 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
LDNet: Unified Listener Dependent Modeling in MOS Prediction for Synthetic Speech
Oct 18, 2021

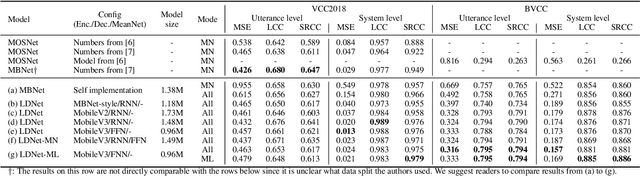
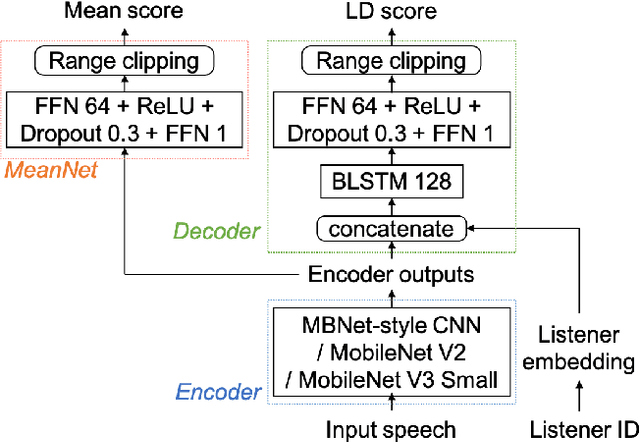
An effective approach to automatically predict the subjective rating for synthetic speech is to train on a listening test dataset with human-annotated scores. Although each speech sample in the dataset is rated by several listeners, most previous works only used the mean score as the training target. In this work, we present LDNet, a unified framework for mean opinion score (MOS) prediction that predicts the listener-wise perceived quality given the input speech and the listener identity. We reflect recent advances in LD modeling, including design choices of the model architecture, and propose two inference methods that provide more stable results and efficient computation. We conduct systematic experiments on the voice conversion challenge (VCC) 2018 benchmark and a newly collected large-scale MOS dataset, providing an in-depth analysis of the proposed framework. Results show that the mean listener inference method is a better way to utilize the mean scores, whose effectiveness is more obvious when having more ratings per sample.
Prediction of Listener Perception of Argumentative Speech in a Crowdsourced Data Using (Psycho-)Linguistic and Fluency Features
Nov 13, 2021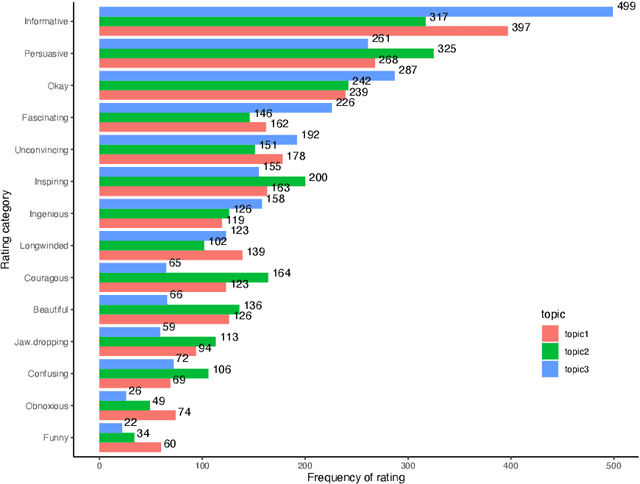
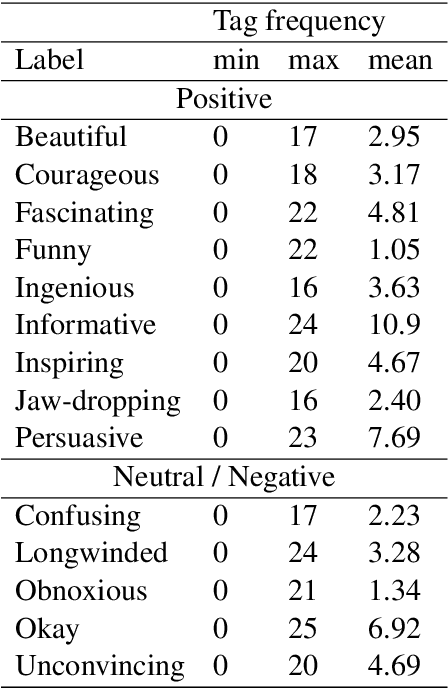
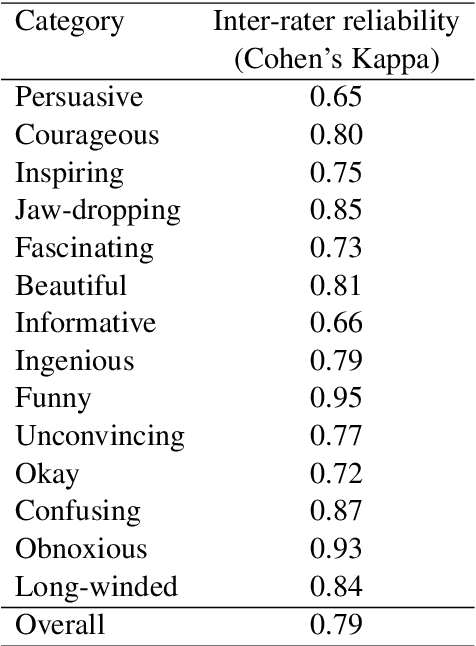

One of the key communicative competencies is the ability to maintain fluency in monologic speech and the ability to produce sophisticated language to argue a position convincingly. In this paper we aim to predict TED talk-style affective ratings in a crowdsourced dataset of argumentative speech consisting of 7 hours of speech from 110 individuals. The speech samples were elicited through task prompts relating to three debating topics. The samples received a total of 2211 