 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Non-Standard Vietnamese Word Detection and Normalization for Text-to-Speech
Sep 07, 2022
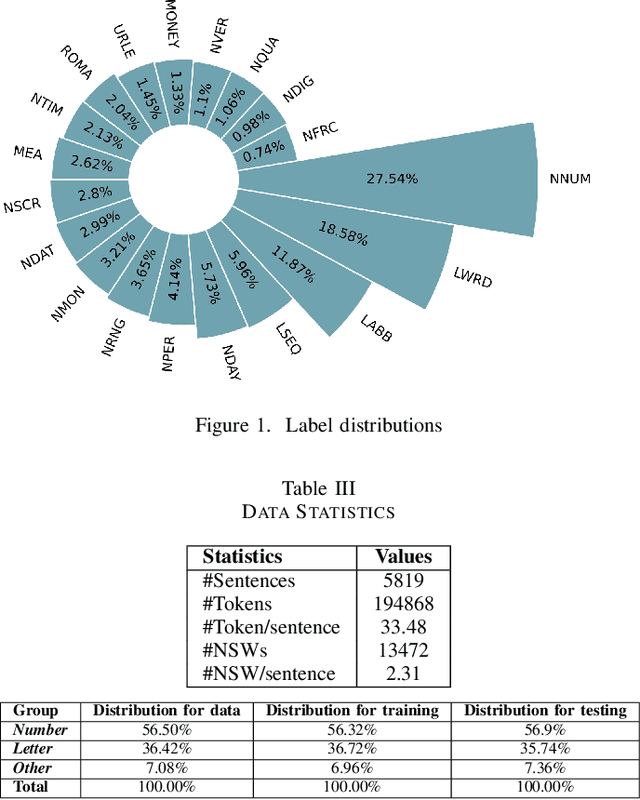
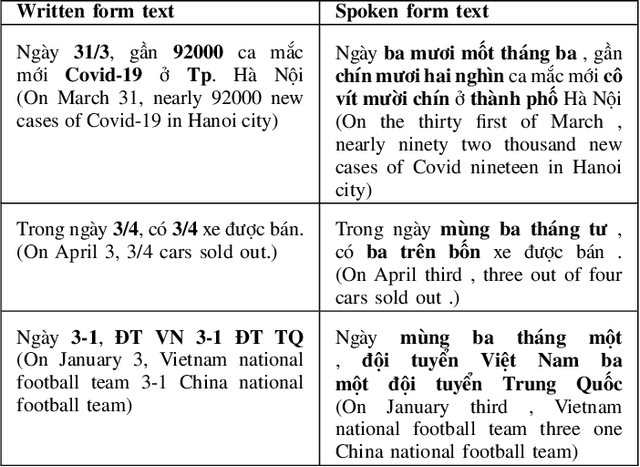

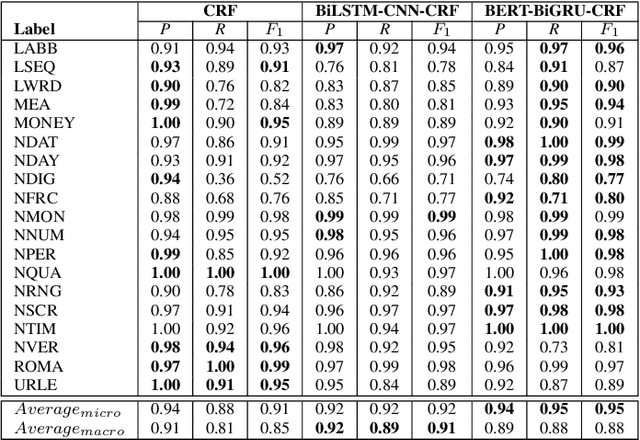
Converting written texts into their spoken forms is an essential problem in any text-to-speech (TTS) systems. However, building an effective text normalization solution for a real-world TTS system face two main challenges: (1) the semantic ambiguity of non-standard words (NSWs), e.g., numbers, dates, ranges, scores, abbreviations, and (2) transforming NSWs into pronounceable syllables, such as URL, email address, hashtag, and contact name. In this paper, we propose a new two-phase normalization approach to deal with these challenges. First, a model-based tagger is designed to detect NSWs. Then, depending on NSW types, a rule-based normalizer expands those NSWs into their final verbal forms. We conducted three empirical experiments for NSW detection using Conditional Random Fields (CRFs), BiLSTM-CNN-CRF, and BERT-BiGRU-CRF models on a manually annotated dataset including 5819 sentences extracted from Vietnamese news articles. In the second phase, we propose a forward lexicon-based maximum matching algorithm to split down the hashtag, email, URL, and contact name. The experimental results of the tagging phase show that the average F1 scores of the BiLSTM-CNN-CRF and CRF models are above 90.00%, reaching the highest F1 of 95.00% with the BERT-BiGRU-CRF model. Overall, our approach has low sentence error rates, at 8.15% with CRF and 7.11% with BiLSTM-CNN-CRF taggers, and only 6.67% with BERT-BiGRU-CRF tagger.
