 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
VCVTS: Multi-speaker Video-to-Speech synthesis via cross-modal knowledge transfer from voice conversion
Feb 18, 2022
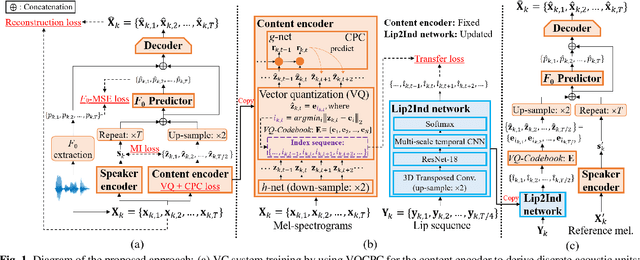
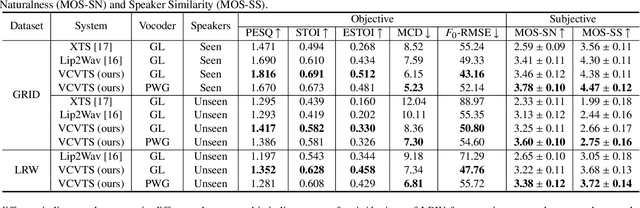
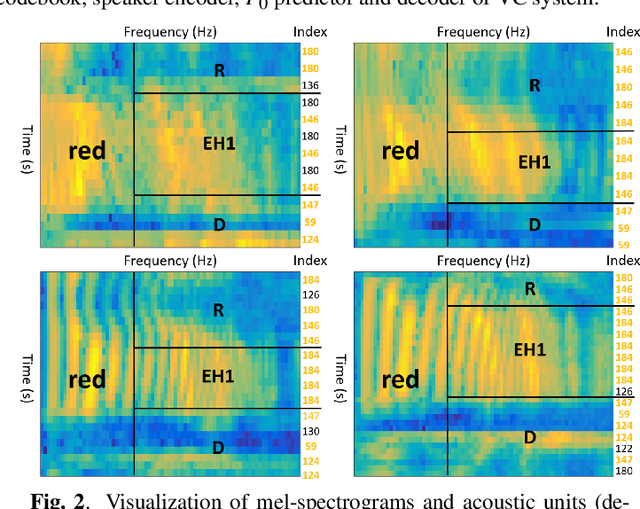
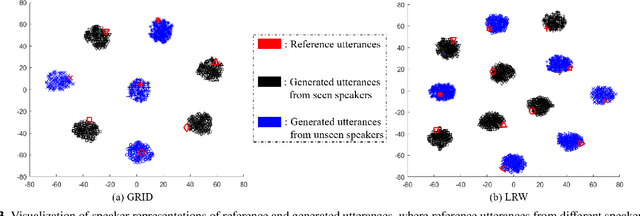
Though significant progress has been made for speaker-dependent Video-to-Speech (VTS) synthesis, little attention is devoted to multi-speaker VTS that can map silent video to speech, while allowing flexible control of speaker identity, all in a single system. This paper proposes a novel multi-speaker VTS system based on cross-modal knowledge transfer from voice conversion (VC), where vector quantization with contrastive predictive coding (VQCPC) is used for the content encoder of VC to derive discrete phoneme-like acoustic units, which are transferred to a Lip-to-Index (Lip2Ind) network to infer the index sequence of acoustic units. The Lip2Ind network can then substitute the content encoder of VC to form a multi-speaker VTS system to convert silent video to acoustic units for reconstructing accurate spoken content. The VTS system also inherits the advantages of VC by using a speaker encoder to produce speaker representations to effectively control the speaker identity of generated speech. Extensive evaluations verify the effectiveness of proposed approach, which can be applied in both constrained vocabulary and open vocabulary conditions, achieving state-of-the-art performance in generating high-quality speech with high naturalness, intelligibility and speaker similarity. Our demo page is released here: https://wendison.github.io/VCVTS-demo/
