 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Self-Supervised Detection of Fundamental Frequency and Accurate Probability of Voicing in Monophonic Music
Jan 16, 2026Reliable fundamental frequency (F 0) and voicing estimation is essential for neural synthesis, yet many pitch extractors depend on large labeled corpora and degrade under realistic recording artifacts. We propose a lightweight, fully self-supervised framework for joint F 0 estimation and voicing inference, designed for rapid single-instrument training from limited audio. Using transposition-equivariant learning on CQT features, we introduce an EM-style iterative reweighting scheme that uses Shift Cross-Entropy (SCE) consistency as a reliability signal to suppress uninformative noisy/unvoiced frames. The resulting weights provide confidence scores that enable pseudo-labeling for a separate lightweight voicing classifier without manual annotations. Trained on MedleyDB and evaluated on MDB-stem-synth ground truth, our method achieves competitive cross-corpus performance (RPA 95.84, RCA 96.24) and demonstrates cross-instrument generalization.
Quality-Controlled Multimodal Emotion Recognition in Conversations with Identity-Based Transfer Learning and MAMBA Fusion
Nov 18, 2025This paper addresses data quality issues in multimodal emotion recognition in conversation (MERC) through systematic quality control and multi-stage transfer learning. We implement a quality control pipeline for MELD and IEMOCAP datasets that validates speaker identity, audio-text alignment, and face detection. We leverage transfer learning from speaker and face recognition, assuming that identity-discriminative embeddings capture not only stable acoustic and Facial traits but also person-specific patterns of emotional expression. We employ RecoMadeEasy(R) engines for extracting 512-dimensional speaker and face embeddings, fine-tune MPNet-v2 for emotion-aware text representations, and adapt these features through emotion-specific MLPs trained on unimodal datasets. MAMBA-based trimodal fusion achieves 64.8% accuracy on MELD and 74.3% on IEMOCAP. These results show that combining identity-based audio and visual embeddings with emotion-tuned text representations on a quality-controlled subset of data yields consistent competitive performance for multimodal emotion recognition in conversation and provides a basis for further improvement on challenging, low-frequency emotion classes.
* 8 pages, 14 images, 3 tables, Recognition Technologies, Inc. Technical Report RTI-20251118-01
Spontaneous Informal Speech Dataset for Punctuation Restoration
Sep 17, 2024



Presently, punctuation restoration models are evaluated almost solely on well-structured, scripted corpora. On the other hand, real-world ASR systems and post-processing pipelines typically apply towards spontaneous speech with significant irregularities, stutters, and deviations from perfect grammar. To address this discrepancy, we introduce SponSpeech, a punctuation restoration dataset derived from informal speech sources, which includes punctuation and casing information. In addition to publicly releasing the dataset, we contribute a filtering pipeline that can be used to generate more data. Our filtering pipeline examines the quality of both speech audio and transcription text. We also carefully construct a ``challenging" test set, aimed at evaluating models' ability to leverage audio information to predict otherwise grammatically ambiguous punctuation. SponSpeech is available at https://github.com/GitHubAccountAnonymous/PR, along with all code for dataset building and model runs.
* 8 pages, 7 tables, 1 figure, Recognition Technologies, Inc. Technical Report
Carnatic Raga Identification System using Rigorous Time-Delay Neural Network
May 25, 2024Large scale machine learning-based Raga identification continues to be a nontrivial issue in the computational aspects behind Carnatic music. Each raga consists of many unique and intrinsic melodic patterns that can be used to easily identify them from others. These ragas can also then be used to cluster songs within the same raga, as well as identify songs in other closely related ragas. In this case, the input sound is analyzed using a combination of steps including using a Discrete Fourier transformation and using Triangular Filtering to create custom bins of possible notes, extracting features from the presence of particular notes or lack thereof. Using a combination of Neural Networks including 1D Convolutional Neural Networks conventionally known as Time-Delay Neural Networks) and Long Short-Term Memory (LSTM), which are a form of Recurrent Neural Networks, the backbone of the classification strategy to build the model can be created. In addition, to help with variations in shruti, a long-time attention-based mechanism will be implemented to determine the relative changes in frequency rather than the absolute differences. This will provide a much more meaningful data point when training audio clips in different shrutis. To evaluate the accuracy of the classifier, a dataset of 676 recordings is used. The songs are distributed across the list of ragas. The goal of this program is to be able to effectively and efficiently label a much wider range of audio clips in more shrutis, ragas, and with more background noise.
