 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating State Aliasing in Vision-Language-Action Models via Inverse Dynamics Learning
May 28, 2026Vision-Language-Action (VLA) models have emerged as a promising framework that unifies perception, reasoning, and control for robot manipulation by adapting pretrained vision-language models (VLMs) to action prediction. However, VLM-derived representations are often insensitive to subtle visual distinctions required for low-level control, causing state aliasing between visually similar states that require substantially different actions. Prior VLA studies improve visual understanding by generating visual or reasoning outputs, such as future frames, 2D grounding points or traces, or intermediate spatial reasoning steps, but these objectives typically shape the vision encoder only indirectly through end-to-end prediction and do not explicitly analyze state aliasing in the learned visual feature space. To mitigate state aliasing, we introduce inverse dynamics learning as an auxiliary objective that directly supervises the VLA vision encoder. By predicting the action between current and future observations, our objective encourages the encoder to capture fine-grained visual distinctions that determine low-level actions. We further use pseudo-reversed supervision to expose the encoder to a broader range of action directions and improve generalization under limited robot demonstrations. Our method applies to diverse VLA baselines, uses only standard observation-action pairs without additional annotations, and preserves the original inference pipeline at test time. Experiments on CALVIN ABC-D and SimplerEnv show consistent gains across diverse VLA baselines. Frozen-encoder probing and state-feature alignment analyses further show that our method learns state-discriminative visual representations that reduce state aliasing and better align with robot state changes.
RegFormer: Transferable Relational Grounding for Efficient Weakly-Supervised Human-Object Interaction Detection
Apr 01, 2026Weakly-supervised Human-Object Interaction (HOI) detection is essential for scalable scene understanding, as it learns interactions from only image-level annotations. Due to the lack of localization signals, prior works typically rely on an external object detector to generate candidate pairs and then infer their interactions through pairwise reasoning. However, this framework often struggles to scale due to the substantial computational cost incurred by enumerating numerous instance pairs. In addition, it suffers from false positives arising from non-interactive combinations, which hinder accurate instance-level HOI reasoning. To address these issues, we introduce Relational Grounding Transformer (RegFormer), a versatile interaction recognition module for efficient and accurate HOI reasoning. Under image-level supervision, RegFormer leverages spatially grounded signals as guidance for the reasoning process and promotes locality-aware interaction learning. By learning localized interaction cues, our module distinguishes humans, objects, and their interactions, enabling direct transfer from image-level interaction reasoning to precise and efficient instance-level reasoning without additional training. Our extensive experiments and analyses demonstrate that RegFormer effectively learns spatial cues for instance-level interaction reasoning, operates with high efficiency, and even achieves performance comparable to fully supervised models. Our code is available at https://github.com/mlvlab/RegFormer.
Hybrid Decoding: Rapid Pass and Selective Detailed Correction for Sequence Models
Aug 27, 2025Recently, Transformer-based encoder-decoder models have demonstrated strong performance in multilingual speech recognition. However, the decoder's autoregressive nature and large size introduce significant bottlenecks during inference. Additionally, although rare, repetition can occur and negatively affect recognition accuracy. To tackle these challenges, we propose a novel Hybrid Decoding approach that both accelerates inference and alleviates the issue of repetition. Our method extends the transformer encoder-decoder architecture by attaching a lightweight, fast decoder to the pretrained encoder. During inference, the fast decoder rapidly generates an output, which is then verified and, if necessary, selectively corrected by the Transformer decoder. This results in faster decoding and improved robustness against repetitive errors. Experiments on the LibriSpeech and GigaSpeech test sets indicate that, with fine-tuning limited to the added decoder, our method achieves word error rates comparable to or better than the baseline, while more than doubling the inference speed.
