 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Learning Speech-driven 3D Conversational Gestures from Video
Feb 13, 2021
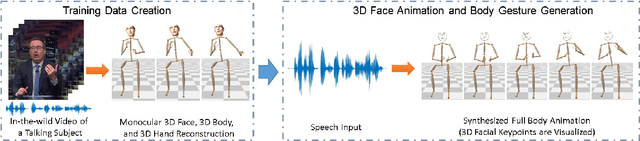
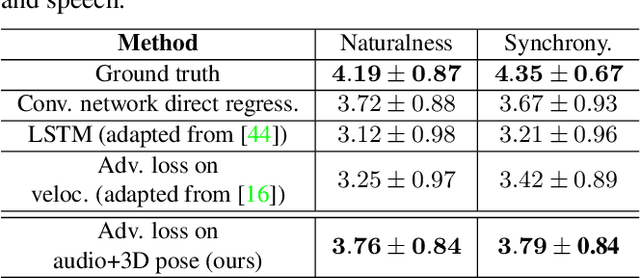
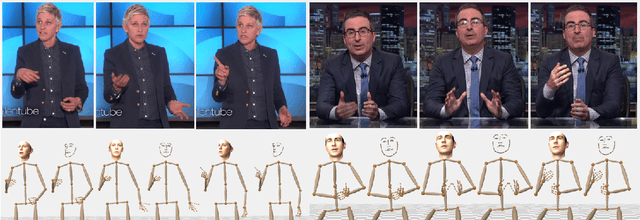
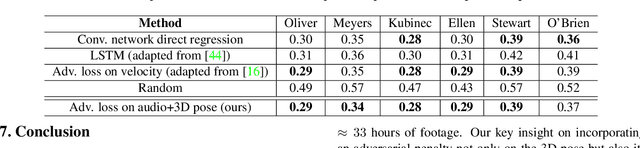
We propose the first approach to automatically and jointly synthesize both the synchronous 3D conversational body and hand gestures, as well as 3D face and head animations, of a virtual character from speech input. Our algorithm uses a CNN architecture that leverages the inherent correlation between facial expression and hand gestures. Synthesis of conversational body gestures is a multi-modal problem since many similar gestures can plausibly accompany the same input speech. To synthesize plausible body gestures in this setting, we train a Generative Adversarial Network (GAN) based model that measures the plausibility of the generated sequences of 3D body motion when paired with the input audio features. We also contribute a new way to create a large corpus of more than 33 hours of annotated body, hand, and face data from in-the-wild videos of talking people. To this end, we apply state-of-the-art monocular approaches for 3D body and hand pose estimation as well as dense 3D face performance capture to the video corpus. In this way, we can train on orders of magnitude more data than previous algorithms that resort to complex in-studio motion capture solutions, and thereby train more expressive synthesis algorithms. Our experiments and user study show the state-of-the-art quality of our speech-synthesized full 3D character animations.
AVQVC: One-shot Voice Conversion by Vector Quantization with applying contrastive learning
Feb 21, 2022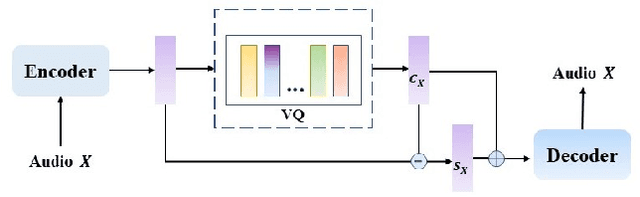

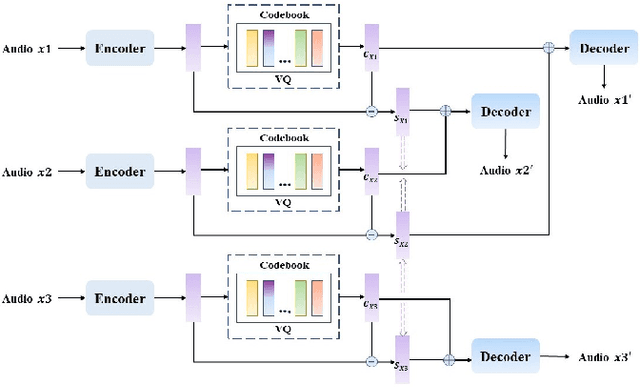
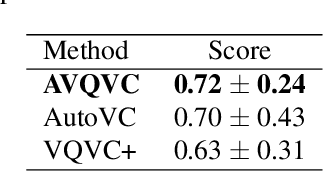
Voice Conversion(VC) refers to changing the timbre of a speech while retaining the discourse content. Recently, many works have focused on disentangle-based learning techniques to separate the timbre and the linguistic content information from a speech signal. Once successful, voice conversion will be feasible and straightforward. This paper proposed a novel one-shot voice conversion framework based on vector quantization voice conversion (VQVC) and AutoVC, called AVQVC. A new training method is applied to VQVC to separate content and timbre information from speech more effectively. The result shows that this approach has better performance than VQVC in separating content and timbre to improve the sound quality of generated speech.