Metric Learning for User-defined Keyword Spotting
Nov 01, 2022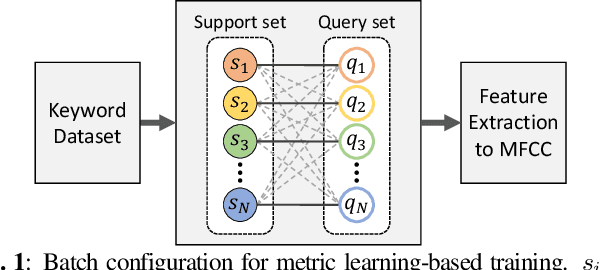
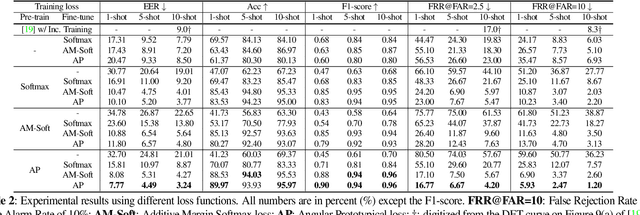

The goal of this work is to detect new spoken terms defined by users. While most previous works address Keyword Spotting (KWS) as a closed-set classification problem, this limits their transferability to unseen terms. The ability to define custom keywords has advantages in terms of user experience. In this paper, we propose a metric learning-based training strategy for user-defined keyword spotting. In particular, we make the following contributions: (1) we construct a large-scale keyword dataset with an existing speech corpus and propose a filtering method to remove data that degrade model training; (2) we propose a metric learning-based two-stage training strategy, and demonstrate that the proposed method improves the performance on the user-defined keyword spotting task by enriching their representations; (3) to facilitate the fair comparison in the user-defined KWS field, we propose unified evaluation protocol and metrics. Our proposed system does not require an incremental training on the user-defined keywords, and outperforms previous works by a significant margin on the Google Speech Commands dataset using the proposed as well as the existing metrics.
Multi-Dialect Arabic Speech Recognition
