 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Evaluation of Quantization-Effects in Neural Codecs
Feb 07, 2025



Neural codecs, comprising an encoder, quantizer, and decoder, enable signal transmission at exceptionally low bitrates. Training these systems requires techniques like the straight-through estimator, soft-to-hard annealing, or statistical quantizer emulation to allow a non-zero gradient across the quantizer. Evaluating the effect of quantization in neural codecs, like the influence of gradient passing techniques on the whole system, is often costly and time-consuming due to training demands and the lack of affordable and reliable metrics. This paper proposes an efficient evaluation framework for neural codecs using simulated data with a defined number of bits and low-complexity neural encoders/decoders to emulate the non-linear behavior in larger networks. Our system is highly efficient in terms of training time and computational and hardware requirements, allowing us to uncover distinct behaviors in neural codecs. We propose a modification to stabilize training with the straight-through estimator based on our findings. We validate our findings against an internal neural audio codec and against the state-of-the-art descript-audio-codec.
Reinforcement Learning for Adaptive Traffic Signal Control: Turn-Based and Time-Based Approaches to Reduce Congestion
Sep 01, 2024



The growing demand for road use in urban areas has led to significant traffic congestion, posing challenges that are costly to mitigate through infrastructure expansion alone. As an alternative, optimizing existing traffic management systems, particularly through adaptive traffic signal control, offers a promising solution. This paper explores the use of Reinforcement Learning (RL) to enhance traffic signal operations at intersections, aiming to reduce congestion without extensive sensor networks. We introduce two RL-based algorithms: a turn-based agent, which dynamically prioritizes traffic signals based on real-time queue lengths, and a time-based agent, which adjusts signal phase durations according to traffic conditions while following a fixed phase cycle. By representing the state as a scalar queue length, our approach simplifies the learning process and lowers deployment costs. The algorithms were tested in four distinct traffic scenarios using seven evaluation metrics to comprehensively assess performance. Simulation results demonstrate that both RL algorithms significantly outperform conventional traffic signal control systems, highlighting their potential to improve urban traffic flow efficiently.
A Permuted Autoregressive Approach to Word-Level Recognition for Urdu Digital Text
Aug 30, 2024

This research paper introduces a novel word-level Optical Character Recognition (OCR) model specifically designed for digital Urdu text, leveraging transformer-based architectures and attention mechanisms to address the distinct challenges of Urdu script recognition, including its diverse text styles, fonts, and variations. The model employs a permuted autoregressive sequence (PARSeq) architecture, which enhances its performance by enabling context-aware inference and iterative refinement through the training of multiple token permutations. This method allows the model to adeptly manage character reordering and overlapping characters, commonly encountered in Urdu script. Trained on a dataset comprising approximately 160,000 Urdu text images, the model demonstrates a high level of accuracy in capturing the intricacies of Urdu script, achieving a CER of 0.178. Despite ongoing challenges in handling certain text variations, the model exhibits superior accuracy and effectiveness in practical applications. Future work will focus on refining the model through advanced data augmentation techniques and the integration of context-aware language models to further enhance its performance and robustness in Urdu text recognition.
Urdu Digital Text Word Optical Character Recognition Using Permuted Auto Regressive Sequence Modeling
Aug 27, 2024This research paper introduces an innovative word-level Optical Character Recognition (OCR) model specifically designed for digital Urdu text recognition. Utilizing transformer-based architectures and attention mechanisms, the model was trained on a comprehensive dataset of approximately 160,000 Urdu text images, achieving a character error rate (CER) of 0.178, which highlights its superior accuracy in recognizing Urdu characters. The model's strength lies in its unique architecture, incorporating the permuted autoregressive sequence (PARSeq) model, which allows for context-aware inference and iterative refinement by leveraging bidirectional context information to enhance recognition accuracy. Furthermore, its capability to handle a diverse range of Urdu text styles, fonts, and variations enhances its applicability in real-world scenarios. Despite its promising results, the model has some limitations, such as difficulty with blurred images, non-horizontal orientations, and overlays of patterns, lines, or other text, which can occasionally lead to suboptimal performance. Additionally, trailing or following punctuation marks can introduce noise into the recognition process. Addressing these challenges will be a focus of future research, aiming to refine the model further, explore data augmentation techniques, optimize hyperparameters, and integrate contextual improvements for more accurate and efficient Urdu text recognition.
Very Low Complexity Speech Synthesis Using Framewise Autoregressive GAN (FARGAN) with Pitch Prediction
May 31, 2024Neural vocoders are now being used in a wide range of speech processing applications. In many of those applications, the vocoder can be the most complex component, so finding lower complexity algorithms can lead to significant practical benefits. In this work, we propose FARGAN, an autoregressive vocoder that takes advantage of long-term pitch prediction to synthesize high-quality speech in small subframes, without the need for teacher-forcing. Experimental results show that the proposed 600~MFLOPS FARGAN vocoder can achieve both higher quality and lower complexity than existing low-complexity vocoders. The quality even matches that of existing higher-complexity vocoders.
NoLACE: Improving Low-Complexity Speech Codec Enhancement Through Adaptive Temporal Shaping
Sep 25, 2023



