 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWanderlust: Online Continual Object Detection in the Real World
Sep 07, 2021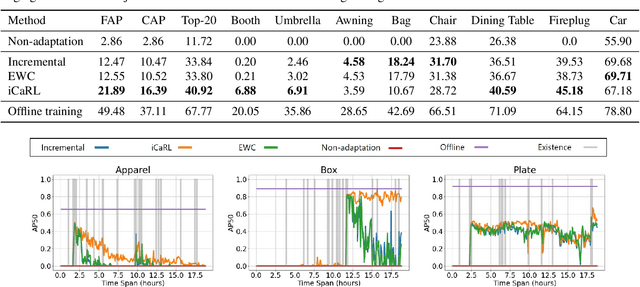


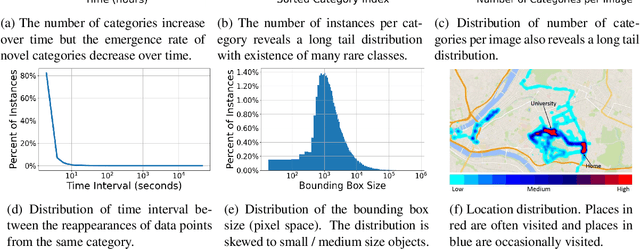
Online continual learning from data streams in dynamic environments is a critical direction in the computer vision field. However, realistic benchmarks and fundamental studies in this line are still missing. To bridge the gap, we present a new online continual object detection benchmark with an egocentric video dataset, Objects Around Krishna (OAK). OAK adopts the KrishnaCAM videos, an ego-centric video stream collected over nine months by a graduate student. OAK provides exhaustive bounding box annotations of 80 video snippets (~17.5 hours) for 105 object categories in outdoor scenes. The emergence of new object categories in our benchmark follows a pattern similar to what a single person might see in their day-to-day life. The dataset also captures the natural distribution shifts as the person travels to different places. These egocentric long-running videos provide a realistic playground for continual learning algorithms, especially in online embodied settings. We also introduce new evaluation metrics to evaluate the model performance and catastrophic forgetting and provide baseline studies for online continual object detection. We believe this benchmark will pose new exciting challenges for learning from non-stationary data in continual learning. The OAK dataset and the associated benchmark are released at https://oakdata.github.io/.
The Functional Correspondence Problem
Sep 02, 2021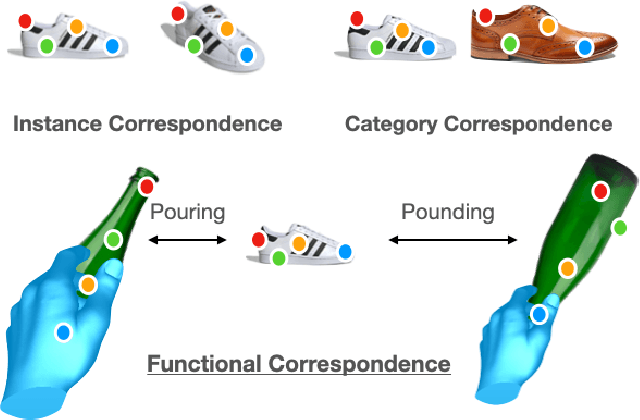



The ability to find correspondences in visual data is the essence of most computer vision tasks. But what are the right correspondences? The task of visual correspondence is well defined for two different images of same object instance. In case of two images of objects belonging to same category, visual correspondence is reasonably well-defined in most cases. But what about correspondence between two objects of completely different category -- e.g., a shoe and a bottle? Does there exist any correspondence? Inspired by humans' ability to: (a) generalize beyond semantic categories and; (b) infer functional affordances, we introduce the problem of functional correspondences in this paper. Given images of two objects, we ask a simple question: what is the set of correspondences between these two images for a given task? For example, what are the correspondences between a bottle and shoe for the task of pounding or the task of pouring. We introduce a new dataset: FunKPoint that has ground truth correspondences for 10 tasks and 20 object categories. We also introduce a modular task-driven representation for attacking this problem and demonstrate that our learned representation is effective for this task. But most importantly, because our supervision signal is not bound by semantics, we show that our learned representation can generalize better on few-shot classification problem. We hope this paper will inspire our community to think beyond semantics and focus more on cross-category generalization and learning representations for robotics tasks.
