 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForged Image Detection using SOTA Image Classification Deep Learning Methods for Image Forensics with Error Level Analysis
Nov 28, 2022The advancement in the area of computer vision has been brought using deep learning mechanisms. Image Forensics is one of the major areas of computer vision application. Forgery of images is sub-category of image forensics and can be detected using Error Level Analysis. Using such images as an input, this can turn out to be a binary classification problem which can be leveraged using variations of convolutional neural networks. In this paper we perform transfer learning with state-of-the-art image classification models over error level analysis induced CASIA ITDE v.2 dataset. The algorithms used are VGG-19, Inception-V3, ResNet-152-V2, XceptionNet and EfficientNet-V2L with their respective methodologies and results.
Metric Effects based on Fluctuations in values of k in Nearest Neighbor Regressor
Aug 24, 2022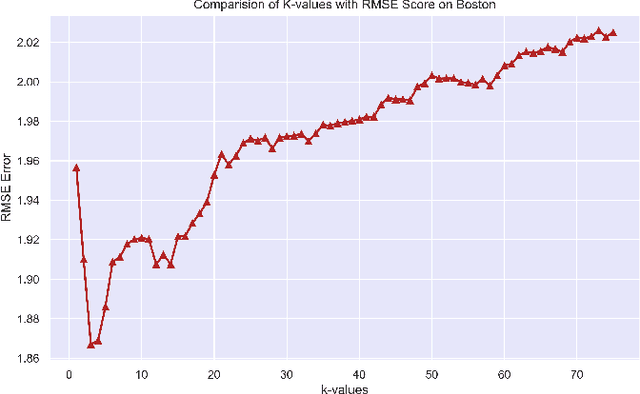
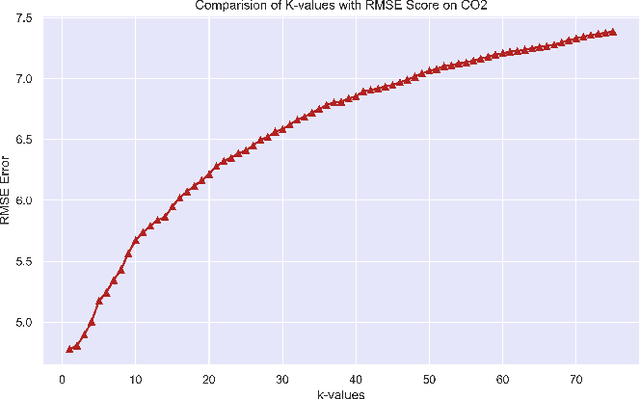
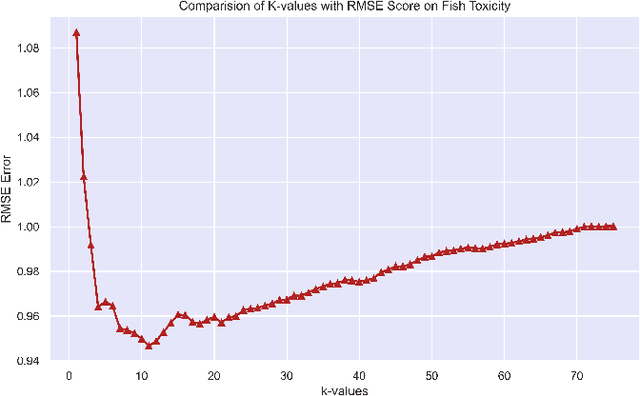
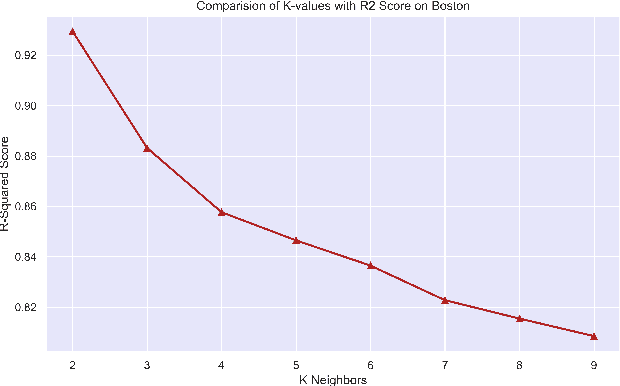
Regression branch of Machine Learning purely focuses on prediction of continuous values. The supervised learning branch has many regression based methods with parametric and non-parametric learning models. In this paper we aim to target a very subtle point related to distance based regression model. The distance based model used is K-Nearest Neighbors Regressor which is a supervised non-parametric method. The point that we want to prove is the effect of k parameter of the model and its fluctuations affecting the metrics. The metrics that we use are Root Mean Squared Error and R-Squared Goodness of Fit with their visual representation of values with respect to k values.