Dec 25, 2021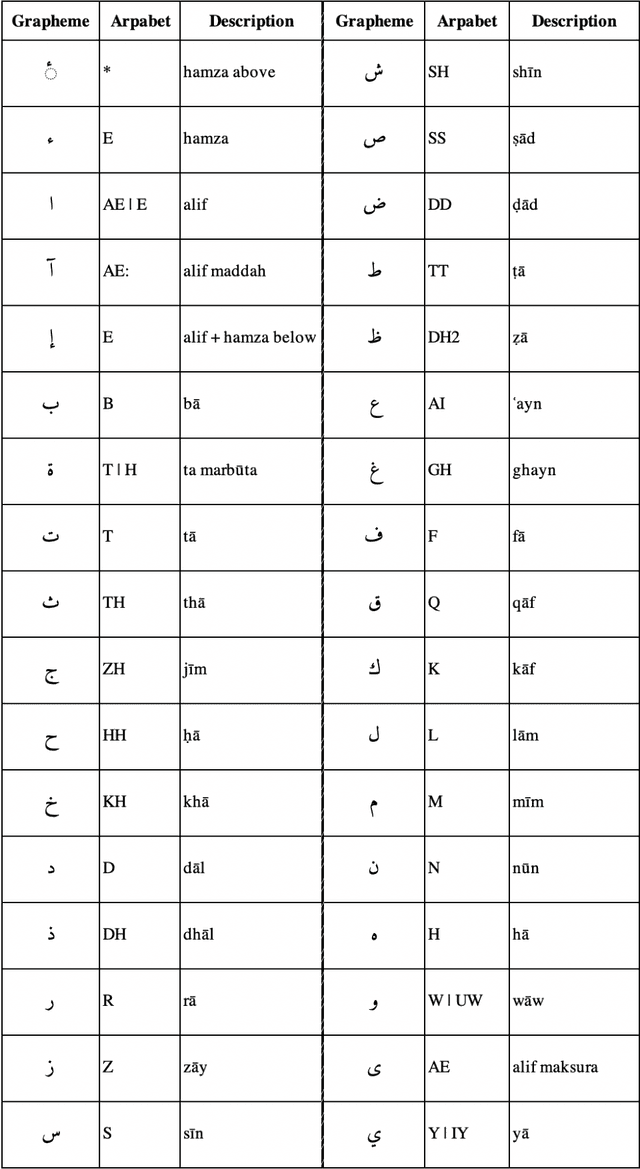
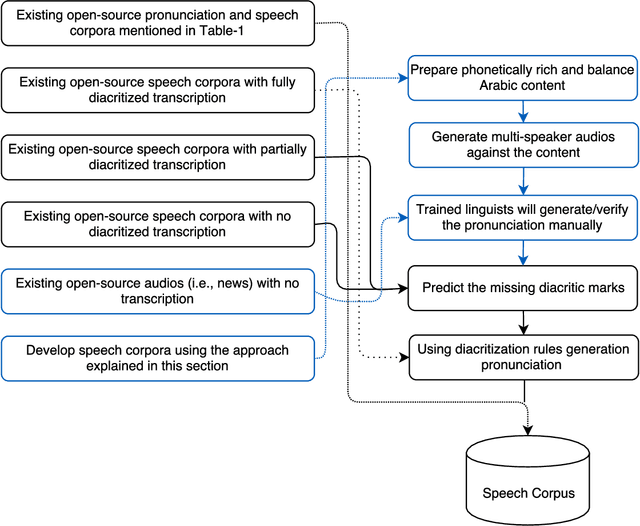
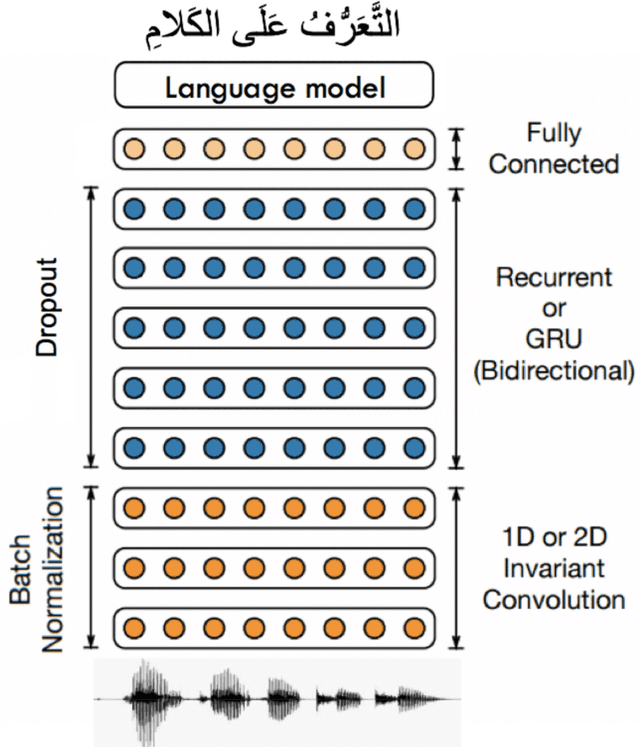

This paper presents the design and development of multi-dialect automatic speech recognition for Arabic. Deep neural networks are becoming an effective tool to solve sequential data problems, particularly, adopting an end-to-end training of the system. Arabic speech recognition is a complex task because of the existence of multiple dialects, non-availability of large corpora, and missing vocalization. Thus, the first contribution of this work is the development of a large multi-dialectal corpus with either full or at least partially vocalized transcription. Additionally, the open-source corpus has been gathered from multiple sources that bring non-standard Arabic alphabets in transcription which are normalized by defining a common character-set. The second contribution is the development of a framework to train an acoustic model achieving state-of-the-art performance. The network architecture comprises of a combination of convolutional and recurrent layers. The spectrogram features of the audio data are extracted in the frequency vs time domain and fed in the network. The output frames, produced by the recurrent model, are further trained to align the audio features with its corresponding transcription sequences. The sequence alignment is performed using a beam search decoder with a tetra-gram language model. The proposed system achieved a 14% error rate which outperforms previous systems.