Hierarchical Neural Dynamic Policies
Jul 12, 2021
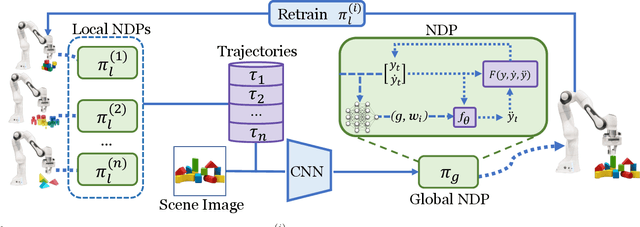
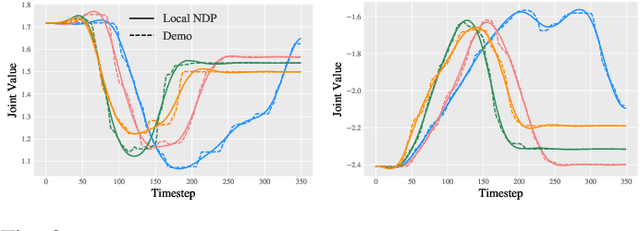

We tackle the problem of generalization to unseen configurations for dynamic tasks in the real world while learning from high-dimensional image input. The family of nonlinear dynamical system-based methods have successfully demonstrated dynamic robot behaviors but have difficulty in generalizing to unseen configurations as well as learning from image inputs. Recent works approach this issue by using deep network policies and reparameterize actions to embed the structure of dynamical systems but still struggle in domains with diverse configurations of image goals, and hence, find it difficult to generalize. In this paper, we address this dichotomy by leveraging embedding the structure of dynamical systems in a hierarchical deep policy learning framework, called Hierarchical Neural Dynamical Policies (H-NDPs). Instead of fitting deep dynamical systems to diverse data directly, H-NDPs form a curriculum by learning local dynamical system-based policies on small regions in state-space and then distill them into a global dynamical system-based policy that operates only from high-dimensional images. H-NDPs additionally provide smooth trajectories, a strong safety benefit in the real world. We perform extensive experiments on dynamic tasks both in the real world (digit writing, scooping, and pouring) and simulation (catching, throwing, picking). We show that H-NDPs are easily integrated with both imitation as well as reinforcement learning setups and achieve state-of-the-art results. Video results are at https://shikharbahl.github.io/hierarchical-ndps/
Digital-Twin-Based Improvements to Diagnosis, Prognosis, Strategy Assessment, and Discrepancy Checking in a Nearly Autonomous Management and Control System
May 23, 2021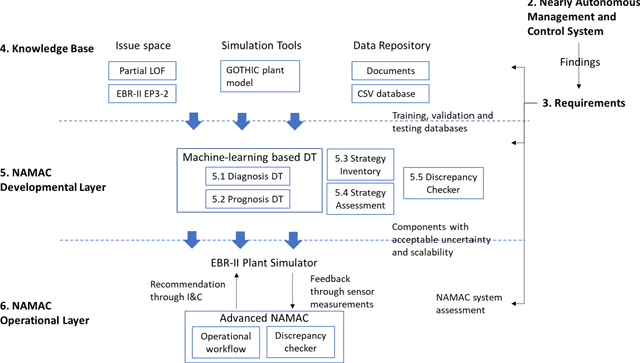
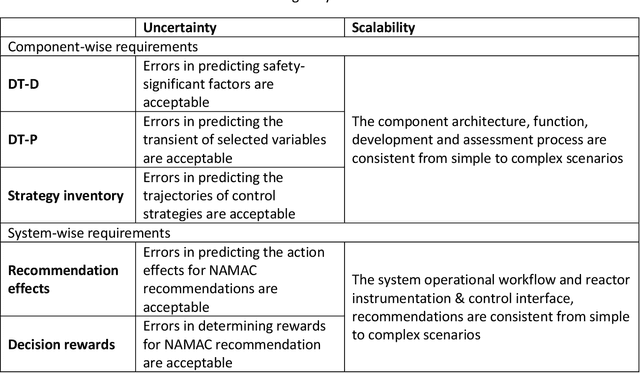
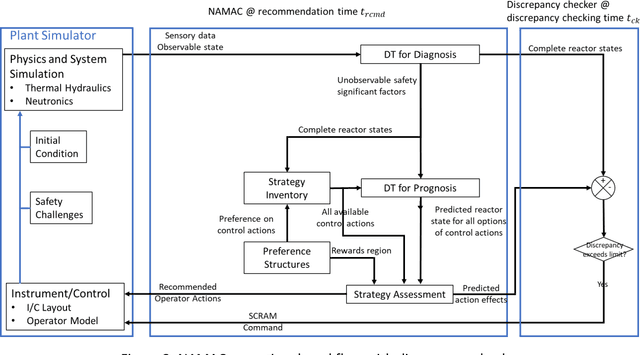