Improved Processing of Ultrasound Tongue Videos by Combining ConvLSTM and 3D Convolutional Networks
Jun 26, 2022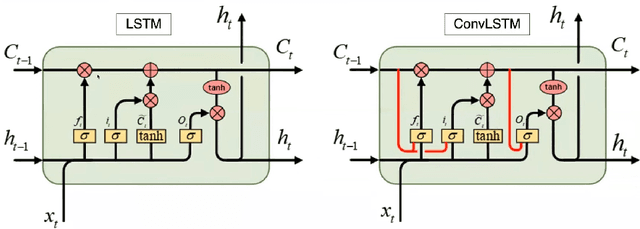
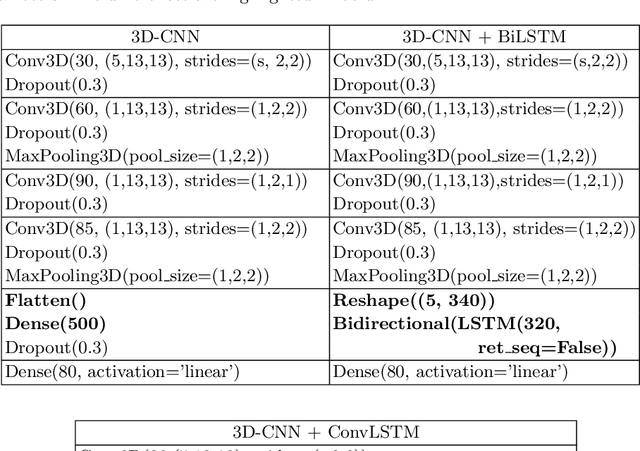
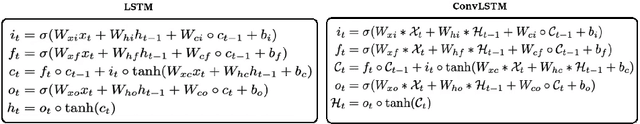
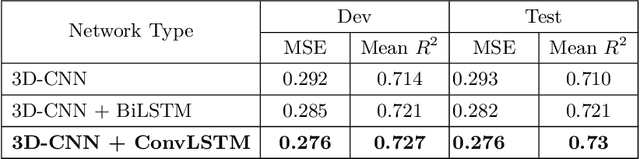
Silent Speech Interfaces aim to reconstruct the acoustic signal from a sequence of ultrasound tongue images that records the articulatory movement. The extraction of information about the tongue movement requires us to efficiently process the whole sequence of images, not just as a single image. Several approaches have been suggested to process such a sequential image data. The classic neural network structure combines two-dimensional convolutional (2D-CNN) layers that process the images separately with recurrent layers (eg. an LSTM) on top of them to fuse the information along time. More recently, it was shown that one may also apply a 3D-CNN network that can extract information along both the spatial and the temporal axes in parallel, achieving a similar accuracy while being less time consuming. A third option is to apply the less well-known ConvLSTM layer type, which combines the advantages of LSTM and CNN layers by replacing matrix multiplication with the convolution operation. In this paper, we experimentally compared various combinations of the above mentions layer types for a silent speech interface task, and we obtained the best result with a hybrid model that consists of a combination of 3D-CNN and ConvLSTM layers. This hybrid network is slightly faster, smaller and more accurate than our previous 3D-CNN model. %with combination of (2+1)D CNN.
