 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Bit Transmission of Adaptive Pre- and De-emphasis Filters for Speech and Audio Coding
Jul 02, 2024



This paper introduces a novel adaptation approach for first-order pre- and de-emphasis filters, an essential tool in many speech and audio codecs to increase coding efficiency and perceived quality. The proposed zero-bit self-adaptation approach differs from classical forward and backward adaptation approaches in that the de-emphasis coefficient is estimated at the receiver, from the decoded pre-emphasized signal. This eliminates the need to transmit information that arises from forward adaptation as well as the signal-filter lag that is inherent in backward adaptation. Evaluation results show that the de-emphasis coefficient can be estimated accurately from the decoded pre-emphasized signal and that the proposed zero-bit self-adaptation approach provides comparable subjective improvement to forward adaptation.
Practical cognitive speech compression
Mar 08, 2022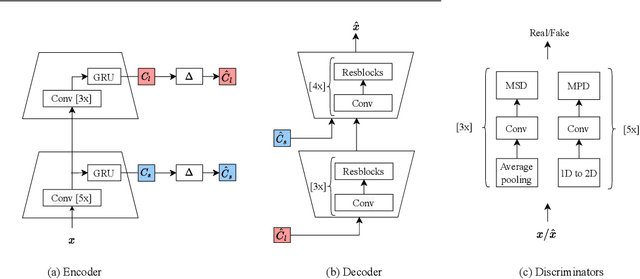
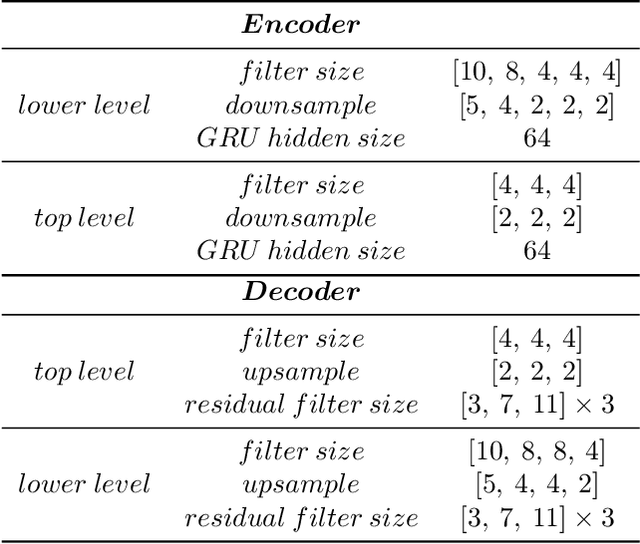
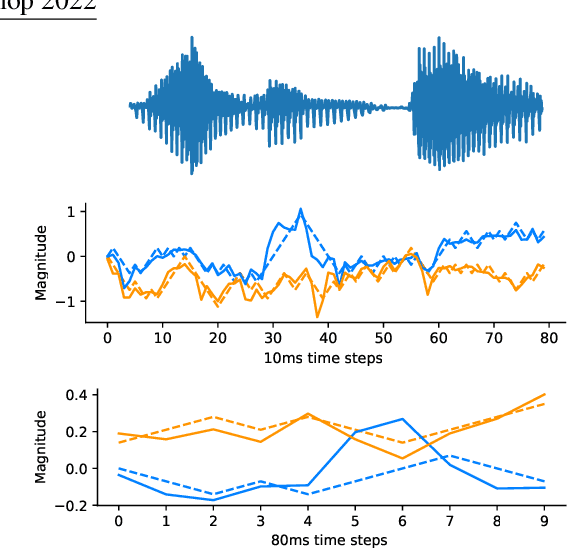
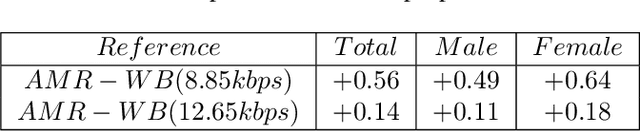
This paper presents a new neural speech compression method that is practical in the sense that it operates at low bitrate, introduces a low latency, is compatible in computational complexity with current mobile devices, and provides a subjective quality that is comparable to that of standard mobile-telephony codecs. Other recently proposed neural vocoders also have the ability to operate at low bitrate. However, they do not produce the same level of subjective quality as standard codecs. On the other hand, standard codecs rely on objective and short-term metrics such as the segmental signal-to-noise ratio that correlate only weakly with perception. Furthermore, standard codecs are less efficient than unsupervised neural networks at capturing speech attributes, especially long-term ones. The proposed method combines a cognitive-coding encoder that extracts an interpretable unsupervised hierarchical representation with a multi stage decoder that has a GAN-based architecture. We observe that this method is very robust to the quantization of representation features. An AB test was conducted on a subset of the Harvard sentences that are commonly used to evaluate standard mobile-telephony codecs. The results show that the proposed method outperforms the standard AMR-WB codec in terms of delay, bitrate and subjective quality.