Res-CNN-BiLSTM Network for overcoming Mental Health Disturbances caused due to Cyberbullying through Social Media
Apr 20, 2022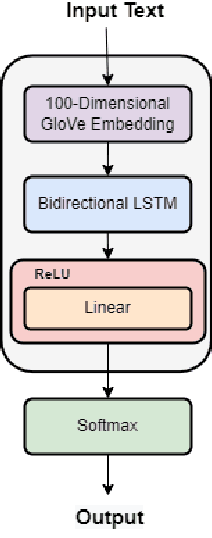
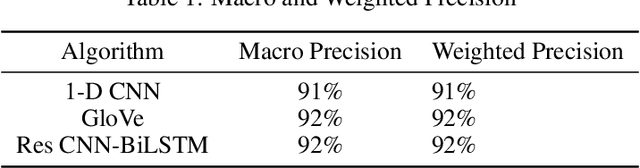

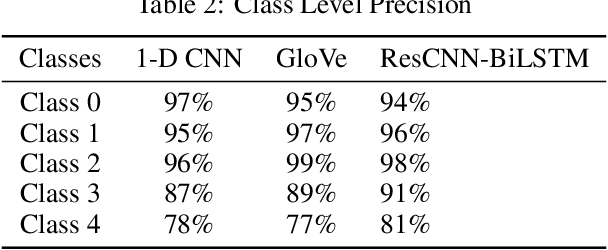
Mental Health Disturbance has many reasons and cyberbullying is one of the major causes that does exploitation using social media as an instrument. The cyberbullying is done on the basis of Religion, Ethnicity, Age and Gender which is a sensitive psychological issue. This can be addressed using Natural Language Processing with Deep Learning, since social media is the medium and it generates massive form of data in textual form. Such data can be leveraged to find the semantics and derive what type of cyberbullying is done and who are the people involved for early measures. Since deriving semantics is essential we proposed a Hybrid Deep Learning Model named 1-Dimensional CNN-Bidirectional-LSTMs with Residuals shortly known as Res-CNN-BiLSTM. In this paper we have proposed the architecture and compared its performance with different approaches of Embedding Deep Learning Algorithms.
