 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple and Efficient Architectures for Semantic Segmentation
Jun 16, 2022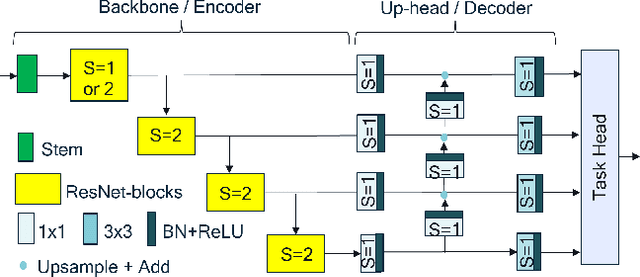
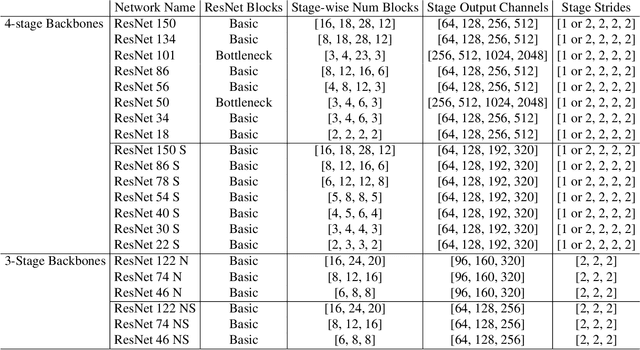
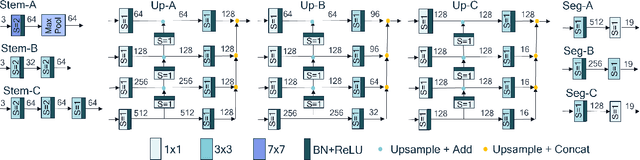
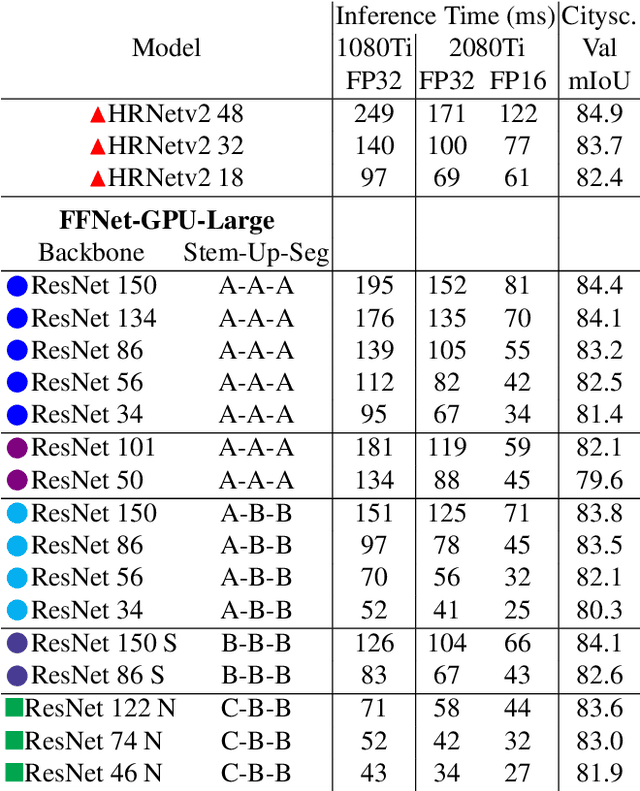
Though the state-of-the architectures for semantic segmentation, such as HRNet, demonstrate impressive accuracy, the complexity arising from their salient design choices hinders a range of model acceleration tools, and further they make use of operations that are inefficient on current hardware. This paper demonstrates that a simple encoder-decoder architecture with a ResNet-like backbone and a small multi-scale head, performs on-par or better than complex semantic segmentation architectures such as HRNet, FANet and DDRNets. Naively applying deep backbones designed for Image Classification to the task of Semantic Segmentation leads to sub-par results, owing to a much smaller effective receptive field of these backbones. Implicit among the various design choices put forth in works like HRNet, DDRNet, and FANet are networks with a large effective receptive field. It is natural to ask if a simple encoder-decoder architecture would compare favorably if comprised of backbones that have a larger effective receptive field, though without the use of inefficient operations like dilated convolutions. We show that with minor and inexpensive modifications to ResNets, enlarging the receptive field, very simple and competitive baselines can be created for Semantic Segmentation. We present a family of such simple architectures for desktop as well as mobile targets, which match or exceed the performance of complex models on the Cityscapes dataset. We hope that our work provides simple yet effective baselines for practitioners to develop efficient semantic segmentation models.