Speech codec enhancement methods are designed to remove distortions added by speech codecs. While classical methods are very low in complexity and add zero delay, their effectiveness is rather limited. Compared to that, DNN-based methods deliver higher quality but they are typically high in complexity and/or require delay. The recently proposed Linear Adaptive Coding Enhancer (LACE) addresses this problem by combining DNNs with classical long-term/short-term postfiltering resulting in a causal low-complexity model. A short-coming of the LACE model is, however, that quality quickly saturates when the model size is scaled up. To mitigate this problem, we propose a novel adatpive temporal shaping module that adds high temporal resolution to the LACE model resulting in the Non-Linear Adaptive Coding Enhancer (NoLACE). We adapt NoLACE to enhance the Opus codec and show that NoLACE significantly outperforms both the Opus baseline and an enlarged LACE model at 6, 9 and 12 kb/s. We also show that LACE and NoLACE are well-behaved when used with an ASR system.
LACE: A light-weight, causal model for enhancing coded speech through adaptive convolutions
Jul 13, 2023



Classical speech coding uses low-complexity postfilters with zero lookahead to enhance the quality of coded speech, but their effectiveness is limited by their simplicity. Deep Neural Networks (DNNs) can be much more effective, but require high complexity and model size, or added delay. We propose a DNN model that generates classical filter kernels on a per-frame basis with a model of just 300~K parameters and 100~MFLOPS complexity, which is a practical complexity for desktop or mobile device CPUs. The lack of added delay allows it to be integrated into the Opus codec, and we demonstrate that it enables effective wideband encoding for bitrates down to 6 kb/s.
Framewise WaveGAN: High Speed Adversarial Vocoder in Time Domain with Very Low Computational Complexity
Dec 08, 2022GAN vocoders are currently one of the state-of-the-art methods for building high-quality neural waveform generative models. However, most of their architectures require dozens of billion floating-point operations per second (GFLOPS) to generate speech waveforms in samplewise manner. This makes GAN vocoders still challenging to run on normal CPUs without accelerators or parallel computers. In this work, we propose a new architecture for GAN vocoders that mainly depends on recurrent and