ratings from 737 human raters pertaining to 14 affective categories. We present an effective approach to the classification task of predicting these categories through fine-tuning a model pre-trained on a large dataset of TED talks public speeches. We use a combination of fluency features derived from a state-of-the-art automatic speech recognition system and a large set of human-interpretable linguistic features obtained from an automatic text analysis system. Classification accuracy was greater than 60% for all 14 rating categories, with a peak performance of 72% for the rating category 'informative'. In a secondary experiment, we determined the relative importance of features from different groups using SP-LIME.
An Attribute-Aligned Strategy for Learning Speech Representation
Jun 05, 2021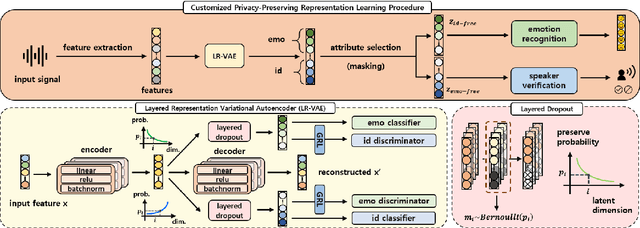
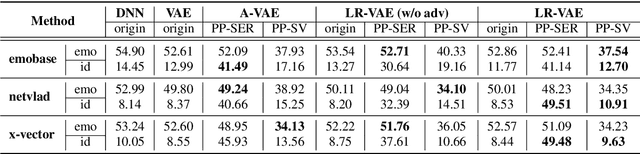
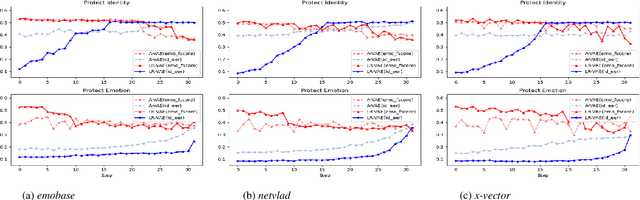
Advancement in speech technology has brought convenience to our life. However, the concern is on the rise as speech signal contains multiple personal attributes, which would lead to either sensitive information leakage or bias toward decision. In this work, we propose an attribute-aligned learning strategy to derive speech representation that can flexibly address these issues by attribute-selection mechanism. Specifically, we propose a layered-representation variational autoencoder (LR-VAE), which factorizes speech representation into attribute-sensitive nodes, to derive an identity-free representation for speech emotion recognition (SER), and an emotionless representation for speaker verification (SV). Our proposed method achieves competitive performances on identity-free SER and a better performance on emotionless SV, comparing to the current state-of-the-art method of using adversarial learning applied on a large emotion corpora, the MSP-Podcast. Also, our proposed learning strategy reduces the model and training process needed to achieve multiple privacy-preserving tasks.
