 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Cross Lingual Cross Corpus Speech Emotion Recognition
Mar 18, 2020

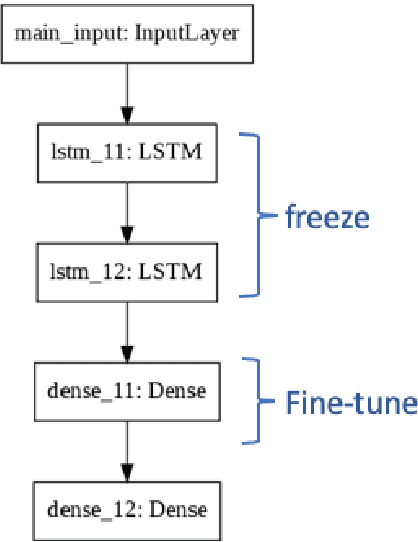
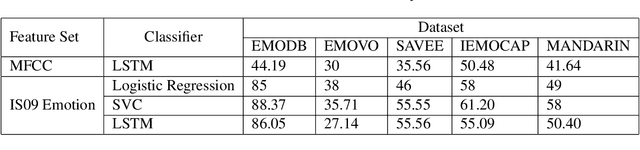
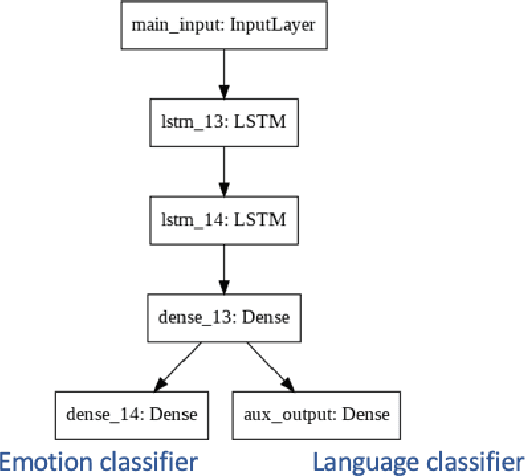
The majority of existing speech emotion recognition models are trained and evaluated on a single corpus and a single language setting. These systems do not perform as well when applied in a cross-corpus and cross-language scenario. This paper presents results for speech emotion recognition for 4 languages in both single corpus and cross corpus setting. Additionally, since multi-task learning (MTL) with gender, naturalness and arousal as auxiliary tasks has shown to enhance the generalisation capabilities of the emotion models, this paper introduces language ID as another auxiliary task in MTL framework to explore the role of spoken language on emotion recognition which has not been studied yet.
FastSpeech 2: Fast and High-Quality End-to-End Text-to-Speech
Jun 08, 2020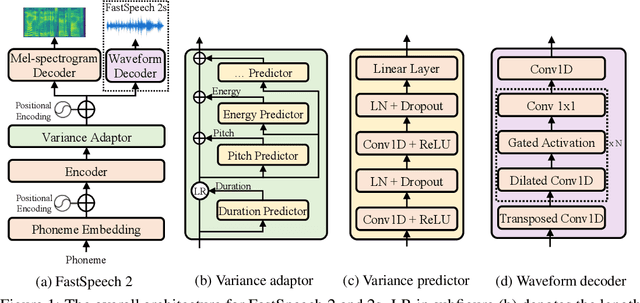
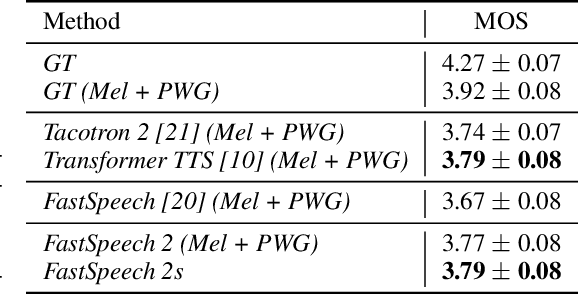
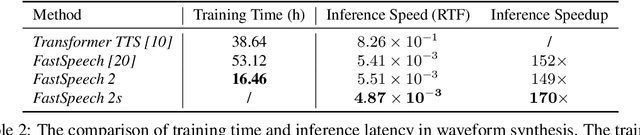
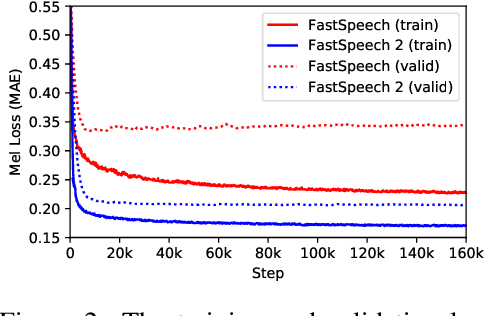
Advanced text-to-speech (TTS) models such as FastSpeech can synthesize speech significantly faster than previous autoregressive models with comparable quality. The training of FastSpeech model relies on an autoregressive teacher model for duration prediction (to provide more information as input) and knowledge distillation (to simplify the data distribution in output), which can ease the one-to-many mapping problem (i.e., multiple speech variations correspond to the same text) in TTS. However, FastSpeech has several disadvantages: 1) the teacher-student distillation pipeline is complicated, 2) the duration extracted from the teacher model is not accurate enough, and the target mel-spectrograms distilled from teacher model suffer from information loss due to data simplification, both of which limit the voice quality. In this paper, we propose FastSpeech 2, which addresses the issues in FastSpeech and better solves the one-to-many mapping problem in TTS by 1) directly training the model with ground-truth target instead of the