 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Detection of Malignant Lesions in the Ovary Using Deep Learning Models and XAI
Mar 12, 2026The unrestrained proliferation of cells that are malignant in nature is cancer. In recent times, medical professionals are constantly acquiring enhanced diagnostic and treatment abilities by implementing deep learning models to analyze medical data for better clinical decision, disease diagnosis and drug discovery. A majority of cancers are studied and treated by incorporating these technologies. However, ovarian cancer remains a dilemma as it has inaccurate non-invasive detection procedures and a time consuming, invasive procedure for accurate detection. Thus, in this research, several Convolutional Neural Networks such as LeNet-5, ResNet, VGGNet and GoogLeNet/Inception have been utilized to develop 15 variants and choose a model that accurately detects and identifies ovarian cancer. For effective model training, the dataset OvarianCancer&SubtypesDatasetHistopathology from Mendeley has been used. After constructing a model, we utilized Explainable Artificial Intelligence (XAI) models such as LIME, Integrated Gradients and SHAP to explain the black box outcome of the selected model. For evaluating the performance of the model, Accuracy, Precision, Recall, F1-Score, ROC Curve and AUC have been used. From the evaluation, it was seen that the slightly compact InceptionV3 model with ReLu had the overall best result achieving an average score of 94% across all the performance metrics in the augmented dataset. Lastly for XAI, the three aforementioned XAI have been used for an overall comparative analysis. It is the aim of this research that the contributions of the study will help in achieving a better detection method for ovarian cancer.
* Accepted and published at ICAIC 2025. Accepted version
From Scarcity to Capability: Empowering Fake News Detection in Low-Resource Languages with LLMs
Jan 16, 2025
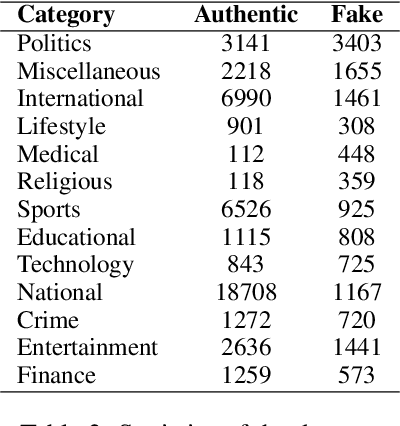

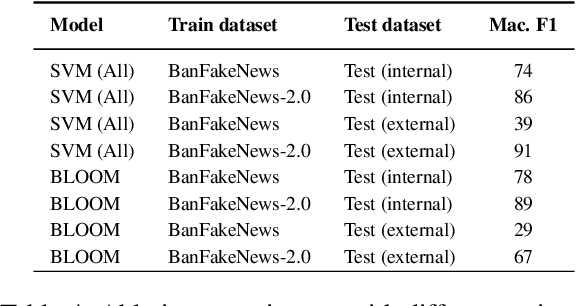
The rapid spread of fake news presents a significant global challenge, particularly in low-resource languages like Bangla, which lack adequate datasets and detection tools. Although manual fact-checking is accurate, it is expensive and slow to prevent the dissemination of fake news. Addressing this gap, we introduce BanFakeNews-2.0, a robust dataset to enhance Bangla fake news detection. This version includes 11,700 additional, meticulously curated fake news articles validated from credible sources, creating a proportional dataset of 47,000 authentic and 13,000 fake news items across 13 categories. In addition, we created a manually curated independent test set of 460 fake and 540 authentic news items for rigorous evaluation. We invest efforts in collecting fake news from credible sources and manually verified while preserving the linguistic richness. We develop a benchmark system utilizing transformer-based architectures, including fine-tuned Bidirectional Encoder Representations from Transformers variants (F1-87\%) and Large Language Models with Quantized Low-Rank Approximation (F1-89\%), that significantly outperforms traditional methods. BanFakeNews-2.0 offers a valuable resource to advance research and application in fake news detection for low-resourced languages. We publicly release our dataset and model on Github to foster research in this direction.
Designing Cellular Manufacturing System in Presence of Alternative Process Plans
Nov 22, 2024



In the design of cellular manufacturing systems (CMS), numerous technological and managerial decisions must be made at both the design and operational stages. The first step in designing a CMS involves grouping parts and machines. In this paper, four integer programming formulations are presented for grouping parts and machines in a CMS at both the design and operational levels for a generalized grouping problem, where each part has more than one process plan, and each operation of a process plan can be performed on more than one machine. The minimization of inter-cell and intra-cell movements is achieved by assigning the maximum possible number of consecutive operations of a part type to the same cell and to the same machine, respectively. The suitability of minimizing inter-cell and intra-cell movements as an objective, compared to other objectives such as minimizing investment costs on machines, operating costs, etc., is discussed. Numerical examples are included to illustrate the workings of the formulations.
Solving Generalized Grouping Problems in Cellular Manufacturing Systems Using a Network Flow Model
Nov 07, 2024