Incremental Text-to-Speech Synthesis Using Pseudo Lookahead with Large Pretrained Language Model
Dec 23, 2020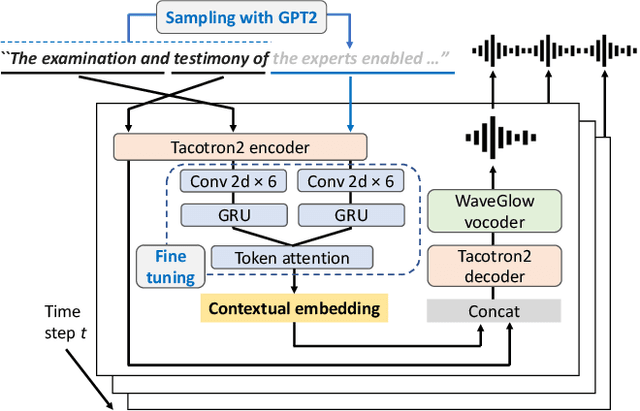
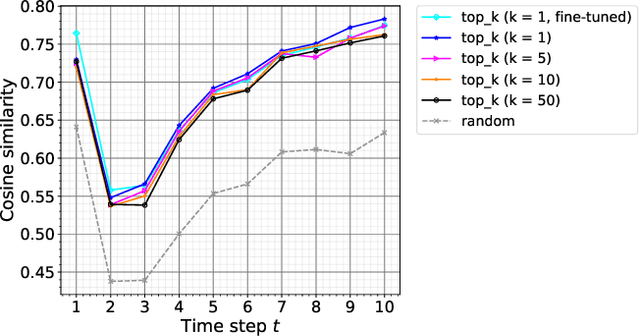
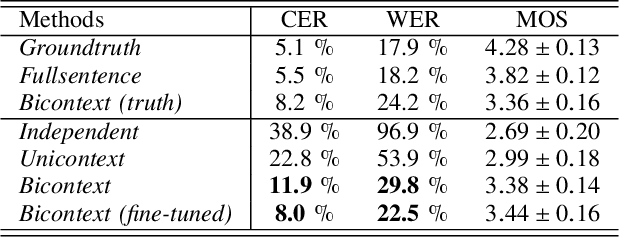
Text-to-speech (TTS) synthesis, a technique for artificially generating human-like utterances from texts, has dramatically evolved with the advances of end-to-end deep neural network-based methods in recent years. The majority of these methods are sentence-level TTS, which can take into account time-series information in the whole sentence. However, it is necessary to establish incremental TTS, which performs synthesis in smaller linguistic units, to realize low-latency synthesis usable for simultaneous speech-to-speech translation systems. In general, incremental TTS is subject to a trade-off between the latency and quality of output speech. It is challenging to produce high-quality speech with a low-latency setup that does not make much use of an unobserved future sentence (hereafter, "lookahead"). This study proposes an incremental TTS method that uses the pseudo lookahead generated with a language model to consider the future contextual information without increasing latency. Our method can be regarded as imitating a human's incremental reading and uses pretrained GPT2, which accounts for the large-scale linguistic knowledge, for the lookahead generation. Evaluation results show that our method 1) achieves higher speech quality without increasing the latency than the method using only observed information and 2) reduces the latency while achieving the equivalent speech quality to waiting for the future context observation.
Training end-to-end speech-to-text models on mobile phones
Dec 07, 2021
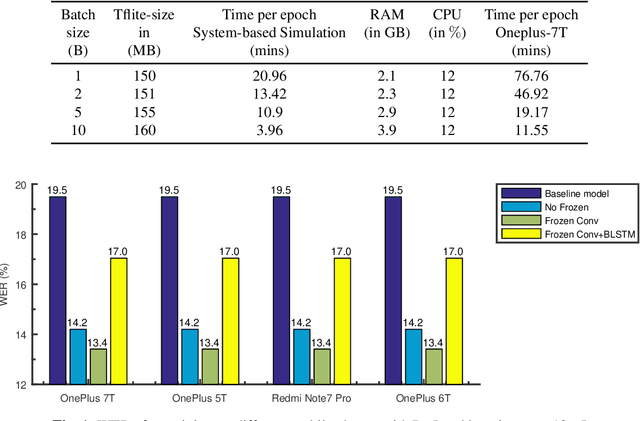
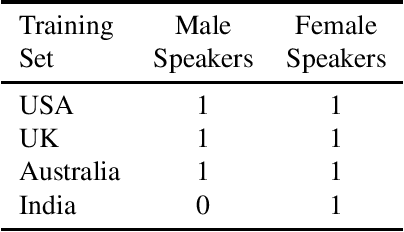
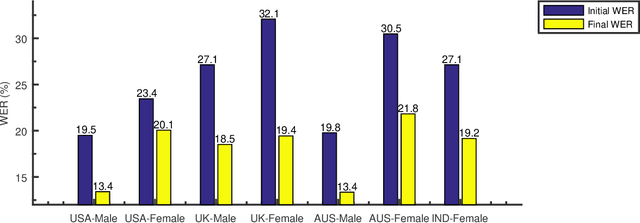
Training the state-of-the-art speech-to-text (STT) models in mobile devices is challenging due to its limited resources relative to a server environment. In addition, these models are trained on generic datasets that are not exhaustive in capturing user-specific characteristics. Recently, on-device personalization techniques have been making strides in mitigating the problem. Although many current works have already explored the effectiveness of on-device personalization, the majority of their findings are limited to simulation settings or a specific smartphone. In this paper, we develop and provide a detailed explanation of our framework to train end-to-end models in mobile phones. To make it simple, we considered a model based on connectionist temporal classification (CTC) loss. We evaluated the framework on various mobile phones from different brands and reported the results. We provide enough evidence that fine-tuning the models and choosing the right hyperparameter values is a trade-off between the lowest WER achievable, training time on-device, and memory consumption. Hence, this is vital for a successful deployment of on-device training onto a resource-limited environment like mobile phones. We use training sets from speakers with different accents and record a 7.6% decrease in average word error rate (WER). We also report the associated computational cost measurements with respect to time, memory usage, and cpu utilization in mobile phones in real-time.
