 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUBGAN: Enhancing Coded Speech with Blind and Guided Bandwidth Extension
May 22, 2025



In practical application of speech codecs, a multitude of factors such as the quality of the radio connection, limiting hardware or required user experience necessitate trade-offs between achievable perceptual quality, engendered bitrate and computational complexity. Most conventional and neural speech codecs operate on wideband (WB) speech signals to achieve this compromise. To further enhance the perceptual quality of coded speech, bandwidth extension (BWE) of the transmitted speech is an attractive and popular technique in conventional speech coding. In contrast, neural speech codecs are typically trained end-to-end to a specific set of requirements and are often not easily adaptable. In particular, they are typically trained to operate at a single fixed sampling rate. With the Universal Bandwidth Extension Generative Adversarial Network (UBGAN), we propose a modular and lightweight GAN-based solution that increases the operational flexibility of a wide range of conventional and neural codecs. Our model operates in the subband domain and extends the bandwidth of WB signals from 8 kHz to 16 kHz, resulting in super-wideband (SWB) signals. We further introduce two variants, guided-UBGAN and blind-UBGAN, where the guided version transmits quantized learned representation as a side information at a very low bitrate additional to the bitrate of the codec, while blind-BWE operates without such side-information. Our subjective assessments demonstrate the advantage of UBGAN applied to WB codecs and highlight the generalization capacity of our proposed method across multiple codecs and bitrates.
Low-Resource Text-to-Speech Synthesis Using Noise-Augmented Training of ForwardTacotron
Jan 10, 2025



In recent years, several text-to-speech systems have been proposed to synthesize natural speech in zero-shot, few-shot, and low-resource scenarios. However, these methods typically require training with data from many different speakers. The speech quality across the speaker set typically is diverse and imposes an upper limit on the quality achievable for the low-resource speaker. In the current work, we achieve high-quality speech synthesis using as little as five minutes of speech from the desired speaker by augmenting the low-resource speaker data with noise and employing multiple sampling techniques during training. Our method requires only four high-quality, high-resource speakers, which are easy to obtain and use in practice. Our low-complexity method achieves improved speaker similarity compared to the state-of-the-art zero-shot method HierSpeech++ and the recent low-resource method AdapterMix while maintaining comparable naturalness. Our proposed approach can also reduce the data requirements for speech synthesis for new speakers and languages.
FlowMAC: Conditional Flow Matching for Audio Coding at Low Bit Rates
Sep 26, 2024This paper introduces FlowMAC, a novel neural audio codec for high-quality general audio compression at low bit rates based on conditional flow matching (CFM). FlowMAC jointly learns a mel spectrogram encoder, quantizer and decoder. At inference time the decoder integrates a continuous normalizing flow via an ODE solver to generate a high-quality mel spectrogram. This is the first time that a CFM-based approach is applied to general audio coding, enabling a scalable, simple and memory efficient training. Our subjective evaluations show that FlowMAC at 3 kbps achieves similar quality as state-of-the-art GAN-based and DDPM-based neural audio codecs at double the bit rate. Moreover, FlowMAC offers a tunable inference pipeline, which permits to trade off complexity and quality. This enables real-time coding on CPU, while maintaining high perceptual quality.
On Improving Error Resilience of Neural End-to-End Speech Coders
Jun 13, 2024Error resilient tools like Packet Loss Concealment (PLC) and Forward Error Correction (FEC) are essential to maintain a reliable speech communication for applications like Voice over Internet Protocol (VoIP), where packets are frequently delayed and lost. In recent times, end-to-end neural speech codecs have seen a significant rise, due to their ability to transmit speech signal at low bitrates but few considerations were made about their error resilience in a real system. Recently introduced Neural End-to-End Speech Codec (NESC) can reproduce high quality natural speech at low bitrates. We extend its robustness to packet losses by adding a low complexity network to predict the codebook indices in latent space. Furthermore, we propose a method to add an in-band FEC at an additional bitrate of 0.8 kbps. Both subjective and objective assessment indicate the effectiveness of proposed methods, and demonstrate that coupling PLC and FEC provide significant robustness against packet losses.