Prosody-TTS: An end-to-end speech synthesis system with prosody control
Oct 06, 2021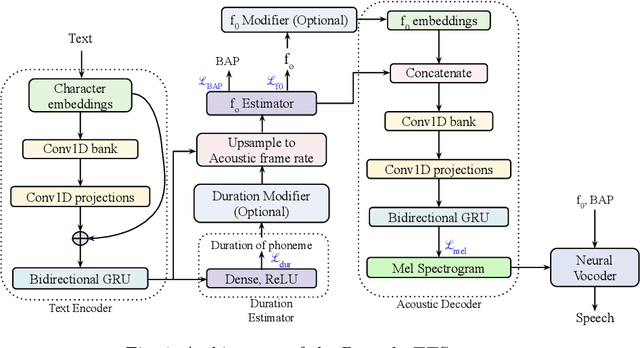
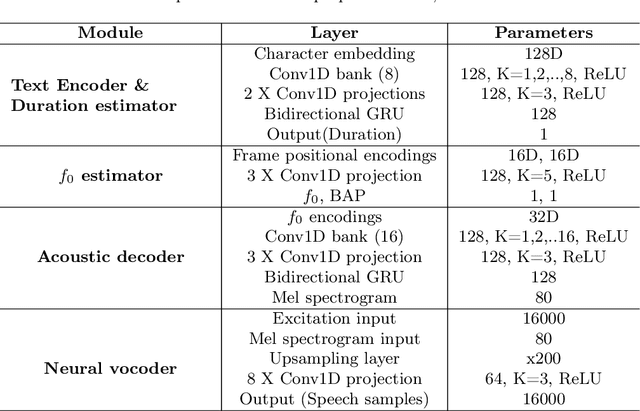
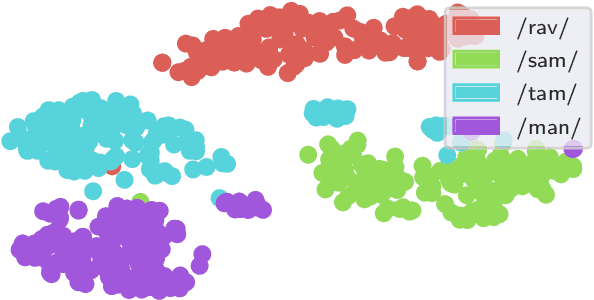
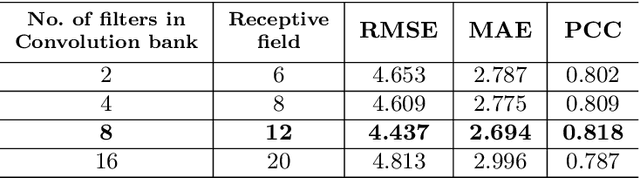
End-to-end text-to-speech synthesis systems achieved immense success in recent times, with improved naturalness and intelligibility. However, the end-to-end models, which primarily depend on the attention-based alignment, do not offer an explicit provision to modify/incorporate the desired prosody while synthesizing the signal. Moreover, the state-of-the-art end-to-end systems use autoregressive models for synthesis, making the prediction sequential. Hence, the inference time and the computational complexity are quite high. This paper proposes Prosody-TTS, an end-to-end speech synthesis model that combines the advantages of statistical parametric models and end-to-end neural network models. It also has a provision to modify or incorporate the desired prosody by controlling the fundamental frequency (f0) and the phone duration. Generating speech samples with appropriate prosody and rhythm helps in improving the naturalness of the synthesized speech. We explicitly model the duration of the phoneme and the f0 to have control over them during the synthesis. The model is trained in an end-to-end fashion to directly generate the speech waveform from the input text, which in turn depends on the auxiliary subtasks of predicting the phoneme duration, f0, and mel spectrogram. Experiments on the Telugu language data of the IndicTTS database show that the proposed Prosody-TTS model achieves state-of-the-art performance with a mean opinion score of 4.08, with a very low inference time.