Two Streams and Two Resolution Spectrograms Model for End-to-end Automatic Speech Recognition
Aug 18, 2021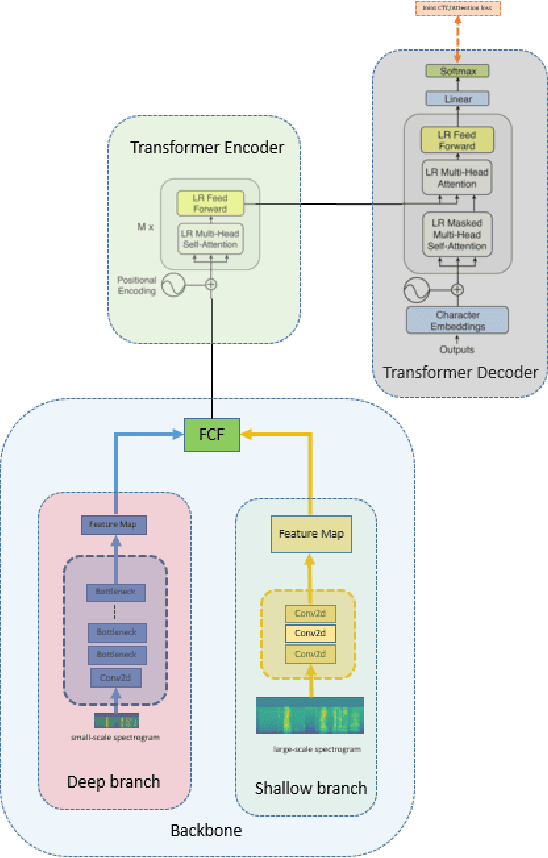
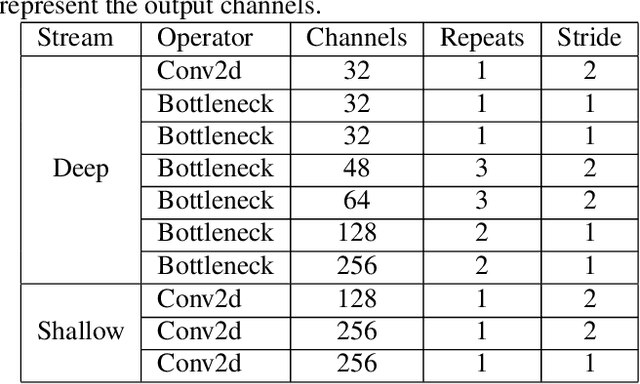

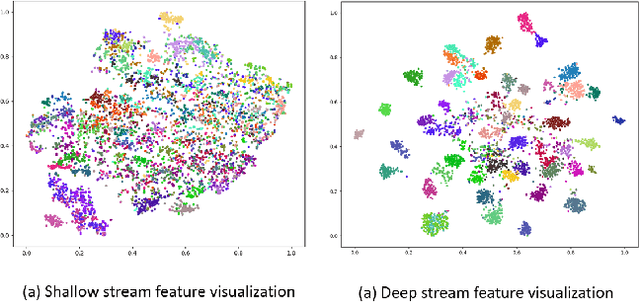
Transformer has shown tremendous progress in Automatic Speech Recognition (ASR), outperforming recurrent neural network-based approaches. Transformer architecture is good at parallelizing data to accelerate as well as capturing content-based global interaction. However, most studies with Transfomer have been utilized only shallow features extracted from the backbone without taking advantage of the deep feature that possesses invariant property. In this paper, we propose a novel framework with two streams that consist of different resolution spectrograms for each steam aiming to capture both shallow and deep features. The feature extraction module consists of a deep network for small resolution spectrogram and a shallow network for large resolution spectrogram. The backbone obtains not only detailed acoustic information for speech-text alignment but also sentence invariant features such as speaker information. Both features are fused with our proposed fusion method and then input into the Transformer encoder-decoder. With our method, the proposed framework shows competitive performance on Mandarin corpus. It outperforms various current state-of-the-art results on the HKUST Mandarian telephone ASR benchmark with a CER of 21.08. To the best of our knowledge, this is the first investigation of incorporating deep features to the backbone.