Learning Speech-driven 3D Conversational Gestures from Video
Feb 13, 2021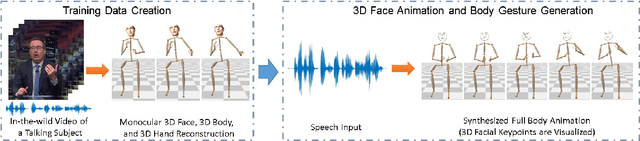
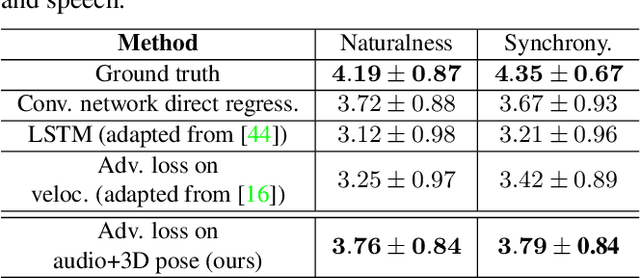
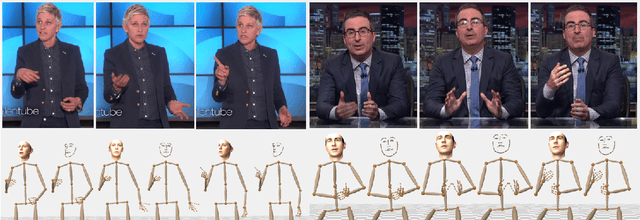
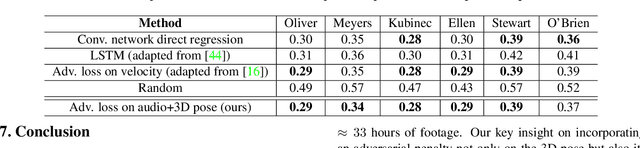
We propose the first approach to automatically and jointly synthesize both the synchronous 3D conversational body and hand gestures, as well as 3D face and head animations, of a virtual character from speech input. Our algorithm uses a CNN architecture that leverages the inherent correlation between facial expression and hand gestures. Synthesis of conversational body gestures is a multi-modal problem since many similar gestures can plausibly accompany the same input speech. To synthesize plausible body gestures in this setting, we train a Generative Adversarial Network (GAN) based model that measures the plausibility of the generated sequences of 3D body motion when paired with the input audio features. We also contribute a new way to create a large corpus of more than 33 hours of annotated body, hand, and face data from in-the-wild videos of talking people. To this end, we apply state-of-the-art monocular approaches for 3D body and hand pose estimation as well as dense 3D face performance capture to the video corpus. In this way, we can train on orders of magnitude more data than previous algorithms that resort to complex in-studio motion capture solutions, and thereby train more expressive synthesis algorithms. Our experiments and user study show the state-of-the-art quality of our speech-synthesized full 3D character animations.
Neural Re-Rendering of Humans from a Single Image
Jan 11, 2021
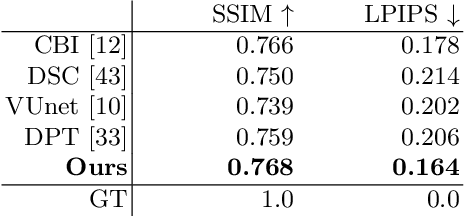
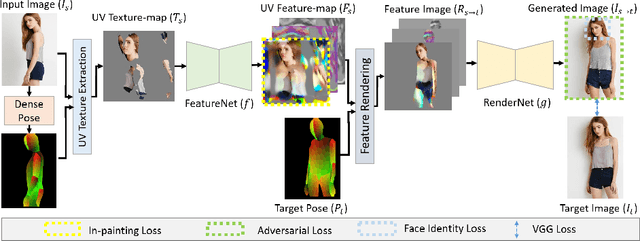

Human re-rendering from a single image is a starkly under-constrained problem, and state-of-the-art algorithms often exhibit undesired artefacts, such as over-smoothing, unrealistic distortions of the body parts and garments, or implausible changes of the texture. To address these challenges, we propose a new method for neural re-rendering of a human under a novel user-defined pose and viewpoint, given one input image. Our algorithm represents body pose and shape as a parametric mesh which can be reconstructed from a single image and easily reposed. Instead of a colour-based UV texture map, our approach further employs a learned high-dimensional UV feature map to encode appearance. This rich implicit representation captures detailed appearance variation across poses, viewpoints, person identities and clothing styles better than learned colour texture maps. The body model with the rendered feature maps is fed through a neural image-translation network that creates the final rendered colour image. The above components are combined in an end-to-end-trained neural network architecture that takes as input a source person image, and images of the parametric body model in the source pose and desired target pose. Experimental evaluation demonstrates that our approach produces higher quality single image re-rendering results than existing methods.