Wav2vec-Switch: Contrastive Learning from Original-noisy Speech Pairs for Robust Speech Recognition
Oct 11, 2021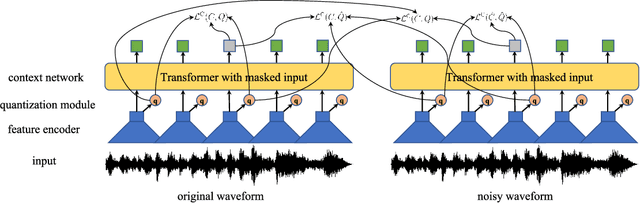
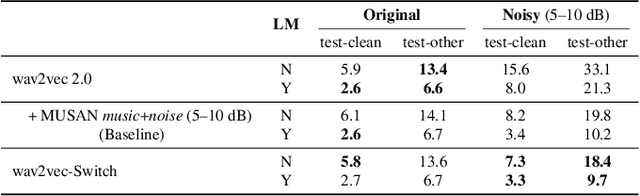
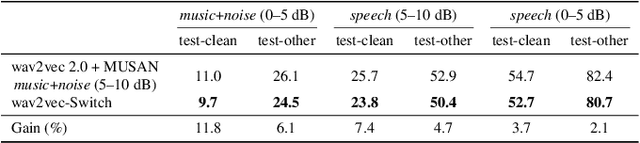

The goal of self-supervised learning (SSL) for automatic speech recognition (ASR) is to learn good speech representations from a large amount of unlabeled speech for the downstream ASR task. However, most SSL frameworks do not consider noise robustness which is crucial for real-world applications. In this paper we propose wav2vec-Switch, a method to encode noise robustness into contextualized representations of speech via contrastive learning. Specifically, we feed original-noisy speech pairs simultaneously into the wav2vec 2.0 network. In addition to the existing contrastive learning task, we switch the quantized representations of the original and noisy speech as additional prediction targets of each other. By doing this, it enforces the network to have consistent predictions for the original and noisy speech, thus allows to learn contextualized representation with noise robustness. Our experiments on synthesized and real noisy data show the effectiveness of our method: it achieves 2.9--4.9% relative word error rate (WER) reduction on the synthesized noisy LibriSpeech data without deterioration on the original data, and 5.7% on CHiME-4 real 1-channel noisy data compared to a data augmentation baseline even with a strong language model for decoding. Our results on CHiME-4 can match or even surpass those with well-designed speech enhancement components.
Towards Error-Resilient Neural Speech Coding
Jul 03, 2022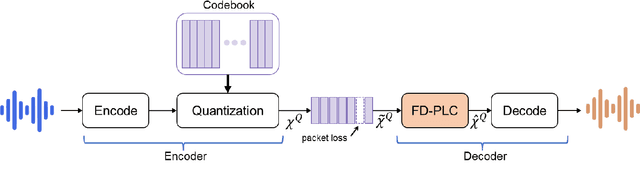
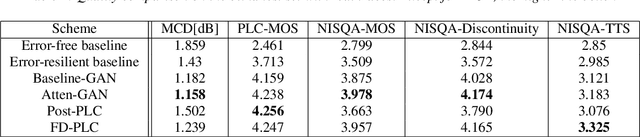

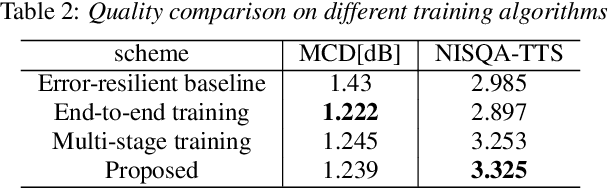
Neural audio coding has shown very promising results recently in the literature to largely outperform traditional codecs but limited attention has been paid on its error resilience. Neural codecs trained considering only source coding tend to be extremely sensitive to channel noises, especially in wireless channels with high error rate. In this paper, we investigate how to elevate the error resilience of neural audio codecs for packet losses that often occur during real-time communications. We propose a feature-domain packet loss concealment algorithm (FD-PLC) for real-time neural speech coding. Specifically, we introduce a self-attention-based module on the received latent features to recover lost frames in the feature domain before the decoder. A hybrid segment-level and frame-level frequency-domain discriminator is employed to guide the network to focus on both the generative quality of lost frames and the continuity with neighbouring frames. Experimental results on several error patterns show that the proposed scheme can achieve better robustness compared with the corresponding error-free and error-resilient baselines. We also show that feature-domain concealment is superior to waveform-domain counterpart as post-processing.