The Nearly Autonomous Management and Control System (NAMAC) is a comprehensive control system that assists plant operations by furnishing control recommendations to operators in a broad class of situations. This study refines a NAMAC system for making reasonable recommendations during complex loss-of-flow scenarios with a validated Experimental Breeder Reactor II simulator, digital twins improved by machine-learning algorithms, a multi-attribute decision-making scheme, and a discrepancy checker for identifying unexpected recommendation effects. We assessed the performance of each NAMAC component, while we demonstrated and evaluated the capability of NAMAC in a class of loss-of-flow scenarios.
DeepMPCVS: Deep Model Predictive Control for Visual Servoing
May 03, 2021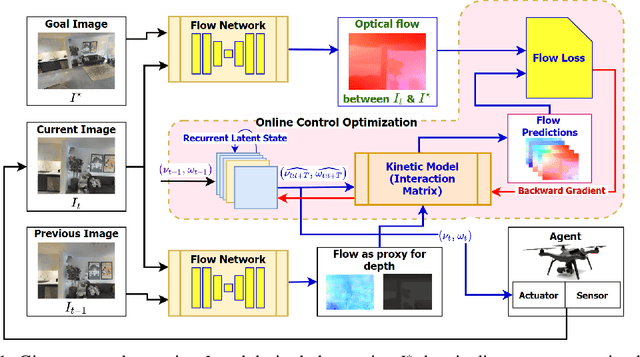
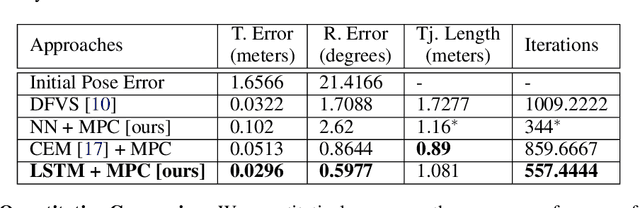

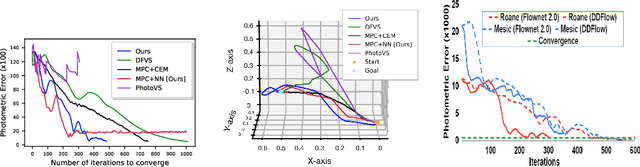
The simplicity of the visual servoing approach makes it an attractive option for tasks dealing with vision-based control of robots in many real-world applications. However, attaining precise alignment for unseen environments pose a challenge to existing visual servoing approaches. While classical approaches assume a perfect world, the recent data-driven approaches face issues when generalizing to novel environments. In this paper, we aim to combine the best of both worlds. We present a deep model predictive visual servoing framework that can achieve precise alignment with optimal trajectories and can generalize to novel environments. Our framework consists of a deep network for optical flow predictions, which are used along with a predictive model to forecast future optical flow. For generating an optimal set of velocities we present a control network that can be trained on the fly without any supervision. Through extensive simulations on photo-realistic indoor settings of the popular Habitat framework, we show significant performance gain due to the proposed formulation vis-a-vis recent state-of-the-art methods. Specifically, we show a faster convergence and an improved performance in trajectory length over recent approaches.