Binary Classification for High Dimensional Data using Supervised Non-Parametric Ensemble Method
Feb 15, 2022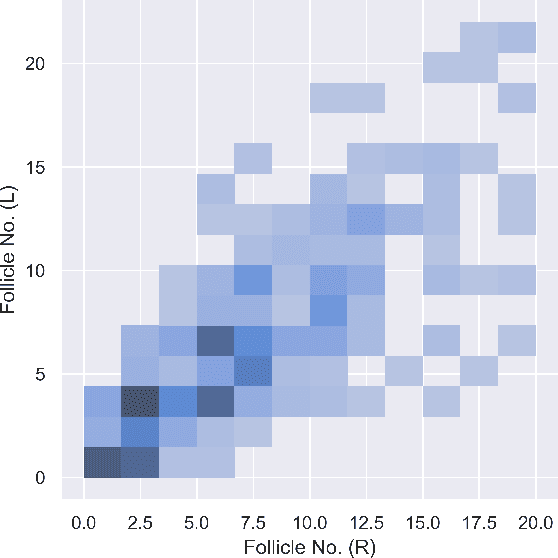

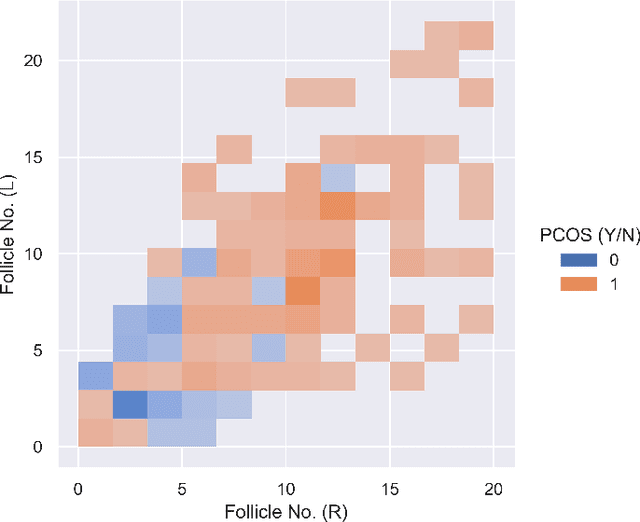
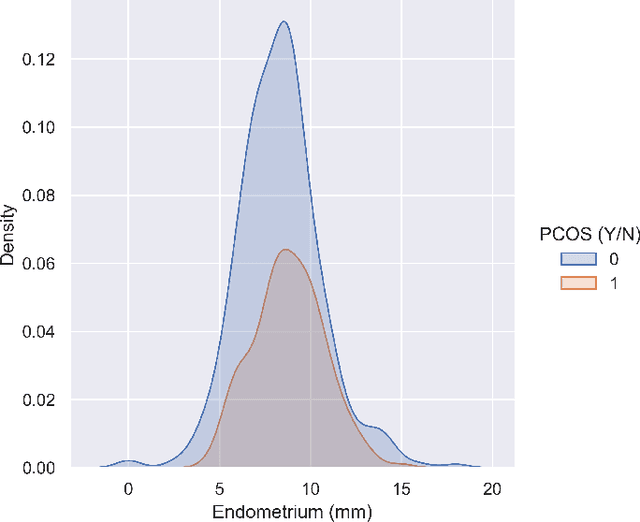
Medical Research data used for prognostication deals with binary classification problems in most of the cases. The endocrinological disorders have data available and it can be leveraged using Machine Learning. The dataset for Polycystic Ovary Syndrome is available, which is termed as an endocrinological disorder in women. Non-Parametric Supervised Ensemble machine learning methods can be used for prediction of the disorder in early stages. In this paper we present the Bootstrap Aggregation Supervised Ensemble Non-parametric method for prognostication that competes state-of-the-art performance with accuracy of over 92% along with in depth analysis of the data.
Effects of Parametric and Non-Parametric Methods on High Dimensional Sparse Matrix Representations
Feb 07, 2022The semantics are derived from textual data that provide representations for Machine Learning algorithms. These representations are interpretable form of high dimensional sparse matrix that are given as an input to the machine learning algorithms. Since learning methods are broadly classified as parametric and non-parametric learning methods, in this paper we provide the effects of these type of algorithms on the high dimensional sparse matrix representations. In order to derive the representations from the text data, we have considered TF-IDF representation with valid reason in the paper. We have formed representations of 50, 100, 500, 1000 and 5000 dimensions respectively over which we have performed classification using Linear Discriminant Analysis and Naive Bayes as parametric learning method, Decision Tree and Support Vector Machines as non-parametric learning method. We have later provided the metrics on every single dimension of the representation and effect of every single algorithm detailed in this paper.