Large-Scale Streaming End-to-End Speech Translation with Neural Transducers
Apr 11, 2022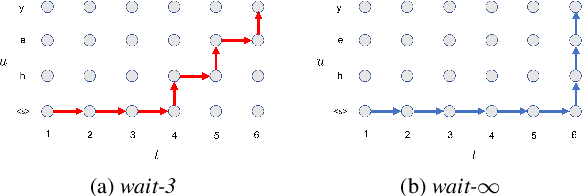
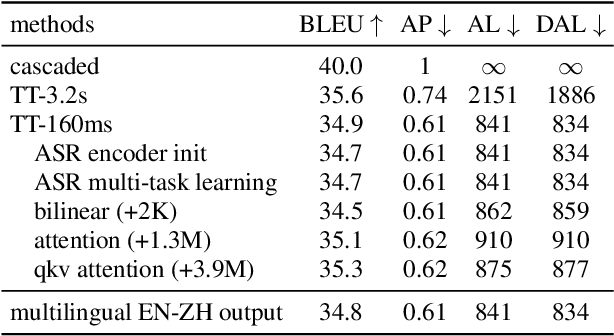
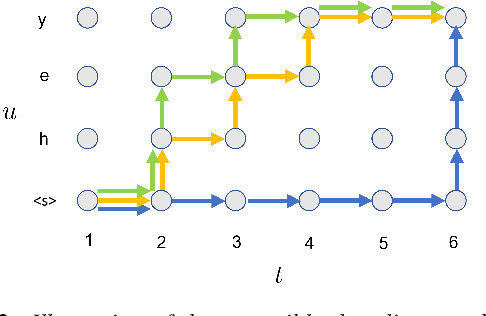
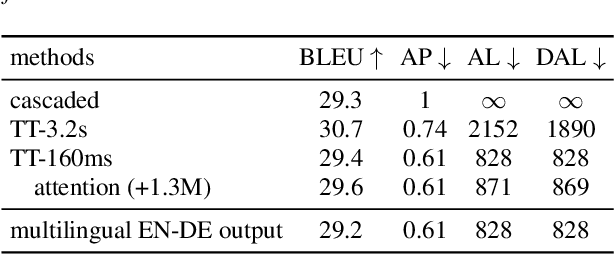
Neural transducers have been widely used in automatic speech recognition (ASR). In this paper, we introduce it to streaming end-to-end speech translation (ST), which aims to convert audio signals to texts in other languages directly. Compared with cascaded ST that performs ASR followed by text-based machine translation (MT), the proposed Transformer transducer (TT)-based ST model drastically reduces inference latency, exploits speech information, and avoids error propagation from ASR to MT. To improve the modeling capacity, we propose attention pooling for the joint network in TT. In addition, we extend TT-based ST to multilingual ST, which generates texts of multiple languages at the same time. Experimental results on a large-scale 50 thousand (K) hours pseudo-labeled training set show that TT-based ST not only significantly reduces inference time but also outperforms non-streaming cascaded ST for English-German translation.