Speech Prediction using an Adaptive Recurrent Neural Network with Application to Packet Loss Concealment
Nov 15, 2021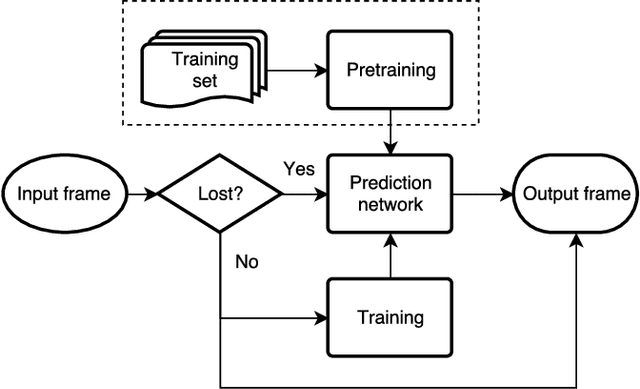
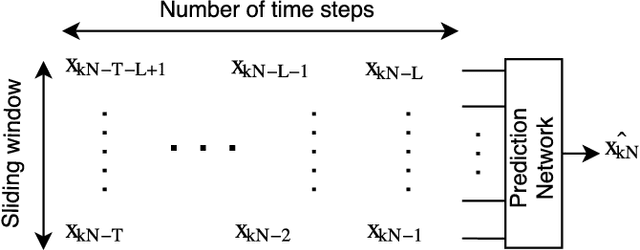
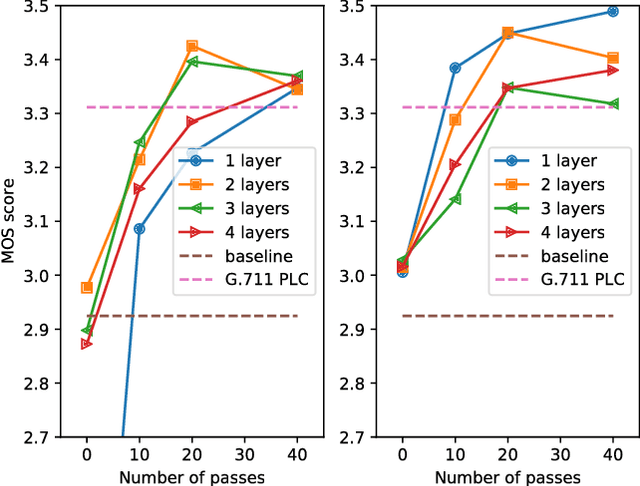
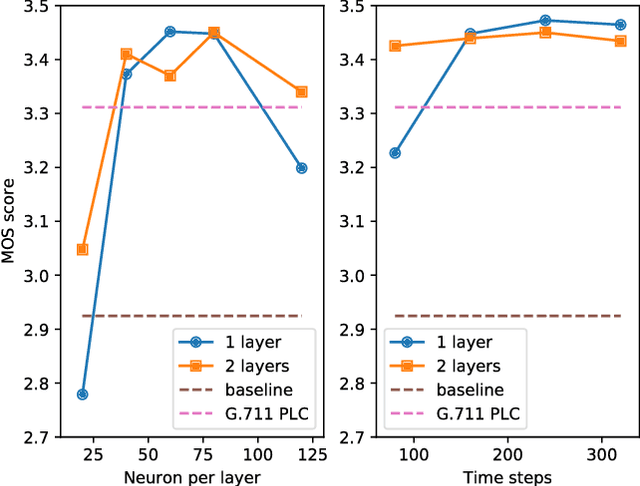
This paper proposes a novel approach for speech signal prediction based on a recurrent neural network (RNN). Unlike existing RNN-based predictors, which operate on parametric features and are trained offline on a large collection of such features, the proposed predictor operates directly on speech samples and is trained online on the recent past of the speech signal. Optionally, the network can be pre-trained offline to speed-up convergence at start-up. The proposed predictor is a single end-to-end network that captures all sorts of dependencies between samples, and therefore has the potential to outperform classical linear/non-linear and short-term/long-term speech predictor structures. We apply it to the packet loss concealment (PLC) problem and show that it outperforms the standard ITU G.711 Appendix I PLC technique.
