 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLawPal : A Retrieval Augmented Generation Based System for Enhanced Legal Accessibility in India
Feb 23, 2025Access to legal knowledge in India is often hindered by a lack of awareness, misinformation and limited accessibility to judicial resources. Many individuals struggle to navigate complex legal frameworks, leading to the frequent misuse of laws and inadequate legal protection. To address these issues, we propose a Retrieval-Augmented Generation (RAG)-based legal chatbot powered by vectorstore oriented FAISS for efficient and accurate legal information retrieval. Unlike traditional chatbots, our model is trained using an extensive dataset comprising legal books, official documentation and the Indian Constitution, ensuring accurate responses to even the most complex or misleading legal queries. The chatbot leverages FAISS for rapid vector-based search, significantly improving retrieval speed and accuracy. It is also prompt-engineered to handle twisted or ambiguous legal questions, reducing the chances of incorrect interpretations. Apart from its core functionality of answering legal queries, the platform includes additional features such as real-time legal news updates, legal blogs, and access to law-related books, making it a comprehensive resource for users. By integrating advanced AI techniques with an optimized retrieval system, our chatbot aims to democratize legal knowledge, enhance legal literacy, and prevent the spread of misinformation. The study demonstrates that our approach effectively improves legal accessibility while maintaining high accuracy and efficiency, thereby contributing to a more informed and empowered society.
Deep Linear Discriminant Analysis with Variation for Polycystic Ovary Syndrome Classification
Mar 25, 2023The polycystic ovary syndrome diagnosis is a problem that can be leveraged using prognostication based learning procedures. Many implementations of PCOS can be seen with Machine Learning but the algorithms have certain limitations in utilizing the processing power graphical processing units. The simple machine learning algorithms can be improved with advanced frameworks using Deep Learning. The Linear Discriminant Analysis is a linear dimensionality reduction algorithm for classification that can be boosted in terms of performance using deep learning with Deep LDA, a transformed version of the traditional LDA. In this result oriented paper we present the Deep LDA implementation with a variation for prognostication of PCOS.
Forged Image Detection using SOTA Image Classification Deep Learning Methods for Image Forensics with Error Level Analysis