simplified output from teacher, and 2) introducing more variation information of speech (e.g., pitch, energy and more accurate duration) as conditional inputs. Specifically, we extract duration, pitch and energy from speech waveform and directly take them as conditional inputs during training and use predicted values during inference. We further design FastSpeech 2s, which is the first attempt to directly generate speech waveform from text in parallel, enjoying the benefit of full end-to-end training and even faster inference than FastSpeech. Experimental results show that 1) FastSpeech 2 and 2s outperform FastSpeech in voice quality with much simplified training pipeline and reduced training time; 2) FastSpeech 2 and 2s can match the voice quality of autoregressive models while enjoying much faster inference speed.
From Universal Language Model to Downstream Task: Improving RoBERTa-Based Vietnamese Hate Speech Detection
Feb 24, 2021Natural language processing is a fast-growing field of artificial intelligence. Since the Transformer was introduced by Google in 2017, a large number of language models such as BERT, GPT, and ELMo have been inspired by this architecture. These models were trained on huge datasets and achieved state-of-the-art results on natural language understanding. However, fine-tuning a pre-trained language model on much smaller datasets for downstream tasks requires a carefully-designed pipeline to mitigate problems of the datasets such as lack of training data and imbalanced data. In this paper, we propose a pipeline to adapt the general-purpose RoBERTa language model to a specific text classification task: Vietnamese Hate Speech Detection. We first tune the PhoBERT on our dataset by re-training the model on the Masked Language Model task; then, we employ its encoder for text classification. In order to preserve pre-trained weights while learning new feature representations, we further utilize different training techniques: layer freezing, block-wise learning rate, and label smoothing. Our experiments proved that our proposed pipeline boosts the performance significantly, achieving a new state-of-the-art on Vietnamese Hate Speech Detection campaign with 0.7221 F1 score.