Transferable Model-agnostic Vision-Language Model Adaptation for Efficient Weak-to-Strong Generalization
Aug 13, 2025



Vision-Language Models (VLMs) have been widely used in various visual recognition tasks due to their remarkable generalization capabilities. As these models grow in size and complexity, fine-tuning becomes costly, emphasizing the need to reuse adaptation knowledge from 'weaker' models to efficiently enhance 'stronger' ones. However, existing adaptation transfer methods exhibit limited transferability across models due to their model-specific design and high computational demands. To tackle this, we propose Transferable Model-agnostic adapter (TransMiter), a light-weight adapter that improves vision-language models 'without backpropagation'. TransMiter captures the knowledge gap between pre-trained and fine-tuned VLMs, in an 'unsupervised' manner. Once trained, this knowledge can be seamlessly transferred across different models without the need for backpropagation. Moreover, TransMiter consists of only a few layers, inducing a negligible additional inference cost. Notably, supplementing the process with a few labeled data further yields additional performance gain, often surpassing a fine-tuned stronger model, with a marginal training cost. Experimental results and analyses demonstrate that TransMiter effectively and efficiently transfers adaptation knowledge while preserving generalization abilities across VLMs of different sizes and architectures in visual recognition tasks.
Super-class guided Transformer for Zero-Shot Attribute Classification
Jan 16, 2025



Attribute classification is crucial for identifying specific characteristics within image regions. Vision-Language Models (VLMs) have been effective in zero-shot tasks by leveraging their general knowledge from large-scale datasets. Recent studies demonstrate that transformer-based models with class-wise queries can effectively address zero-shot multi-label classification. However, poor utilization of the relationship between seen and unseen attributes makes the model lack generalizability. Additionally, attribute classification generally involves many attributes, making maintaining the model's scalability difficult. To address these issues, we propose Super-class guided transFormer (SugaFormer), a novel framework that leverages super-classes to enhance scalability and generalizability for zero-shot attribute classification. SugaFormer employs Super-class Query Initialization (SQI) to reduce the number of queries, utilizing common semantic information from super-classes, and incorporates Multi-context Decoding (MD) to handle diverse visual cues. To strengthen generalizability, we introduce two knowledge transfer strategies that utilize VLMs. During training, Super-class guided Consistency Regularization (SCR) aligns model's features with VLMs using super-class guided prompts, and during inference, Zero-shot Retrieval-based Score Enhancement (ZRSE) refines predictions for unseen attributes. Extensive experiments demonstrate that SugaFormer achieves state-of-the-art performance across three widely-used attribute classification benchmarks under zero-shot, and cross-dataset transfer settings. Our code is available at https://github.com/mlvlab/SugaFormer.
Bridging the Gap between Audio and Text using Parallel-attention for User-defined Keyword Spotting
Aug 07, 2024


This paper proposes a novel user-defined keyword spotting framework that accurately detects audio keywords based on text enrollment. Since audio data possesses additional acoustic information compared to text, there are discrepancies between these two modalities. To address this challenge, we present ParallelKWS, which utilises self- and cross-attention in a parallel architecture to effectively capture information both within and across the two modalities. We further propose a phoneme duration-based alignment loss that enforces the sequential correspondence between audio and text features. Extensive experimental results demonstrate that our proposed method achieves state-of-the-art performance on several benchmark datasets in both seen and unseen domains, without incorporating extra data beyond the dataset used in previous studies.
Robust Multimodal 3D Object Detection via Modality-Agnostic Decoding and Proximity-based Modality Ensemble
Jul 27, 2024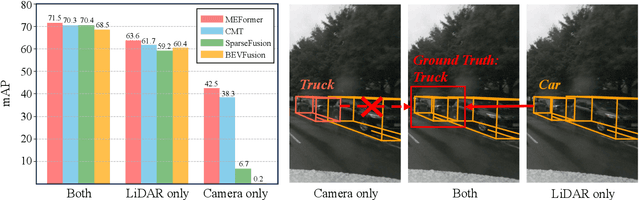



Recent advancements in 3D object detection have benefited from multi-modal information from the multi-view cameras and LiDAR sensors. However, the inherent disparities between the modalities pose substantial challenges. We observe that existing multi-modal 3D object detection methods heavily rely on the LiDAR sensor, treating the camera as an auxiliary modality for augmenting semantic details. This often leads to not only underutilization of camera data but also significant performance degradation in scenarios where LiDAR data is unavailable. Additionally, existing fusion methods overlook the detrimental impact of sensor noise induced by environmental changes, on detection performance. In this paper, we propose MEFormer to address the LiDAR over-reliance problem by harnessing critical information for 3D object detection from every available modality while concurrently safeguarding against corrupted signals