ParaTTS: Learning Linguistic and Prosodic Cross-sentence Information in Paragraph-based TTS
Sep 14, 2022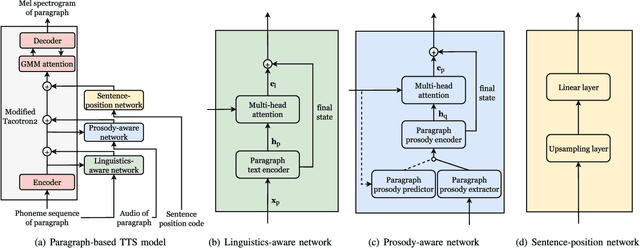


Recent advancements in neural end-to-end TTS models have shown high-quality, natural synthesized speech in a conventional sentence-based TTS. However, it is still challenging to reproduce similar high quality when a whole paragraph is considered in TTS, where a large amount of contextual information needs to be considered in building a paragraph-based TTS model. To alleviate the difficulty in training, we propose to model linguistic and prosodic information by considering cross-sentence, embedded structure in training. Three sub-modules, including linguistics-aware, prosody-aware and sentence-position networks, are trained together with a modified Tacotron2. Specifically, to learn the information embedded in a paragraph and the relations among the corresponding component sentences, we utilize linguistics-aware and prosody-aware networks. The information in a paragraph is captured by encoders and the inter-sentence information in a paragraph is learned with multi-head attention mechanisms. The relative sentence position in a paragraph is explicitly exploited by a sentence-position network. Trained on a storytelling audio-book corpus (4.08 hours), recorded by a female Mandarin Chinese speaker, the proposed TTS model demonstrates that it can produce rather natural and good-quality speech paragraph-wise. The cross-sentence contextual information, such as break and prosodic variations between consecutive sentences, can be better predicted and rendered than the sentence-based model. Tested on paragraph texts, of which the lengths are similar to, longer than, or much longer than the typical paragraph length of the training data, the TTS speech produced by the new model is consistently preferred over the sentence-based model in subjective tests and confirmed in objective measures.
Deciphering Speech: a Zero-Resource Approach to Cross-Lingual Transfer in ASR
Nov 22, 2021



We present a method for cross-lingual training an ASR system using absolutely no transcribed training data from the target language, and with no phonetic knowledge of the language in question. Our approach uses a novel application of a decipherment algorithm, which operates given only unpaired speech and text data from the target language. We apply this decipherment to phone sequences generated by a universal phone recogniser trained on out-of-language speech corpora, which we follow with flat-start semi-supervised training to obtain an acoustic model for the new language. To the best of our knowledge, this is the first practical approach to zero-resource cross-lingual ASR which does not rely on any hand-crafted phonetic information. We carry out experiments on read speech from the GlobalPhone corpus, and show that it is possible to learn a decipherment model on just 20 minutes of data from the target language. When used to generate pseudo-labels for semi-supervised training, we obtain WERs that range from 25% to just 5% absolute worse than the equivalent fully supervised models trained on the same data.