* Published in 2020 12th International Conference on Knowledge and Systems Engineering (KSE)
DNSMOS: A Non-Intrusive Perceptual Objective Speech Quality metric to evaluate Noise Suppressors
Oct 28, 2020
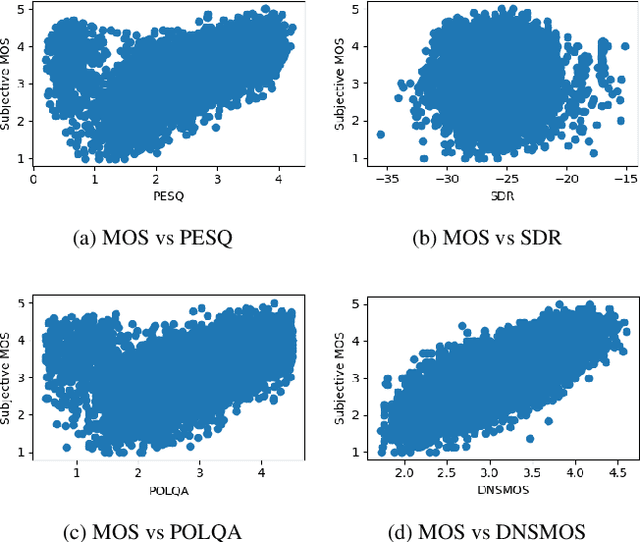
Human subjective evaluation is the gold standard to evaluate speech quality optimized for human perception. Perceptual objective metrics serve as a proxy for subjective scores. The conventional and widely used metrics require a reference clean speech signal, which is unavailable in real recordings. The no-reference approaches correlate poorly with human ratings and are not widely adopted in the research community. One of the biggest use cases of these perceptual objective metrics is to evaluate noise suppression algorithms. This paper introduces a multi-stage self-teaching based perceptual objective metric that is designed to evaluate noise suppressors. The proposed method generalizes well in challenging test conditions with a high correlation to human ratings.
USEV: Universal Speaker Extraction with Visual Cue
Sep 30, 2021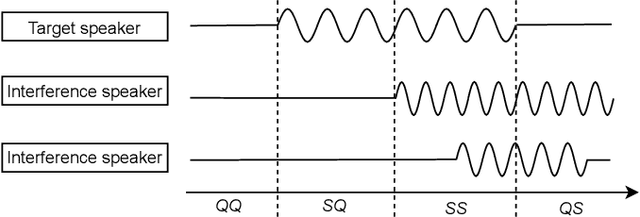
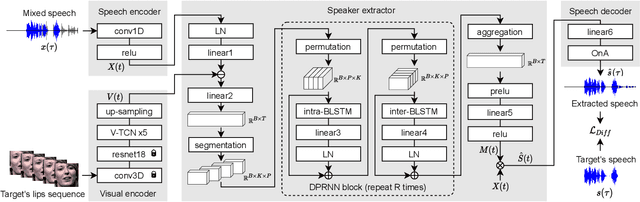
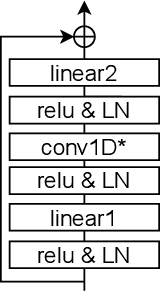
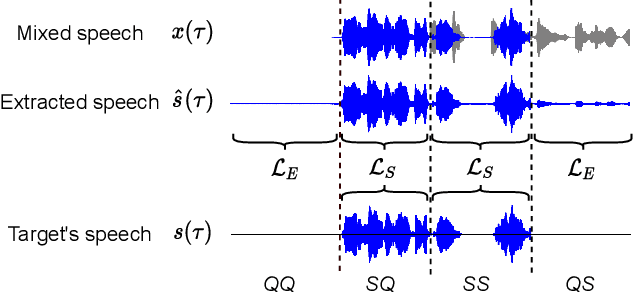
A speaker extraction algorithm seeks to extract the target speaker's voice from a multi-talker speech mixture. An auxiliary reference, such as a video recording or a pre-recorded speech, is usually used as a cue to form a top-down auditory attention. The prior studies are focused mostly on speaker extraction from a multi-talker speech mixture with highly overlapping speakers. However, a multi-talker speech mixture is often sparsely overlapped, furthermore, the target speaker could even be absent sometimes. In this paper, we propose a universal speaker extraction network that works for all multi-talker scenarios, where the target speaker can be either absent or present. When the target speaker is present, the network performs over a wide range of target-interference speaker overlapping ratios, from 0% to 100%. The speech in such universal multi-talker scenarios is generally described as sparsely overlapped speech. We advocate that a visual cue, i.e. lips movement, is more informative to serve as the auxiliary reference than an audio cue, i.e. pre-recorded speech. In addition, we propose a scenario-aware differentiated loss function for network training. The experimental results show that our proposed network outperforms various competitive baselines in disentangling sparsely overlapped speech in terms of signal fidelity and perceptual evaluations.