Biologically inspired speech emotion recognition
Nov 15, 2021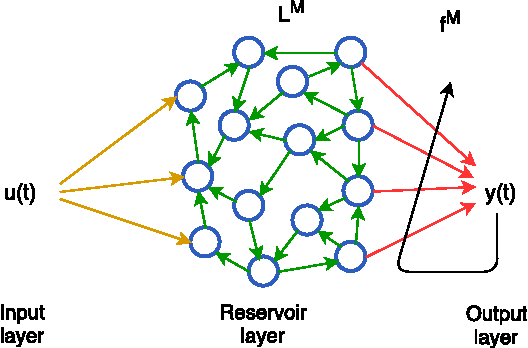
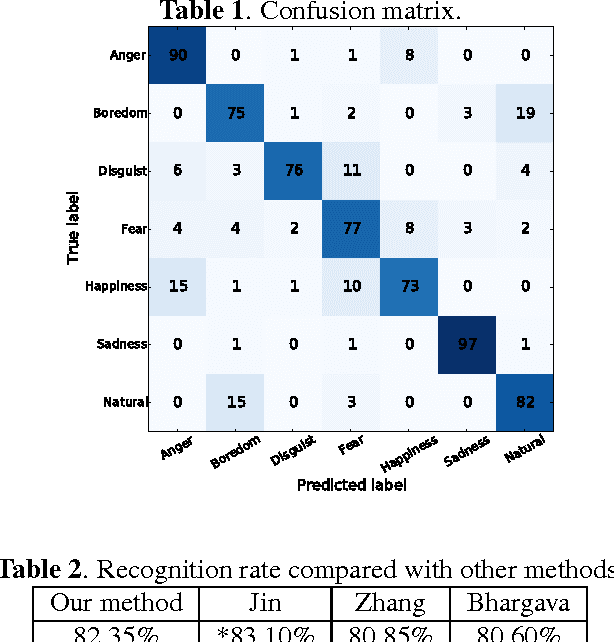
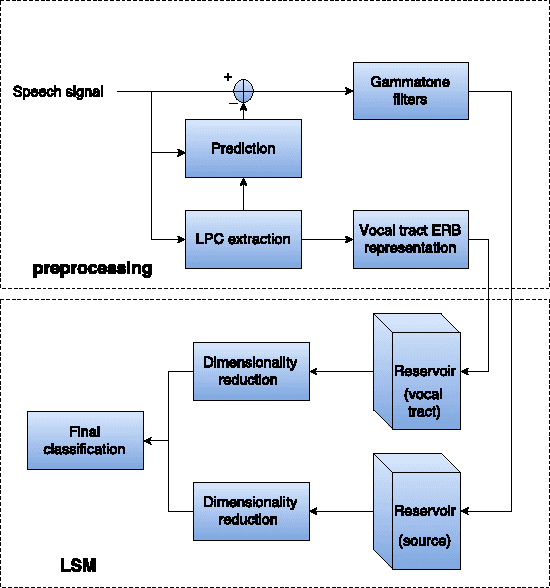
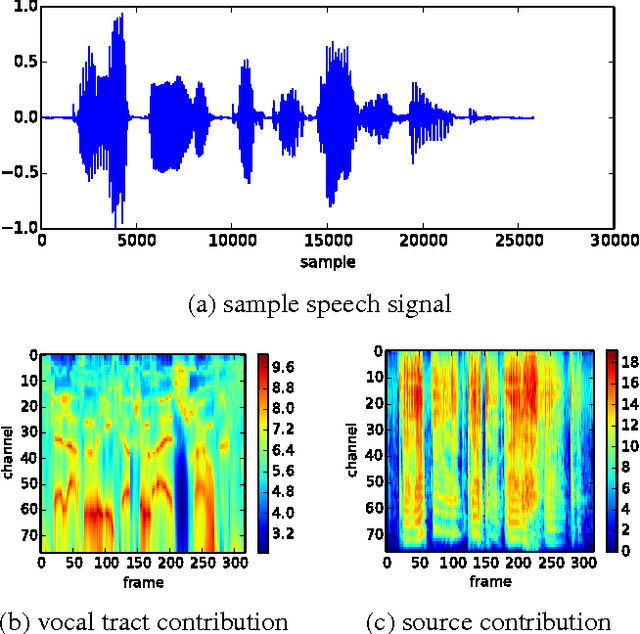
Conventional feature-based classification methods do not apply well to automatic recognition of speech emotions, mostly because the precise set of spectral and prosodic features that is required to identify the emotional state of a speaker has not been determined yet. This paper presents a method that operates directly on the speech signal, thus avoiding the problematic step of feature extraction. Furthermore, this method combines the strengths of the classical source-filter model of human speech production with those of the recently introduced liquid state machine (LSM), a biologically-inspired spiking neural network (SNN). The source and vocal tract components of the speech signal are first separated and converted into perceptually relevant spectral representations. These representations are then processed separately by two reservoirs of neurons. The output of each reservoir is reduced in dimensionality and fed to a final classifier. This method is shown to provide very good classification performance on the Berlin Database of Emotional Speech (Emo-DB). This seems a very promising framework for solving efficiently many other problems in speech processing.