Nov 28, 2022The advancement in the area of computer vision has been brought using deep learning mechanisms. Image Forensics is one of the major areas of computer vision application. Forgery of images is sub-category of image forensics and can be detected using Error Level Analysis. Using such images as an input, this can turn out to be a binary classification problem which can be leveraged using variations of convolutional neural networks. In this paper we perform transfer learning with state-of-the-art image classification models over error level analysis induced CASIA ITDE v.2 dataset. The algorithms used are VGG-19, Inception-V3, ResNet-152-V2, XceptionNet and EfficientNet-V2L with their respective methodologies and results.
Metric Effects based on Fluctuations in values of k in Nearest Neighbor Regressor
Aug 24, 2022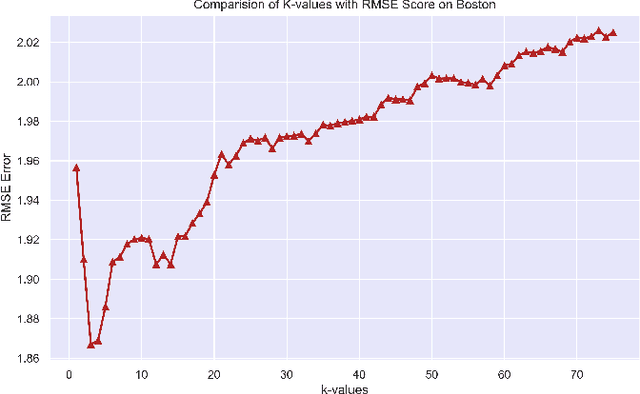
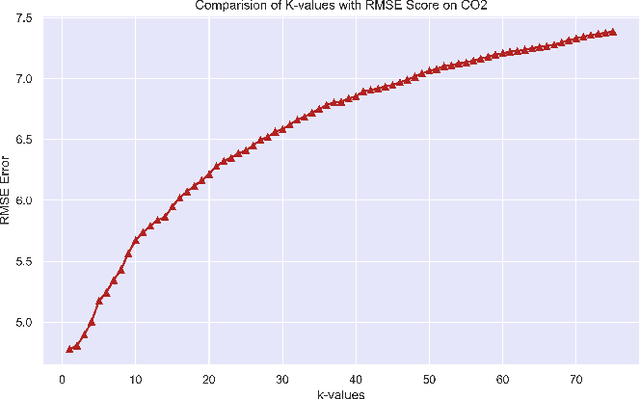
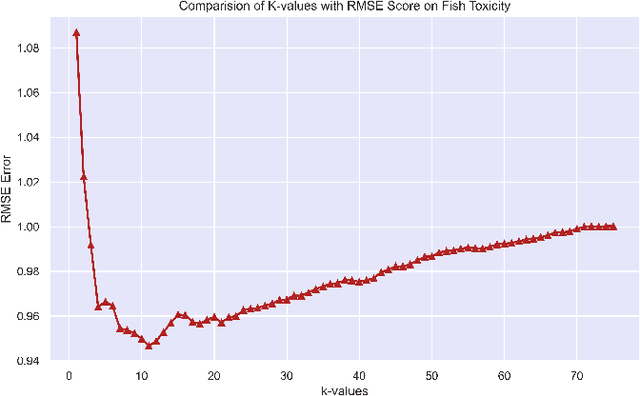
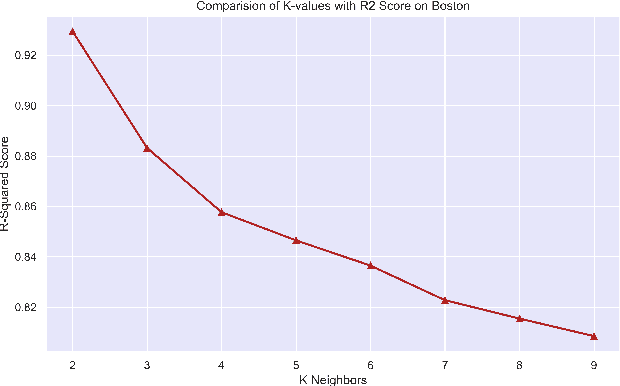
Regression branch of Machine Learning purely focuses on prediction of continuous values. The supervised learning branch has many regression based methods with parametric and non-parametric learning models. In this paper we aim to target a very subtle point related to distance based regression model. The distance based model used is K-Nearest Neighbors Regressor which is a supervised non-parametric method. The point that we want to prove is the effect of k parameter of the model and its fluctuations affecting the metrics. The metrics that we use are Root Mean Squared Error and R-Squared Goodness of Fit with their visual representation of values with respect to k values.
Performance Comparison of Simple Transformer and Res-CNN-BiLSTM for Cyberbullying Classification
Jun 05, 2022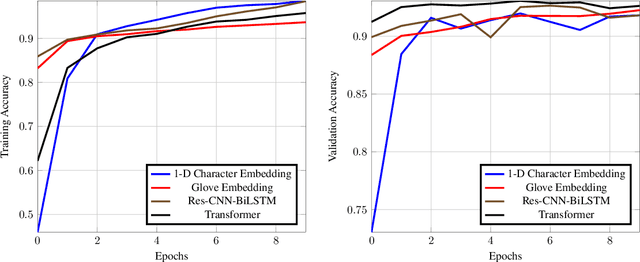
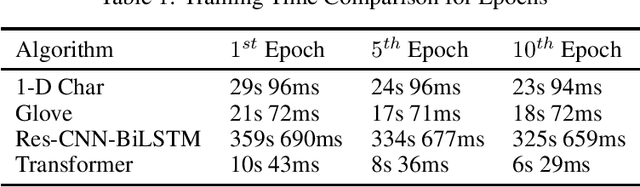
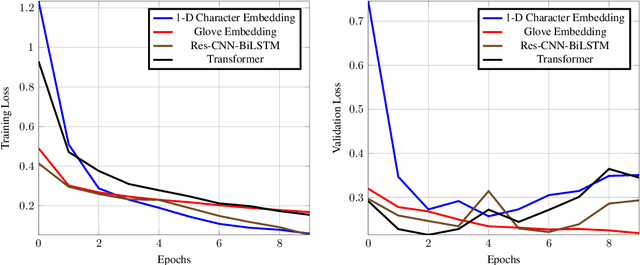
The task of text classification using Bidirectional based LSTM architectures is computationally expensive and time consuming to train. For this, transformers were discovered which effectively give good performance as compared to the traditional deep learning architectures. In this paper we present a performance based comparison between simple transformer based network and Res-CNN-BiLSTM based network for cyberbullying text classification problem. The results obtained show that transformer we trained with 0.65 million parameters has significantly being able to beat the performance of Res-CNN-BiLSTM with 48.82 million parameters for faster training speeds and more generalized metrics. The paper also compares the 1-dimensional character level embedding network and 100-dimensional glove embedding network with transformer.