Distilling Optimal Neural Networks: Rapid Search in Diverse Spaces
Dec 16, 2020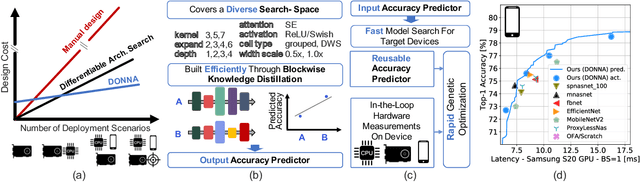



This work presents DONNA (Distilling Optimal Neural Network Architectures), a novel pipeline for rapid neural architecture search and search space exploration, targeting multiple different hardware platforms and user scenarios. In DONNA, a search consists of three phases. First, an accuracy predictor is built for a diverse search space using blockwise knowledge distillation. This predictor enables searching across diverse macro-architectural network parameters such as layer types, attention mechanisms, and channel widths, as well as across micro-architectural parameters such as block repeats, kernel sizes, and expansion rates. Second, a rapid evolutionary search phase finds a Pareto-optimal set of architectures in terms of accuracy and latency for any scenario using the predictor and on-device measurements. Third, Pareto-optimal models can be quickly finetuned to full accuracy. With this approach, DONNA finds architectures that outperform the state of the art. In ImageNet classification, architectures found by DONNA are 20% faster than EfficientNet-B0 and MobileNetV2 on a Nvidia V100 GPU at similar accuracy and 10% faster with 0.5% higher accuracy than MobileNetV2-1.4x on a Samsung S20 smartphone. In addition to neural architecture search, DONNA is used for search-space exploration and hardware-aware model compression.
XNect: Real-time Multi-person 3D Human Pose Estimation with a Single RGB Camera
Jul 01, 2019
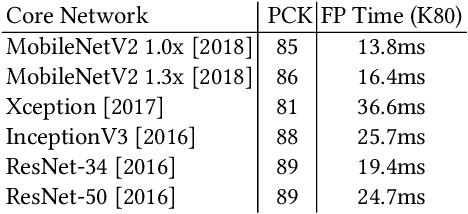
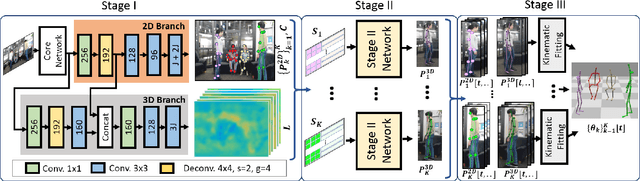
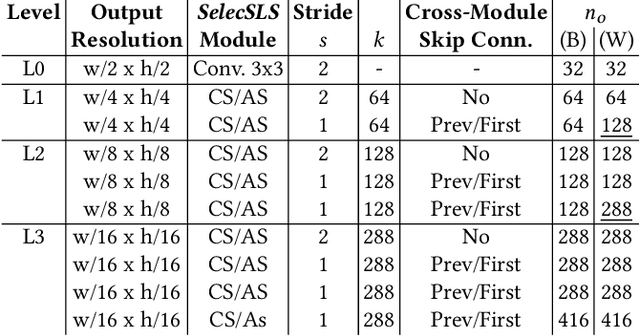
We present a real-time approach for multi-person 3D motion capture at over 30 fps using a single RGB camera. It operates in generic scenes and is robust to difficult occlusions both by other people and objects. Our method operates in subsequent stages. The first stage is a convolutional neural network (CNN) that estimates 2D and 3D pose features along with identity assignments for all visible joints of all individuals. We contribute a new architecture for this CNN, called SelecSLS Net, that uses novel selective long and short range skip connections to improve the information flow allowing for a drastically faster network without compromising accuracy. In the second stage, a fully-connected neural network turns the possibly partial (on account of occlusion) 2D pose and 3D pose features for each subject into a complete 3D pose estimate per individual. The third stage applies space-time skeletal model fitting to the predicted 2D and 3D pose per subject to further reconcile the 2D and 3D pose, and enforce temporal coherence. Our method returns the full skeletal pose in joint angles for each subject. This is a further key distinction from previous work that neither extracted global body positions nor joint angle results of a coherent skeleton in real time for multi-person scenes. The proposed system runs on consumer hardware at a previously unseen speed of more than 30 fps given 512x320 images as input while achieving state-of-the-art accuracy, which we will demonstrate on a range of challenging real-world scenes.
