 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Provable Robustness for Streaming Models with a Sliding Window
Mar 28, 2023
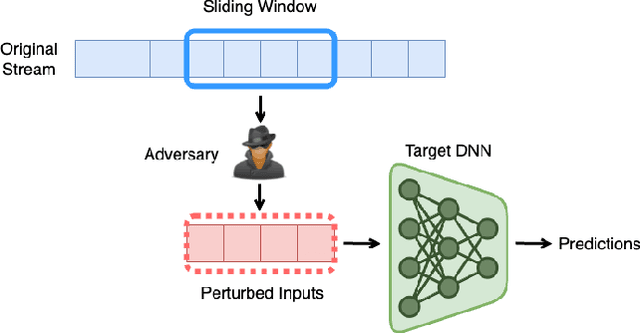
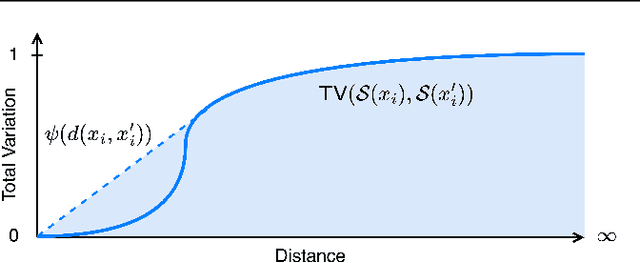

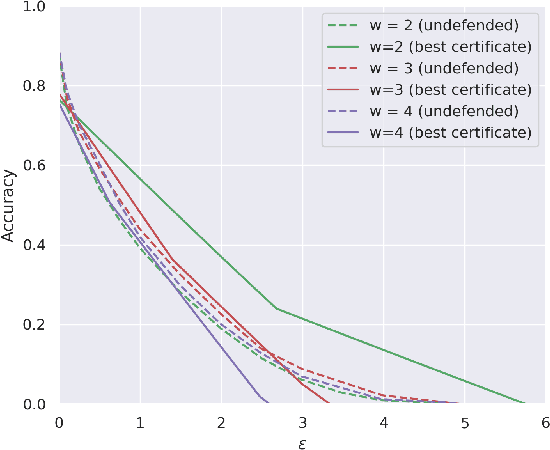
The literature on provable robustness in machine learning has primarily focused on static prediction problems, such as image classification, in which input samples are assumed to be independent and model performance is measured as an expectation over the input distribution. Robustness certificates are derived for individual input instances with the assumption that the model is evaluated on each instance separately. However, in many deep learning applications such as online content recommendation and stock market analysis, models use historical data to make predictions. Robustness certificates based on the assumption of independent input samples are not directly applicable in such scenarios. In this work, we focus on the provable robustness of machine learning models in the context of data streams, where inputs are presented as a sequence of potentially correlated items. We derive robustness certificates for models that use a fixed-size sliding window over the input stream. Our guarantees hold for the average model performance across the entire stream and are independent of stream size, making them suitable for large data streams. We perform experiments on speech detection and human activity recognition tasks and show that our certificates can produce meaningful performance guarantees against adversarial perturbations.