Simple and Efficient Quantization Techniques for Neural Speech Coding
May 14, 2024Neural audio coding has emerged as a vivid research direction by promising good audio quality at very low bitrates unachievable by classical coding techniques. Here, end-to-end trainable autoencoder-like models represent the state of the art, where a discrete representation in the bottleneck of the autoencoder has to be learned that allows for efficient transmission of the input audio signal. This discrete representation is typically generated by applying a quantizer to the output of the neural encoder. In almost all state-of-the-art neural audio coding approaches, this quantizer is realized as a Vector Quantizer (VQ) and a lot of effort has been spent to alleviate drawbacks of this quantization technique when used together with a neural audio coder. In this paper, we propose simple alternatives to VQ, which are based on projected Scalar Quantization (SQ). These quantization techniques do not need any additional losses, scheduling parameters or codebook storage thereby simplifying the training of neural audio codecs. Furthermore, we propose a new causal network architecture for neural speech coding that shows good performance at very low computational complexity.
SEFGAN: Harvesting the Power of Normalizing Flows and GANs for Efficient High-Quality Speech Enhancement
Dec 04, 2023



This paper proposes SEFGAN, a Deep Neural Network (DNN) combining maximum likelihood training and Generative Adversarial Networks (GANs) for efficient speech enhancement (SE). For this, a DNN is trained to synthesize the enhanced speech conditioned on noisy speech using a Normalizing Flow (NF) as generator in a GAN framework. While the combination of likelihood models and GANs is not trivial, SEFGAN demonstrates that a hybrid adversarial and maximum likelihood training approach enables the model to maintain high quality audio generation and log-likelihood estimation. Our experiments indicate that this approach strongly outperforms the baseline NF-based model without introducing additional complexity to the enhancement network. A comparison using computational metrics and a listening experiment reveals that SEFGAN is competitive with other state-of-the-art models.
Low-Resource Text-to-Speech Using Specific Data and Noise Augmentation
Jun 16, 2023



Many neural text-to-speech architectures can synthesize nearly natural speech from text inputs. These architectures must be trained with tens of hours of annotated and high-quality speech data. Compiling such large databases for every new voice requires a lot of time and effort. In this paper, we describe a method to extend the popular Tacotron-2 architecture and its training with data augmentation to enable single-speaker synthesis using a limited amount of specific