 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Dubbing: End-to-End Auto-Audiobook System with Text-to-Timbre and Context-Aware Instruct-TTS
Sep 19, 2025



The pipeline for multi-participant audiobook production primarily consists of three stages: script analysis, character voice timbre selection, and speech synthesis. Among these, script analysis can be automated with high accuracy using NLP models, whereas character voice timbre selection still relies on manual effort. Speech synthesis uses either manual dubbing or text-to-speech (TTS). While TTS boosts efficiency, it struggles with emotional expression, intonation control, and contextual scene adaptation. To address these challenges, we propose DeepDubbing, an end-to-end automated system for multi-participant audiobook production. The system comprises two main components: a Text-to-Timbre (TTT) model and a Context-Aware Instruct-TTS (CA-Instruct-TTS) model. The TTT model generates role-specific timbre embeddings conditioned on text descriptions. The CA-Instruct-TTS model synthesizes expressive speech by analyzing contextual dialogue and incorporating fine-grained emotional instructions. This system enables the automated generation of multi-participant audiobooks with both timbre-matched character voices and emotionally expressive narration, offering a novel solution for audiobook production.
Speaker Diarization Based on Multi-channel Microphone Array in Small-scale Meeting
Oct 26, 2022In the task of speaker diarization, the number of small-scale meetings accounts for a large proportion. When microphone arrays are employed as a recording device, its spatial information is usually ignored by most researchers. In this paper, inspired by the clustering method combining d-vector and microphone