SpeechSplit 2.0: Unsupervised speech disentanglement for voice conversion Without tuning autoencoder Bottlenecks
Mar 26, 2022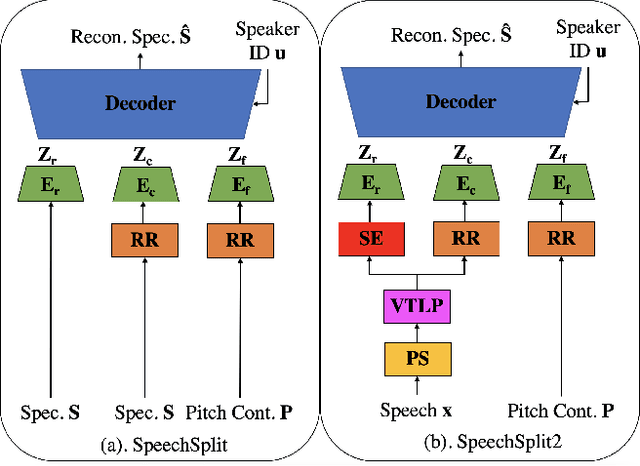
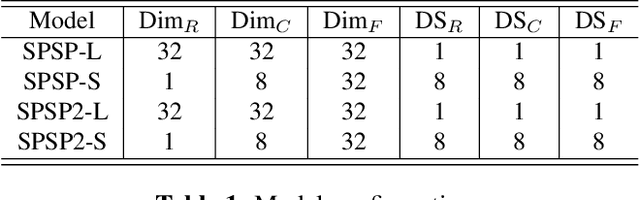
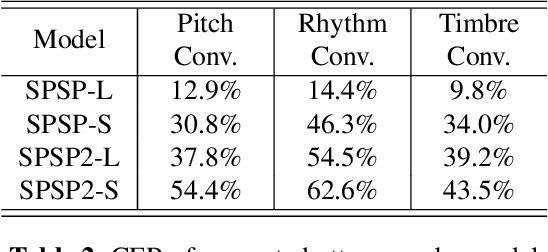
SpeechSplit can perform aspect-specific voice conversion by disentangling speech into content, rhythm, pitch, and timbre using multiple autoencoders in an unsupervised manner. However, SpeechSplit requires careful tuning of the autoencoder bottlenecks, which can be time-consuming and less robust. This paper proposes SpeechSplit 2.0, which constrains the information flow of the speech component to be disentangled on the autoencoder input using efficient signal processing methods instead of bottleneck tuning. Evaluation results show that SpeechSplit 2.0 achieves comparable performance to SpeechSplit in speech disentanglement and superior robustness to the bottleneck size variations. Our code is available at https://github.com/biggytruck/SpeechSplit2.
An Investigation of Indian Native Language Phonemic Influences on L2 English Pronunciations
Dec 19, 2022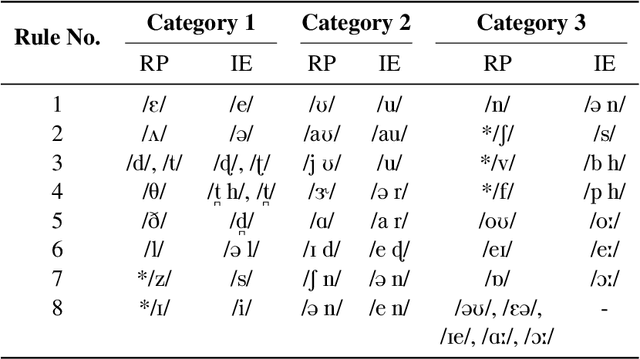
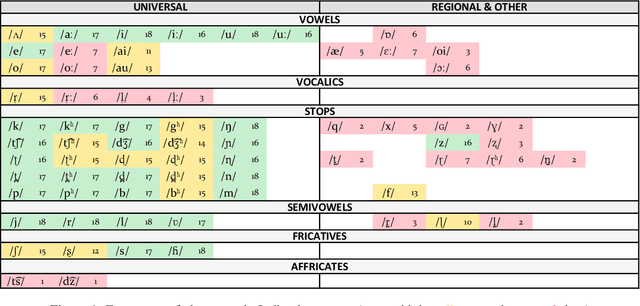
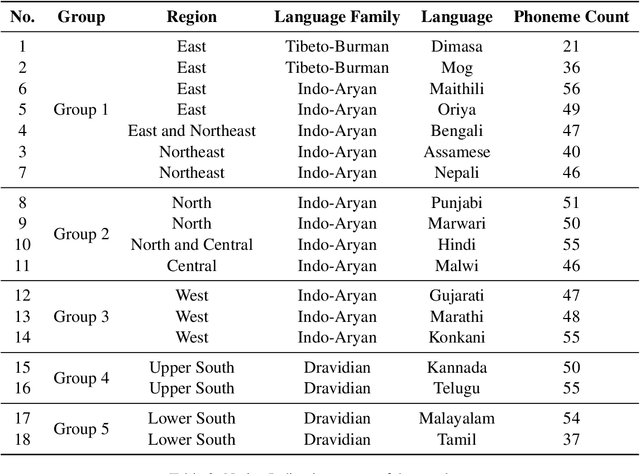