* Accepted at 4th Annual Conference on Robot Learning, CoRL 2020, Cambridge, MA, USA, November 16 - November 18, 2020
Learn-to-Race: A Multimodal Control Environment for Autonomous Racing
Mar 31, 2021
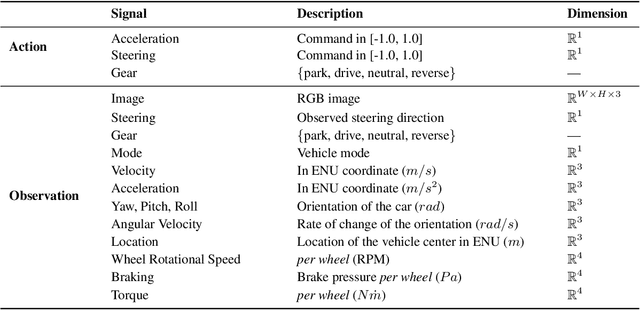
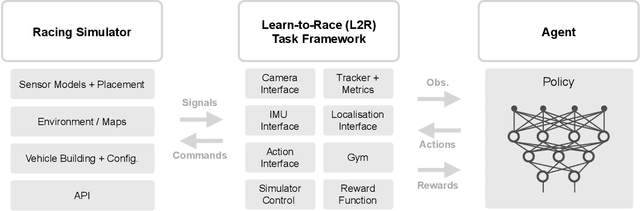

Existing research on autonomous driving primarily focuses on urban driving, which is insufficient for characterising the complex driving behaviour underlying high-speed racing. At the same time, existing racing simulation frameworks struggle in capturing realism, with respect to visual rendering, vehicular dynamics, and task objectives, inhibiting the transfer of learning agents to real-world contexts. We introduce a new environment, where agents Learn-to-Race (L2R) in simulated competition-style racing, using multimodal information--from virtual cameras to a comprehensive array of inertial measurement sensors. Our environment, which includes a simulator and an interfacing training framework, accurately models vehicle dynamics and racing conditions. In this paper, we release the Arrival simulator for autonomous racing. Next, we propose the L2R task with challenging metrics, inspired by learning-to-drive challenges, Formula-style racing, and multimodal trajectory prediction for autonomous driving. Additionally, we provide the L2R framework suite, facilitating simulated racing on high-precision models of real-world tracks, such as the famed Thruxton Circuit and the Las Vegas Motor Speedway. Finally, we provide an official L2R task dataset of expert demonstrations, as well as a series of baseline experiments and reference implementations. We make all code available: https://github.com/hermgerm29/learn-to-race
PixelTransformer: Sample Conditioned Signal Generation
Mar 29, 2021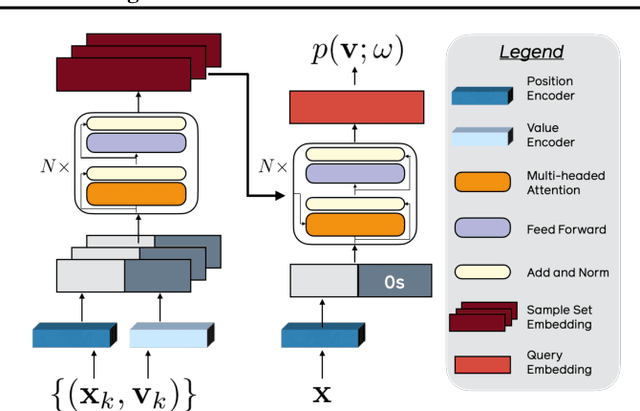
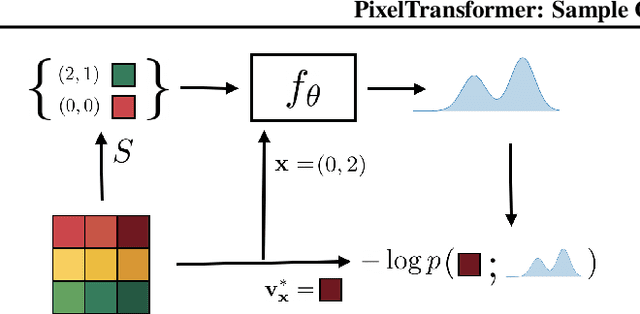