array spatial vector, we proposed a diarization method which using multi-channel microphone arrays for a meeting with no more than 4 speakers. We utilize speech enhancement to preprocess the audio from the microphone array. The Steered-Response Power Phase Transform (SRP-PHAT) algorithm are employed to get more accurate speakers, and apply the number of speakers to recluster the speech segments to achieve better performance. Finally, we fuse our system by DOVER-LAP to get the best result. We evaluated our system on the AMI corpus. Compared with the best experimental results so far, our system has achieved largely improvement in the diarization error rate (DER).
Wake Word Detection Based on Res2Net
Sep 30, 2022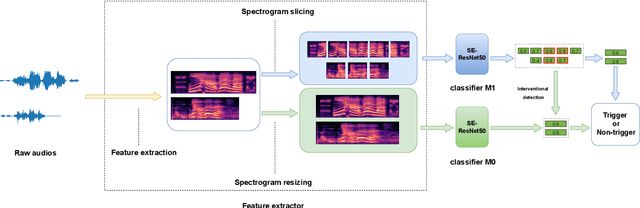
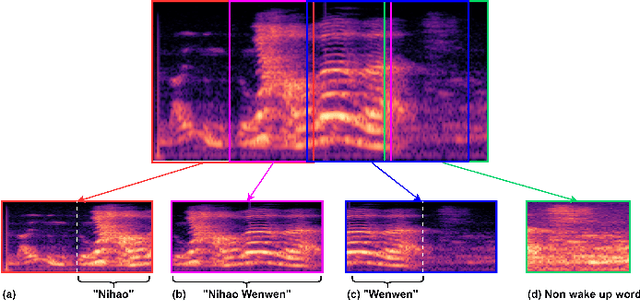
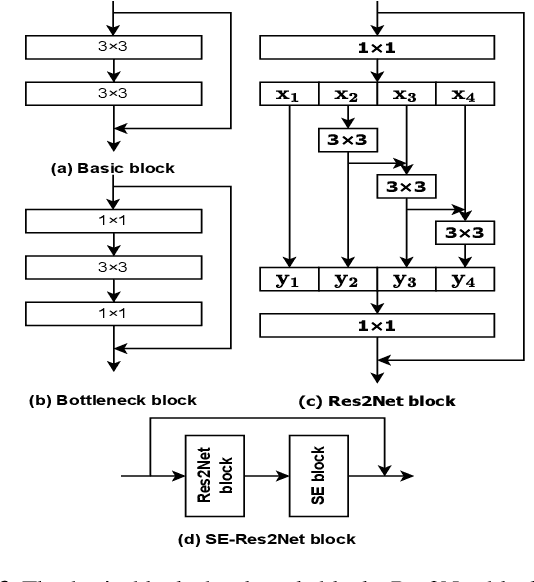
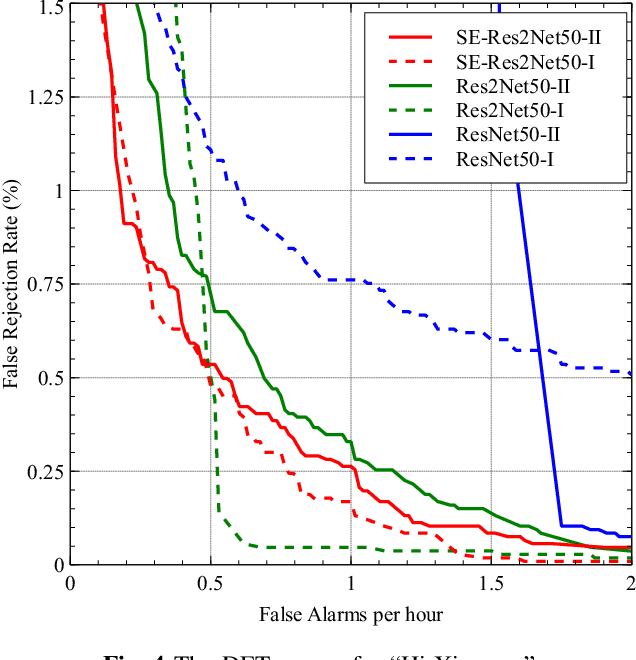
This letter proposes a new wake word detection system based on Res2Net. As a variant of ResNet, Res2Net was first applied to objection detection. Res2Net realizes multiple feature scales by increasing possible receptive fields. This multiple scaling mechanism significantly improves the detection ability of wake words with different durations. Compared with the ResNet-based model, Res2Net also significantly reduces the model size and is more suitable for detecting wake words. The proposed system can determine the positions of wake words from the audio stream without any additional assistance. The proposed method is verified on the Mobvoi dataset containing two wake words. At a false alarm rate of 0.5 per hour, the system reduced the false rejection of the two wake words by more than 12% over prior works.
Synthetic Voice Spoofing Detection Based On Online Hard Example Mining