Transfer Learning for Robust Low-Resource Children's Speech ASR with Transformers and Source-Filter Warping
Jun 19, 2022
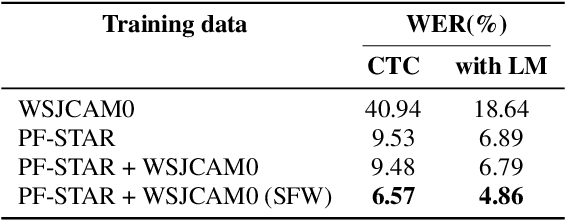
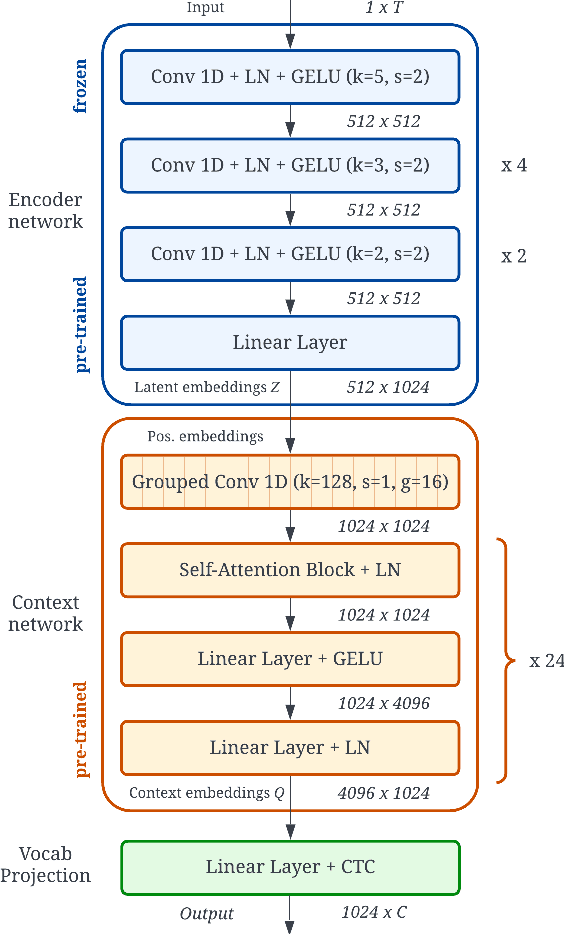
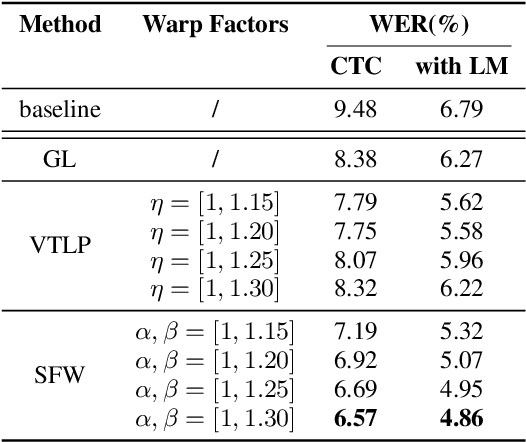
Automatic Speech Recognition (ASR) systems are known to exhibit difficulties when transcribing children's speech. This can mainly be attributed to the absence of large children's speech corpora to train robust ASR models and the resulting domain mismatch when decoding children's speech with systems trained on adult data. In this paper, we propose multiple enhancements to alleviate these issues. First, we propose a data augmentation technique based on the source-filter model of speech to close the domain gap between adult and children's speech. This enables us to leverage the data availability of adult speech corpora by making these samples perceptually similar to children's speech. Second, using this augmentation strategy, we apply transfer learning on a Transformer model pre-trained on adult data. This model follows the recently introduced XLS-R architecture, a wav2vec 2.0 model pre-trained on several cross-lingual adult speech corpora to learn general and robust acoustic frame-level representations. Adopting this model for the ASR task using adult data augmented with the proposed source-filter warping strategy and a limited amount of in-domain children's speech significantly outperforms previous state-of-the-art results on the PF-STAR British English Children's Speech corpus with a 4.86% WER on the official test set.
Trustera: A Live Conversation Redaction System
Mar 16, 2023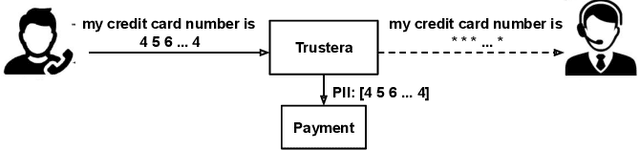
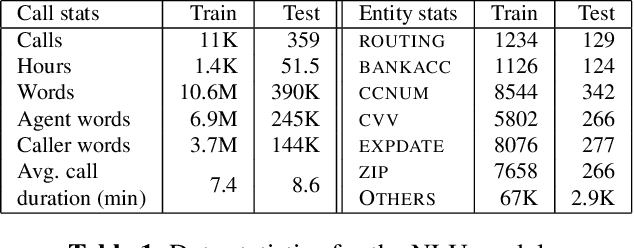

Trustera, the first functional system that redacts personally identifiable information (PII) in real-time spoken conversations to remove agents' need to hear sensitive information while preserving the naturalness of live customer-agent conversations. As opposed to post-call redaction, audio masking starts as soon as the customer begins speaking to a PII entity. This significantly reduces the risk of PII being intercepted or stored in insecure data storage. Trustera's architecture consists of a pipeline of automatic speech recognition, natural language understanding, and a live audio redactor module. The system's goal is three-fold: redact entities that are PII, mask the audio that goes to the agent, and at the same time capture the entity, so that the captured PII can be used for a payment transaction or caller identification. Trustera is currently being used by thousands of agents to secure customers' sensitive information.