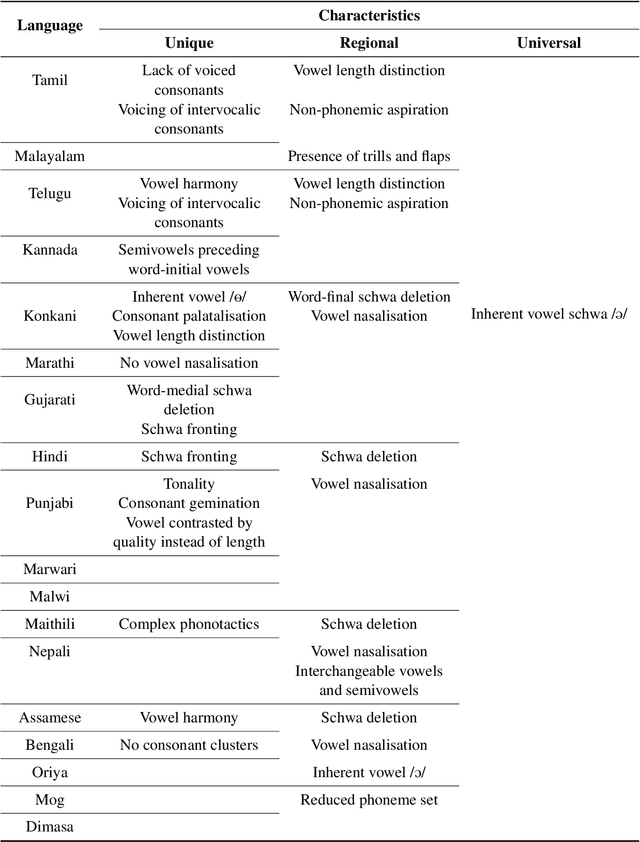
Speech systems are sensitive to accent variations. This is especially challenging in the Indian context, with an abundance of languages but a dearth of linguistic studies characterising pronunciation variations. The growing number of L2 English speakers in India reinforces the need to study accents and L1-L2 interactions. We investigate the accents of Indian English (IE) speakers and report in detail our observations, both specific and common to all regions. In particular, we observe the phonemic variations and phonotactics occurring in the speakers' native languages and apply this to their English pronunciations. We demonstrate the influence of 18 Indian languages on IE by comparing the native language pronunciations with IE pronunciations obtained jointly from existing literature studies and phonetically annotated speech of 80 speakers. Consequently, we are able to validate the intuitions of Indian language influences on IE pronunciations by justifying pronunciation rules from the perspective of Indian language phonology. We obtain a comprehensive description in terms of universal and region-specific characteristics of IE, which facilitates accent conversion and adaptation of existing ASR and TTS systems to different Indian accents.
