 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully-automated sleep staging: multicenter validation of a generalizable deep neural network for Parkinson's disease and isolated REM sleep behavior disorder
Feb 11, 2026Isolated REM sleep behavior disorder (iRBD) is a key prodromal marker of Parkinson's disease (PD), and video-polysomnography (vPSG) remains the diagnostic gold standard. However, manual sleep staging is particularly challenging in neurodegenerative diseases due to EEG abnormalities and fragmented sleep, making PSG assessments a bottleneck for deploying new RBD screening technologies at scale. We adapted U-Sleep, a deep neural network, for generalizable sleep staging in PD and iRBD. A pretrained U-Sleep model, based on a large, multisite non-neurodegenerative dataset (PUB; 19,236 PSGs across 12 sites), was fine-tuned on research datasets from two centers (Lundbeck Foundation Parkinson's Disease Research Center (PACE) and the Cologne-Bonn Cohort (CBC); 112 PD, 138 iRBD, 89 age-matched controls. The resulting model was evaluated on an independent dataset from the Danish Center for Sleep Medicine (DCSM; 81 PD, 36 iRBD, 87 sleep-clinic controls). A subset of PSGs with low agreement between the human rater and the model (Cohen's $κ$ < 0.6) was re-scored by a second blinded human rater to identify sources of disagreement. Finally, we applied confidence-based thresholds to optimize REM sleep staging. The pretrained model achieved mean $κ$ = 0.81 in PUB, but $κ$ = 0.66 when applied directly to PACE/CBC. By fine-tuning the model, we developed a generalized model with $κ$ = 0.74 on PACE/CBC (p < 0.001 vs. the pretrained model). In DCSM, mean and median $κ$ increased from 0.60 to 0.64 (p < 0.001) and 0.64 to 0.69 (p < 0.001), respectively. In the interrater study, PSGs with low agreement between the model and the initial scorer showed similarly low agreement between human scorers. Applying a confidence threshold increased the proportion of correctly identified REM sleep epochs from 85% to 95.5%, while preserving sufficient (> 5 min) REM sleep for 95% of subjects.
A Direct Comparison of Simultaneously Recorded Scalp, Around-Ear, and In-Ear EEG for Neural Selective Auditory Attention Decoding to Speech
May 20, 2025Current assistive hearing devices, such as hearing aids and cochlear implants, lack the ability to adapt to the listener's focus of auditory attention, limiting their effectiveness in complex acoustic environments like cocktail party scenarios where multiple conversations occur simultaneously. Neuro-steered hearing devices aim to overcome this limitation by decoding the listener's auditory attention from neural signals, such as electroencephalography (EEG). While many auditory attention decoding (AAD) studies have used high-density scalp EEG, such systems are impractical for daily use as they are bulky and uncomfortable. Therefore, AAD with wearable and unobtrusive EEG systems that are comfortable to wear and can be used for long-term recording are required. Around-ear EEG systems like cEEGrids have shown promise in AAD, but in-ear EEG, recorded via custom earpieces offering superior comfort, remains underexplored. We present a new AAD dataset with simultaneously recorded scalp, around-ear, and in-ear EEG, enabling a direct comparison. Using a classic linear stimulus reconstruction algorithm, a significant performance gap between all three systems exists, with AAD accuracies of 83.4% (scalp), 67.2% (around-ear), and 61.1% (in-ear) on 60s decision windows. These results highlight the trade-off between decoding performance and practical usability. Yet, while the ear-based systems using basic algorithms might currently not yield accurate enough performances for a decision speed-sensitive application in hearing aids, their significant performance suggests potential for attention monitoring on longer timescales. Furthermore, adding an external reference or a few scalp electrodes via greedy forward selection substantially and quickly boosts accuracy by over 10 percent point, especially for in-ear EEG. These findings position in-ear EEG as a promising component in EEG sensor networks for AAD.
AADNet: An End-to-End Deep Learning Model for Auditory Attention Decoding
Oct 16, 2024



Auditory attention decoding (AAD) is the process of identifying the attended speech in a multi-talker environment using brain signals, typically recorded through electroencephalography (EEG). Over the past decade, AAD has undergone continuous development, driven by its promising application in neuro-steered hearing devices. Most AAD algorithms are relying on the increase in neural entrainment to the envelope of attended speech, as compared to unattended speech, typically using a two-step approach. First, the algorithm predicts representations of the attended speech signal envelopes; second, it identifies the attended speech by finding the highest correlation between the predictions and the representations of the actual speech signals. In this study, we proposed a novel end-to-end neural network architecture, named AADNet, which combines these two stages into a direct approach to address the AAD problem. We compare the proposed network against the traditional approaches, including linear stimulus reconstruction, canonical correlation analysis, and an alternative non-linear stimulus reconstruction using two different datasets. AADNet shows a significant performance improvement for both subject-specific and subject-independent models. Notably, the average subject-independent classification accuracies from 56.1 % to 82.7 % with analysis window lengths ranging from 1 to 40 seconds, respectively, show a significantly improved ability to generalize to data from unseen subjects. These results highlight the potential of deep learning models for advancing AAD, with promising implications for future hearing aids, assistive devices, and clinical assessments.