We propose a generative model that can infer a distribution for the underlying spatial signal conditioned on sparse samples e.g. plausible images given a few observed pixels. In contrast to sequential autoregressive generative models, our model allows conditioning on arbitrary samples and can answer distributional queries for any location. We empirically validate our approach across three image datasets and show that we learn to generate diverse and meaningful samples, with the distribution variance reducing given more observed pixels. We also show that our approach is applicable beyond images and can allow generating other types of spatial outputs e.g. polynomials, 3D shapes, and videos.
Shelf-Supervised Mesh Prediction in the Wild
Feb 11, 2021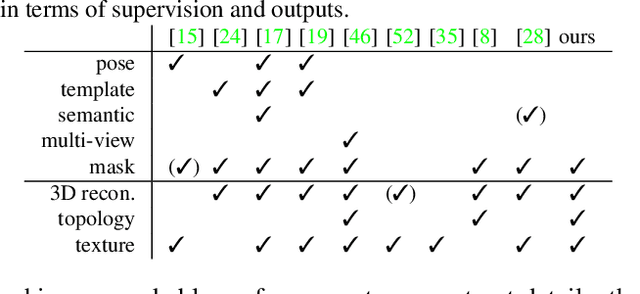
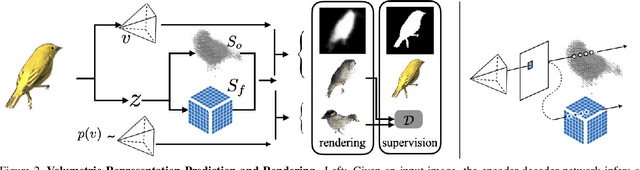
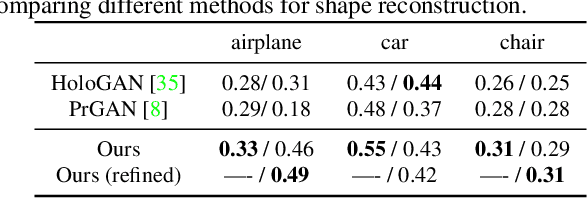
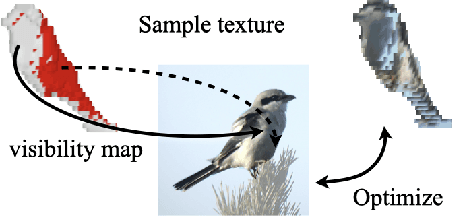
We aim to infer 3D shape and pose of object from a single image and propose a learning-based approach that can train from unstructured image collections, supervised by only segmentation outputs from off-the-shelf recognition systems (i.e. 'shelf-supervised'). We first infer a volumetric representation in a canonical frame, along with the camera pose. We enforce the representation geometrically consistent with both appearance and masks, and also that the synthesized novel views are indistinguishable from image collections. The coarse volumetric prediction is then converted to a mesh-based representation, which is further refined in the predicted camera frame. These two steps allow both shape-pose factorization from image collections and per-instance reconstruction in finer details. We examine the method on both synthetic and real-world datasets and demonstrate its scalability on 50 categories in the wild, an order of magnitude more classes than existing works.
