 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
USM-Lite: Quantization and Sparsity Aware Fine-tuning for Speech Recognition with Universal Speech Models
Dec 13, 2023
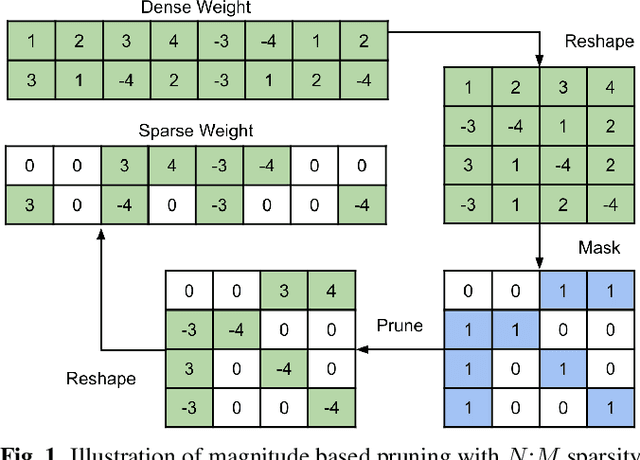
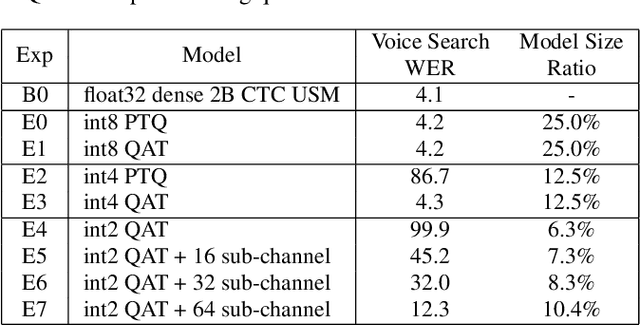
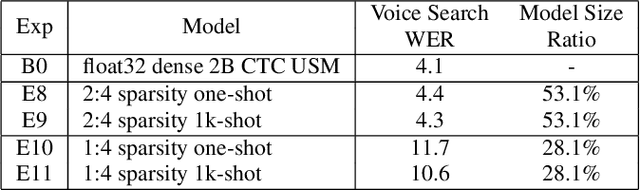
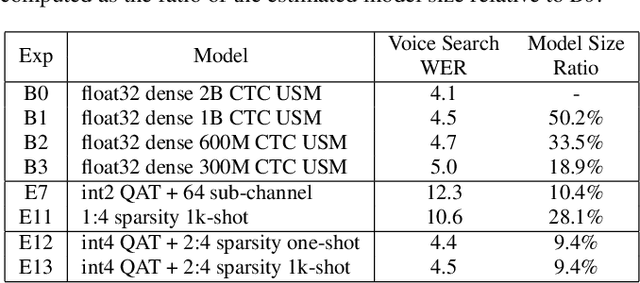
End-to-end automatic speech recognition (ASR) models have seen revolutionary quality gains with the recent development of large-scale universal speech models (USM). However, deploying these massive USMs is extremely expensive due to the enormous memory usage and computational cost. Therefore, model compression is an important research topic to fit USM-based ASR under budget in real-world scenarios. In this study, we propose a USM fine-tuning approach for ASR, with a low-bit quantization and N:M structured sparsity aware paradigm on the model weights, reducing the model complexity from parameter precision and matrix topology perspectives. We conducted extensive experiments with a 2-billion parameter USM on a large-scale voice search dataset to evaluate our proposed method. A series of ablation studies validate the effectiveness of up to int4 quantization and 2:4 sparsity. However, a single compression technique fails to recover the performance well under extreme setups including int2 quantization and 1:4 sparsity. By contrast, our proposed method can compress the model to have 9.4% of the size, at the cost of only 7.3% relative word error rate (WER) regressions. We also provided in-depth analyses on the results and discussions on the limitations and potential solutions, which would be valuable for future studies.
Toward A Reinforcement-Learning-Based System for Adjusting Medication to Minimize Speech Disfluency
Dec 12, 2023We propose a Reinforcement-Learning-based system that would automatically prescribe a hypothetical patient medications that may help the patient with their mental-health-related speech disfluency, and adjust the medication and the dosages in response to data from the patient. We demonstrate the components of the system: a module that detects and evaluates speech disfluency on a large dataset we built, and a Reinforcement Learning algorithm that automatically finds good combinations of medications. To support the two modules, we collect data on the effect of psychiatric medications for speech disfluency from the literature, and build a plausible patient simulation system. We demonstrate that the Reinforcement Learning system is, under some circumstances, able to converge to a good medication regime. We collect and label a dataset of people with possible speech disfluency and demonstrate our methods using that dataset. Our work is a proof of concept: we show that there is promise in the idea of using automatic data collection to address disfluency.