fully-connected networks to directly generate the time domain signal in framewise manner. This results in considerable reduction of the computational cost and enables very fast generation on both GPUs and low-complexity CPUs. Experimental results show that our Framewise WaveGAN vocoder achieves significantly higher quality than auto-regressive maximum-likelihood vocoders such as LPCNet at a very low complexity of 1.2 GFLOPS. This makes GAN vocoders more practical on edge and low-power devices.
Low-Bitrate Redundancy Coding of Speech Using a Rate-Distortion-Optimized Variational Autoencoder
Dec 08, 2022Robustness to packet loss is one of the main ongoing challenges in real-time speech communication. Deep packet loss concealment (PLC) techniques have recently demonstrated improved quality compared to traditional PLC. Despite that, all PLC techniques hit fundamental limitations when too much acoustic information is lost. To reduce losses in the first place, data is commonly sent multiple times using various redundancy mechanisms. We propose a neural speech coder specifically optimized to transmit a large amount of overlapping redundancy at a very low bitrate, up to 50x redundancy using less than 32~kb/s. Results show that the proposed redundancy is more effective than the existing Opus codec redundancy, and that the two can be combined for even greater robustness.
Real-Time Packet Loss Concealment With Mixed Generative and Predictive Model
May 11, 2022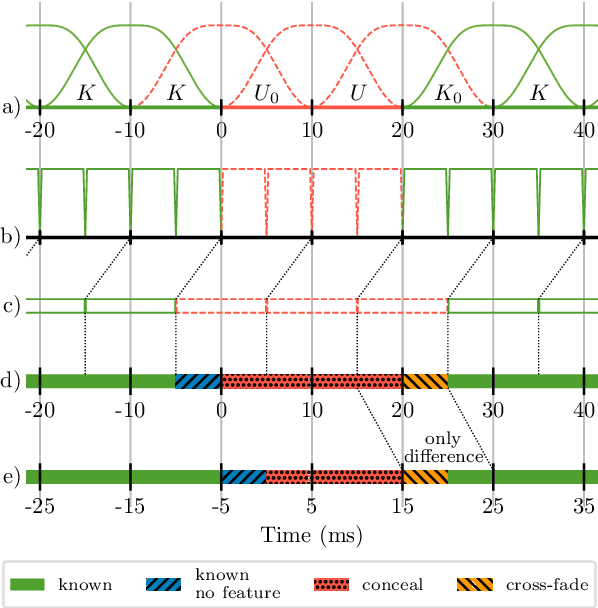

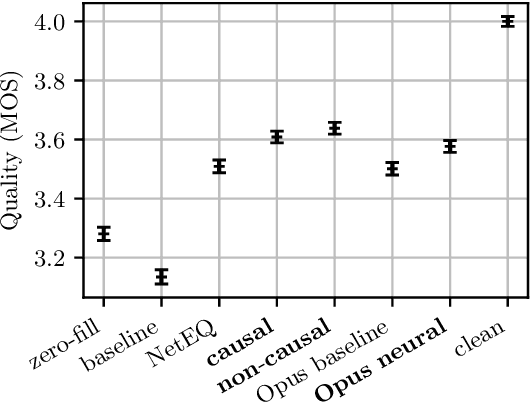
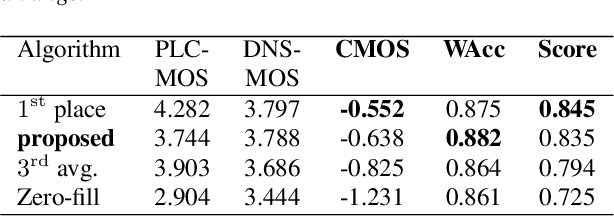
As deep speech enhancement algorithms have recently demonstrated capabilities greatly surpassing their traditional counterparts for suppressing noise, reverberation and echo, attention is turning to the problem of packet loss concealment (PLC). PLC is a challenging task because it not only involves real-time speech synthesis, but also frequent transitions between the received audio and the synthesized concealment. We propose a hybrid neural PLC architecture where the missing speech is synthesized using a generative model conditioned using a predictive model. The resulting algorithm achieves natural concealment that surpasses the quality of existing conventional PLC algorithms and ranked second in the Interspeech 2022 PLC Challenge. We show that our solution not only works for uncompressed audio, but is also applicable to a modern speech codec.