Dysfluencies Seldom Come Alone -- Detection as a Multi-Label Problem
Oct 28, 2022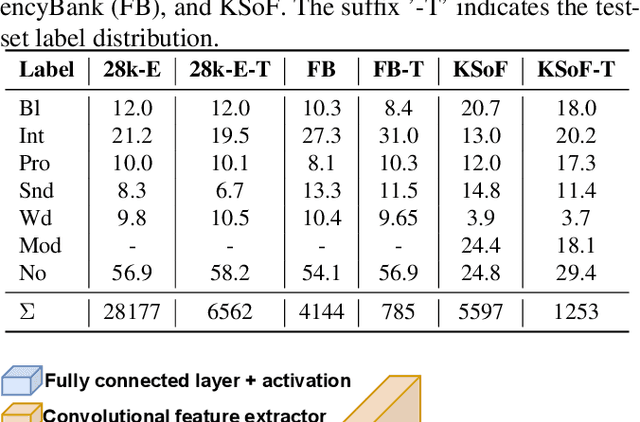
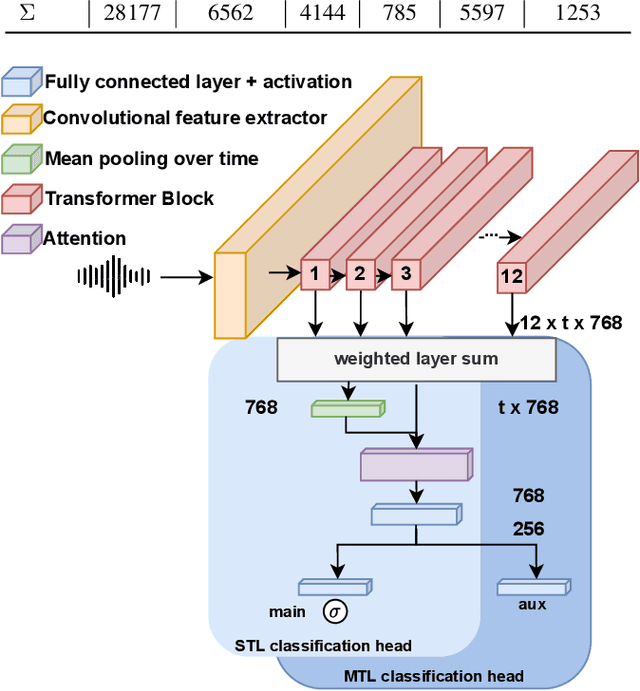
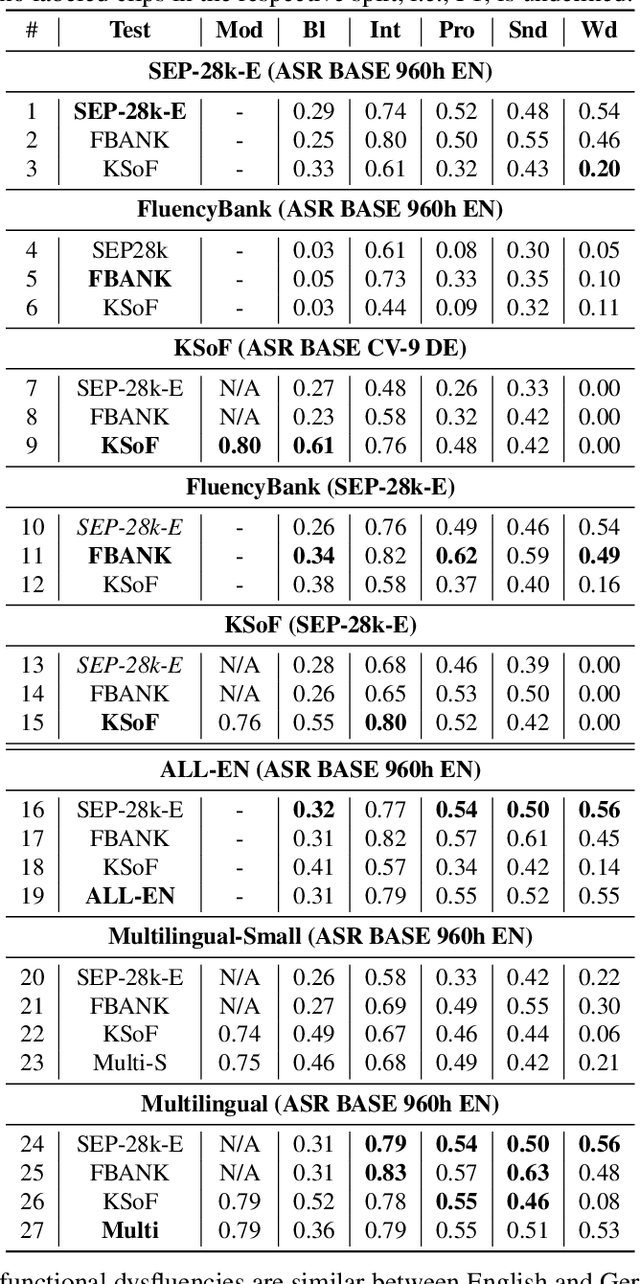
Specially adapted speech recognition models are necessary to handle stuttered speech. For these to be used in a targeted manner, stuttered speech must be reliably detected. Recent works have treated stuttering as a multi-class classification problem or viewed detecting each dysfluency type as an isolated task; that does not capture the nature of stuttering, where one dysfluency seldom comes alone, i.e., co-occurs with others. This work explores an approach based on a modified wav2vec 2.0 system for end-to-end stuttering detection and classification as a multi-label problem. The method is evaluated on combinations of three datasets containing English and German stuttered speech, yielding state-of-the-art results for stuttering detection on the SEP-28k-Extended dataset. Experimental results provide evidence for the transferability of features and the generalizability of the method across datasets and languages.