Incorporating Symbolic Sequential Modeling for Speech Enhancement
Apr 30, 2019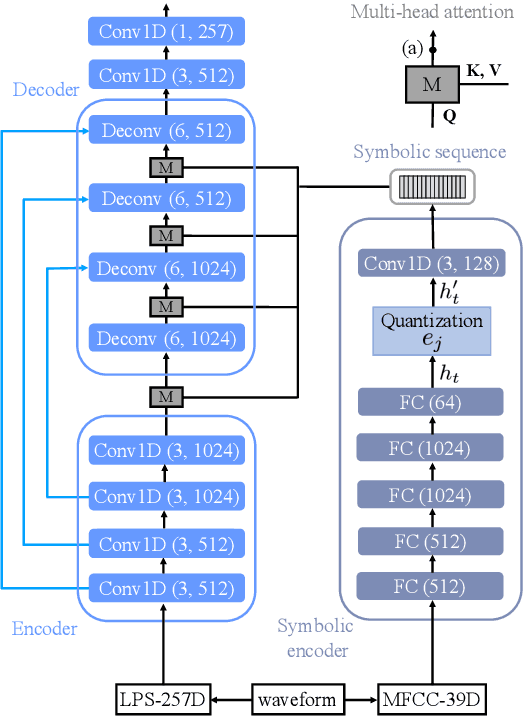
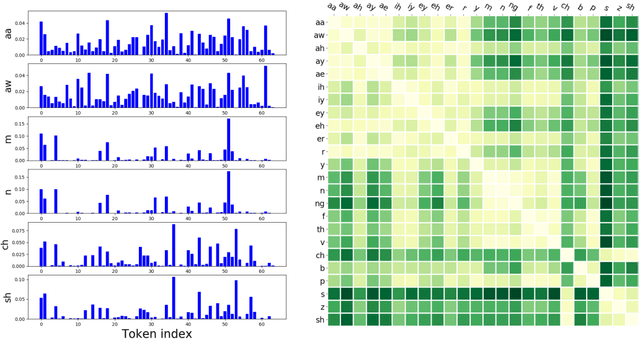
In a noisy environment, a lossy speech signal can be automatically restored by a listener if he/she knows the language well. That is, with the built-in knowledge of a "language model", a listener may effectively suppress noise interference and retrieve the target speech signals. Accordingly, we argue that familiarity with the underlying linguistic content of spoken utterances benefits speech enhancement (SE) in noisy environments. In this study, in addition to the conventional modeling for learning the acoustic noisy-clean speech mapping, an abstract symbolic sequential modeling is incorporated into the SE framework. This symbolic sequential modeling can be regarded as a "linguistic constraint" in learning the acoustic noisy-clean speech mapping function. In this study, the symbolic sequences for acoustic signals are obtained as discrete representations with a Vector Quantized Variational Autoencoder algorithm. The obtained symbols are able to capture high-level phoneme-like content from speech signals. The experimental results demonstrate that the proposed framework can significantly improve the SE performance in terms of perceptual evaluation of speech quality (PESQ) and short-time objective intelligibility (STOI) on the TIMIT dataset.