* 7 pages, 2 tables, 3 figures
Robust Open-Set Spoken Language Identification and the CU MultiLang Dataset
Aug 29, 2023Most state-of-the-art spoken language identification models are closed-set; in other words, they can only output a language label from the set of classes they were trained on. Open-set spoken language identification systems, however, gain the ability to detect when an input exhibits none of the original languages. In this paper, we implement a novel approach to open-set spoken language identification that uses MFCC and pitch features, a TDNN model to extract meaningful feature embeddings, confidence thresholding on softmax outputs, and LDA and pLDA for learning to classify new unknown languages. We present a spoken language identification system that achieves 91.76% accuracy on trained languages and has the capability to adapt to unknown languages on the fly. To that end, we also built the CU MultiLang Dataset, a large and diverse multilingual speech corpus which was used to train and evaluate our system.
* 6pages, 1 table, 6 figures
Efficient Ensemble Architecture for Multimodal Acoustic and Textual Embeddings in Punctuation Restoration using Time-Delay Neural Networks
Feb 26, 2023



Punctuation restoration plays an essential role in the post-processing procedure of automatic speech recognition, but model efficiency is a key requirement for this task. To that end, we present EfficientPunct, an ensemble method with a multimodal time-delay neural network that outperforms the current best model by 1.0 F1 points, using less than a tenth of its parameters to process embeddings. We streamline a speech recognizer to efficiently output hidden layer latent vectors as audio embeddings for punctuation restoration, as well as BERT to extract meaningful text embeddings. By using forced alignment and temporal convolutions, we eliminate the need for multi-head attention-based fusion, greatly increasing computational efficiency but also raising performance. EfficientPunct sets a new state of the art, in terms of both performance and efficiency, with an ensemble that weights BERT's purely language-based predictions slightly more than the multimodal network's predictions.
A Transaction Represented with Weighted Finite-State Transducers