Public Wisdom Matters! Discourse-Aware Hyperbolic Fourier Co-Attention for Social-Text Classification
Sep 15, 2022
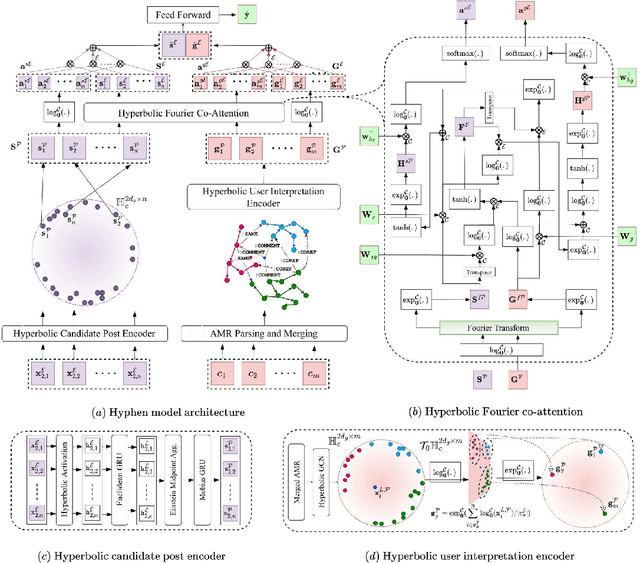
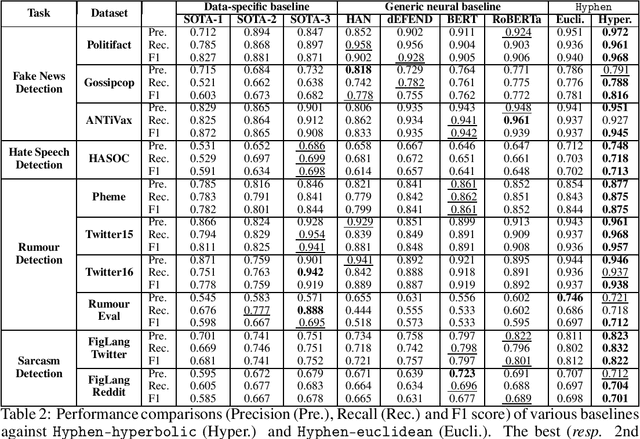
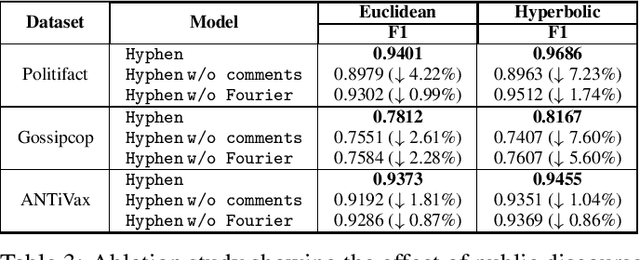
Social media has become the fulcrum of all forms of communication. Classifying social texts such as fake news, rumour, sarcasm, etc. has gained significant attention. The surface-level signals expressed by a social-text itself may not be adequate for such tasks; therefore, recent methods attempted to incorporate other intrinsic signals such as user behavior and the underlying graph structure. Oftentimes, the `public wisdom' expressed through the comments/replies to a social-text acts as a surrogate of crowd-sourced view and may provide us with complementary signals. State-of-the-art methods on social-text classification tend to ignore such a rich hierarchical signal. Here, we propose Hyphen, a discourse-aware hyperbolic spectral co-attention network. Hyphen is a fusion of hyperbolic graph representation learning with a novel Fourier co-attention mechanism in an attempt to generalise the social-text classification tasks by incorporating public discourse. We parse public discourse as an Abstract Meaning Representation (AMR) graph and use the powerful hyperbolic geometric representation to model graphs with hierarchical structure. Finally, we equip it with a novel Fourier co-attention mechanism to capture the correlation between the source post and public discourse. Extensive experiments on four different social-text classification tasks, namely detecting fake news, hate speech, rumour, and sarcasm, show that Hyphen generalises well, and achieves state-of-the-art results on ten benchmark datasets. We also employ a sentence-level fact-checked and annotated dataset to evaluate how Hyphen is capable of producing explanations as analogous evidence to the final prediction.
