool based Edited Images from Error Level Analysis and Convolutional Neural Network
Apr 19, 2022



Image Forgery is a problem of image forensics and its detection can be leveraged using Deep Learning. In this paper we present an approach for identification of authentic and tampered images done using image editing tools with Error Level Analysis and Convolutional Neural Network. The process is performed on CASIA ITDE v2 dataset and trained for 50 and 100 epochs respectively. The respective accuracies of the training and validation sets are represented using graphs.
Demonstration-Bootstrapped Autonomous Practicing via Multi-Task Reinforcement Learning
Mar 29, 2022
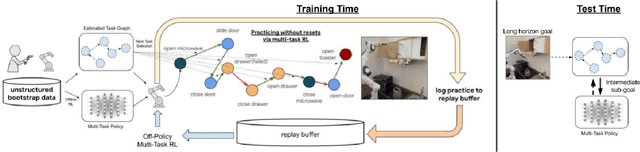
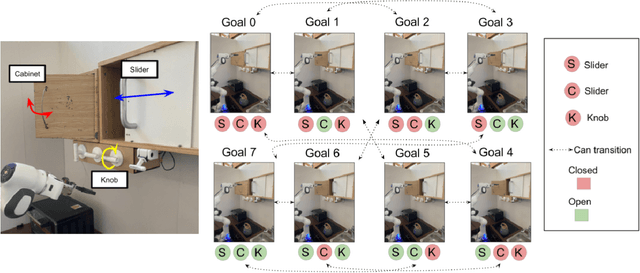
Reinforcement learning systems have the potential to enable continuous improvement in unstructured environments, leveraging data collected autonomously. However, in practice these systems require significant amounts of instrumentation or human intervention to learn in the real world. In this work, we propose a system for reinforcement learning that leverages multi-task reinforcement learning bootstrapped with prior data to enable continuous autonomous practicing, minimizing the number of resets needed while being able to learn temporally extended behaviors. We show how appropriately provided prior data can help bootstrap both low-level multi-task policies and strategies for sequencing these tasks one after another to enable learning with minimal resets. This mechanism enables our robotic system to practice with minimal human intervention at training time while being able to solve long horizon tasks at test time. We show the efficacy of the proposed system on a challenging kitchen manipulation task both in simulation and in the real world, demonstrating the ability to practice autonomously in order to solve temporally extended problems.
Lean Evolutionary Reinforcement Learning by Multitasking with Importance Sampling
Mar 21, 2022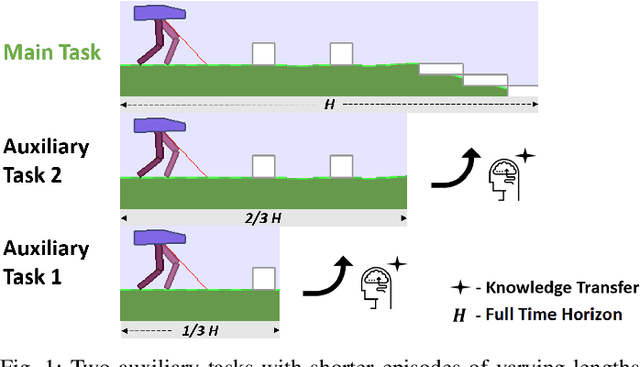


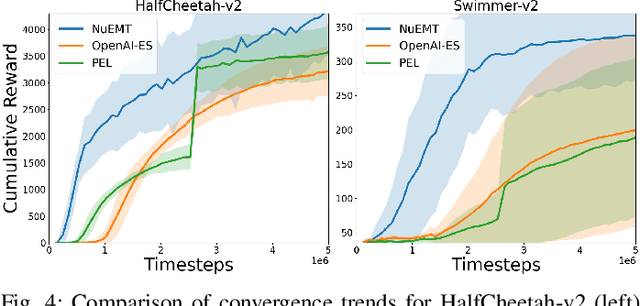
Studies have shown evolution strategies (ES) to be a promising approach for reinforcement learning (RL) with deep neural networks. However, the issue of high sample complexity persists in applications of ES to deep RL. In this paper, we address the shortcoming of today's methods via a novel neuroevolutionary multitasking (NuEMT) algorithm, designed to transfer information from a set of auxiliary tasks (of short episode length) to the target (full length) RL task at hand. The artificially generated auxiliary tasks allow an agent to update and quickly evaluate policies on shorter time horizons. The evolved skills are then transferred to guide the longer and harder task towards an optimal policy. We demonstrate that the NuEMT algorithm achieves data-lean evolutionary RL, reducing expensive agent-environment interaction data requirements. Our key algorithmic contribution in this setting is to introduce, for the first time, a multitask information transfer mechanism based on the statistical importance sampling technique. In addition, an adaptive resource allocation strategy is utilized to assign computational resources to auxiliary tasks based on their gleaned usefulness. Experiments on a range of continuous control tasks from the OpenAI Gym confirm that our proposed algorithm is efficient compared to recent ES baselines.