training data. In contrast to elaborate augmentation methods proposed in the literature, we use simple stationary noises for data augmentation. Our extension is easy to implement and adds almost no computational overhead during training and inference. Using only two hours of training data, our approach was rated by human listeners to be on par with the baseline Tacotron-2 trained with 23.5 hours of LJSpeech data. In addition, we tested our model with a semantically unpredictable sentences test, which showed that both models exhibit similar intelligibility levels.
NESC: Robust Neural End-2-End Speech Coding with GANs
Jul 07, 2022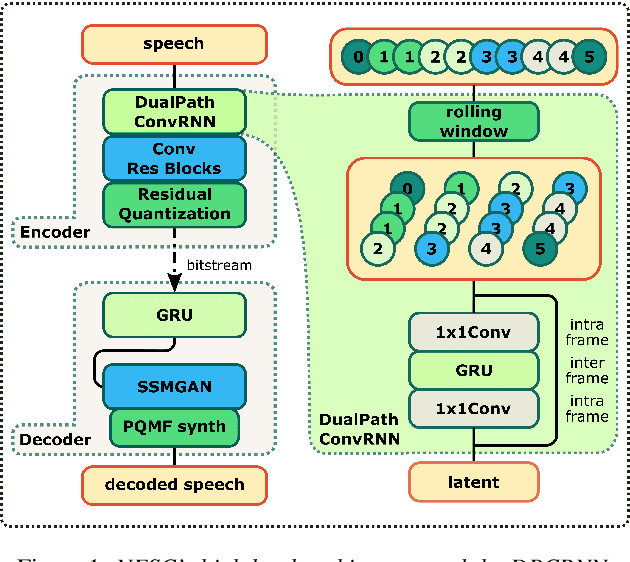
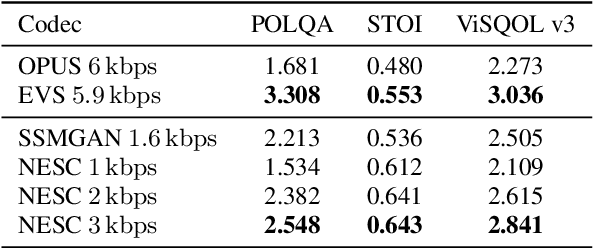
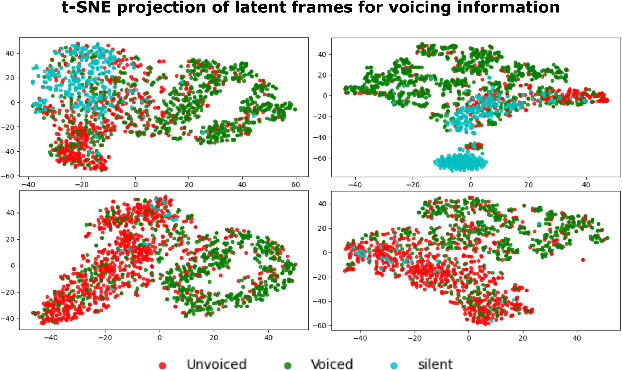
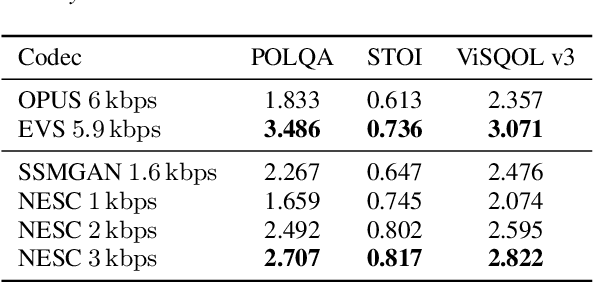
Neural networks have proven to be a formidable tool to tackle the problem of speech coding at very low bit rates. However, the design of a neural coder that can be operated robustly under real-world conditions remains a major challenge. Therefore, we present Neural End-2-End Speech Codec (NESC) a robust, scalable end-to-end neural speech codec for high-quality wideband speech coding at 3 kbps. The encoder uses a new architecture configuration, which relies on our proposed Dual-PathConvRNN (DPCRNN) layer, while the decoder architecture is based on our previous work Streamwise-StyleMelGAN. Our subjective listening tests on clean and noisy speech show that NESC is particularly robust to unseen conditions and signal perturbations.
PostGAN: A GAN-Based Post-Processor to Enhance the Quality of Coded Speech
Jan 31, 2022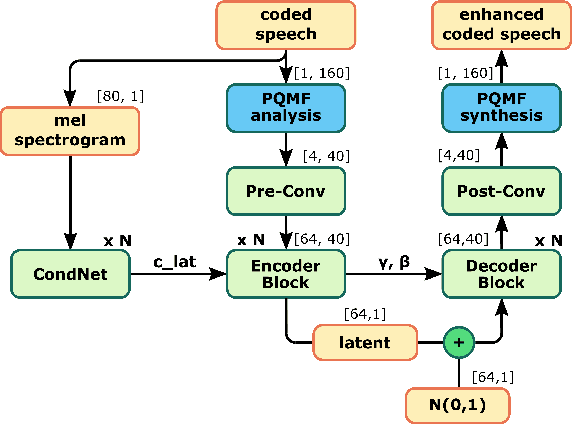
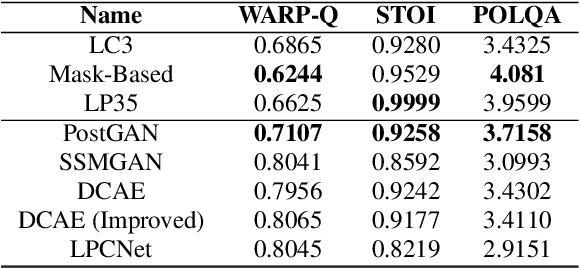
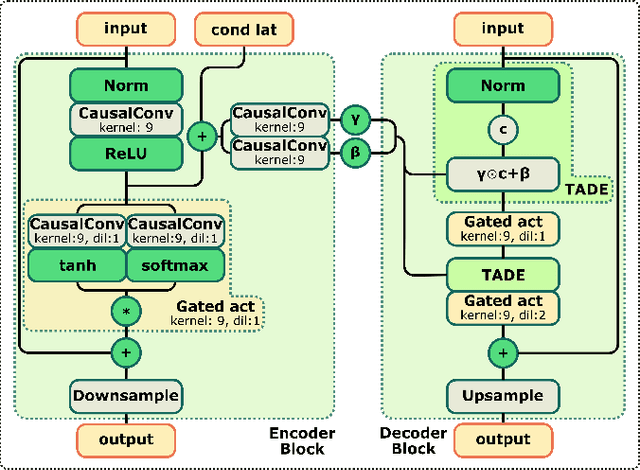
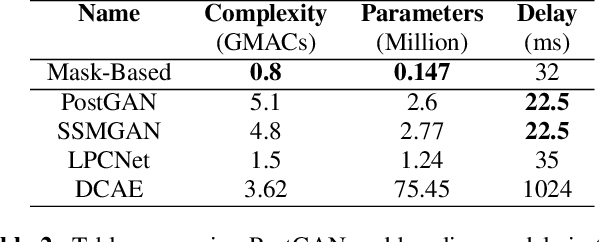
The quality of speech coded by transform coding is affected by various artefacts especially when bitrates to quantize the frequency components become too low. In order to mitigate these coding artefacts and enhance the quality of coded speech, a post-processor that relies on a-priori information transmitted from the encoder is traditionally employed at the decoder side. In recent years, several data-driven post-postprocessors have been proposed which were shown to outperform traditional approaches. In this paper, we propose PostGAN, a GAN-based neural post-processor that operates in the sub-band domain and relies on the U-Net architecture and a learned affine transform. It has been tested on the recently standardized low-complexity, low-delay bluetooth codec (LC3) for wideband speech at the lowest bitrate (16 kbit/s). Subjective evaluations and objective scores show that the newly introduced post-processor surpasses previously published methods and can improve the quality of coded speech by around 20 MUSHRA points.