This paper focuses on the generalized grouping problem in the context of cellular manufacturing systems (CMS), where parts may have more than one process route. A process route lists the machines corresponding to each part of the operation. Inspired by the extensive and widespread use of network flow algorithms, this research formulates the process route family formation for generalized grouping as a unit capacity minimum cost network flow model. The objective is to minimize dissimilarity (based on the machines required) among the process routes within a family. The proposed model optimally solves the process route family formation problem without pre-specifying the number of part families to be formed. The process route of family formation is the first stage in a hierarchical procedure. For the second stage (machine cell formation), two procedures, a quadratic assignment programming (QAP) formulation and a heuristic procedure, are proposed. The QAP simultaneously assigns process route families and machines to a pre-specified number of cells in such a way that total machine utilization is maximized. The heuristic procedure for machine cell formation is hierarchical in nature. Computational results for some test problems show that the QAP and the heuristic procedure yield the same results.
ChatGPT in Research and Education: Exploring Benefits and Threats
Nov 05, 2024



In recent years, advanced artificial intelligence technologies, such as ChatGPT, have significantly impacted various fields, including education and research. Developed by OpenAI, ChatGPT is a powerful language model that presents numerous opportunities for students and educators. It offers personalized feedback, enhances accessibility, enables interactive conversations, assists with lesson preparation and evaluation, and introduces new methods for teaching complex subjects. However, ChatGPT also poses challenges to traditional education and research systems. These challenges include the risk of cheating on online exams, the generation of human-like text that may compromise academic integrity, a potential decline in critical thinking skills, and difficulties in assessing the reliability of information generated by AI. This study examines both the opportunities and challenges ChatGPT brings to education from the perspectives of students and educators. Specifically, it explores the role of ChatGPT in helping students develop their subjective skills. To demonstrate its effectiveness, we conducted several subjective experiments using ChatGPT, such as generating solutions from subjective problem descriptions. Additionally, surveys were conducted with students and teachers to gather insights into how ChatGPT supports subjective learning and teaching. The results and analysis of these surveys are presented to highlight the impact of ChatGPT in this context.
Optimizing Container Loading and Unloading through Dual-Cycling and Dockyard Rehandle Reduction Using a Hybrid Genetic Algorithm
Jun 12, 2024



This paper addresses the optimization of container unloading and loading operations at ports, integrating quay-crane dual-cycling with dockyard rehandle minimization. We present a unified model encompassing both operations: ship container unloading and loading by quay crane, and the other is reducing dockyard rehandles while loading the ship. We recognize that optimizing one aspect in isolation can lead to suboptimal outcomes due to interdependencies. Specifically, optimizing unloading sequences for minimal operation time may inadvertently increase dockyard rehandles during loading and vice versa. To address this NP-hard problem, we propose a hybrid genetic algorithm (GA) QCDC-DR-GA comprising one-dimensional and two-dimensional GA components. Our model, QCDC-DR-GA, consistently outperforms four state-of-the-art methods in maximizing dual cycles and minimizing dockyard rehandles. Compared to those methods, it reduced 15-20% of total operation time for large vessels. Statistical validation through a two-tailed paired t-test confirms the superiority of QCDC-DR-GA at a 5% significance level. The approach effectively combines QCDC optimization with dockyard rehandle minimization, optimizing the total unloading-loading time. Results underscore the inefficiency of separately optimizing QCDC and dockyard rehandles. Fragmented approaches, such as QCDC Scheduling Optimized by bi-level GA and GA-ILSRS (Scenario 2), show limited improvement compared to QCDC-DR-GA. As in GA-ILSRS (Scenario 1), neglecting dual-cycle optimization leads to inferior performance than QCDC-DR-GA. This emphasizes the necessity of simultaneously considering both aspects for optimal resource utilization and overall operational efficiency.
Analysis of Internet of Things implementation barriers in the cold supply chain: an integrated ISM-MICMAC and DEMATEL approach
Feb 07, 2024



