 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Part-of-Speech Tagging of Odia Language Using statistical and Deep Learning-Based Approaches
Jul 07, 2022




Automatic Part-of-speech (POS) tagging is a preprocessing step of many natural language processing (NLP) tasks such as name entity recognition (NER), speech processing, information extraction, word sense disambiguation, and machine translation. It has already gained a promising result in English and European languages, but in Indian languages, particularly in Odia language, it is not yet well explored because of the lack of supporting tools, resources, and morphological richness of language. Unfortunately, we were unable to locate an open source POS tagger for Odia, and only a handful of attempts have been made to develop POS taggers for Odia language. The main contribution of this research work is to present a conditional random field (CRF) and deep learning-based approaches (CNN and Bidirectional Long Short-Term Memory) to develop Odia part-of-speech tagger. We used a publicly accessible corpus and the dataset is annotated with the Bureau of Indian Standards (BIS) tagset. However, most of the languages around the globe have used the dataset annotated with Universal Dependencies (UD) tagset. Hence, to maintain uniformity Odia dataset should use the same tagset. So we have constructed a simple mapping from BIS tagset to UD tagset. We experimented with various feature set inputs to the CRF model, observed the impact of constructed feature set. The deep learning-based model includes Bi-LSTM network, CNN network, CRF layer, character sequence information, and pre-trained word vector. Character sequence information was extracted by using convolutional neural network (CNN) and Bi-LSTM network. Six different combinations of neural sequence labelling models are implemented, and their performance measures are investigated. It has been observed that Bi-LSTM model with character sequence feature and pre-trained word vector achieved a significant state-of-the-art result.
Subword Dictionary Learning and Segmentation Techniques for Automatic Speech Recognition in Tamil and Kannada
Jul 27, 2022
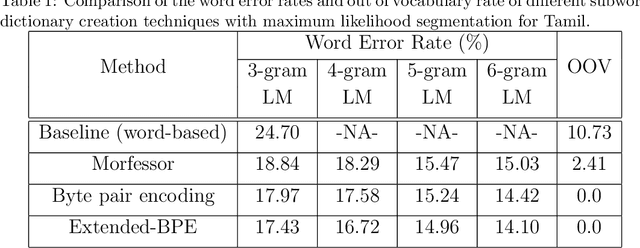
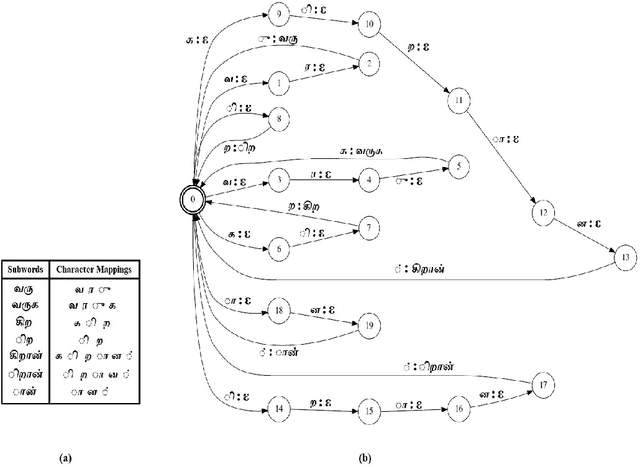
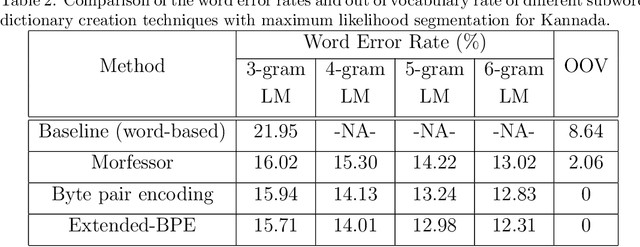
We present automatic speech recognition (ASR) systems for Tamil and Kannada based on subword modeling to effectively handle unlimited vocabulary due to the highly agglutinative nature of the languages. We explore byte pair encoding (BPE), and proposed a variant of this algorithm named extended-BPE, and Morfessor tool to segment each word as subwords. We have effectively incorporated maximum likelihood (ML) and Viterbi estimation techniques with weighted finite state transducers (WFST) framework in these algorithms to learn the subword dictionary from a large text corpus. Using the learnt subword dictionary, the words in training data transcriptions are segmented to subwords and we train deep neural network ASR systems which recognize subword sequence for any given test speech utterance. The output subword sequence is then post-processed using deterministic rules to get the final word sequence such that the actual number of words that can be recognized is much larger. For Tamil ASR, We use 152 hours of data for training and 65 hours for testing, whereas for Kannada ASR, we use 275 hours for training and 72 hours for testing. Upon experimenting with different combination of segmentation and estimation techniques, we find that the word error rate (WER) reduces drastically when compared to the baseline word-level ASR, achieving a maximum absolute WER reduction of 6.24% and 6.63% for Tamil and Kannada respectively.