Cognitive Coding of Speech
Oct 08, 2021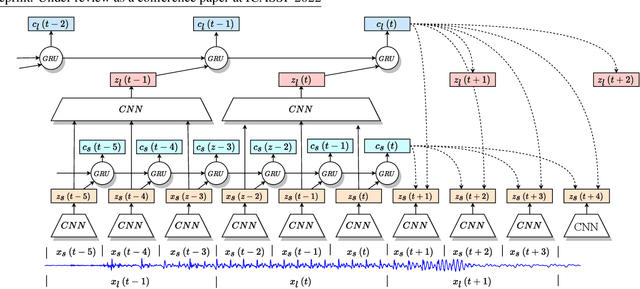
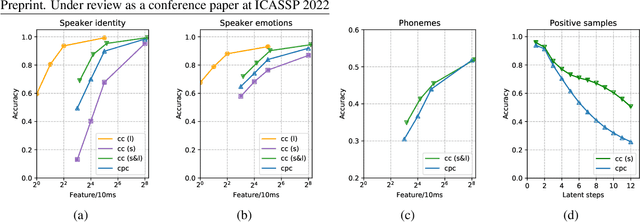
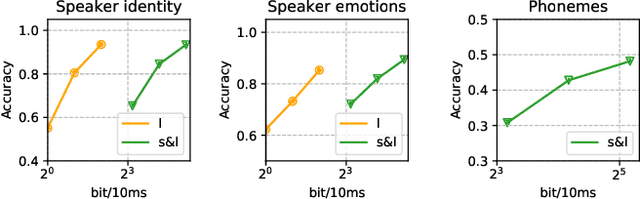
We propose an approach for cognitive coding of speech by unsupervised extraction of contextual representations in two hierarchical levels of abstraction. Speech attributes such as phoneme identity that last one hundred milliseconds or less are captured in the lower level of abstraction, while speech attributes such as speaker identity and emotion that persist up to one second are captured in the higher level of abstraction. This decomposition is achieved by a two-stage neural network, with a lower and an upper stage operating at different time scales. Both stages are trained to predict the content of the signal in their respective latent spaces. A top-down pathway between stages further improves the predictive capability of the network. With an application in speech compression in mind, we investigate the effect of dimensionality reduction and low bitrate quantization on the extracted representations. The performance measured on the LibriSpeech and EmoV-DB datasets reaches, and for some speech attributes even exceeds, that of state-of-the-art approaches.