VSEGAN: Visual Speech Enhancement Generative Adversarial Network
Feb 04, 2021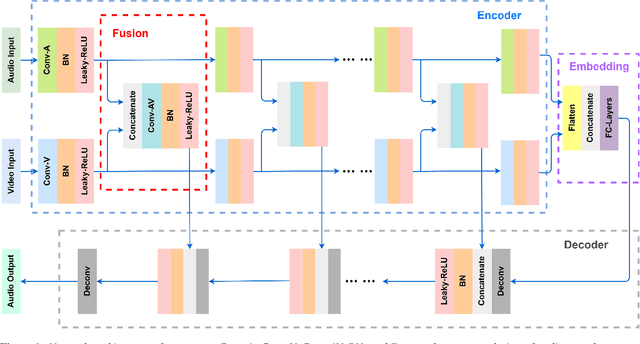

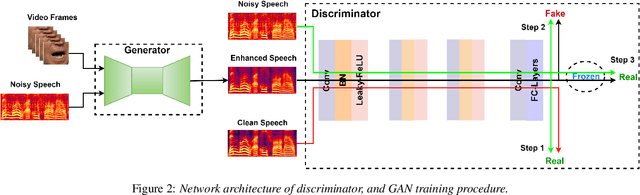
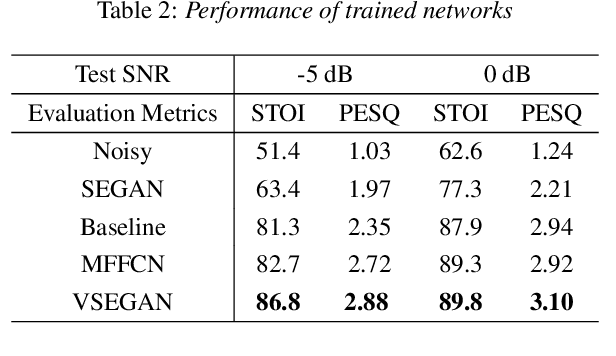
Speech enhancement is an essential task of improving speech quality in noise scenario. Several state-of-the-art approaches have introduced visual information for speech enhancement,since the visual aspect of speech is essentially unaffected by acoustic environment. This paper proposes a novel frameworkthat involves visual information for speech enhancement, by in-corporating a Generative Adversarial Network (GAN). In par-ticular, the proposed visual speech enhancement GAN consistof two networks trained in adversarial manner, i) a generator that adopts multi-layer feature fusion convolution network to enhance input noisy speech, and ii) a discriminator that attemptsto minimize the discrepancy between the distributions of the clean speech signal and enhanced speech signal. Experiment re-sults demonstrated superior performance of the proposed modelagainst several state-of-the-art
Time-Domain Mapping Based Single-Channel Speech Separation With Hierarchical Constraint Training
Oct 20, 2021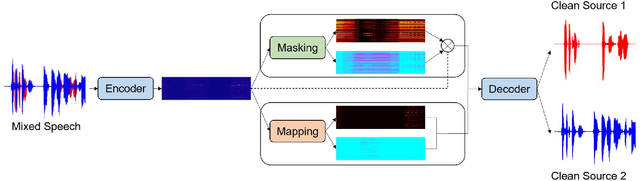
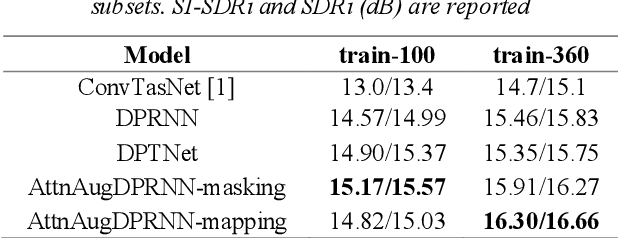

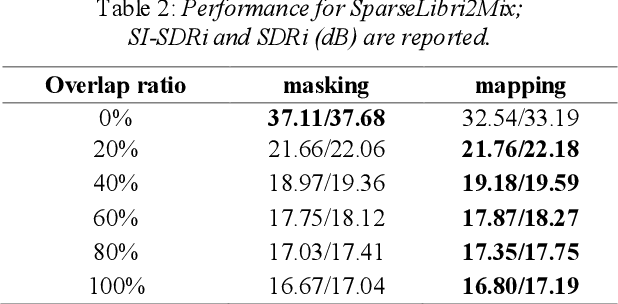
Single-channel speech separation is required for multi-speaker speech recognition. Recent deep learning-based approaches focused on time-domain audio separation net (TasNet) because it has superior performance and lower latency compared to the conventional time-frequency-based (T-F-based) approaches. Most of these works rely on the masking-based method that estimates a linear mapping function (mask) for each speaker. However, the other commonly used method, the mapping-based method that is less sensitive to SNR variations, is inadequately studied in the time domain. We explore the potential of the mapping-based method by introducing attention augmented DPRNN (AttnAugDPRNN) which directly approximates the clean sources from the mixture for speech separation. Permutation Invariant Training (PIT) has been a paradigm to solve the label ambiguity problem for speech separation but usually leads to suboptimal performance. To solve this problem, we propose an efficient training strategy called Hierarchical Constraint Training (HCT) to regularize the training, which could effectively improve the model performance. When using PIT, our results showed that mapping-based AttnAugDPRNN outperformed masking-based AttnAugDPRNN when the training corpus is large. Mapping-based AttnAugDPRNN with HCT significantly improved the SI-SDR by 10.1% compared to the masking-based AttnAugDPRNN without HCT.