Enabling Real-time On-chip Audio Super Resolution for Bone Conduction Microphones
Dec 24, 2021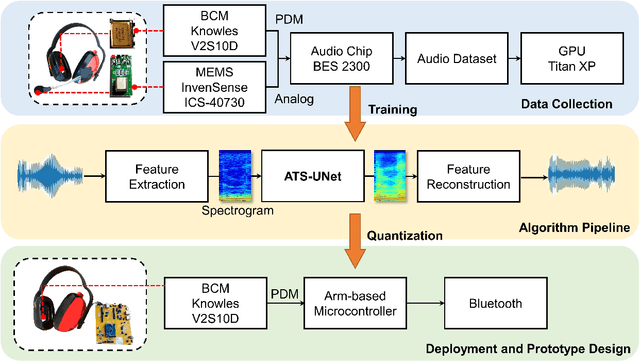
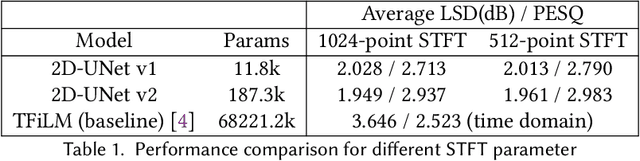
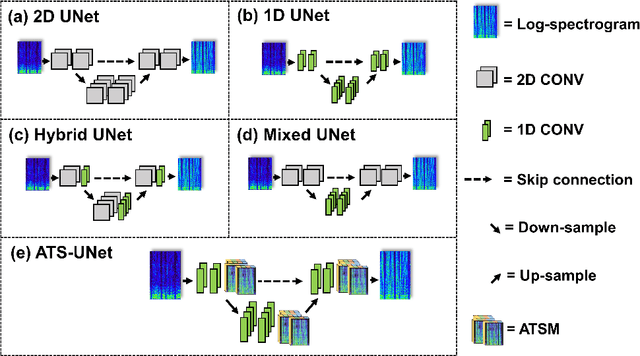
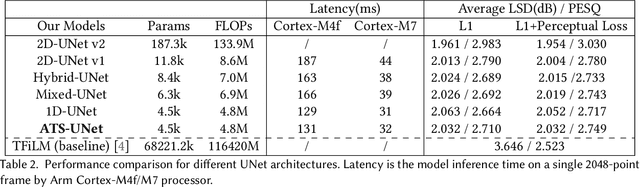
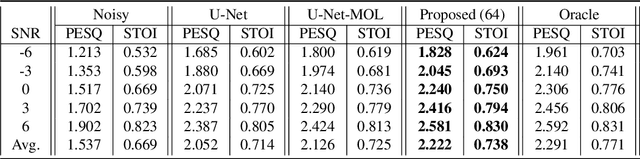
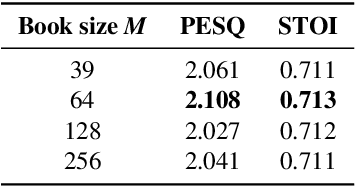
Voice communication using the air conduction microphone in noisy environments suffers from the degradation of speech audibility. Bone conduction microphones (BCM) are robust against ambient noises but suffer from limited effective bandwidth due to their sensing mechanism. Although existing audio super resolution algorithms can recover the high frequency loss to achieve high-fidelity audio, they require considerably more computational resources than available in low-power hearable devices. This paper proposes the first-ever real-time on-chip speech audio super resolution system for BCM. To accomplish this, we built and compared a series of lightweight audio super resolution deep learning models. Among all these models, ATS-UNet is the most cost-efficient because the proposed novel Audio Temporal Shift Module (ATSM) reduces the network's dimensionality while maintaining sufficient temporal features from speech audios. Then we quantized and deployed the ATS-UNet to low-end ARM micro-controller units for real-time embedded prototypes. Evaluation results show that our system achieved real-time inference speed on Cortex-M7 and higher quality than the baseline audio super resolution method. Finally, we conducted a user study with ten experts and ten amateur listeners to evaluate our method's effectiveness to human ears. Both groups perceived a significantly higher speech quality with our method when compared to the solutions with the original BCM or air conduction microphone with cutting-edge noise reduction algorithms.