TTS-by-TTS 2: Data-selective augmentation for neural speech synthesis using ranking support vector machine with variational autoencoder
Jun 30, 2022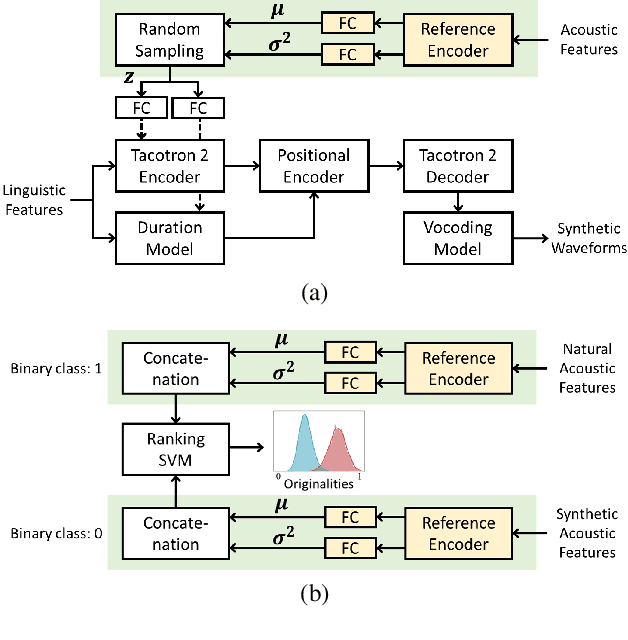

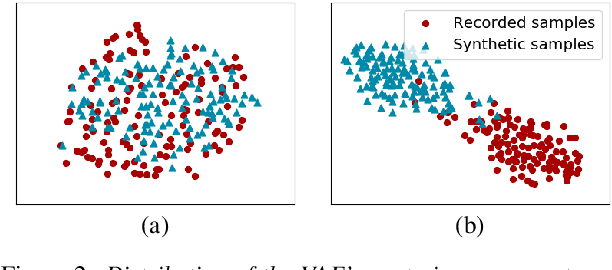
Recent advances in synthetic speech quality have enabled us to train text-to-speech (TTS) systems by using synthetic corpora. However, merely increasing the amount of synthetic data is not always advantageous for improving training efficiency. Our aim in this study is to selectively choose synthetic data that are beneficial to the training process. In the proposed method, we first adopt a variational autoencoder whose posterior distribution is utilized to extract latent features representing acoustic similarity between the recorded and synthetic corpora. By using those learned features, we then train a ranking support vector machine (RankSVM) that is well known for effectively ranking relative attributes among binary classes. By setting the recorded and synthetic ones as two opposite classes, RankSVM is used to determine how the synthesized speech is acoustically similar to the recorded data. Then, synthetic TTS data, whose distribution is close to the recorded data, are selected from large-scale synthetic corpora. By using these data for retraining the TTS model, the synthetic quality can be significantly improved. Objective and subjective evaluation results show the superiority of the proposed method over the conventional methods.
Practical cognitive speech compression
Mar 08, 2022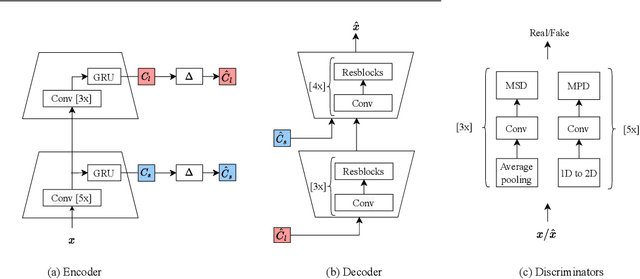
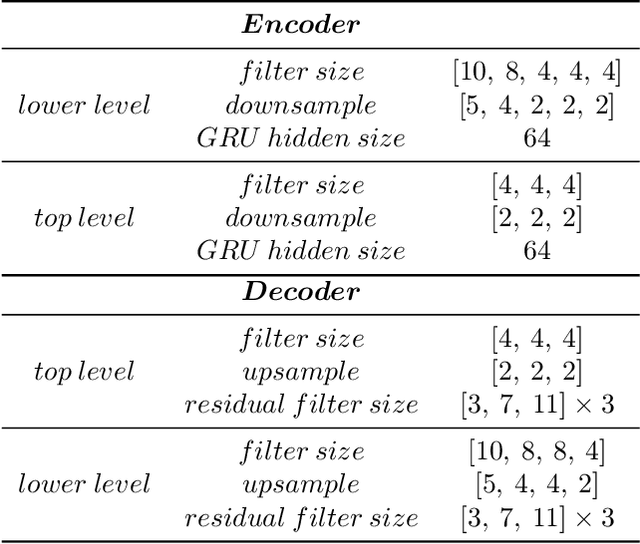
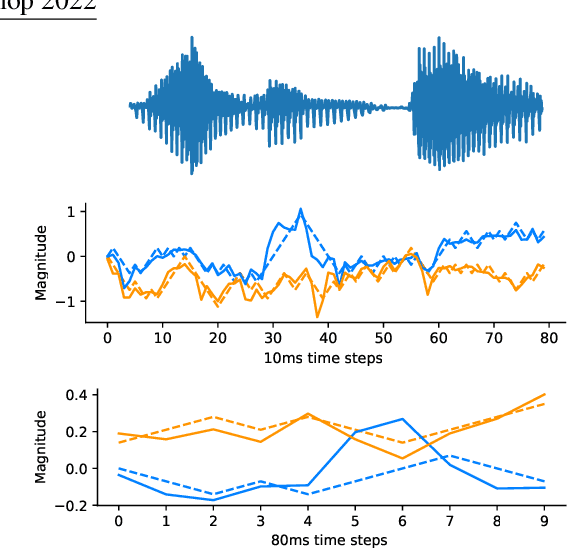
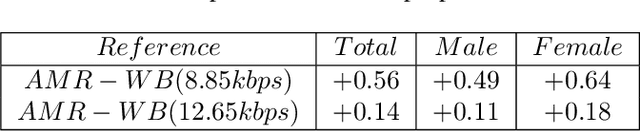
This paper presents a new neural speech compression method that is practical in the sense that it operates at low bitrate, introduces a low latency, is compatible in computational complexity with current mobile devices, and provides a subjective quality that is comparable to that of standard mobile-telephony codecs. Other recently