 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric Effects based on Fluctuations in values of k in Nearest Neighbor Regressor
Aug 24, 2022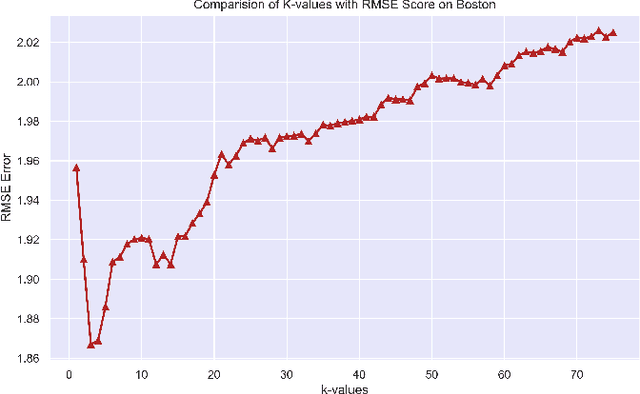
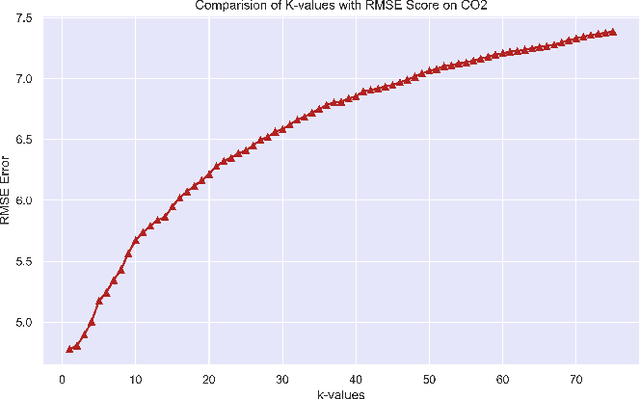
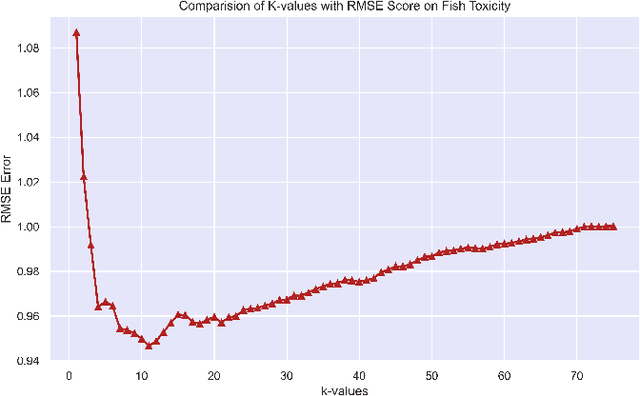
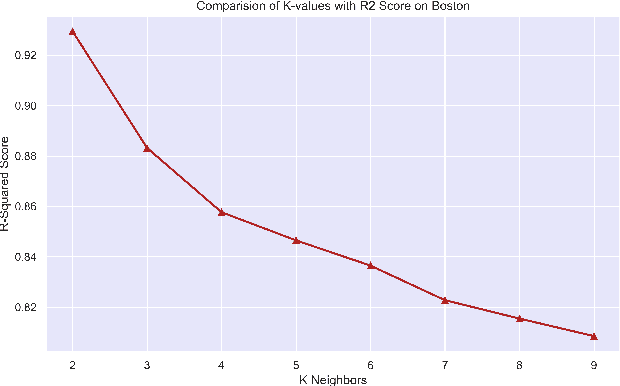
Regression branch of Machine Learning purely focuses on prediction of continuous values. The supervised learning branch has many regression based methods with parametric and non-parametric learning models. In this paper we aim to target a very subtle point related to distance based regression model. The distance based model used is K-Nearest Neighbors Regressor which is a supervised non-parametric method. The point that we want to prove is the effect of k parameter of the model and its fluctuations affecting the metrics. The metrics that we use are Root Mean Squared Error and R-Squared Goodness of Fit with their visual representation of values with respect to k values.