Acoustic echo suppression using a learning-based multi-frame minimum variance distortionless response filter
May 07, 2022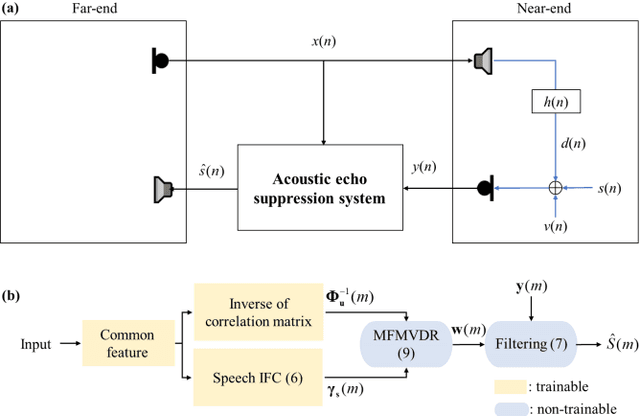
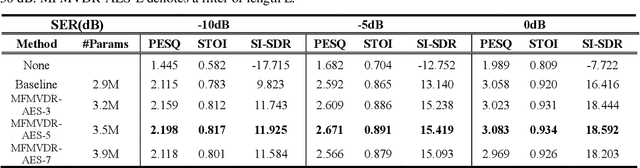
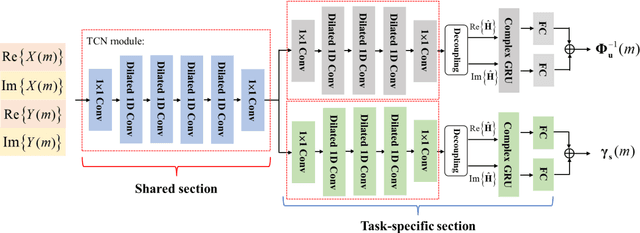
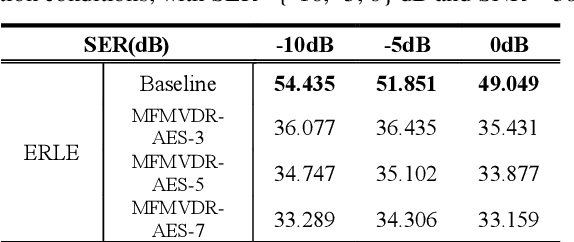
Distortion resulting from acoustic echo suppression (AES) is a common issue in full-duplex communication. To address the distortion problem, a multi-frame minimum variance distortionless response (MFMVDR) filtering technique is proposed. The MFMVDR filter with parameter estimation which was used in speech enhancement problems is extended in this study from a deep learning perspective. To alleviate numerical instability of the MFMVDR filter, we propose to directly estimate the inverse of the correlation matrix. The AES system is advantageous in that no double-talk detection is required. The negative scale-invariant signal-to-distortion ratio is employed as the loss function in training the network at the output of the MFMVDR filter. Simulation results have demonstrated the efficacy of the proposed learning-based AES system in double-talk, background noise, and nonlinear distortion conditions.
Latency-Controlled Neural Architecture Search for Streaming Speech Recognition
May 08, 2021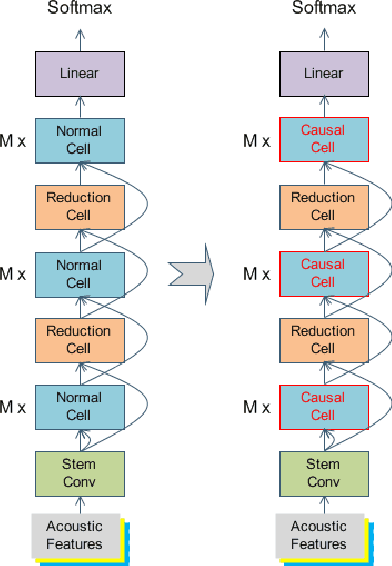


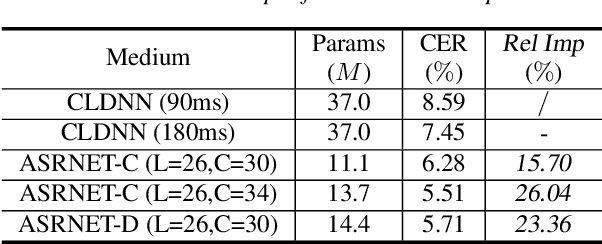
Recently, neural architecture search (NAS) has attracted much attention and has been explored for automatic speech recognition (ASR). Our prior work has shown promising results compared with hand-designed neural networks. In this work, we focus on streaming ASR scenarios and propose the latency-controlled NAS for acoustic modeling. First, based on the vanilla neural architecture, normal cells are altered to be causal cells, in order to control the total latency of the neural network. Second, a revised operation space with a smaller receptive field is proposed to generate the final architecture with low latency. Extensive experiments show that: 1) Based on the proposed neural architecture, the neural networks with a medium latency of 550ms (millisecond) and a low latency of 190ms can be learned in the vanilla and revised operation space respectively. 2) For the low latency setting, the evaluation network can achieve more than 19\% (average on the four test sets) relative improvements compared with the hybrid CLDNN baseline, on a 10k-hour large-scale dataset. Additional 11\% relative improvements can be achieved if the latency of the neural network is relaxed to the medium latency setting.