proposed neural vocoders also have the ability to operate at low bitrate. However, they do not produce the same level of subjective quality as standard codecs. On the other hand, standard codecs rely on objective and short-term metrics such as the segmental signal-to-noise ratio that correlate only weakly with perception. Furthermore, standard codecs are less efficient than unsupervised neural networks at capturing speech attributes, especially long-term ones. The proposed method combines a cognitive-coding encoder that extracts an interpretable unsupervised hierarchical representation with a multi stage decoder that has a GAN-based architecture. We observe that this method is very robust to the quantization of representation features. An AB test was conducted on a subset of the Harvard sentences that are commonly used to evaluate standard mobile-telephony codecs. The results show that the proposed method outperforms the standard AMR-WB codec in terms of delay, bitrate and subjective quality.
GigaST: A 10,000-hour Pseudo Speech Translation Corpus
Apr 08, 2022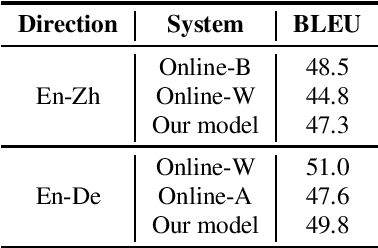
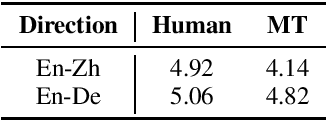
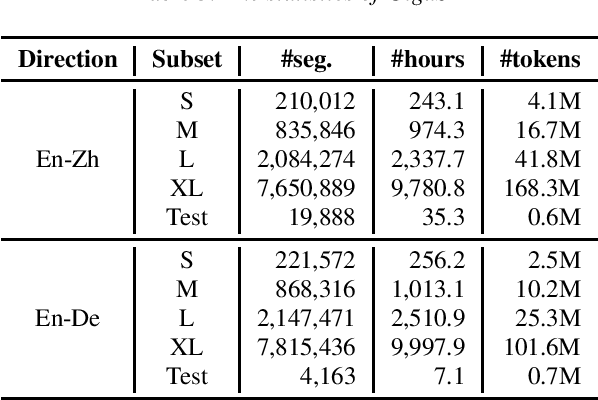
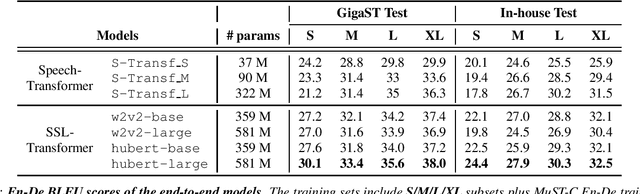
This paper introduces GigaST, a large-scale pseudo speech translation (ST) corpus. We create the corpus by translating the text in GigaSpeech, an English ASR corpus, into German and Chinese. The training set is translated by a strong machine translation system and the test set is translated by human. ST models trained with an addition of our corpus obtain new state-of-the-art results on the MuST-C English-German benchmark test set. We provide a detailed description of the translation process and verify its quality. We make the translated text data public and hope to facilitate research in speech translation. Additionally, we also release the training scripts on NeurST to make it easy to replicate our systems. GigaST dataset is available at https://st-benchmark.github.io/resources/GigaST.