Study of cognitive component of auditory attention to natural speech events
Dec 19, 2023



Event-related potentials (ERP) have been used to address a wide range of research questions in neuroscience and cognitive psychology including selective auditory attention. The recent progress in auditory attention decoding (AAD) methods is based on algorithms that find a relation between the audio envelope and the neurophysiological response. The most popular approach is based on the reconstruction of the audio envelope based on EEG signals. However, these methods are mainly based on the neurophysiological entrainment to physical attributes of the sensory stimulus and are generally limited by a long detection window. This study proposes a novel approach to auditory attention decoding by looking at higher-level cognitive responses to natural speech. To investigate if natural speech events elicit cognitive ERP components and how these components are affected by attention mechanisms, we designed a series of four experimental paradigms with increasing complexity: a word category oddball paradigm, a word category oddball paradigm with competing speakers, and competing speech streams with and without specific targets. We recorded the electroencephalogram (EEG) from 32 scalp electrodes and 12 in-ear electrodes (ear-EEG) from 24 participants. A cognitive ERP component, which we believe is related to the well-known P3b component, was observed at parietal electrode sites with a latency of approximately 620 ms. The component is statistically most significant for the simplest paradigm and gradually decreases in strength with increasing complexity of the paradigm. We also show that the component can be observed in the in-ear EEG signals by using spatial filtering. The cognitive component elicited by auditory attention may contribute to decoding auditory attention from electrophysiological recordings and its presence in the ear-EEG signals is promising for future applications within hearing aids.
Personalized Automatic Sleep Staging with Single-Night Data: a Pilot Study with KL-Divergence Regularization
May 11, 2020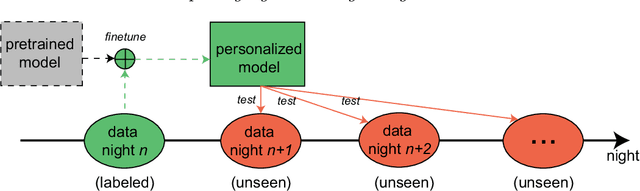
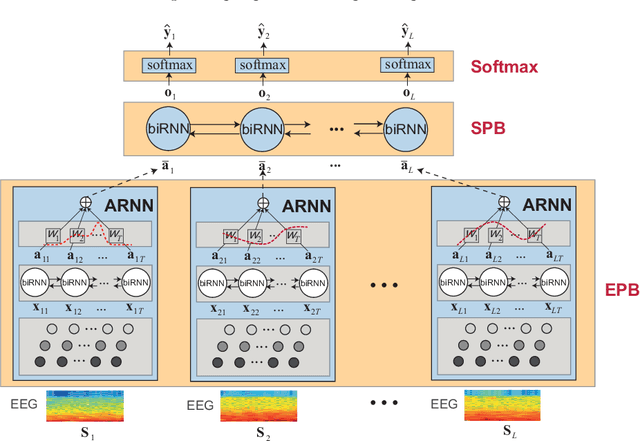
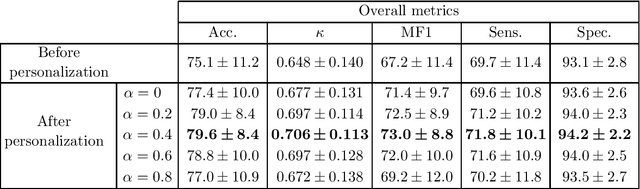
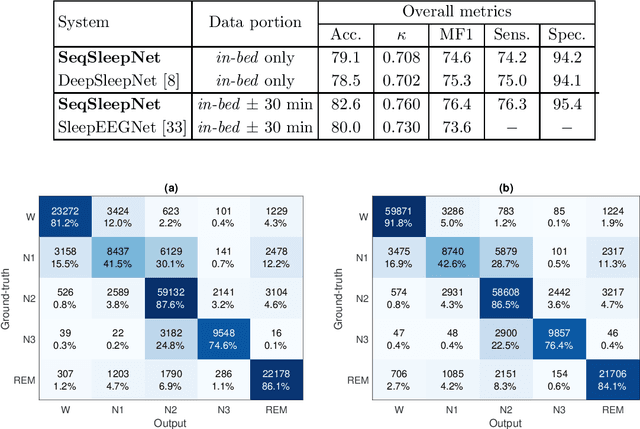
Brain waves vary between people. An obvious way to improve automatic sleep staging for longitudinal sleep monitoring is personalization of algorithms based on individual characteristics extracted from the first night of data. As a single night is a very small amount of data to train a sleep staging model, we propose a Kullback-Leibler (KL) divergence regularized transfer learning approach to address this problem. We employ the pretrained SeqSleepNet (i.e. the subject independent model) as a starting point and finetune it with the single-night personalization data to derive the personalized model. This is done by adding the KL divergence between the output of the subject independent model and the output of the personalized model to the loss function during finetuning. In effect, KL-divergence regularization prevents the personalized model from overfitting to the single-night data and straying too far away from the subject independent model. Experimental results on the Sleep-EDF Expanded database with 75 subjects show that sleep staging personalization with a single-night data is possible with help of the proposed KL-divergence regularization. On average, we achieve a personalized sleep staging accuracy of 79.6%, a Cohen's kappa of 0.706, a macro F1-score of 73.0%, a sensitivity of 71.8%, and a specificity of 94.2%. We find both that the approach is robust against overfitting and that it improves the accuracy by 4.5 percentage points compared to non-personalization and 2.2 percentage points compared to personalization without regularization.