AdaSpeech 4: Adaptive Text to Speech in Zero-Shot Scenarios
Apr 01, 2022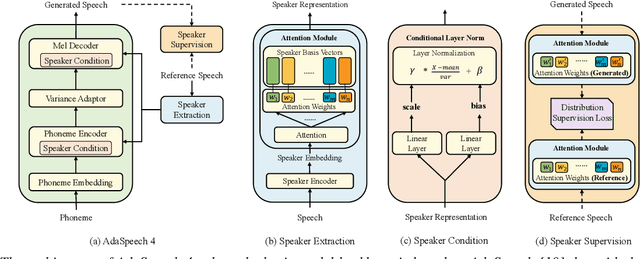
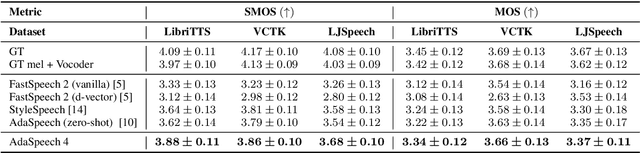
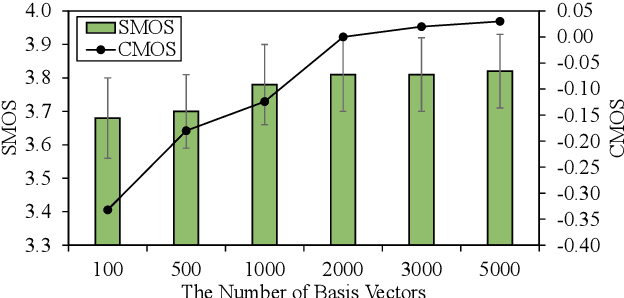
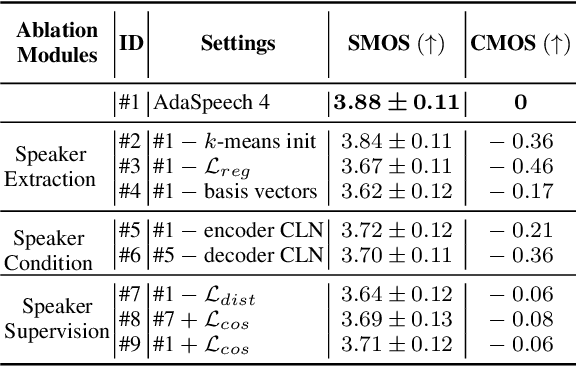
Adaptive text to speech (TTS) can synthesize new voices in zero-shot scenarios efficiently, by using a well-trained source TTS model without adapting it on the speech data of new speakers. Considering seen and unseen speakers have diverse characteristics, zero-shot adaptive TTS requires strong generalization ability on speaker characteristics, which brings modeling challenges. In this paper, we develop AdaSpeech 4, a zero-shot adaptive TTS system for high-quality speech synthesis. We model the speaker characteristics systematically to improve the generalization on new speakers. Generally, the modeling of speaker characteristics can be categorized into three steps: extracting speaker representation, taking this speaker representation as condition, and synthesizing speech/mel-spectrogram given this speaker representation. Accordingly, we improve the modeling in three steps: 1) To extract speaker representation with better generalization, we factorize the speaker characteristics into basis vectors and extract speaker representation by weighted combining of these basis vectors through attention. 2) We leverage conditional layer normalization to integrate the extracted speaker representation to TTS model. 3) We propose a novel supervision loss based on the distribution of basis vectors to maintain the corresponding speaker characteristics in generated mel-spectrograms. Without any fine-tuning, AdaSpeech 4 achieves better voice quality and similarity than baselines in multiple datasets.