during the fusion process. Specifically, we introduce Modality Agnostic Decoding (MOAD) that extracts geometric and semantic features with a shared transformer decoder regardless of input modalities and provides promising improvement with a single modality as well as multi-modality. Additionally, our Proximity-based Modality Ensemble (PME) module adaptively utilizes the strengths of each modality depending on the environment while mitigating the effects of a noisy sensor. Our MEFormer achieves state-of-the-art performance of 73.9% NDS and 71.5% mAP in the nuScenes validation set. Extensive analyses validate that our MEFormer improves robustness against challenging conditions such as sensor malfunctions or environmental changes. The source code is available at https://github.com/hanchaa/MEFormer
Groupwise Query Specialization and Quality-Aware Multi-Assignment for Transformer-based Visual Relationship Detection
Mar 26, 2024Visual Relationship Detection (VRD) has seen significant advancements with Transformer-based architectures recently. However, we identify two key limitations in a conventional label assignment for training Transformer-based VRD models, which is a process of mapping a ground-truth (GT) to a prediction. Under the conventional assignment, an unspecialized query is trained since a query is expected to detect every relation, which makes it difficult for a query to specialize in specific relations. Furthermore, a query is also insufficiently trained since a GT is assigned only to a single prediction, therefore near-correct or even correct predictions are suppressed by being assigned no relation as a GT. To address these issues, we propose Groupwise Query Specialization and Quality-Aware Multi-Assignment (SpeaQ). Groupwise Query Specialization trains a specialized query by dividing queries and relations into disjoint groups and directing a query in a specific query group solely toward relations in the corresponding relation group. Quality-Aware Multi-Assignment further facilitates the training by assigning a GT to multiple predictions that are significantly close to a GT in terms of a subject, an object, and the relation in between. Experimental results and analyses show that SpeaQ effectively trains specialized queries, which better utilize the capacity of a model, resulting in consistent performance gains with zero additional inference cost across multiple VRD models and benchmarks. Code is available at https://github.com/mlvlab/SpeaQ.
Open-vocabulary Video Question Answering: A New Benchmark for Evaluating the Generalizability of Video Question Answering Models
Aug 18, 2023Video Question Answering (VideoQA) is a challenging task that entails complex multi-modal reasoning. In contrast to multiple-choice VideoQA which aims to predict the answer given several options, the goal of open-ended VideoQA is to answer questions without restricting candidate answers. However, the majority of previous VideoQA models formulate open-ended VideoQA as a classification task to classify the video-question pairs into a fixed answer set, i.e., closed-vocabulary, which contains only frequent answers (e.g., top-1000 answers). This leads the model to be biased toward only frequent answers and fail to generalize on out-of-vocabulary answers. We hence propose a new benchmark, Open-vocabulary Video Question Answering (OVQA), to measure the generalizability of VideoQA models by considering rare and unseen answers. In addition, in order to improve the model's generalization power, we introduce a novel GNN-based soft verbalizer that enhances the prediction on rare and unseen answers by aggregating the information from their similar words. For evaluation, we introduce new baselines by modifying the existing (closed-vocabulary) open-ended VideoQA models and improve their performances by further taking into account rare and unseen answers. Our ablation studies and qualitative analyses demonstrate that our GNN-based soft verbalizer further improves the model performance, especially on rare and unseen answers. We hope that our benchmark OVQA can serve as a guide for evaluating the generalizability of VideoQA models and inspire future research. Code is available at https://github.com/mlvlab/OVQA.
Joint unsupervised and supervised learning for context-aware language identification
Apr 14, 2023Language identification (LID) recognizes the language of a spoken utterance automatically. According to recent studies, LID models trained with an automatic speech recognition (ASR) task perform better than those trained with a LID task only. However, we need additional text labels to train the model to recognize speech, and acquiring the text labels is a cost high. In order to overcome this problem, we propose context-aware language identification using a combination of unsupervised and supervised learning without any text labels. The proposed method learns the context of speech through masked language modeling (MLM) loss and simultaneously trains to determine the language of the utterance with supervised learning loss. The proposed joint learning was found to reduce the error rate by 15.6% compared to the same structure model trained by supervised-only learning on a subset of the VoxLingua107 dataset consisting of sub-three-second utterances in 11 languages.