Unsupervised Speech Segmentation and Variable Rate Representation Learning using Segmental Contrastive Predictive Coding
Oct 08, 2021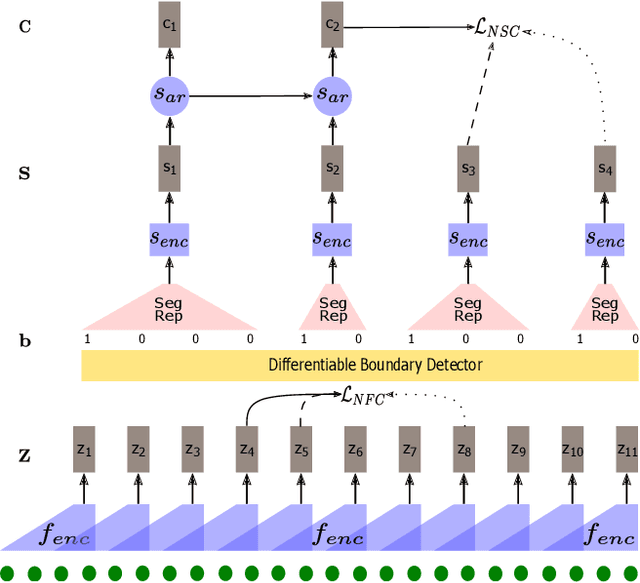
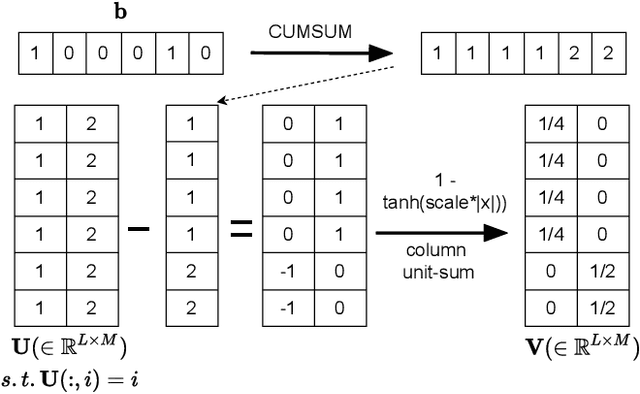
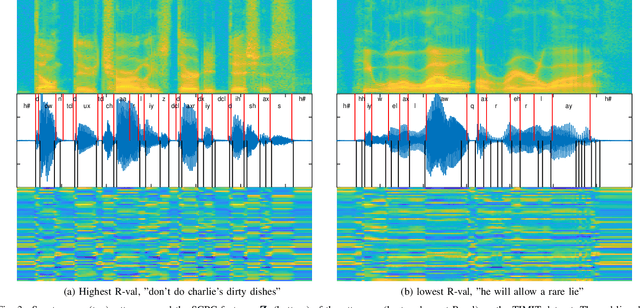
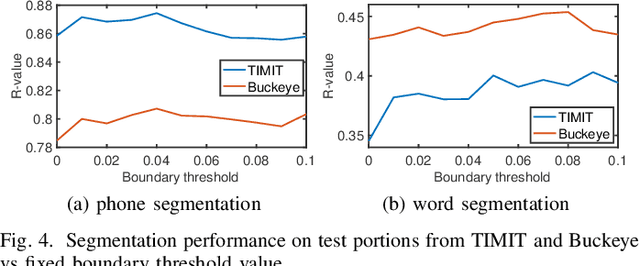
Typically, unsupervised segmentation of speech into the phone and word-like units are treated as separate tasks and are often done via different methods which do not fully leverage the inter-dependence of the two tasks. Here, we unify them and propose a technique that can jointly perform both, showing that these two tasks indeed benefit from each other. Recent attempts employ self-supervised learning, such as contrastive predictive coding (CPC), where the next frame is predicted given past context. However, CPC only looks at the audio signal's frame-level structure. We overcome this limitation with a segmental contrastive predictive coding (SCPC) framework to model the signal structure at a higher level, e.g., phone level. A convolutional neural network learns frame-level representation from the raw waveform via noise-contrastive estimation (NCE). A differentiable boundary detector finds variable-length segments, which are then used to optimize a segment encoder via NCE to learn segment representations. The differentiable boundary detector allows us to train frame-level and segment-level encoders jointly. Experiments show that our single model outperforms existing phone and word segmentation methods on TIMIT and Buckeye datasets. We discover that phone class impacts the boundary detection performance, and the boundaries between successive vowels or semivowels are the most difficult to identify. Finally, we use SCPC to extract speech features at the segment level rather than at uniformly spaced frame level (e.g., 10 ms) and produce variable rate representations that change according to the contents of the utterance. We can lower the feature extraction rate from the typical 100 Hz to as low as 14.5 Hz on average while still outperforming the MFCC features on the linear phone classification task.