Speaker Adaptation Using Spectro-Temporal Deep Features for Dysarthric and Elderly Speech Recognition
Feb 26, 2022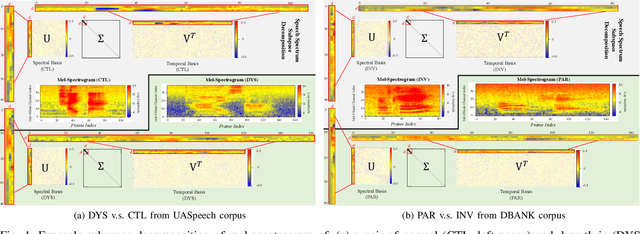
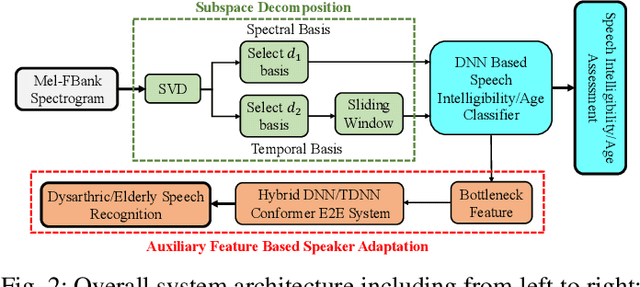
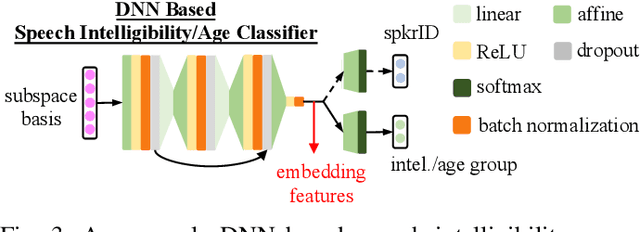
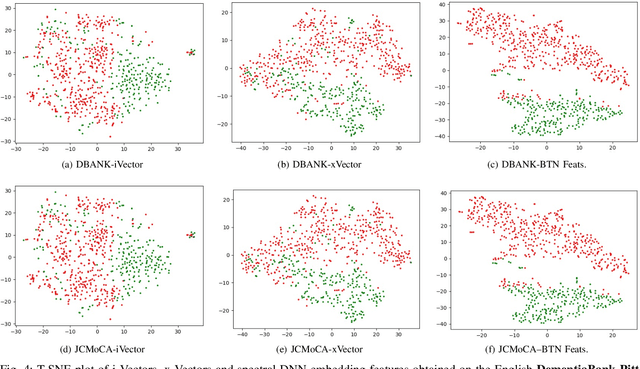
Despite the rapid progress of automatic speech recognition (ASR) technologies targeting normal speech in recent decades, accurate recognition of dysarthric and elderly speech remains highly challenging tasks to date. Sources of heterogeneity commonly found in normal speech including accent or gender, when further compounded with the variability over age and speech pathology severity level, create large diversity among speakers. To this end, speaker adaptation techniques play a key role in personalization of ASR systems for such users. Motivated by the spectro-temporal level differences between dysarthric, elderly and normal speech that systematically manifest in articulatory imprecision, decreased volume and clarity, slower speaking rates and increased dysfluencies, novel spectrotemporal subspace basis deep embedding features derived using SVD speech spectrum decomposition are proposed in this paper to facilitate auxiliary feature based speaker adaptation of state-of-the-art hybrid DNN/TDNN and end-to-end Conformer speech recognition systems. Experiments were conducted on four tasks: the English UASpeech and TORGO dysarthric speech corpora; the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech datasets. The proposed spectro-temporal deep feature adapted systems outperformed baseline i-Vector and xVector adaptation by up to 2.63% absolute (8.63% relative) reduction in word error rate (WER). Consistent performance improvements were retained after model based speaker adaptation using learning hidden unit contributions (LHUC) was further applied. The best speaker adapted system using the proposed spectral basis embedding features produced the lowest published WER of 25.05% on the UASpeech test set of 16 dysarthric speakers.