BD-SHS: A Benchmark Dataset for Learning to Detect Online Bangla Hate Speech in Different Social Contexts
Jun 01, 2022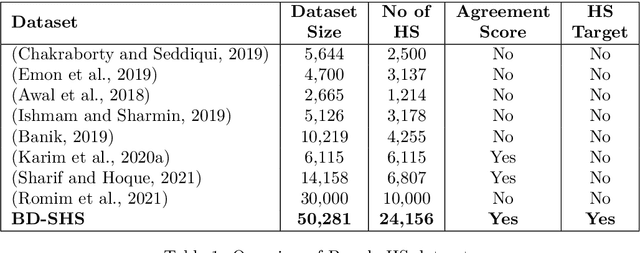

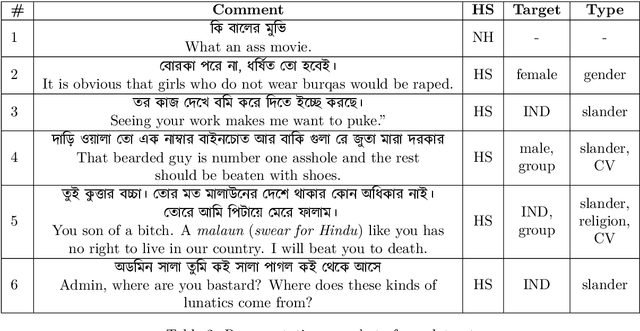
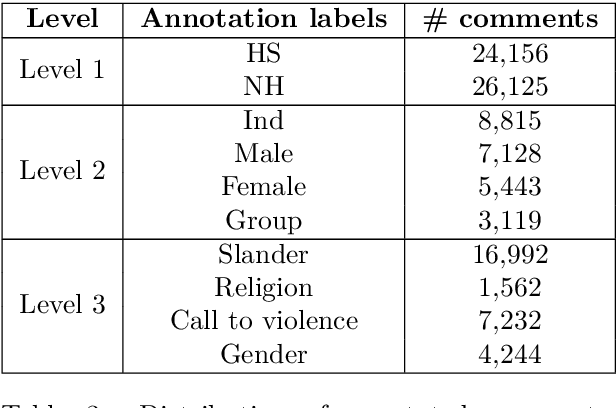
Social media platforms and online streaming services have spawned a new breed of Hate Speech (HS). Due to the massive amount of user-generated content on these sites, modern machine learning techniques are found to be feasible and cost-effective to tackle this problem. However, linguistically diverse datasets covering different social contexts in which offensive language is typically used are required to train generalizable models. In this paper, we identify the shortcomings of existing Bangla HS datasets and introduce a large manually labeled dataset BD-SHS that includes HS in different social contexts. The labeling criteria were prepared following a hierarchical annotation process, which is the first of its kind in Bangla HS to the best of our knowledge. The dataset includes more than 50,200 offensive comments crawled from online social networking sites and is at least 60% larger than any existing Bangla HS datasets. We present the benchmark result of our dataset by training different NLP models resulting in the best one achieving an F1-score of 91.0%. In our experiments, we found that a word embedding trained exclusively using 1.47 million comments from social media and streaming sites consistently resulted in better modeling of HS detection in comparison to other pre-trained embeddings. Our dataset and all accompanying codes is publicly available at github.com/naurosromim/hate-speech-dataset-for-Bengali-social-media
Efficient Use of Large Pre-Trained Models for Low Resource ASR
Oct 26, 2022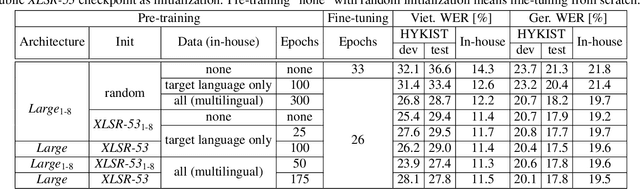
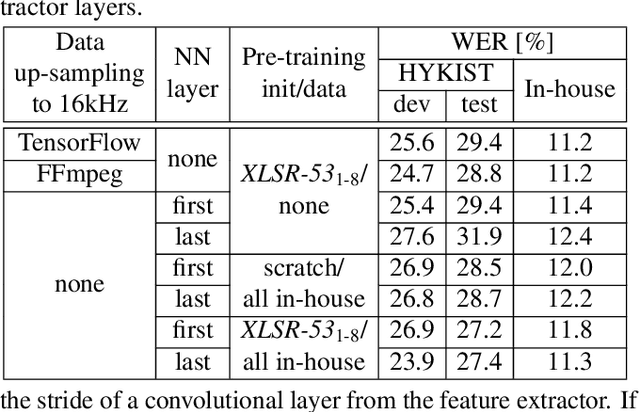
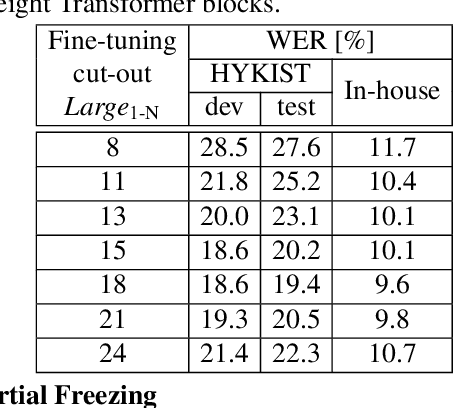
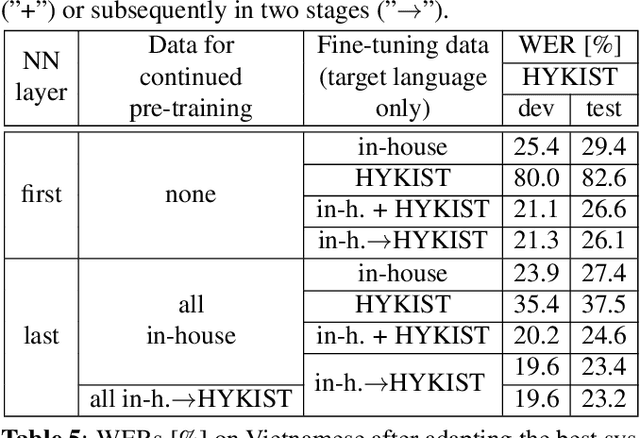