Study of cognitive component of auditory attention to natural speech events
Dec 19, 2023Event-related potentials (ERP) have been used to address a wide range of research questions in neuroscience and cognitive psychology including selective auditory attention. The recent progress in auditory attention decoding (AAD) methods is based on algorithms that find a relation between the audio envelope and the neurophysiological response. The most popular approach is based on the reconstruction of the audio envelope based on EEG signals. However, these methods are mainly based on the neurophysiological entrainment to physical attributes of the sensory stimulus and are generally limited by a long detection window. This study proposes a novel approach to auditory attention decoding by looking at higher-level cognitive responses to natural speech. To investigate if natural speech events elicit cognitive ERP components and how these components are affected by attention mechanisms, we designed a series of four experimental paradigms with increasing complexity: a word category oddball paradigm, a word category oddball paradigm with competing speakers, and competing speech streams with and without specific targets. We recorded the electroencephalogram (EEG) from 32 scalp electrodes and 12 in-ear electrodes (ear-EEG) from 24 participants. A cognitive ERP component, which we believe is related to the well-known P3b component, was observed at parietal electrode sites with a latency of approximately 620 ms. The component is statistically most significant for the simplest paradigm and gradually decreases in strength with increasing complexity of the paradigm. We also show that the component can be observed in the in-ear EEG signals by using spatial filtering. The cognitive component elicited by auditory attention may contribute to decoding auditory attention from electrophysiological recordings and its presence in the ear-EEG signals is promising for future applications within hearing aids.
StyleCap: Automatic Speaking-Style Captioning from Speech Based on Speech and Language Self-supervised Learning Models
Nov 28, 2023We propose StyleCap, a method to generate natural language descriptions of speaking styles appearing in speech. Although most of conventional techniques for para-/non-linguistic information recognition focus on the category classification or the intensity estimation of pre-defined labels, they cannot provide the reasoning of the recognition result in an interpretable manner. As a first step towards an end-to-end method for generating speaking-style prompts from speech, i.e., automatic speaking-style captioning, StyleCap uses paired data of speech and natural language descriptions to train neural networks that predict prefix vectors fed into a large language model (LLM)-based text decoder from a speech representation vector. We explore an appropriate text decoder and speech feature representation suitable for this new task. The experimental results demonstrate that our StyleCap leveraging richer LLMs for the text decoder, speech self-supervised learning (SSL) features, and sentence rephrasing augmentation improves the accuracy and diversity of generated speaking-style captions. Samples of speaking-style captions generated by our StyleCap are publicly available.
A Deep Representation Learning-based Speech Enhancement Method Using Complex Convolution Recurrent Variational Autoencoder
Dec 15, 2023Generally, the performance of deep neural networks (DNNs) heavily depends on the quality of data representation learning. Our preliminary work has emphasized the significance of deep representation learning (DRL) in the context of speech enhancement (SE) applications. Specifically, our initial SE algorithm employed a gated recurrent unit variational autoencoder (VAE) with a Gaussian distribution to enhance the performance of certain existing SE systems. Building upon our preliminary framework, this paper introduces a novel approach for SE using deep complex convolutional recurrent networks with a VAE (DCCRN-VAE). DCCRN-VAE assumes that the latent variables of signals follow complex Gaussian distributions that are modeled by DCCRN, as these distributions can better capture the behaviors of complex signals. Additionally, we propose the application of a residual loss in DCCRN-VAE to further improve the quality of the enhanced speech. {Compared to our preliminary work, DCCRN-VAE introduces a more sophisticated DCCRN structure and probability distribution for DRL. Furthermore, in comparison to DCCRN, DCCRN-VAE employs a more advanced DRL strategy. The experimental results demonstrate that the proposed SE algorithm outperforms both our preliminary SE framework and the state-of-the-art DCCRN SE method in terms of scale-invariant signal-to-distortion ratio, speech quality, and speech intelligibility.
Distributed Speech Dereverberation Using Weighted Prediction Error
Dec 05, 2023Speech dereverberation aims to alleviate the negative impact of late reverberant reflections. The weighted prediction error (WPE) method is a well-established technique known for its superior performance in dereverberation. However, in scenarios where microphone nodes are dispersed, the centralized approach of the WPE method requires aggregating all observations for inverse filtering, resulting in a significant computational burden. This paper introduces a distributed speech dereverberation method that emphasizes low computational complexity at each node. Specifically, we leverage the distributed adaptive node-specific signal estimation (DANSE) algorithm within the multichannel linear prediction (MCLP) process. This approach empowers each node to perform local operations with reduced complexity while achieving the global performance through inter-node cooperation. Experimental results validate the effectiveness of our proposed method, showcasing its ability to achieve efficient speech dereverberation in dispersed microphone node scenarios.