Single-channel speech enhancement by using psychoacoustical model inspired fusion framework
Feb 10, 2022When the parameters of Bayesian Short-time Spectral Amplitude (STSA) estimator for speech enhancement are selected based on the characteristics of the human auditory system, the gain function of the estimator becomes more flexible. Although this type of estimator in acoustic domain is quite effective in reducing the back-ground noise at high frequencies, it produces more speech distortions, which make the high-frequency contents of the speech such as friciatives less perceptible in heavy noise conditions, resulting in intelligibility reduction. On the other hand, the speech enhancement scheme, which exploits the psychoacoustic evidence of frequency selectivity in the modulation domain, is found to be able to increase the intelligibility of noisy speech by a substantial amount, but also suffers from the temporal slurring problem due to its essential design constraint. In order to achieve the joint improvements in both the perceived speech quality and intelligibility, we proposed and investigated a fusion framework by combining the merits of acoustic and modulation domain approaches while avoiding their respective weaknesses. Objective measure evaluation shows that the proposed speech enhancement fusion framework can provide consistent improvements in the perceived speech quality and intelligibility across different SNR levels in various noise conditions, while compared to the other baseline techniques.
Autoregressive Co-Training for Learning Discrete Speech Representations
Mar 29, 2022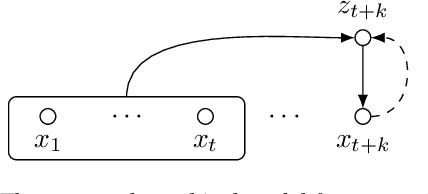
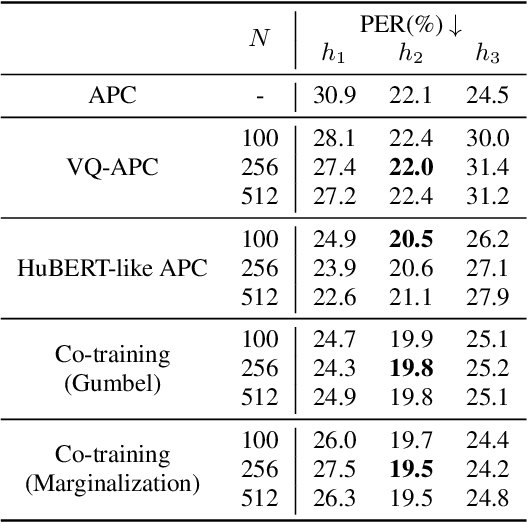
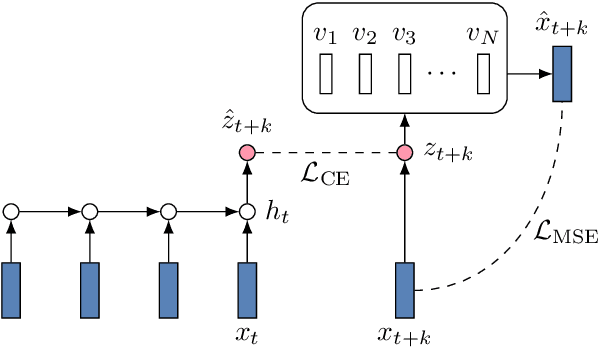
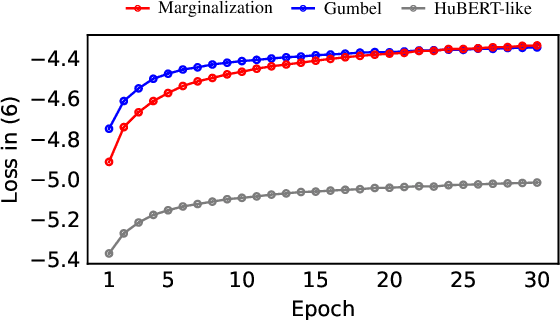
While several self-supervised approaches for learning discrete speech representation have been proposed, it is unclear how these seemingly similar approaches relate to each other. In this paper, we consider a generative model with discrete latent variables that learns a discrete representation for speech. The objective of learning the generative model is formulated as information-theoretic co-training. Besides the wide generality, the objective can be optimized with several approaches, subsuming HuBERT-like training and vector quantization for learning discrete representation. Empirically, we find that the proposed approach learns discrete representation that is highly correlated with phonetic units, more correlated than HuBERT-like training and vector quantization.
