 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Medicine: A Survey
May 20, 2024



To address challenges in the digital economy's landscape of digital intelligence, large language models (LLMs) have been developed. Improvements in computational power and available resources have significantly advanced LLMs, allowing their integration into diverse domains for human life. Medical LLMs are essential application tools with potential across various medical scenarios. In this paper, we review LLM developments, focusing on the requirements and applications of medical LLMs. We provide a concise overview of existing models, aiming to explore advanced research directions and benefit researchers for future medical applications. We emphasize the advantages of medical LLMs in applications, as well as the challenges encountered during their development. Finally, we suggest directions for technical integration to mitigate challenges and potential research directions for the future of medical LLMs, aiming to meet the demands of the medical field better.
Data Scarcity in Recommendation Systems: A Survey
Dec 08, 2023



The prevalence of online content has led to the widespread adoption of recommendation systems (RSs), which serve diverse purposes such as news, advertisements, and e-commerce recommendations. Despite their significance, data scarcity issues have significantly impaired the effectiveness of existing RS models and hindered their progress. To address this challenge, the concept of knowledge transfer, particularly from external sources like pre-trained language models, emerges as a potential solution to alleviate data scarcity and enhance RS development. However, the practice of knowledge transfer in RSs is intricate. Transferring knowledge between domains introduces data disparities, and the application of knowledge transfer in complex RS scenarios can yield negative consequences if not carefully designed. Therefore, this article contributes to this discourse by addressing the implications of data scarcity on RSs and introducing various strategies, such as data augmentation, self-supervised learning, transfer learning, broad learning, and knowledge graph utilization, to mitigate this challenge. Furthermore, it delves into the challenges and future direction within the RS domain, offering insights that are poised to facilitate the development and implementation of robust RSs, particularly when confronted with data scarcity. We aim to provide valuable guidance and inspiration for researchers and practitioners, ultimately driving advancements in the field of RS.
Multimodal Large Language Models: A Survey
Nov 22, 2023



The exploration of multimodal language models integrates multiple data types, such as images, text, language, audio, and other heterogeneity. While the latest large language models excel in text-based tasks, they often struggle to understand and process other data types. Multimodal models address this limitation by combining various modalities, enabling a more comprehensive understanding of diverse data. This paper begins by defining the concept of multimodal and examining the historical development of multimodal algorithms. Furthermore, we introduce a range of multimodal products, focusing on the efforts of major technology companies. A practical guide is provided, offering insights into the technical aspects of multimodal models. Moreover, we present a compilation of the latest algorithms and commonly used datasets, providing researchers with valuable resources for experimentation and evaluation. Lastly, we explore the applications of multimodal models and discuss the challenges associated with their development. By addressing these aspects, this paper aims to facilitate a deeper understanding of multimodal models and their potential in various domains.
AI-Generated Content (AIGC): A Survey
Mar 26, 2023



To address the challenges of digital intelligence in the digital economy, artificial intelligence-generated content (AIGC) has emerged. AIGC uses artificial intelligence to assist or replace manual content generation by generating content based on user-inputted keywords or requirements. The development of large model algorithms has significantly strengthened the capabilities of AIGC, which makes AIGC products a promising generative tool and adds convenience to our lives. As an upstream technology, AIGC has unlimited potential to support different downstream applications. It is important to analyze AIGC's current capabilities and shortcomings to understand how it can be best utilized in future applications. Therefore, this paper provides an extensive overview of AIGC, covering its definition, essential conditions, cutting-edge capabilities, and advanced features. Moreover, it discusses the benefits of large-scale pre-trained models and the industrial chain of AIGC. Furthermore, the article explores the distinctions between auxiliary generation and automatic generation within AIGC, providing examples of text generation. The paper also examines the potential integration of AIGC with the Metaverse. Lastly, the article highlights existing issues and suggests some future directions for application.
Lean Evolutionary Reinforcement Learning by Multitasking with Importance Sampling
Mar 21, 2022