ROSE: A Recognition-Oriented Speech Enhancement Framework in Air Traffic Control Using Multi-Objective Learning
Dec 11, 2023Radio speech echo is a specific phenomenon in the air traffic control (ATC) domain, which degrades speech quality and further impacts automatic speech recognition (ASR) accuracy. In this work, a recognition-oriented speech enhancement (ROSE) framework is proposed to improve speech intelligibility and also advance ASR accuracy, which serves as a plug-and-play tool in ATC scenarios and does not require additional retraining of the ASR model. Specifically, an encoder-decoder-based U-Net framework is proposed to eliminate the radio speech echo based on the real-world collected corpus. By incorporating the SE-oriented and ASR-oriented loss, ROSE is implemented in a multi-objective manner by learning shared representations across the two optimization objectives. An attention-based skip-fusion (ABSF) mechanism is applied to skip connections to refine the features. A channel and sequence attention (CSAtt) block is innovatively designed to guide the model to focus on informative representations and suppress disturbing features. The experimental results show that the ROSE significantly outperforms other state-of-the-art methods for both the SE and ASR tasks. In addition, the proposed approach can contribute to the desired performance improvements on public datasets.
On the Parameter Estimation of Sinusoidal Models for Speech and Audio Signals
Jan 02, 2024In this paper, we examine the parameter estimation performance of three well-known sinusoidal models for speech and audio. The first one is the standard Sinusoidal Model (SM), which is based on the Fast Fourier Transform (FFT). The second is the Exponentially Damped Sinusoidal Model (EDSM) which has been proposed in the last decade, and utilizes a subspace method for parameter estimation, and finally the extended adaptive Quasi-Harmonic Model (eaQHM), which has been recently proposed for AM-FM decomposition, and estimates the signal parameters using Least Squares on a set of basis function that are adaptive to the local characteristics of the signal. The parameter estimation of each model is briefly described and its performance is compared to the others in terms of signal reconstruction accuracy versus window size on a variety of synthetic signals and versus the number of sinusoids on real signals. The latter include highly non stationary signals, such as singing voices and guitar solos. The advantages and disadvantages of each model are presented via synthetic signals and then the application on real signals is discussed. Conclusively, eaQHM outperforms EDS in medium-to-large window size analysis, whereas EDSM yields higher reconstruction values for smaller analysis window sizes. Thus, a future research direction appears to be the merge of adaptivity of the eaQHM and parameter estimation robustness of the EDSM in a new paradigm for high-quality analysis and resynthesis of general audio signals.
An audio-quality-based multi-strategy approach for target speaker extraction in the MISP 2023 Challenge
Jan 08, 2024This paper describes our audio-quality-based multi-strategy approach for the audio-visual target speaker extraction (AVTSE) task in the Multi-modal Information based Speech Processing (MISP) 2023 Challenge. Specifically, our approach adopts different extraction strategies based on the audio quality, striking a balance between interference removal and speech preservation, which benifits the back-end automatic speech recognition (ASR) systems. Experiments show that our approach achieves a character error rate (CER) of 24.2% and 33.2% on the Dev and Eval set, respectively, obtaining the second place in the challenge.
Frame-level emotional state alignment method for speech emotion recognition
Dec 27, 2023Speech emotion recognition (SER) systems aim to recognize human emotional state during human-computer interaction. Most existing SER systems are trained based on utterance-level labels. However, not all frames in an audio have affective states consistent with utterance-level label, which makes it difficult for the model to distinguish the true emotion of the audio and perform poorly. To address this problem, we propose a frame-level emotional state alignment method for SER. First, we fine-tune HuBERT model to obtain a SER system with task-adaptive pretraining (TAPT) method, and extract embeddings from its transformer layers to form frame-level pseudo-emotion labels with clustering. Then, the pseudo labels are used to pretrain HuBERT. Hence, the each frame output of HuBERT has corresponding emotional information. Finally, we fine-tune the above pretrained HuBERT for SER by adding an attention layer on the top of it, which can focus only on those frames that are emotionally more consistent with utterance-level label. The experimental results performed on IEMOCAP indicate that our proposed method performs better than state-of-the-art (SOTA) methods.