Automatic speech recognition (ASR) has been established as a well-performing technique for many scenarios where lots of labeled data is available. Additionally, unsupervised representation learning recently helped to tackle tasks with limited data. Following this, hardware limitations and applications give rise to the question how to efficiently take advantage of large pretrained models and reduce their complexity for downstream tasks. In this work, we study a challenging low resource conversational telephony speech corpus from the medical domain in Vietnamese and German. We show the benefits of using unsupervised techniques beyond simple fine-tuning of large pre-trained models, discuss how to adapt them to a practical telephony task including bandwidth transfer and investigate different data conditions for pre-training and fine-tuning. We outperform the project baselines by 22% relative using pretraining techniques. Further gains of 29% can be achieved by refinements of architecture and training and 6% by adding 0.8 h of in-domain adaptation data.
Speaker Diarization Based on Multi-channel Microphone Array in Small-scale Meeting
Oct 26, 2022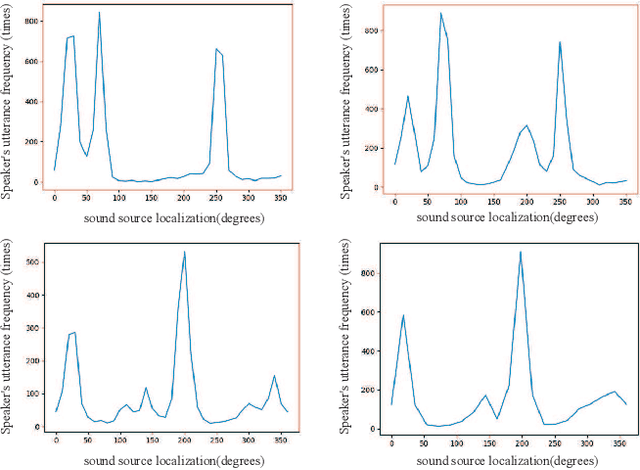
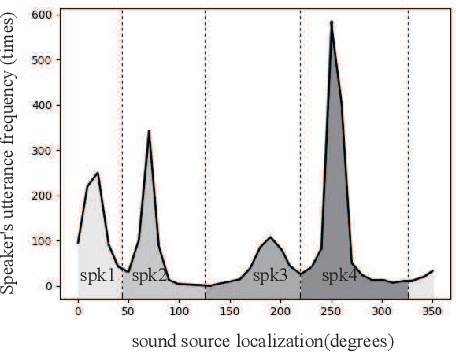
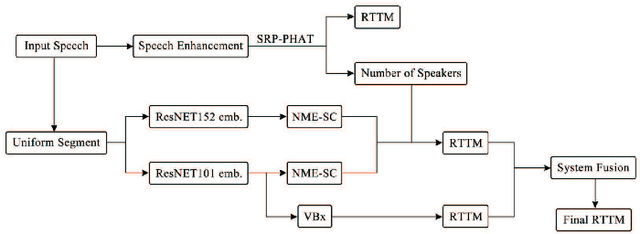

In the task of speaker diarization, the number of small-scale meetings accounts for a large proportion. When microphone arrays are employed as a recording device, its spatial information is usually ignored by most researchers. In this paper, inspired by the clustering method combining d-vector and microphone array spatial vector, we proposed a diarization method which using multi-channel microphone arrays for a meeting with no more than 4 speakers. We utilize speech enhancement to preprocess the audio from the microphone array. The Steered-Response Power Phase Transform (SRP-PHAT) algorithm are employed to get more accurate speakers, and apply the number of speakers to recluster the speech segments to achieve better performance. Finally, we fuse our system by DOVER-LAP to get the best result. We evaluated our system on the AMI corpus. Compared with the best experimental results so far, our system has achieved largely improvement in the diarization error rate (DER).