Implicit Filter Sparsification In Convolutional Neural Networks
May 13, 2019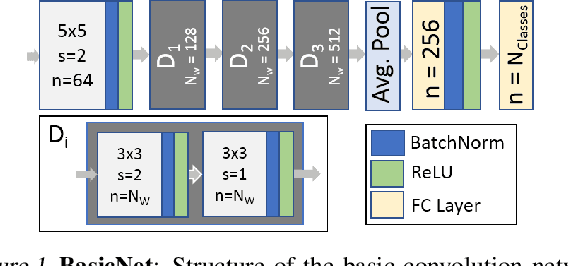
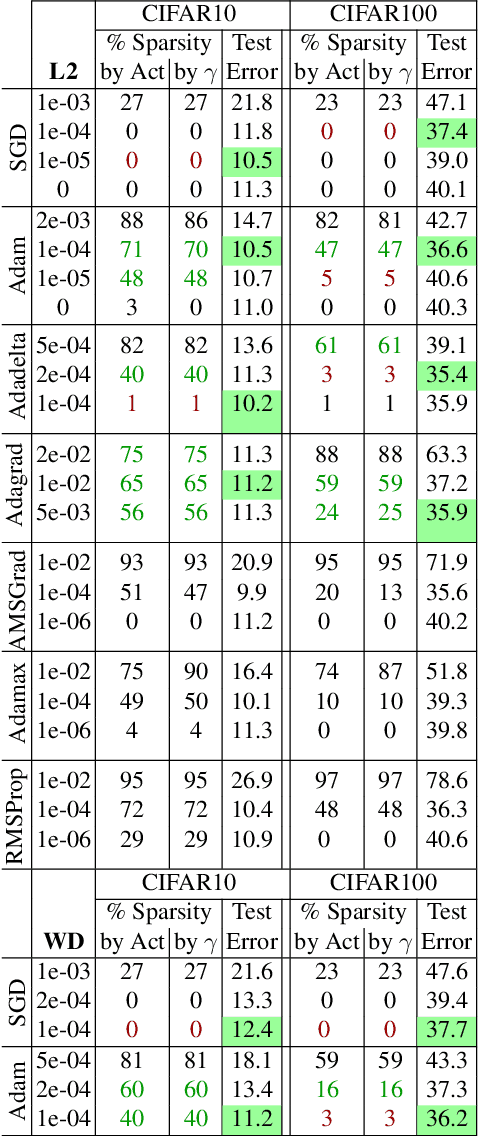
We show implicit filter level sparsity manifests in convolutional neural networks (CNNs) which employ Batch Normalization and ReLU activation, and are trained with adaptive gradient descent techniques and L2 regularization or weight decay. Through an extensive empirical study (Mehta et al., 2019) we hypothesize the mechanism behind the sparsification process, and find surprising links to certain filter sparsification heuristics proposed in literature. Emergence of, and the subsequent pruning of selective features is observed to be one of the contributing mechanisms, leading to feature sparsity at par or better than certain explicit sparsification / pruning approaches. In this workshop article we summarize our findings, and point out corollaries of selective-featurepenalization which could also be employed as heuristics for filter pruning
In the Wild Human Pose Estimation Using Explicit 2D Features and Intermediate 3D Representations
Apr 05, 2019
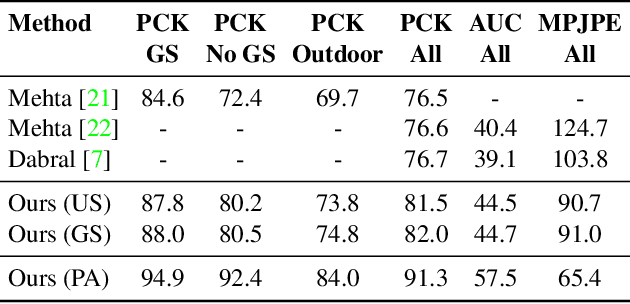
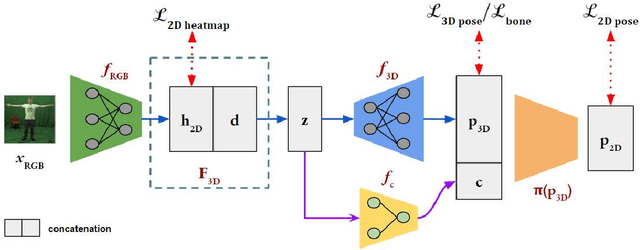