KOLD: Korean Offensive Language Dataset
May 23, 2022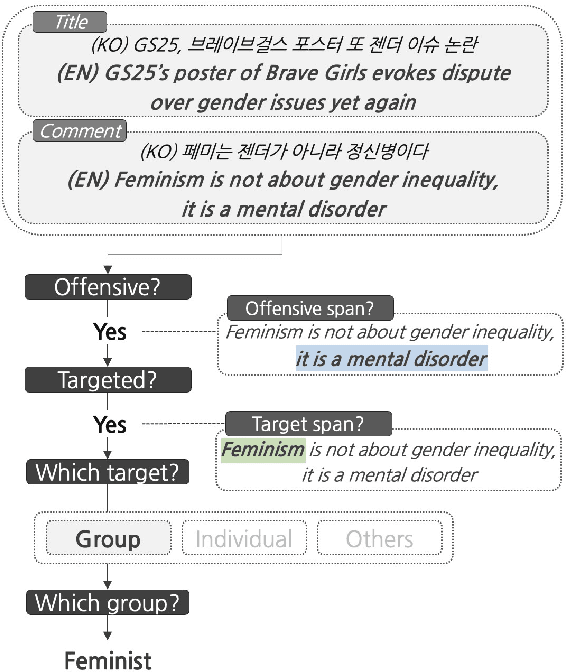
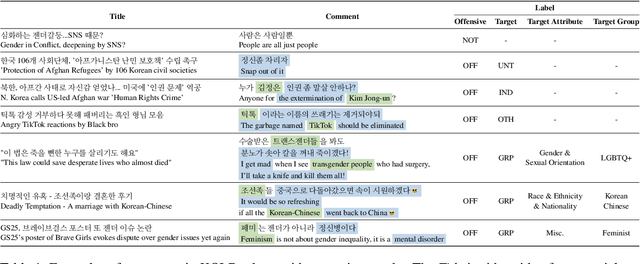
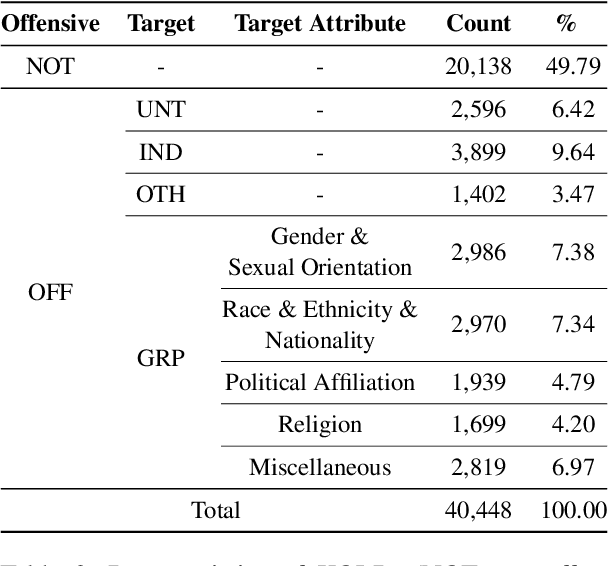
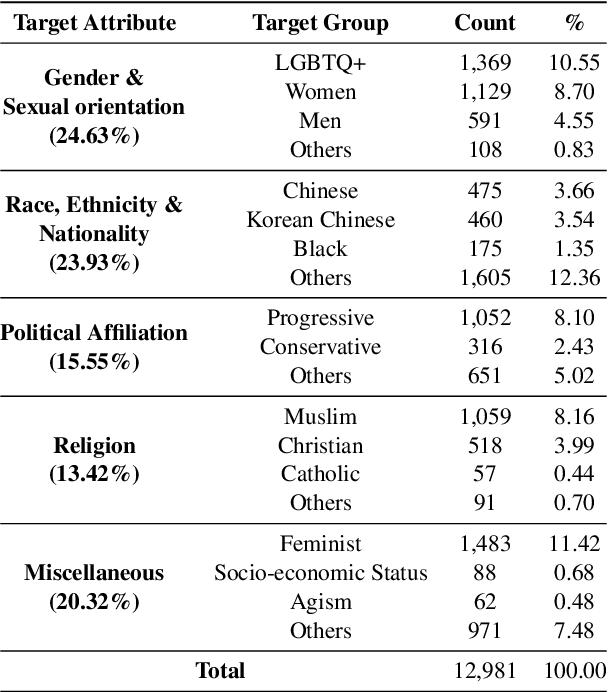
Although large attention has been paid to the detection of hate speech, most work has been done in English, failing to make it applicable to other languages. To fill this gap, we present a Korean offensive language dataset (KOLD), 40k comments labeled with offensiveness, target, and targeted group information. We also collect two types of span, offensive and target span that justifies the decision of the categorization within the text. Comparing the distribution of targeted groups with the existing English dataset, we point out the necessity of a hate speech dataset fitted to the language that best reflects the culture. Trained with our dataset, we report the baseline performance of the models built on top of large pretrained language models. We also show that title information serves as context and is helpful to discern the target of hatred, especially when they are omitted in the comment.