Feb 01, 2023Not all contracts are good, but all good contracts can be expressed as a finite-state transition system ("State-Transition Contracts"). Contracts that can be represented as State-Transition Contracts discretize fat-tailed risk to foreseeable, managed risk, define the boundary of relevant events governed by the relationship, and eliminate the potential of inconsistent contractual provisions. Additionally, State-Transition Contracts reap the substantial benefit of being able to be analyzed under the rules governing the science of the theory of computation. Simple State-Transition Contracts can be represented as discrete finite automata; more complicated State-Transition Contracts, such as those that have downstream effects on other agreements or complicated pathways of performance, benefit from representation as weighted finite-state transducers, with weights assigned as costs, penalties, or probabilities of transitions. This research paper (the "Research" or "Paper") presents a complex legal transaction represented as weighted finite-state transducers. Furthermore, we show that the mathematics/algorithms permitted by the algebraic structure of weighted finite-state transducers provides actionable, legal insight into the transaction.
Modernizing Open-Set Speech Language Identification
May 20, 2022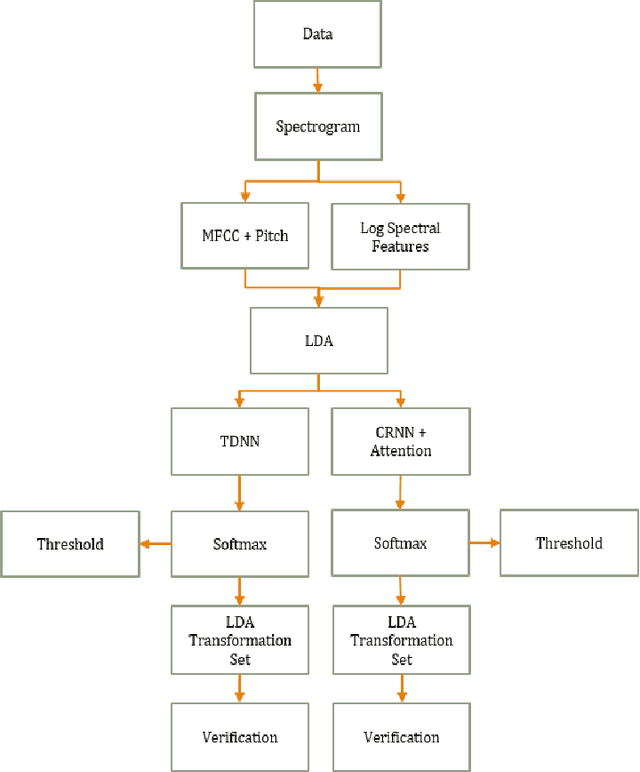
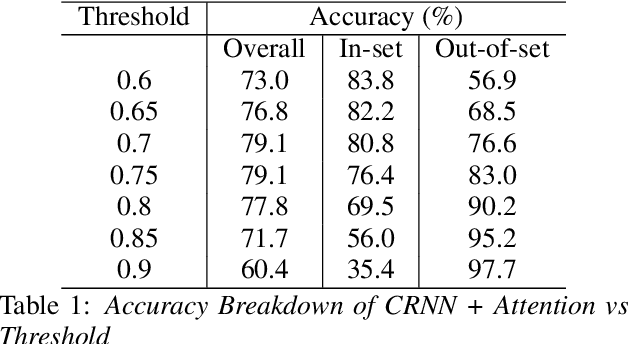
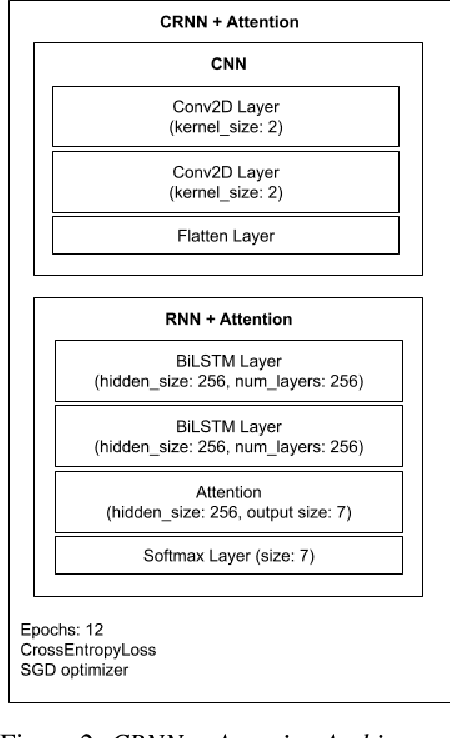

While most modern speech Language Identification methods are closed-set, we want to see if they can be modified and adapted for the open-set problem. When switching to the open-set problem, the solution gains the ability to reject an audio input when it fails to match any of our known language options. We tackle the open-set task by adapting two modern-day state-of-the-art approaches to closed-set language identification: the first using a CRNN with attention and the second using a TDNN. In addition to enhancing our input feature embeddings using MFCCs, log spectral features, and pitch, we will be attempting two approaches to out-of-set language detection: one using thresholds, and the other essentially performing a verification task. We will compare both the performance of the TDNN and the CRNN, as well as our detection approaches.
Bi-LSTM Scoring Based Similarity Measurement with Agglomerative Hierarchical Clustering (AHC) for Speaker Diarization
May 19, 2022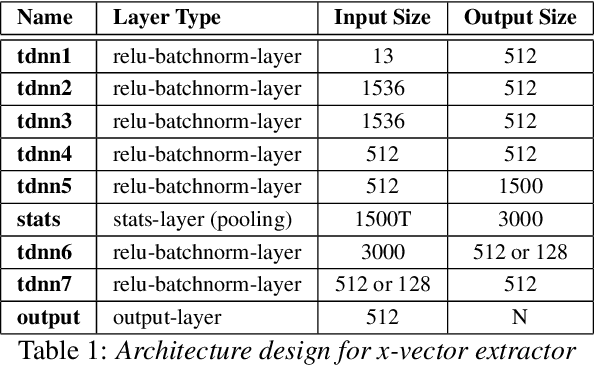
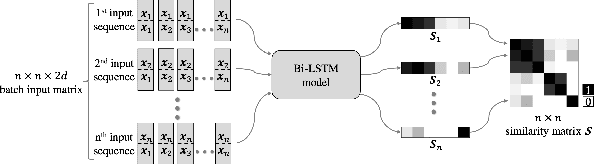
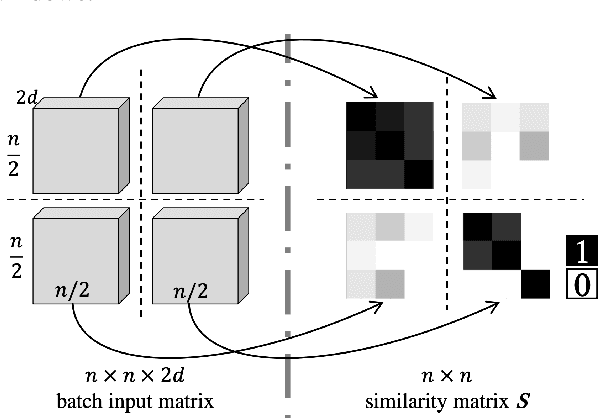
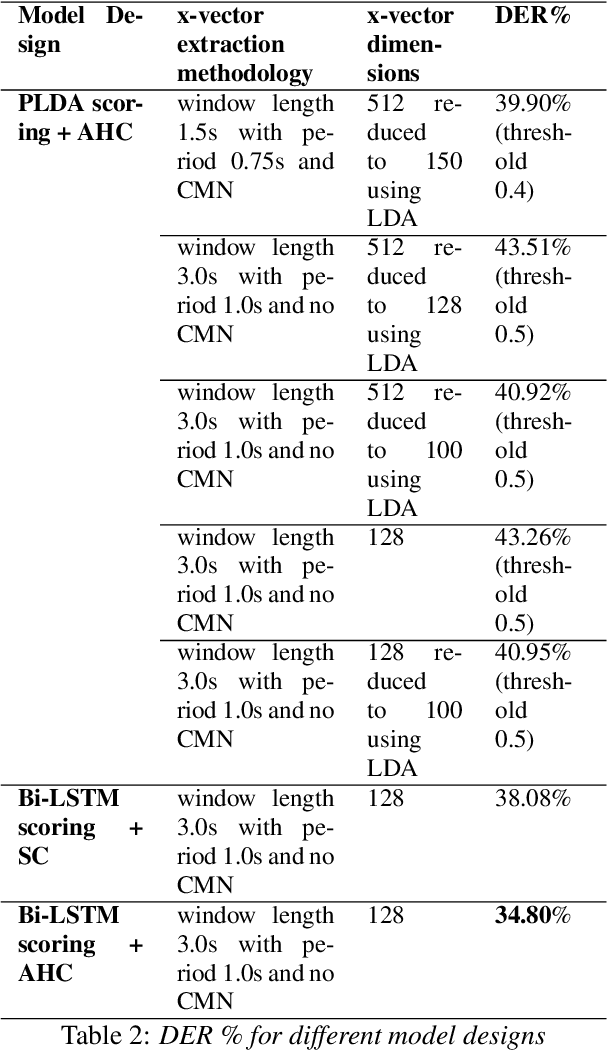