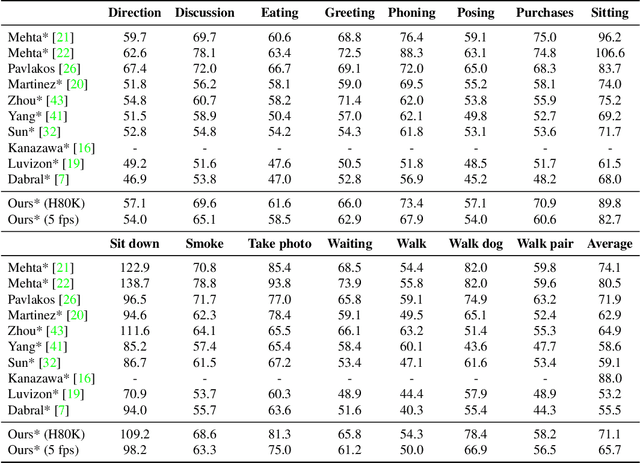
Convolutional Neural Network based approaches for monocular 3D human pose estimation usually require a large amount of training images with 3D pose annotations. While it is feasible to provide 2D joint annotations for large corpora of in-the-wild images with humans, providing accurate 3D annotations to such in-the-wild corpora is hardly feasible in practice. Most existing 3D labelled data sets are either synthetically created or feature in-studio images. 3D pose estimation algorithms trained on such data often have limited ability to generalize to real world scene diversity. We therefore propose a new deep learning based method for monocular 3D human pose estimation that shows high accuracy and generalizes better to in-the-wild scenes. It has a network architecture that comprises a new disentangled hidden space encoding of explicit 2D and 3D features, and uses supervision by a new learned projection model from predicted 3D pose. Our algorithm can be jointly trained on image data with 3D labels and image data with only 2D labels. It achieves state-of-the-art accuracy on challenging in-the-wild data.
On Implicit Filter Level Sparsity in Convolutional Neural Networks