Lisan: Yemeni, Iraqi, Libyan, and Sudanese Arabic Dialect Copora with Morphological Annotations
Dec 17, 2022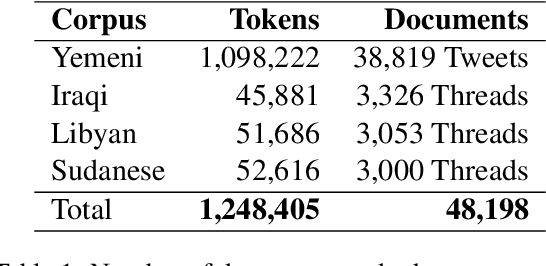
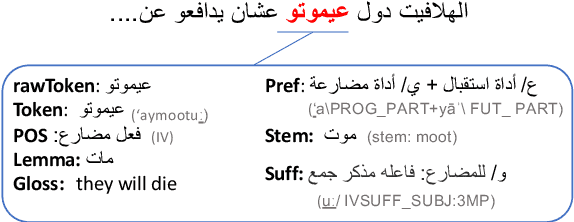
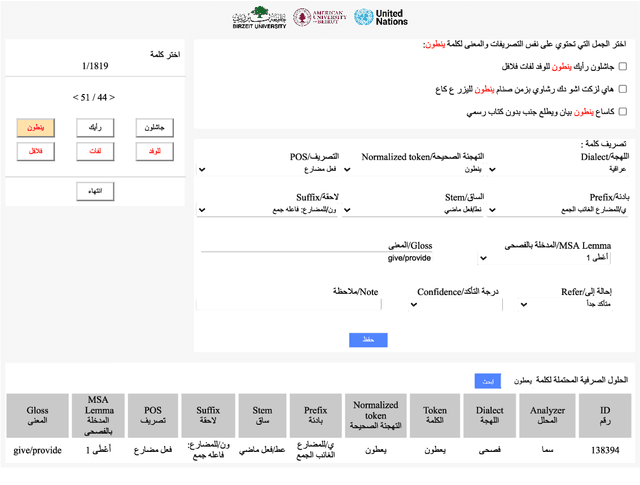
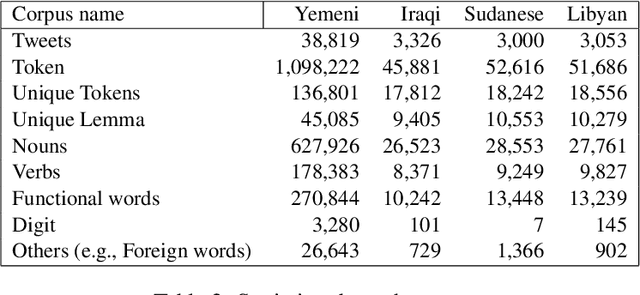
This article presents morphologically-annotated Yemeni, Sudanese, Iraqi, and Libyan Arabic dialects Lisan corpora. Lisan features around 1.2 million tokens. We collected the content of the corpora from several social media platforms. The Yemeni corpus (~ 1.05M tokens) was collected automatically from Twitter. The corpora of the other three dialects (~ 50K tokens each) came manually from Facebook and YouTube posts and comments. Thirty five (35) annotators who are native speakers of the target dialects carried out the annotations. The annotators segemented all words in the four corpora into prefixes, stems and suffixes and labeled each with different morphological features such as part of speech, lemma, and a gloss in English. An Arabic Dialect Annotation Toolkit ADAT was developped for the purpose of the annation. The annotators were trained on a set of guidelines and on how to use ADAT. We developed ADAT to assist the annotators and to ensure compatibility with SAMA and Curras tagsets. The tool is open source, and the four corpora are also available online.