droidlet: modular, heterogenous, multi-modal agents
Jan 25, 2021
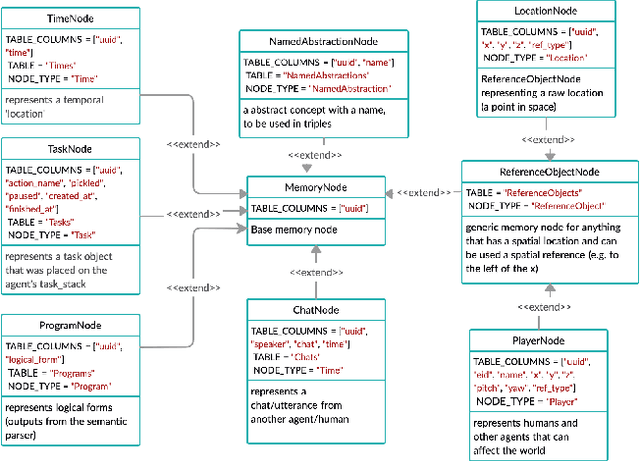
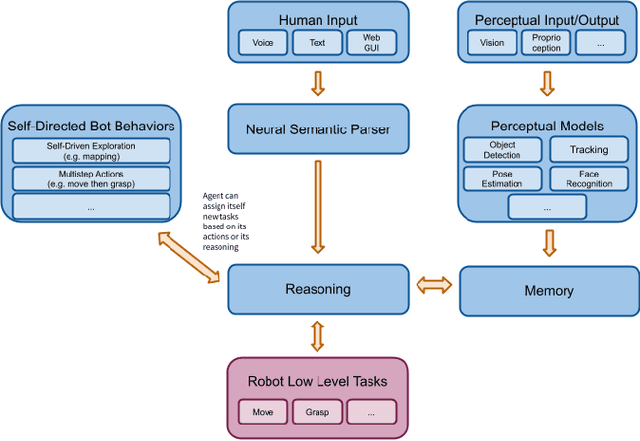
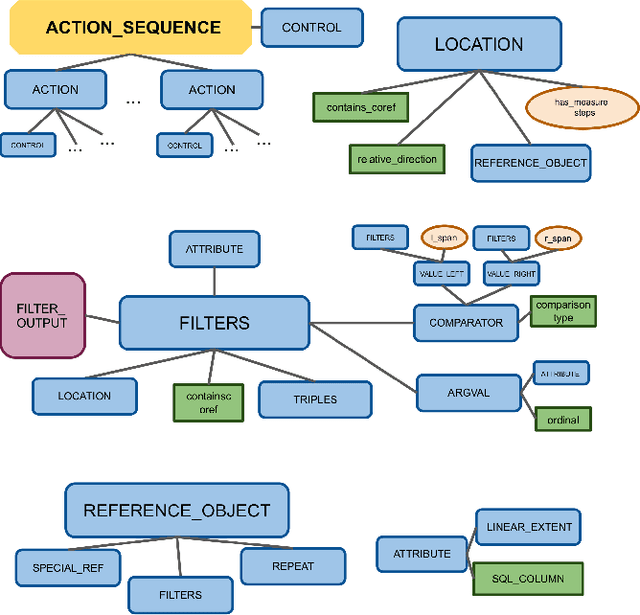
In recent years, there have been significant advances in building end-to-end Machine Learning (ML) systems that learn at scale. But most of these systems are: (a) isolated (perception, speech, or language only); (b) trained on static datasets. On the other hand, in the field of robotics, large-scale learning has always been difficult. Supervision is hard to gather and real world physical interactions are expensive. In this work we introduce and open-source droidlet, a modular, heterogeneous agent architecture and platform. It allows us to exploit both large-scale static datasets in perception and language and sophisticated heuristics often used in robotics; and provides tools for interactive annotation. Furthermore, it brings together perception, language and action onto one platform, providing a path towards agents that learn from the richness of real world interactions.