Consonant-Vowel Transition Models Based on Deep Learning for Objective Evaluation of Articulation
Mar 18, 2022
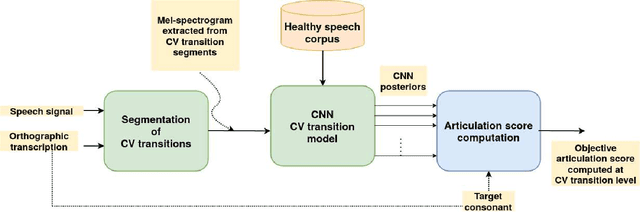
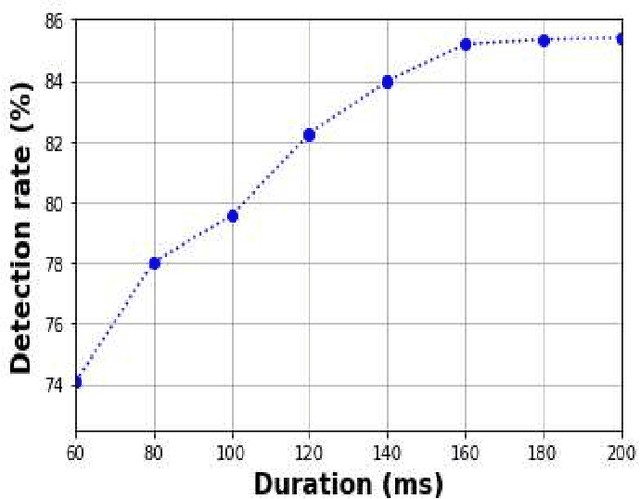
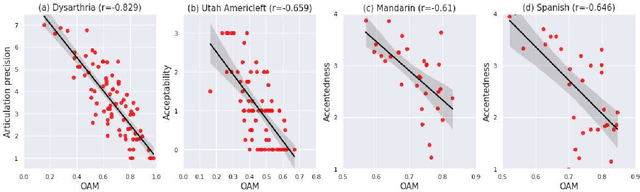
Spectro-temporal dynamics of consonant-vowel (CV) transition regions are considered to provide robust cues related to articulation. In this work, we propose an objective measure of precise articulation, dubbed the objective articulation measure (OAM), by analyzing the CV transitions segmented around vowel onsets. The OAM is derived based on the posteriors of a convolutional neural network pre-trained to classify between different consonants using CV regions as input. We demonstrate the OAM is correlated with perceptual measures in a variety of contexts including (a) adult dysarthric speech, (b) the speech of children with cleft lip/palate, and (c) a database of accented English speech from native Mandarin and Spanish speakers.