Unsupervised Quantized Prosody Representation for Controllable Speech Synthesis
Apr 07, 2022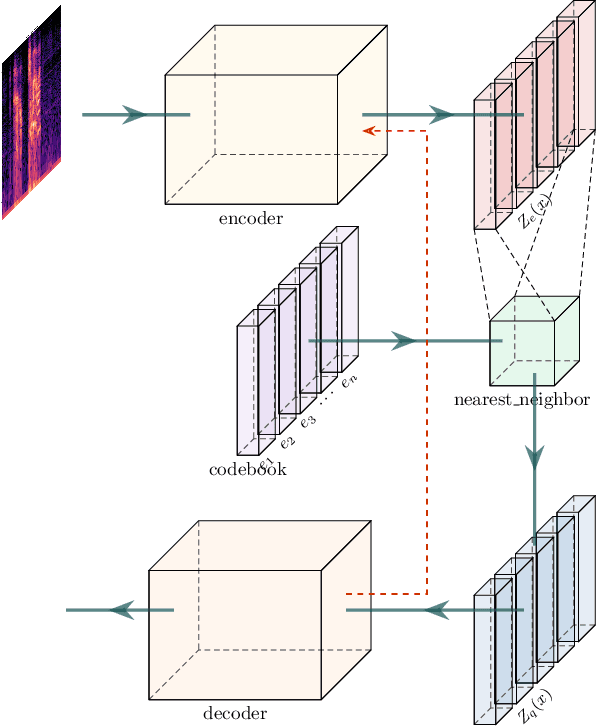
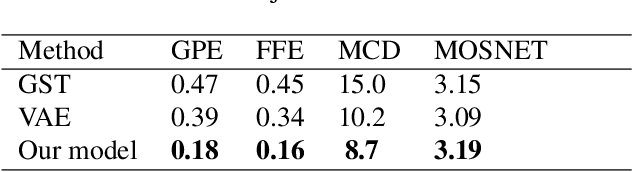
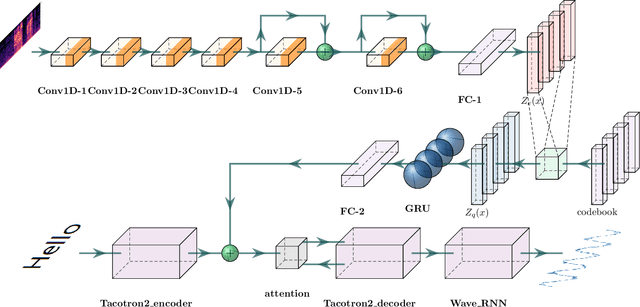
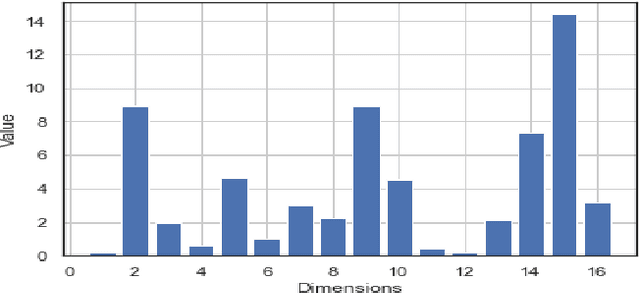
In this paper, we propose a novel prosody disentangle method for prosodic Text-to-Speech (TTS) model, which introduces the vector quantization (VQ) method to the auxiliary prosody encoder to obtain the decomposed prosody representations in an unsupervised manner. Rely on its advantages, the speaking styles, such as pitch, speaking velocity, local pitch variance, etc., are decomposed automatically into the latent quantize vectors. We also investigate the internal mechanism of VQ disentangle process by means of a latent variables counter and find that higher value dimensions usually represent prosody information. Experiments show that our model can control the speaking styles of synthesis results by directly manipulating the latent variables. The objective and subjective evaluations illustrated that our model outperforms the popular models.