Integrating Internet of Things (IoT) technology inside the cold supply chain can enhance transparency, efficiency, and quality, optimizing operating procedures and increasing productivity. The integration of IoT in this complicated setting is hindered by specific barriers that need a thorough examination. Prominent barriers to IoT implementation in the cold supply chain are identified using a two-stage model. After reviewing the available literature on the topic of IoT implementation, a total of 13 barriers were found. The survey data was cross-validated for quality, and Cronbach's alpha test was employed to ensure validity. This research applies the interpretative structural modeling technique in the first phase to identify the main barriers. Among those barriers, "regularity compliance" and "cold chain networks" are key drivers for IoT adoption strategies. MICMAC's driving and dependence power element categorization helps evaluate the barrier interactions. In the second phase of this research, a decision-making trial and evaluation laboratory methodology was employed to identify causal relationships between barriers and evaluate them according to their relative importance. Each cause is a potential drive, and if its efficiency can be enhanced, the system as a whole benefits. The research findings provide industry stakeholders, governments, and organizations with significant drivers of IoT adoption to overcome these barriers and optimize the utilization of IoT technology to improve the effectiveness and reliability of the cold supply chain.
QAmplifyNet: Pushing the Boundaries of Supply Chain Backorder Prediction Using Interpretable Hybrid Quantum - Classical Neural Network
Jul 24, 2023Supply chain management relies on accurate backorder prediction for optimizing inventory control, reducing costs, and enhancing customer satisfaction. However, traditional machine-learning models struggle with large-scale datasets and complex relationships, hindering real-world data collection. This research introduces a novel methodological framework for supply chain backorder prediction, addressing the challenge of handling large datasets. Our proposed model, QAmplifyNet, employs quantum-inspired techniques within a quantum-classical neural network to predict backorders effectively on short and imbalanced datasets. Experimental evaluations on a benchmark dataset demonstrate QAmplifyNet's superiority over classical models, quantum ensembles, quantum neural networks, and deep reinforcement learning. Its proficiency in handling short, imbalanced datasets makes it an ideal solution for supply chain management. To enhance model interpretability, we use Explainable Artificial Intelligence techniques. Practical implications include improved inventory control, reduced backorders, and enhanced operational efficiency. QAmplifyNet seamlessly integrates into real-world supply chain management systems, enabling proactive decision-making and efficient resource allocation. Future work involves exploring additional quantum-inspired techniques, expanding the dataset, and investigating other supply chain applications. This research unlocks the potential of quantum computing in supply chain optimization and paves the way for further exploration of quantum-inspired machine learning models in supply chain management. Our framework and QAmplifyNet model offer a breakthrough approach to supply chain backorder prediction, providing superior performance and opening new avenues for leveraging quantum-inspired techniques in supply chain management.
Ranking the locations and predicting future crime occurrence by retrieving news from different Bangla online newspapers
May 18, 2023



There have thousands of crimes are happening daily all around. But people keep statistics only few of them, therefore crime rates are increasing day by day. The reason behind can be less concern or less statistics of previous crimes. It is much more important to observe the previous crime statistics for general people to make their outing decision and police for catching the criminals are taking steps to restrain the crimes and tourists to make their travelling decision. National institute of justice releases crime survey data for the country, but does not offer crime statistics up to Union or Thana level. Considering all of these cases we have come up with an approach which can give an approximation to people about the safety of a specific location with crime ranking of different areas locating the crimes on a map including a future crime occurrence prediction mechanism. Our approach relies on different online Bangla newspapers for crawling the crime data, stemming and keyword extraction, location finding algorithm, cosine similarity, naive Bayes classifier, and a custom crime prediction model
Multi-Classification of Brain Tumor Images Using Transfer Learning Based Deep Neural Network
Jun 17, 2022
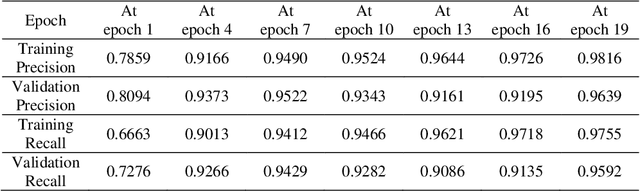
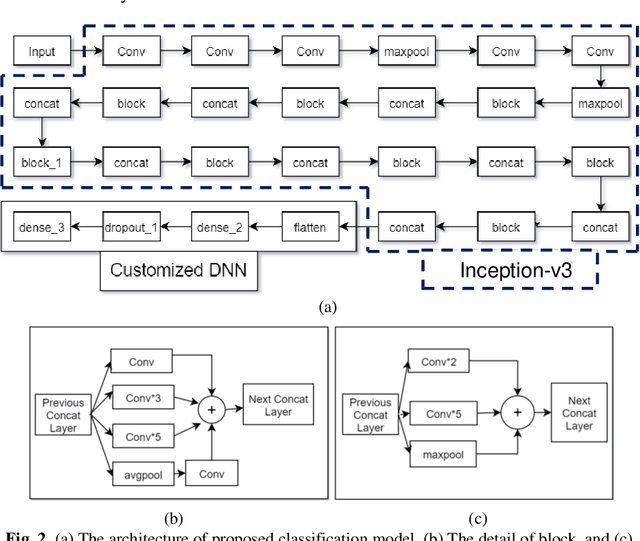

In recent advancement towards computer based diagnostics system, the classification of brain tumor images is a challenging task. This paper mainly focuses on elevating the classification accuracy of brain tumor images with transfer learning based deep neural network. The classification approach is started with the image augmentation operation including rotation, zoom, hori-zontal flip, width shift, height shift, and shear to increase the diversity in image datasets. Then the general features of the input brain tumor images are extracted based on a pre-trained transfer learning method comprised of Inception-v3. Fi-nally, the deep neural network with 4 customized layers is employed for classi-fying the brain tumors in most frequent brain tumor types as meningioma, glioma, and pituitary. The proposed model acquires an effective performance with an overall accuracy of 96.25% which is much improved than some existing multi-classification methods. Whereas, the fine-tuning of hyper-parameters and inclusion of customized DNN with the Inception-v3 model results in an im-provement of the classification accuracy.
* 7 pages, 4 figures, 2 tables, International Virtual Conference on ARTIFICIAL INTELLIGENCE FOR SMART COMMUNITY, Malaysia