Sep 26, 2022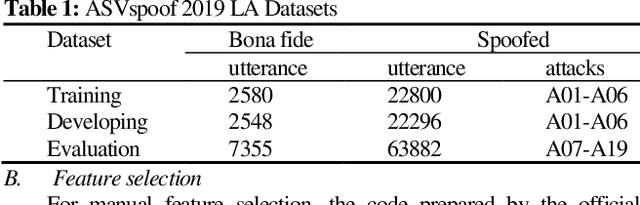

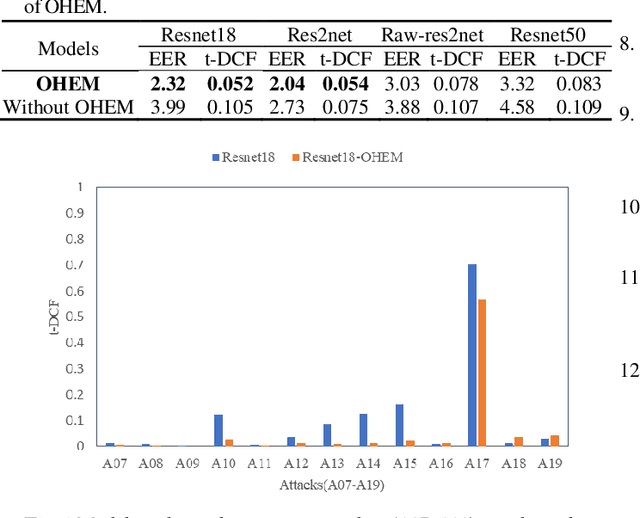
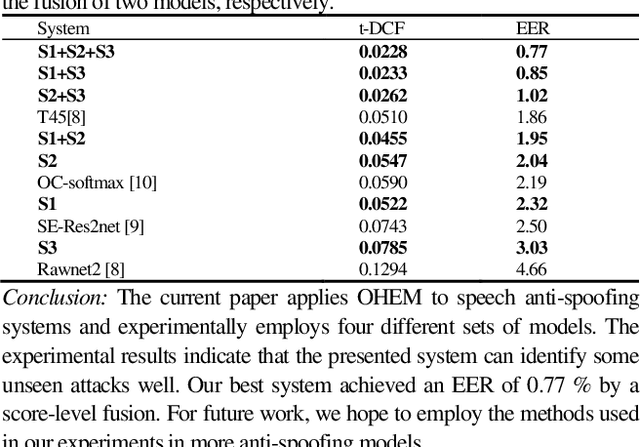
The automatic speaker verification spoofing (ASVspoof) challenge series is crucial for enhancing the spoofing consideration and the countermeasures growth. Although the recent ASVspoof 2019 validation results indicate the significant capability to identify most attacks, the model's recognition effect is still poor for some attacks. This paper presents the Online Hard Example Mining (OHEM) algorithm for detecting unknown voice spoofing attacks. The OHEM is utilized to overcome the imbalance between simple and hard samples in the dataset. The presented system provides an equal error rate (EER) of 0.77% on the ASVspoof 2019 Challenge logical access scenario's evaluation set.
The BUCEA Speaker Diarization System for the VoxCeleb Speaker Recognition Challenge 2022
Sep 20, 2022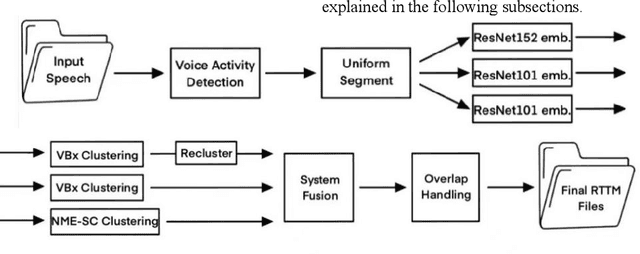
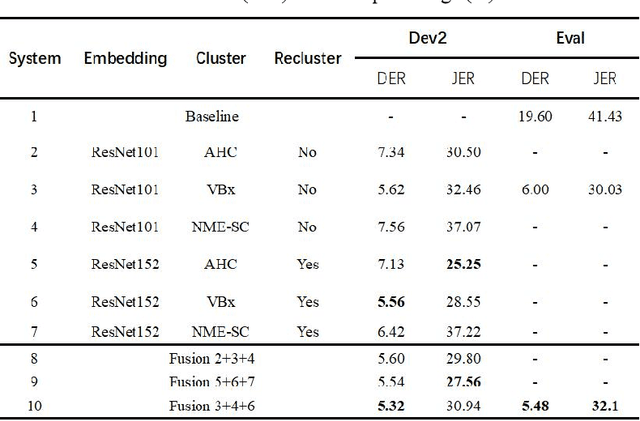
This paper describes the BUCEA speaker diarization system for the 2022 VoxCeleb Speaker Recognition Challenge. Voxsrc-22 provides the development set and test set of VoxConverse, and we mainly use the test set of VoxConverse for parameter adjustment. Our system consists of several modules, including speech activity detection (VAD), speaker embedding extractor, clustering methods, overlapping speech detection (OSD), and result fusion. Without considering overlap, the Dover-LAP (short for Diarization Output Voting Error Reduction) method was applied to system fusion, and overlapping speech detection and processing were finally carried out. Our best system achieves a diarization error rate (DER) of 5.48% and a Jaccard error rate (JER) of 32.1% on the VoxSRC 2022 evaluation set respectively.