Teachable Reinforcement Learning via Advice Distillation
Mar 19, 2022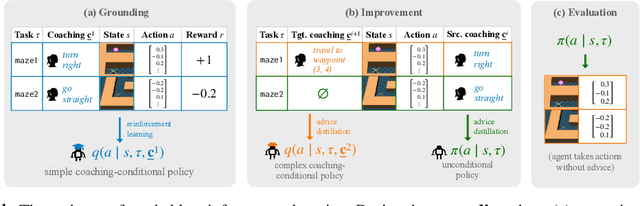
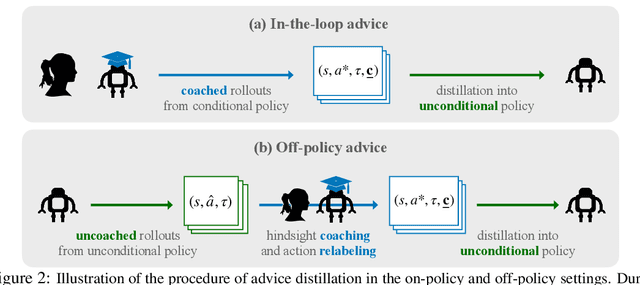
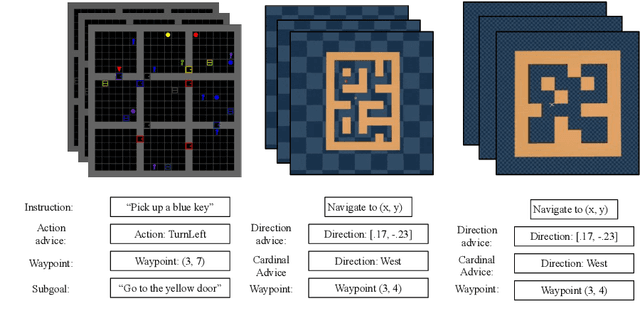
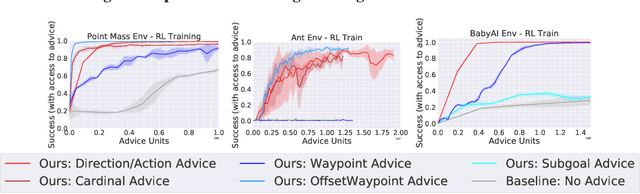
Training automated agents to complete complex tasks in interactive environments is challenging: reinforcement learning requires careful hand-engineering of reward functions, imitation learning requires specialized infrastructure and access to a human expert, and learning from intermediate forms of supervision (like binary preferences) is time-consuming and extracts little information from each human intervention. Can we overcome these challenges by building agents that learn from rich, interactive feedback instead? We propose a new supervision paradigm for interactive learning based on "teachable" decision-making systems that learn from structured advice provided by an external teacher. We begin by formalizing a class of human-in-the-loop decision making problems in which multiple forms of teacher-provided advice are available to a learner. We then describe a simple learning algorithm for these problems that first learns to interpret advice, then learns from advice to complete tasks even in the absence of human supervision. In puzzle-solving, navigation, and locomotion domains, we show that agents that learn from advice can acquire new skills with significantly less human supervision than standard reinforcement learning algorithms and often less than imitation learning.