Exploring Attention Map Reuse for Efficient Transformer Neural Networks
Jan 29, 2023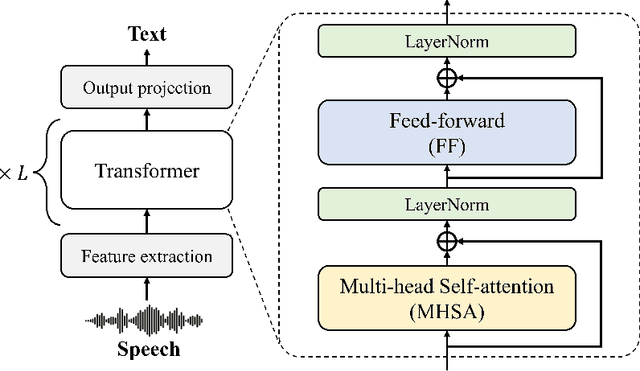
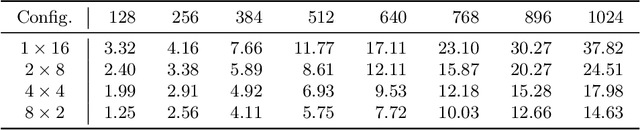
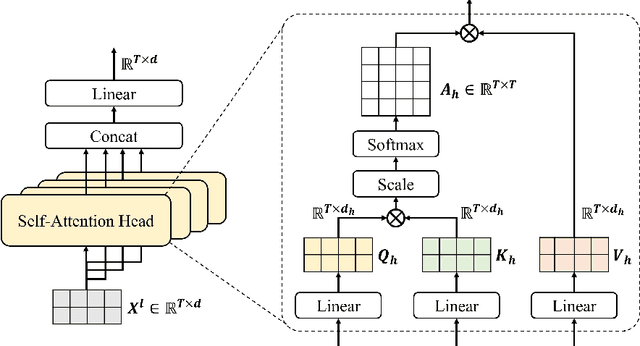
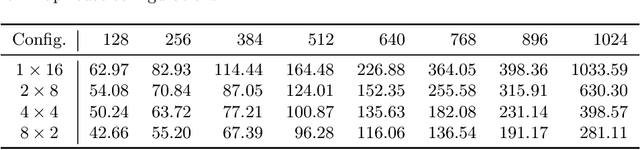
Transformer-based deep neural networks have achieved great success in various sequence applications due to their powerful ability to model long-range dependency. The key module of Transformer is self-attention (SA) which extracts features from the entire sequence regardless of the distance between positions. Although SA helps Transformer performs particularly well on long-range tasks, SA requires quadratic computation and memory complexity with the input sequence length. Recently, attention map reuse, which groups multiple SA layers to share one attention map, has been proposed and achieved significant speedup for speech recognition models. In this paper, we provide a comprehensive study on attention map reuse focusing on its ability to accelerate inference. We compare the method with other SA compression techniques and conduct a breakdown analysis of its advantages for a long sequence. We demonstrate the effectiveness of attention map reuse by measuring the latency on both CPU and GPU platforms.