Where2Act: From Pixels to Actions for Articulated 3D Objects
Jan 07, 2021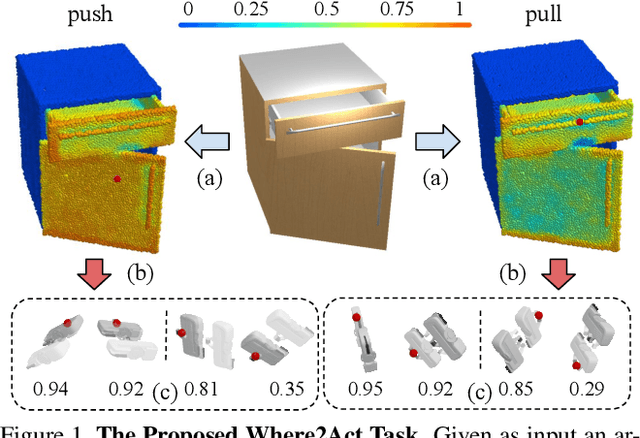
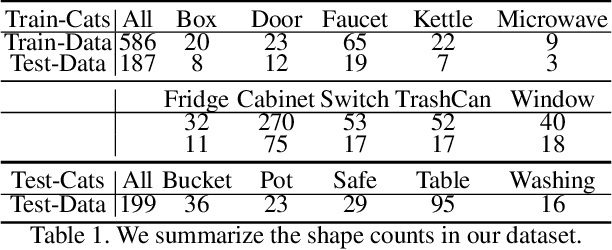
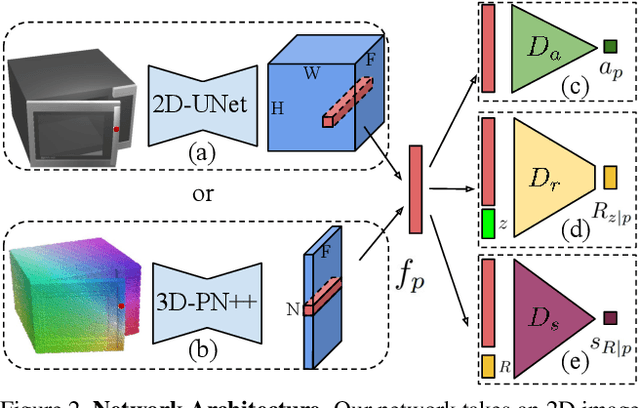
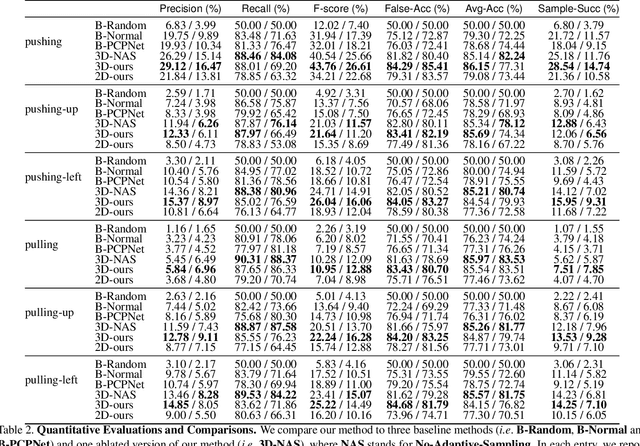
One of the fundamental goals of visual perception is to allow agents to meaningfully interact with their environment. In this paper, we take a step towards that long-term goal -- we extract highly localized actionable information related to elementary actions such as pushing or pulling for articulated objects with movable parts. For example, given a drawer, our network predicts that applying a pulling force on the handle opens the drawer. We propose, discuss, and evaluate novel network architectures that given image and depth data, predict the set of actions possible at each pixel, and the regions over articulated parts that are likely to move under the force. We propose a learning-from-interaction framework with an online data sampling strategy that allows us to train the network in simulation (SAPIEN) and generalizes across categories. But more importantly, our learned models even transfer to real-world data. Check the project website for the code and data release.