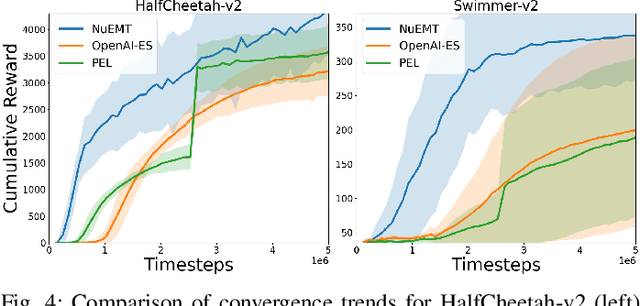
Studies have shown evolution strategies (ES) to be a promising approach for reinforcement learning (RL) with deep neural networks. However, the issue of high sample complexity persists in applications of ES to deep RL. In this paper, we address the shortcoming of today's methods via a novel neuroevolutionary multitasking (NuEMT) algorithm, designed to transfer information from a set of auxiliary tasks (of short episode length) to the target (full length) RL task at hand. The artificially generated auxiliary tasks allow an agent to update and quickly evaluate policies on shorter time horizons. The evolved skills are then transferred to guide the longer and harder task towards an optimal policy. We demonstrate that the NuEMT algorithm achieves data-lean evolutionary RL, reducing expensive agent-environment interaction data requirements. Our key algorithmic contribution in this setting is to introduce, for the first time, a multitask information transfer mechanism based on the statistical importance sampling technique. In addition, an adaptive resource allocation strategy is utilized to assign computational resources to auxiliary tasks based on their gleaned usefulness. Experiments on a range of continuous control tasks from the OpenAI Gym confirm that our proposed algorithm is efficient compared to recent ES baselines.
Half a Dozen Real-World Applications of Evolutionary Multitasking and More
Sep 29, 2021
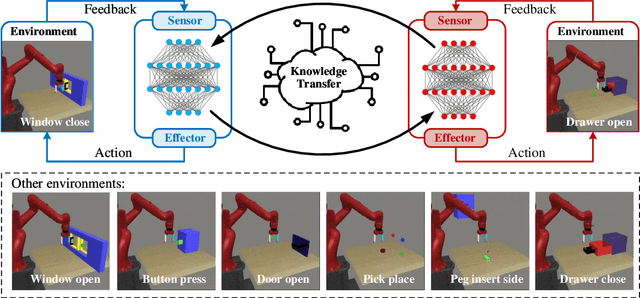
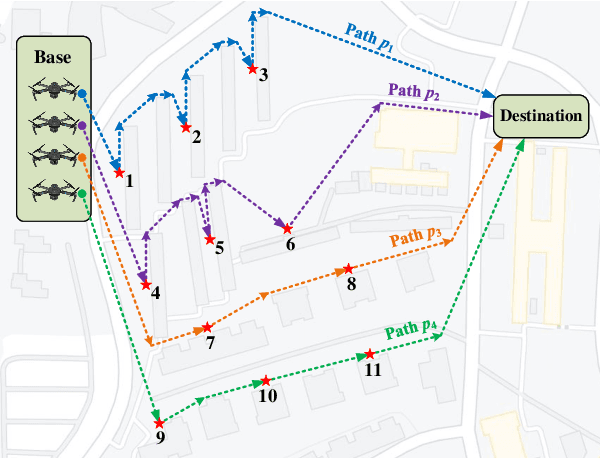
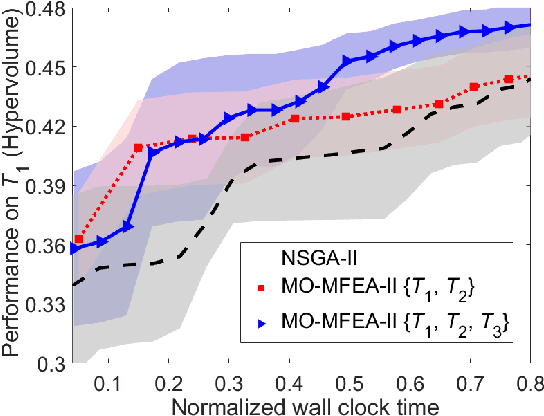
Until recently, the potential to transfer evolved skills across distinct optimization problem instances (or tasks) was seldom explored in evolutionary computation. The concept of evolutionary multitasking (EMT) fills this gap. It unlocks a population's implicit parallelism to jointly solve a set of tasks, hence creating avenues for skills transfer between them. Despite it being early days, the idea of EMT has begun to show promise in a range of real-world applications. In the backdrop of recent advances, the contribution of this paper is twofold. First, we present a review of several application-oriented explorations of EMT in the literature, assimilating them into half a dozen broad categories according to their respective application areas. Each category elaborates fundamental motivations to multitask, and contains a representative experimental study (referred from the literature). Second, we present a set of recipes by which general problem formulations of practical interest, those that cut across different disciplines, could be transformed in the new light of EMT. We intend our discussions to underscore the practical utility of existing EMT methods, and spark future research toward novel algorithms crafted for real-world deployment.