Residual-Concatenate Neural Network with Deep Regularization Layers for Binary Classification
May 25, 2022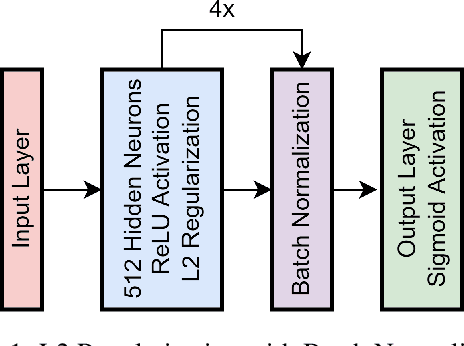

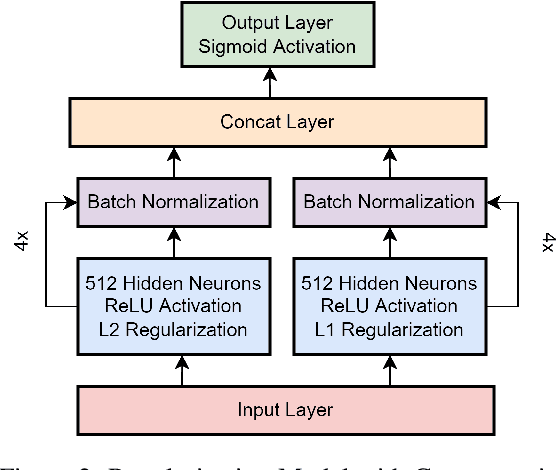
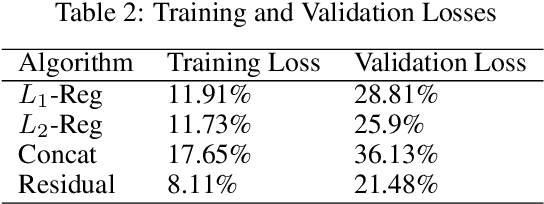
Many complex Deep Learning models are used with different variations for various prognostication tasks. The higher learning parameters not necessarily ensure great accuracy. This can be solved by considering changes in very deep models with many regularization based techniques. In this paper we train a deep neural network that uses many regularization layers with residual and concatenation process for best fit with Polycystic Ovary Syndrome Diagnosis prognostication. The network was built with improvements from every step of failure to meet the needs of the data and achieves an accuracy of 99.3% seamlessly.
Res-CNN-BiLSTM Network for overcoming Mental Health Disturbances caused due to Cyberbullying through Social Media
Apr 20, 2022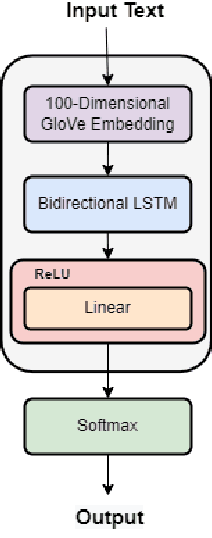
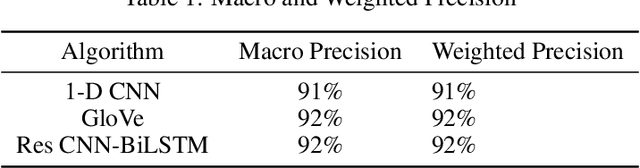

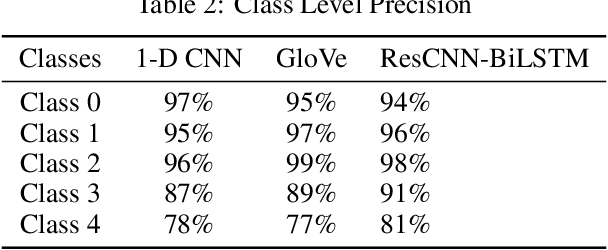
Mental Health Disturbance has many reasons and cyberbullying is one of the major causes that does exploitation using social media as an instrument. The cyberbullying is done on the basis of Religion, Ethnicity, Age and Gender which is a sensitive psychological issue. This can be addressed using Natural Language Processing with Deep Learning, since social media is the medium and it generates massive form of data in textual form. Such data can be leveraged to find the semantics and derive what type of cyberbullying is done and who are the people involved for early measures. Since deriving semantics is essential we proposed a Hybrid Deep Learning Model named 1-Dimensional CNN-Bidirectional-LSTMs with Residuals shortly known as Res-CNN-BiLSTM. In this paper we have proposed the architecture and compared its performance with different approaches of Embedding Deep Learning Algorithms.