Toroidal Probabilistic Spherical Discriminant Analysis
Oct 27, 2022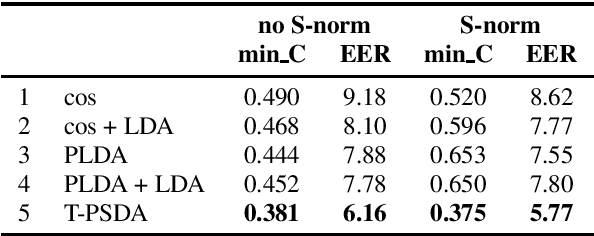
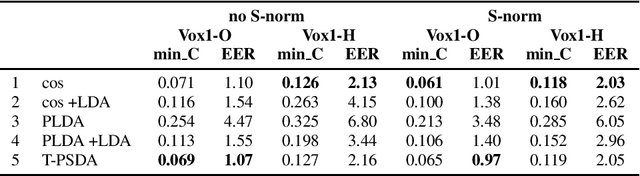
In speaker recognition, where speech segments are mapped to embeddings on the unit hypersphere, two scoring back-ends are commonly used, namely cosine scoring and PLDA. We have recently proposed PSDA, an analog to PLDA that uses Von Mises-Fisher distributions instead of Gaussians. In this paper, we present toroidal PSDA (T-PSDA). It extends PSDA with the ability to model within and between-speaker variabilities in toroidal submanifolds of the hypersphere. Like PLDA and PSDA, the model allows closed-form scoring and closed-form EM updates for training. On VoxCeleb, we find T-PSDA accuracy on par with cosine scoring, while PLDA accuracy is inferior. On NIST SRE'21 we find that T-PSDA gives large accuracy gains compared to both cosine scoring and PLDA.
A Streamwise GAN Vocoder for Wideband Speech Coding at Very Low Bit Rate
Aug 09, 2021
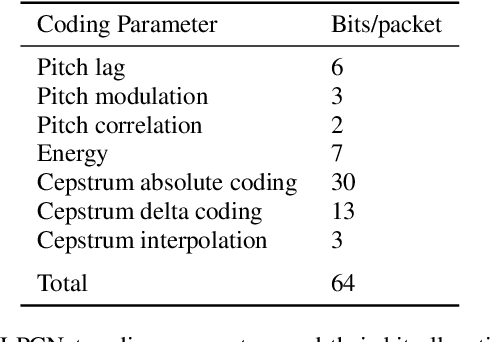
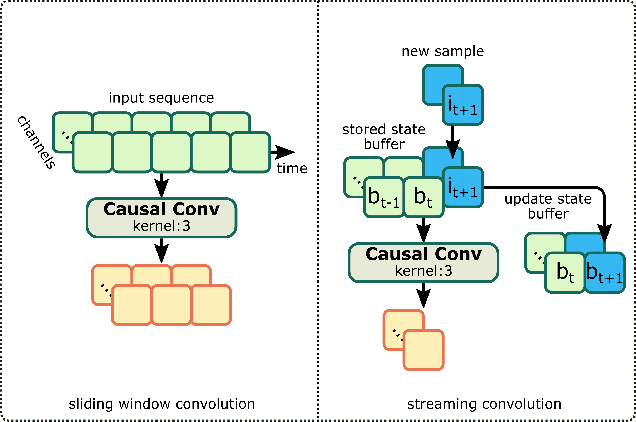
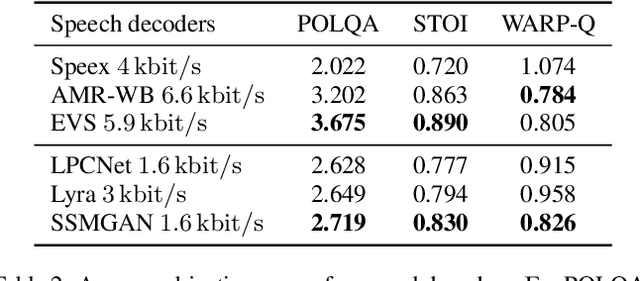
Recently, GAN vocoders have seen rapid progress in speech synthesis, starting to outperform autoregressive models in perceptual quality with much higher generation speed. However, autoregressive vocoders are still the common choice for neural generation of speech signals coded at very low bit rates. In this paper, we present a GAN vocoder which is able to generate wideband speech waveforms from parameters coded at 1.6 kbit/s. The proposed model is a modified version of the StyleMelGAN vocoder that can run in frame-by-frame manner, making it suitable for streaming applications. The experimental results show that the proposed model significantly outperforms prior autoregressive vocoders like LPCNet for very low bit rate speech coding, with computational complexity of about 5 GMACs, providing a new state of the art in this domain. Moreover, this streamwise adversarial vocoder delivers quality competitive to advanced speech codecs such as EVS at 5.9 kbit/s on clean speech, which motivates further usage of feed-forward fully-convolutional models for low bit rate speech coding.