A Streamwise GAN Vocoder for Wideband Speech Coding at Very Low Bit Rate
Aug 09, 2021
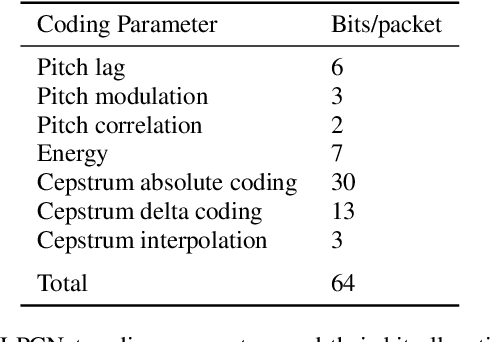
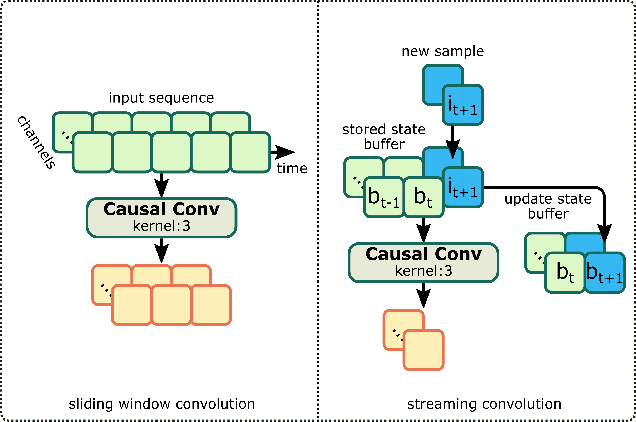
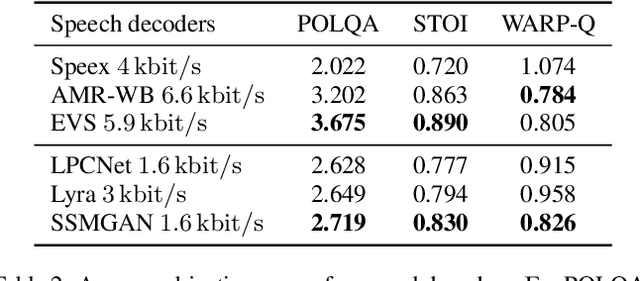
Recently, GAN vocoders have seen rapid progress in speech synthesis, starting to outperform autoregressive models in perceptual quality with much higher generation speed. However, autoregressive vocoders are still the common choice for neural generation of speech signals coded at very low bit rates. In this paper, we present a GAN vocoder which is able to generate wideband speech waveforms from parameters coded at 1.6 kbit/s. The proposed model is a modified version of the StyleMelGAN vocoder that can run in frame-by-frame manner, making it suitable for streaming applications. The experimental results show that the proposed model significantly outperforms prior autoregressive vocoders like LPCNet for very low bit rate speech coding, with computational complexity of about 5 GMACs, providing a new state of the art in this domain. Moreover, this streamwise adversarial vocoder delivers quality competitive to advanced speech codecs such as EVS at 5.9 kbit/s on clean speech, which motivates further usage of feed-forward fully-convolutional models for low bit rate speech coding.