Detection of Tool based Edited Images from Error Level Analysis and Convolutional Neural Network
Apr 19, 2022



Image Forgery is a problem of image forensics and its detection can be leveraged using Deep Learning. In this paper we present an approach for identification of authentic and tampered images done using image editing tools with Error Level Analysis and Convolutional Neural Network. The process is performed on CASIA ITDE v2 dataset and trained for 50 and 100 epochs respectively. The respective accuracies of the training and validation sets are represented using graphs.
Combining Varied Learners for Binary Classification using Stacked Generalization
Feb 17, 2022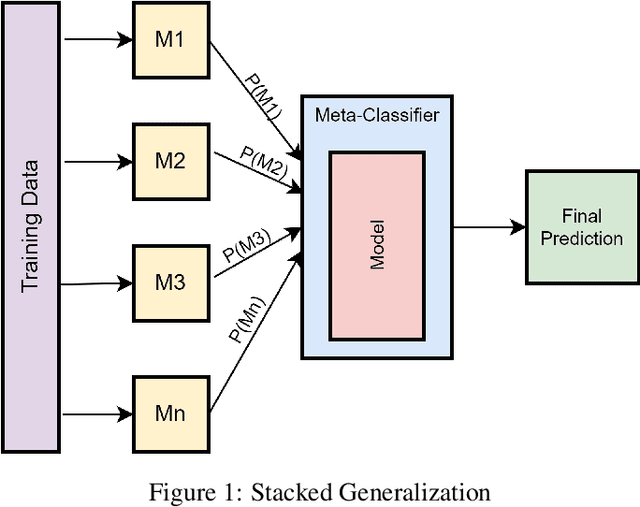
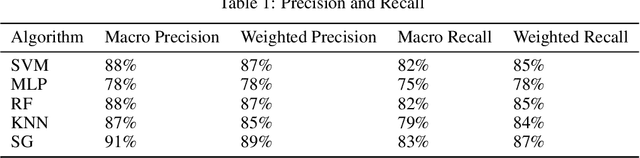
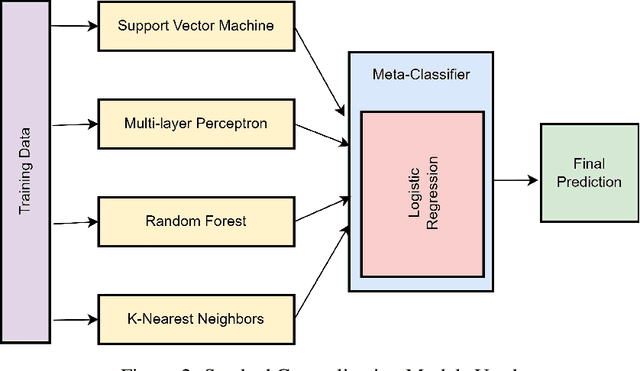
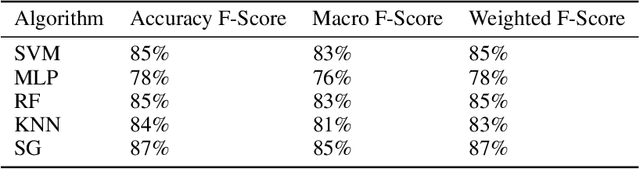
The Machine Learning has various learning algorithms that are better in some or the other aspect when compared with each other but a common error that all algorithms will suffer from is training data with very high dimensional feature set. This usually ends up algorithms into generalization error that deplete the performance. This can be solved using an Ensemble Learning method known as Stacking commonly termed as Stacked Generalization. In this paper we perform binary classification using Stacked Generalization on high dimensional Polycystic Ovary Syndrome dataset and prove the point that model becomes generalized and metrics improve significantly. The various metrics are given in this paper that also point out a subtle transgression found with Receiver Operating Characteristic Curve that was proved to be incorrect.