Discriminant Analysis in Contrasting Dimensions for Polycystic Ovary Syndrome Prognostication
Jan 09, 2022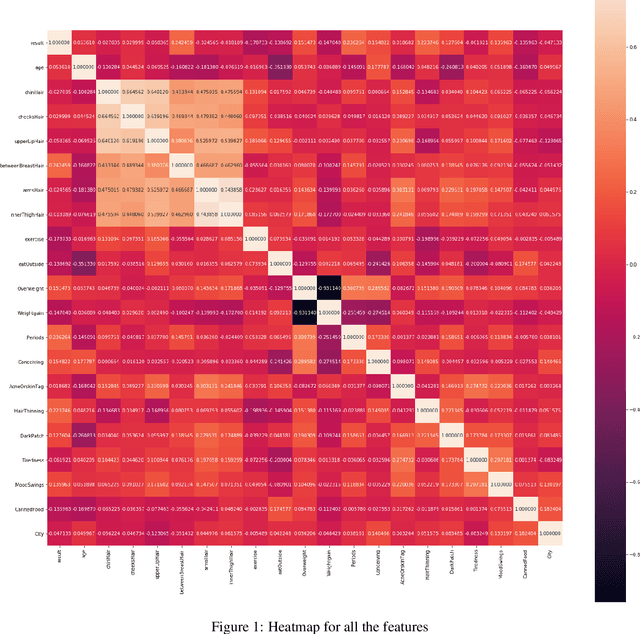

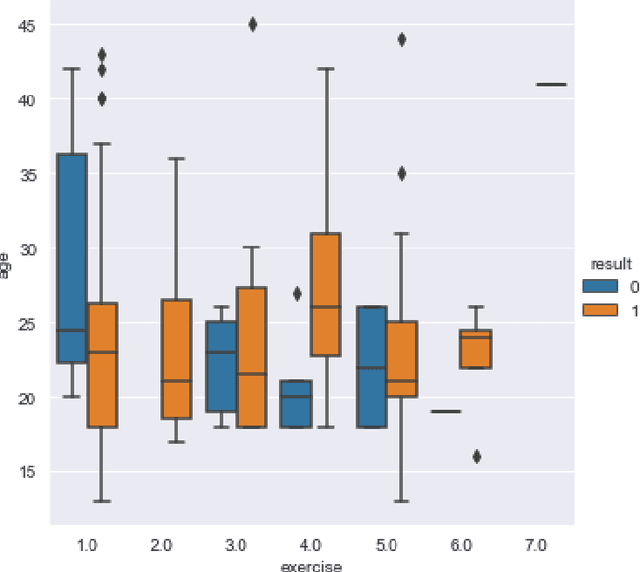

A lot of prognostication methodologies have been formulated for early detection of Polycystic Ovary Syndrome also known as PCOS using Machine Learning. PCOS is a binary classification problem. Dimensionality Reduction methods impact the performance of Machine Learning to a greater extent and using a Supervised Dimensionality Reduction method can give us a new edge to tackle this problem. In this paper we present Discriminant Analysis in different dimensions with Linear and Quadratic form for binary classification along with metrics. We were able to achieve good accuracy and less variation with Discriminant Analysis as compared to many commonly used classification algorithms with training accuracy reaching 97.37% and testing accuracy of 95.92% using Quadratic Discriminant Analysis. Paper also gives the analysis of data with visualizations for deeper understanding of problem.
Succinct Differentiation of Disparate Boosting Ensemble Learning Methods for Prognostication of Polycystic Ovary Syndrome Diagnosis
Jan 02, 2022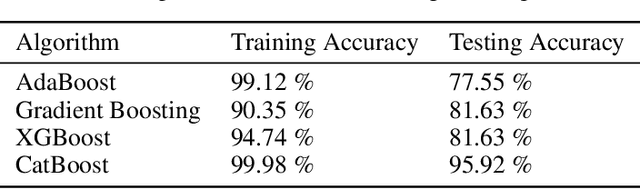
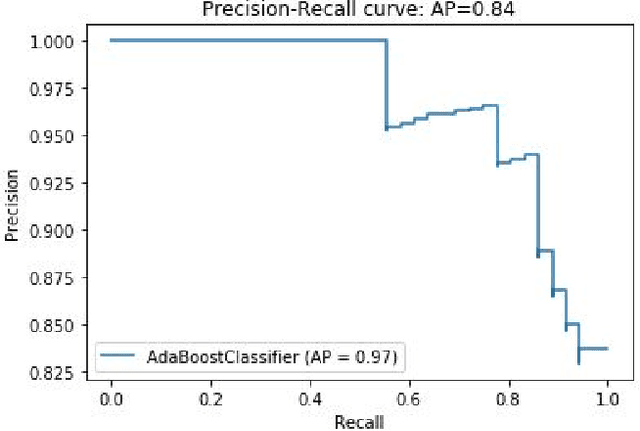
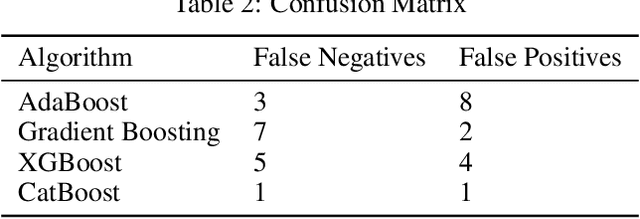
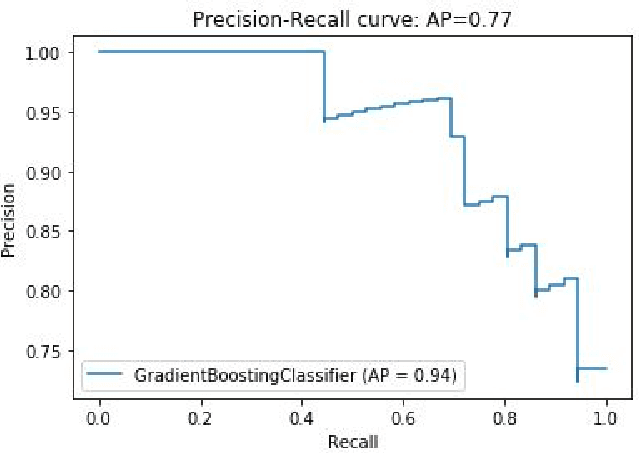
Prognostication of medical problems using the clinical data by leveraging the Machine Learning techniques with stellar precision is one of the most important real world challenges at the present time. Considering the medical problem of Polycystic Ovary Syndrome also known as PCOS is an emerging problem in women aged from 15 to 49. Diagnosing this disorder by using various Boosting Ensemble Methods is something we have presented in this paper. A detailed and compendious differentiation between Adaptive Boost, Gradient Boosting Machine, XGBoost and CatBoost with their respective performance metrics highlighting the hidden anomalies in the data and its effects on the result is something we have presented in this paper. Metrics like Confusion Matrix, Precision, Recall, F1 Score, FPR, RoC Curve and AUC have been used in this paper.