Analysis of Joint Speech-Text Embeddings for Semantic Matching
Apr 04, 2022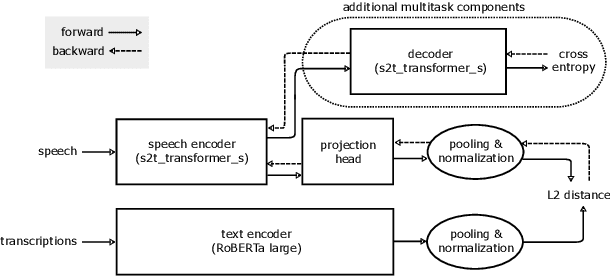
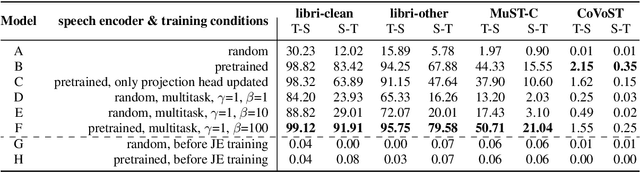

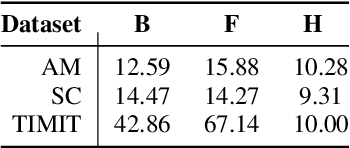
Embeddings play an important role in many recent end-to-end solutions for language processing problems involving more than one data modality. Although there has been some effort to understand the properties of single-modality embedding spaces, particularly that of text, their cross-modal counterparts are less understood. In this work, we study a joint speech-text embedding space trained for semantic matching by minimizing the distance between paired utterance and transcription inputs. This was done through dual encoders in a teacher-student model setup, with a pretrained language model acting as the teacher and a transformer-based speech encoder as the student. We extend our method to incorporate automatic speech recognition through both pretraining and multitask scenarios and found that both approaches improve semantic matching. Multiple techniques were utilized to analyze and evaluate cross-modal semantic alignment of the embeddings: a quantitative retrieval accuracy metric, zero-shot classification to investigate generalizability, and probing of the encoders to observe the extent of knowledge transfer from one modality to another.
Joint Far- and Near-End Speech Intelligibility Enhancement based on the Approximated Speech Intelligibility Index
Nov 15, 2021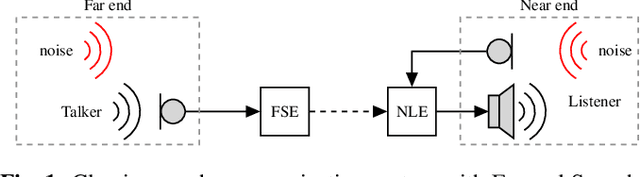
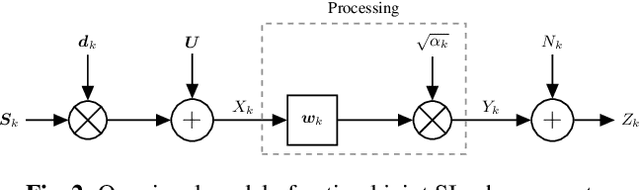
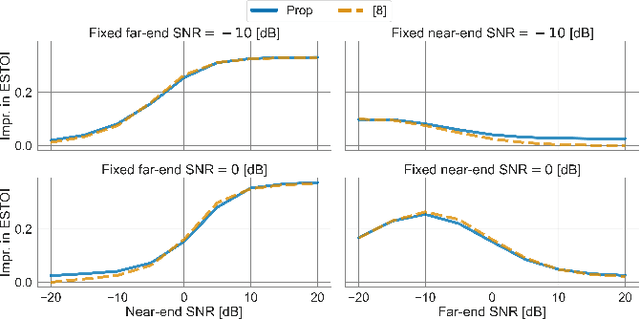
This paper considers speech enhancement of signals picked up in one noisy environment which must be presented to a listener in another noisy environment. Recently, it has been shown that an optimal solution to this problem requires the consideration of the noise sources in both environments jointly. However, the existing optimal mutual information based method requires a complicated system model that includes natural speech variations, and relies on approximations and assumptions of the underlying signal distributions. In this paper, we propose to use a simpler signal model and optimize speech intelligibility based on the Approximated Speech Intelligibility Index (ASII). We derive a closed-form solution to the joint far- and near-end speech enhancement problem that is independent of the marginal distribution of signal coefficients, and that achieves similar performance to existing work. In addition, we do not need to model or optimize for natural speech variations.