Majority of speech signals across different scenarios are never available with well-defined audio segments containing only a single speaker. A typical conversation between two speakers consists of segments where their voices overlap, interrupt each other or halt their speech in between multiple sentences. Recent advancements in diarization technology leverage neural network-based approaches to improvise multiple subsystems of speaker diarization system comprising of extracting segment-wise embedding features and detecting changes in the speaker during conversation. However, to identify speaker through clustering, models depend on methodologies like PLDA to generate similarity measure between two extracted segments from a given conversational audio. Since these algorithms ignore the temporal structure of conversations, they tend to achieve a higher Diarization Error Rate (DER), thus leading to misdetections both in terms of speaker and change identification. Therefore, to compare similarity of two speech segments both independently and sequentially, we propose a Bi-directional Long Short-term Memory network for estimating the elements present in the similarity matrix. Once the similarity matrix is generated, Agglomerative Hierarchical Clustering (AHC) is applied to further identify speaker segments based on thresholding. To evaluate the performance, Diarization Error Rate (DER%) metric is used. The proposed model achieves a low DER of 34.80% on a test set of audio samples derived from ICSI Meeting Corpus as compared to traditional PLDA based similarity measurement mechanism which achieved a DER of 39.90%.
Automatic Spoken Language Identification using a Time-Delay Neural Network
May 19, 2022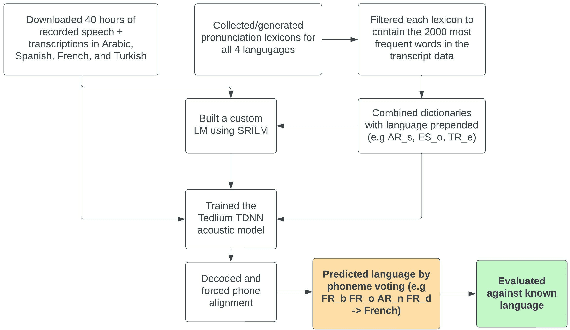



Closed-set spoken language identification is the task of recognizing the language being spoken in a recorded audio clip from a set of known languages. In this study, a language identification system was built and trained to distinguish between Arabic, Spanish, French, and Turkish based on nothing more than recorded speech. A pre-existing multilingual dataset was used to train a series of acoustic models based on the Tedlium TDNN model to perform automatic speech recognition. The system was provided with a custom multilingual language model and a specialized pronunciation lexicon with language names prepended to phones. The trained model was used to generate phone alignments to test data from all four languages, and languages were predicted based on a voting scheme choosing the most common language prepend in an utterance. Accuracy was measured by comparing predicted languages to known languages, and was determined to be very high in identifying Spanish and Arabic, and somewhat lower in identifying Turkish and French.