Adapt-and-Adjust: Overcoming the Long-Tail Problem of Multilingual Speech Recognition
Dec 03, 2020
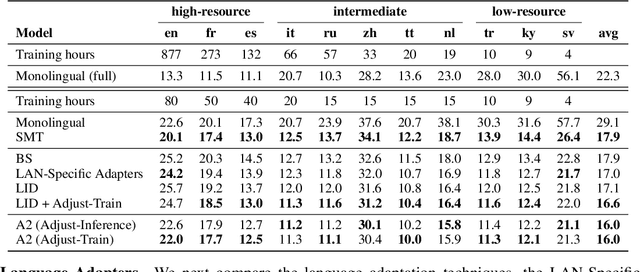
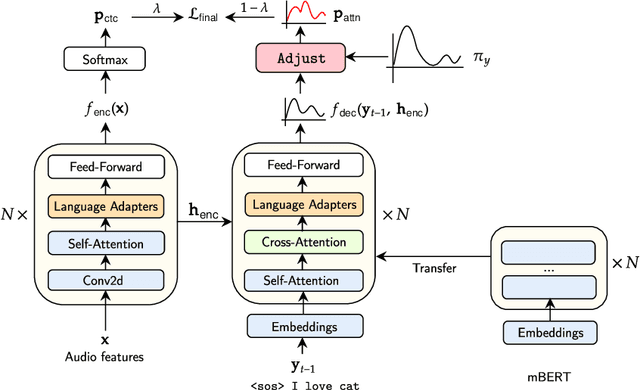
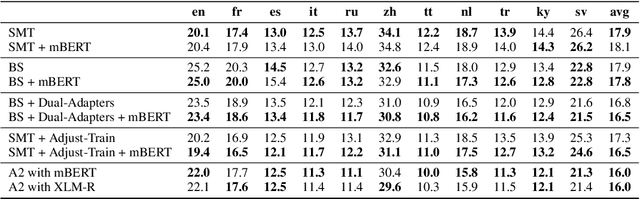
One crucial challenge of real-world multilingual speech recognition is the long-tailed distribution problem, where some resource-rich languages like English have abundant training data, but a long tail of low-resource languages have varying amounts of limited training data. To overcome the long-tail problem, in this paper, we propose Adapt-and-Adjust (A2), a transformer-based multi-task learning framework for end-to-end multilingual speech recognition. The A2 framework overcomes the long-tail problem via three techniques: (1) exploiting a pretrained multilingual language model (mBERT) to improve the performance of low-resource languages; (2) proposing dual adapters consisting of both language-specific and language-agnostic adaptation with minimal additional parameters; and (3) overcoming the class imbalance, either by imposing class priors in the loss during training or adjusting the logits of the softmax output during inference. Extensive experiments on the CommonVoice corpus show that A2 significantly outperforms conventional approaches.