Binary Classification for High Dimensional Data using Supervised Non-Parametric Ensemble Method
Feb 15, 2022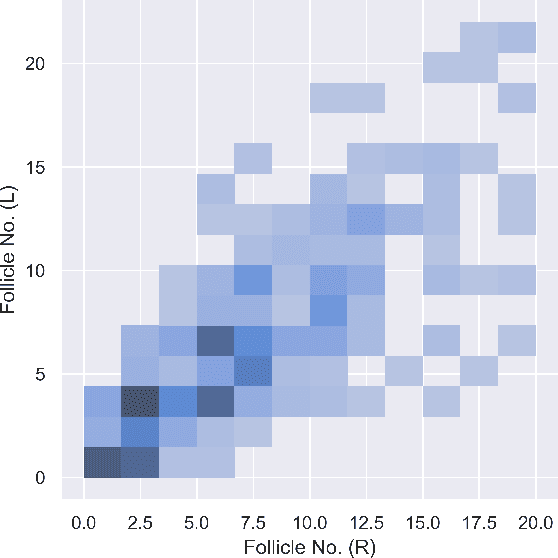

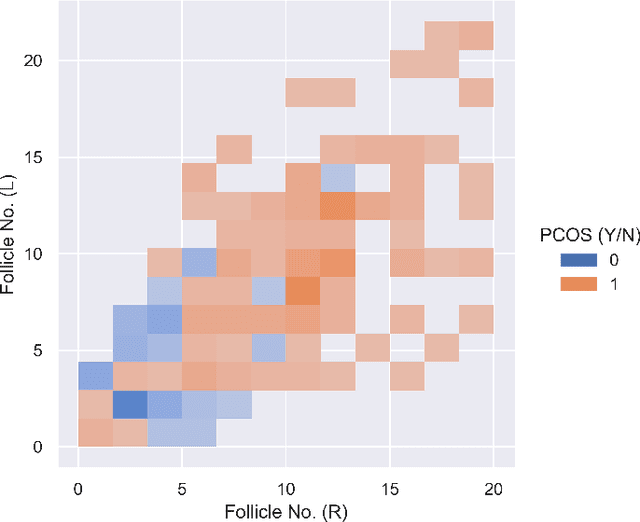
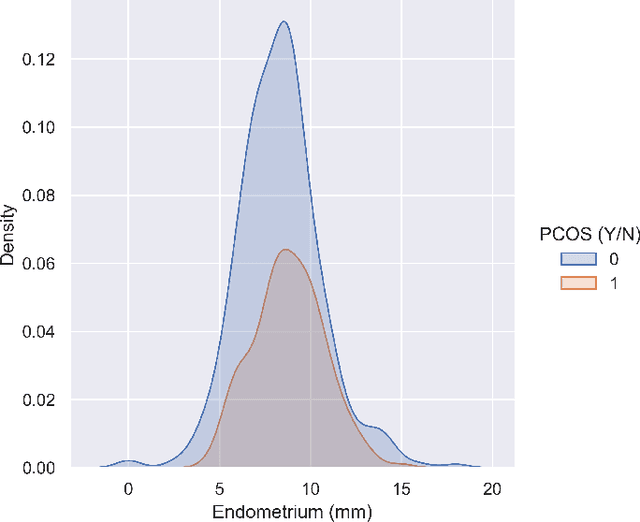
Medical Research data used for prognostication deals with binary classification problems in most of the cases. The endocrinological disorders have data available and it can be leveraged using Machine Learning. The dataset for Polycystic Ovary Syndrome is available, which is termed as an endocrinological disorder in women. Non-Parametric Supervised Ensemble machine learning methods can be used for prediction of the disorder in early stages. In this paper we present the Bootstrap Aggregation Supervised Ensemble Non-parametric method for prognostication that competes state-of-the-art performance with accuracy of over 92% along with in depth analysis of the data.