Nov 29, 2018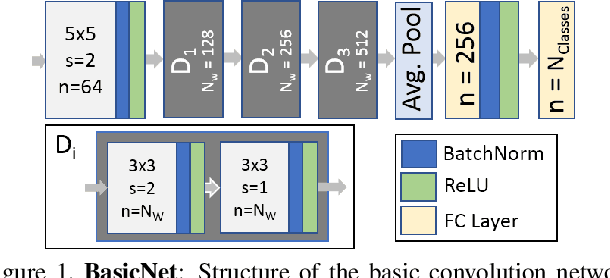
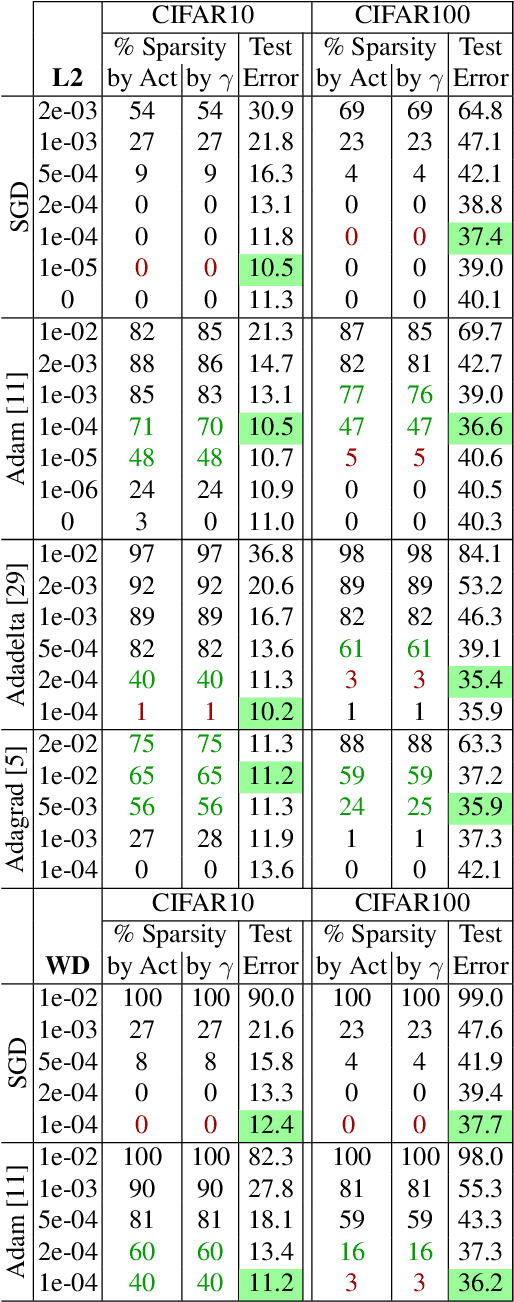
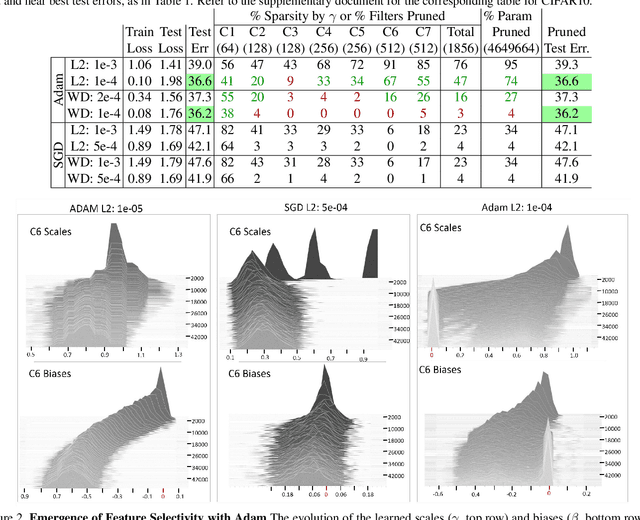
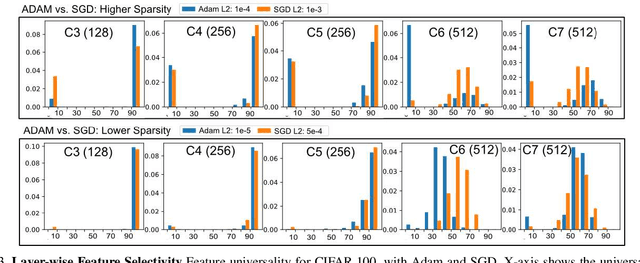
We investigate filter level sparsity that emerges in convolutional neural networks (CNNs) which employ Batch Normalization and ReLU activation, and are trained with adaptive gradient descent techniques and L2 regularization (or weight decay). We conduct an extensive experimental study casting these initial findings into hypotheses and conclusions about the mechanisms underlying the emergent filter level sparsity. This study allows new insight into the performance gap obeserved between adapative and non-adaptive gradient descent methods in practice. Further, analysis of the effect of training strategies and hyperparameters on the sparsity leads to practical suggestions in designing CNN training strategies enabling us to explore the tradeoffs between feature selectivity, network capacity, and generalization performance. Lastly, we show that the implicit sparsity can be harnessed for neural network speedup at par or better than explicit sparsification / pruning approaches, without needing any modifications to the typical training pipeline.