MetricGAN-U: Unsupervised speech enhancement/ dereverberation based only on noisy/ reverberated speech
Oct 12, 2021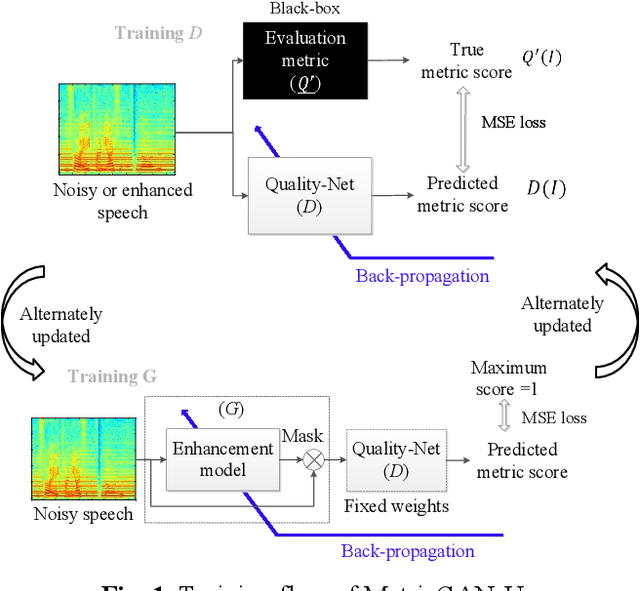
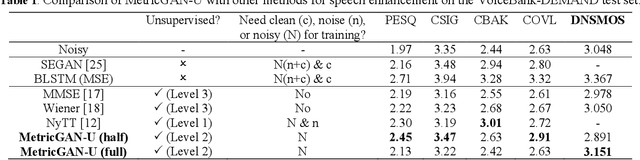
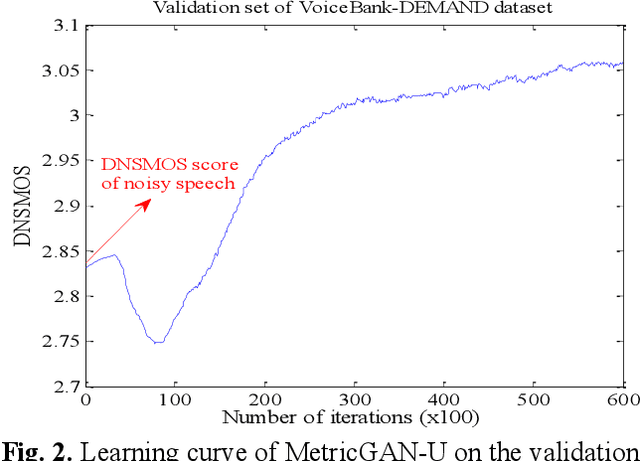
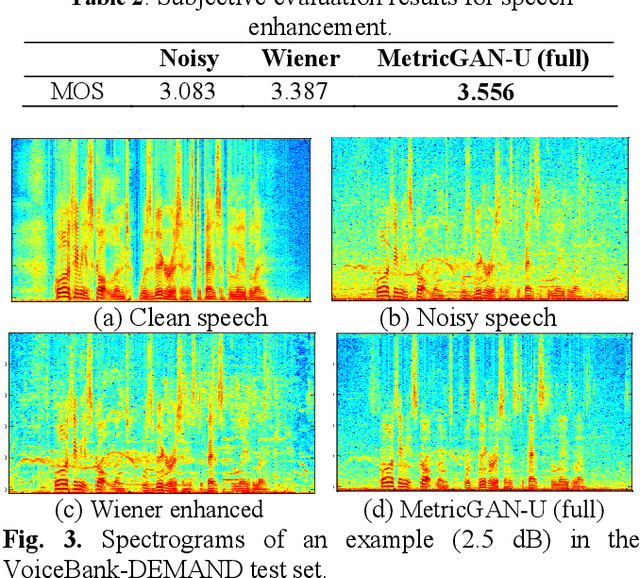
Most of the deep learning-based speech enhancement models are learned in a supervised manner, which implies that pairs of noisy and clean speech are required during training. Consequently, several noisy speeches recorded in daily life cannot be used to train the model. Although certain unsupervised learning frameworks have also been proposed to solve the pair constraint, they still require clean speech or noise for training. Therefore, in this paper, we propose MetricGAN-U, which stands for MetricGAN-unsupervised, to further release the constraint from conventional unsupervised learning. In MetricGAN-U, only noisy speech is required to train the model by optimizing non-intrusive speech quality metrics. The experimental results verified that MetricGAN-U outperforms baselines in both objective and subjective metrics.