Membership Inference Attacks Against Self-supervised Speech Models
Nov 09, 2021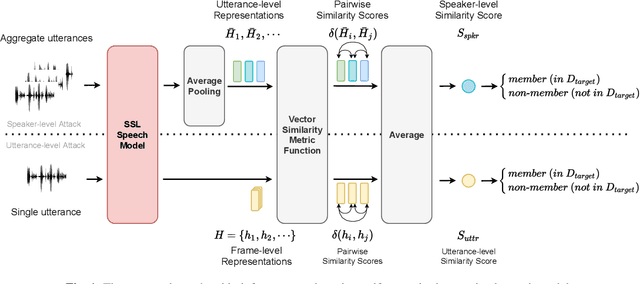
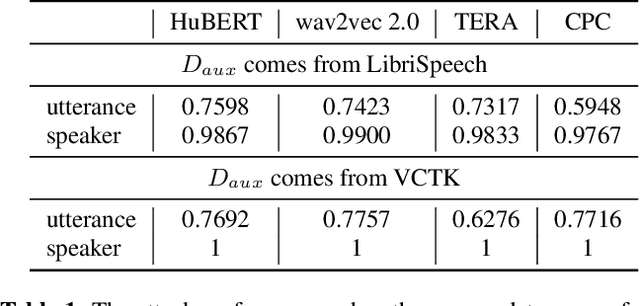
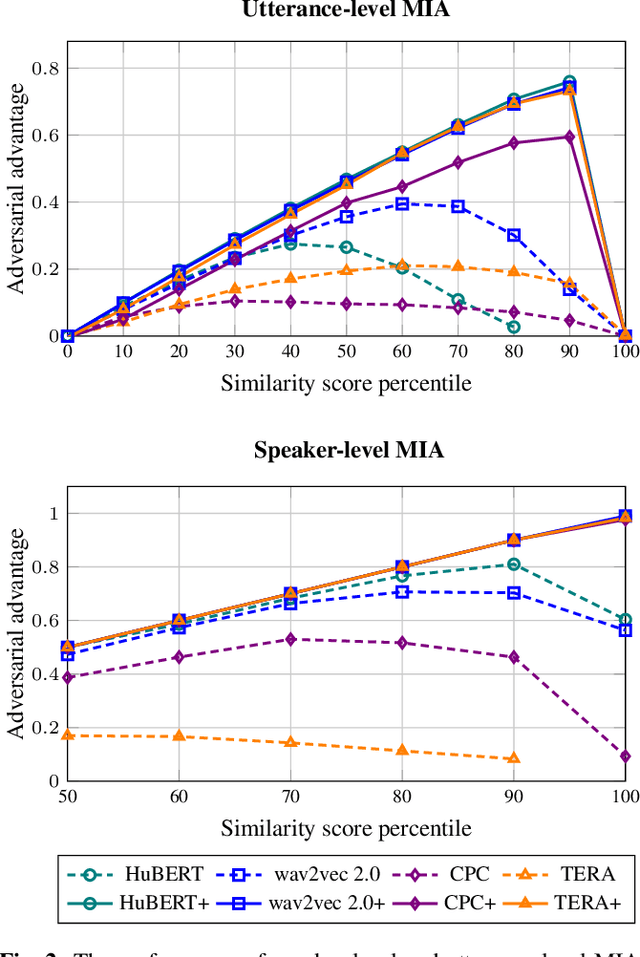
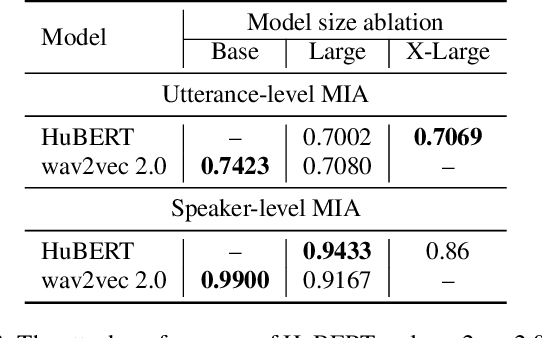
Recently, adapting the idea of self-supervised learning (SSL) on continuous speech has started gaining attention. SSL models pre-trained on a huge amount of unlabeled audio can generate general-purpose representations that benefit a wide variety of speech processing tasks. Despite their ubiquitous deployment, however, the potential privacy risks of these models have not been well investigated. In this paper, we present the first privacy analysis on several SSL speech models using Membership Inference Attacks (MIA) under black-box access. The experiment results show that these pre-trained models are vulnerable to MIA and prone to membership information leakage with high adversarial advantage scores in both utterance-level and speaker-level. Furthermore, we also conduct several ablation studies to understand the factors that contribute to the success of MIA.
Counter Hate Speech in Social Media: A Survey
Feb 21, 2022With the high prevalence of offensive language against minorities in social media, counter-hate speeches (CHS) generation is considered an automatic way of tackling this challenge. The CHS is supposed to appear as a third voice to educate people and keep the social [red lines bold] without limiting the principles of freedom of speech. In this paper, we review the most important research in the past and present with a main focus on methodologies, collected datasets and statistical analysis CHS's impact on social media. The CHS generation is based on the optimistic assumption that any attempt to intervene the hate speech in social media can play a positive role in this context. Beyond that, previous works ignored the investigation of the sequence of comments before and after the CHS. However, the positive impact is not guaranteed, as shown in some previous works. To the best of our knowledge, no attempt has been made to survey the related work to compare the past research in terms of CHS's impact on social media. We take the first step in this direction by providing a comprehensive review on related works and categorizing them based on different factors including impact, methodology, data source, etc.