Single-Shot Multi-Person 3D Pose Estimation From Monocular RGB
Aug 28, 2018
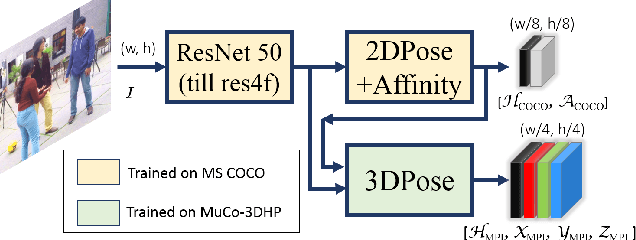

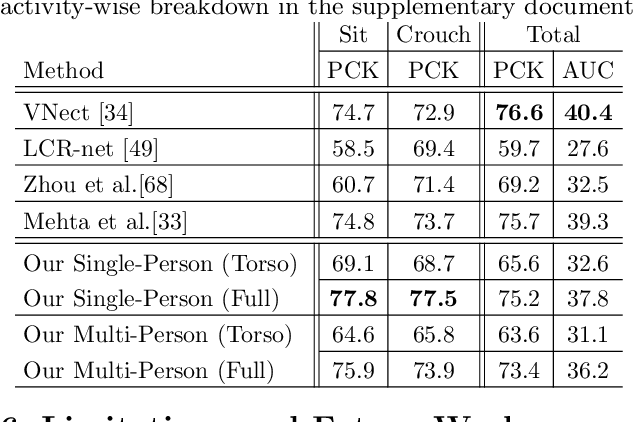
We propose a new single-shot method for multi-person 3D pose estimation in general scenes from a monocular RGB camera. Our approach uses novel occlusion-robust pose-maps (ORPM) which enable full body pose inference even under strong partial occlusions by other people and objects in the scene. ORPM outputs a fixed number of maps which encode the 3D joint locations of all people in the scene. Body part associations allow us to infer 3D pose for an arbitrary number of people without explicit bounding box prediction. To train our approach we introduce MuCo-3DHP, the first large scale training data set showing real images of sophisticated multi-person interactions and occlusions. We synthesize a large corpus of multi-person images by compositing images of individual people (with ground truth from mutli-view performance capture). We evaluate our method on our new challenging 3D annotated multi-person test set MuPoTs-3D where we achieve state-of-the-art performance. To further stimulate research in multi-person 3D pose estimation, we will make our new datasets, and associated code publicly available for research purposes.
MonoPerfCap: Human Performance Capture from Monocular Video
Feb 23, 2018

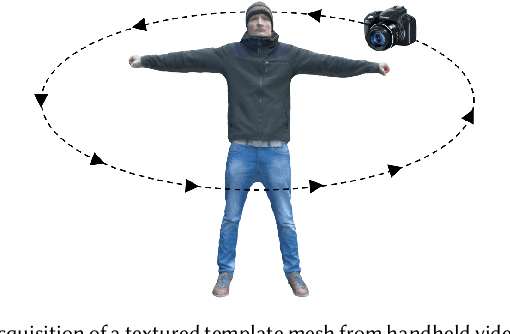
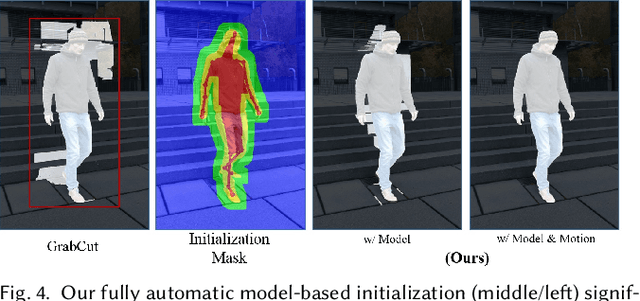
We present the first marker-less approach for temporally coherent 3D performance capture of a human with general clothing from monocular video. Our approach reconstructs articulated human skeleton motion as well as medium-scale non-rigid surface deformations in general scenes. Human performance capture is a challenging problem due to the large range of articulation, potentially fast motion, and considerable non-rigid deformations, even from multi-view data. Reconstruction from monocular video alone is drastically more challenging, since strong occlusions and the inherent depth ambiguity lead to a highly ill-posed reconstruction problem. We tackle these challenges by a novel approach that employs sparse 2D and 3D human pose detections from a convolutional neural network using a batch-based pose estimation strategy. Joint recovery of per-batch motion allows to resolve the ambiguities of the monocular reconstruction problem based on a low dimensional trajectory subspace. In addition, we propose refinement of the surface geometry based on fully automatically extracted silhouettes to enable medium-scale non-rigid alignment. We demonstrate state-of-the-art performance capture results that enable exciting applications such as video editing and free viewpoint video, previously infeasible from monocular video. Our qualitative and quantitative evaluation demonstrates that our approach significantly outperforms previous monocular methods in terms of accuracy, robustness and scene complexity that can be handled.