Crossword: A Semantic Approach to Data Compression via Masking
Apr 03, 2023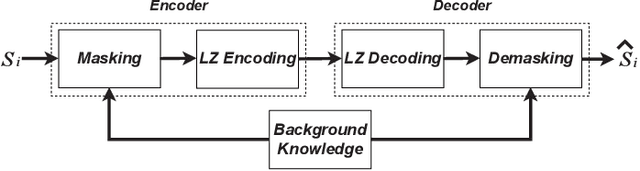
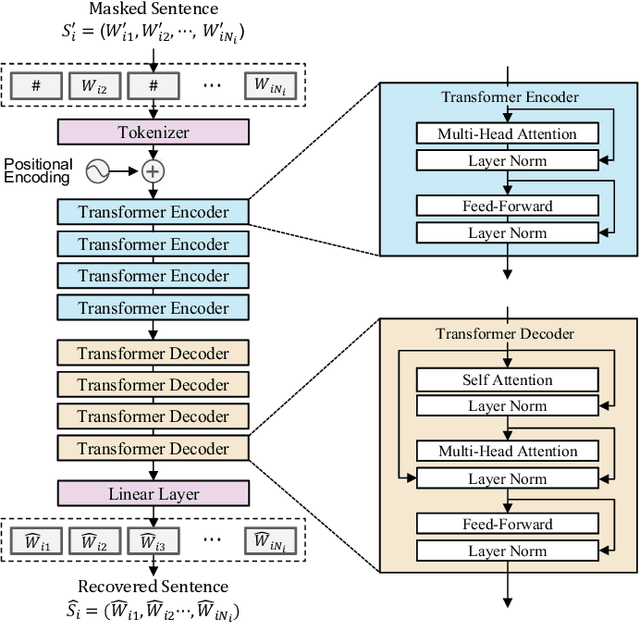
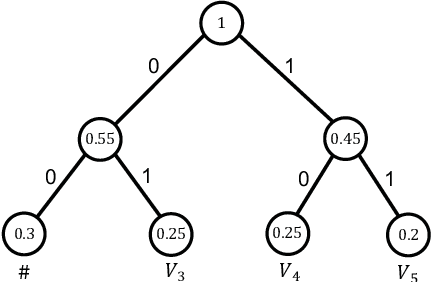
The traditional methods for data compression are typically based on the symbol-level statistics, with the information source modeled as a long sequence of i.i.d. random variables or a stochastic process, thus establishing the fundamental limit as entropy for lossless compression and as mutual information for lossy compression. However, the source (including text, music, and speech) in the real world is often statistically ill-defined because of its close connection to human perception, and thus the model-driven approach can be quite suboptimal. This study places careful emphasis on English text and exploits its semantic aspect to enhance the compression efficiency further. The main idea stems from the puzzle crossword, observing that the hidden words can still be precisely reconstructed so long as some key letters are provided. The proposed masking-based strategy resembles the above game. In a nutshell, the encoder evaluates the semantic importance of each word according to the semantic loss and then masks the minor ones, while the decoder aims to recover the masked words from the semantic context by means of the Transformer. Our experiments show that the proposed semantic approach can achieve much higher compression efficiency than the traditional methods such as Huffman code and UTF-8 code, while preserving the meaning in the target text to a great extent.
On the Impact of Speech Recognition Errors in Passage Retrieval for Spoken Question Answering
Sep 26, 2022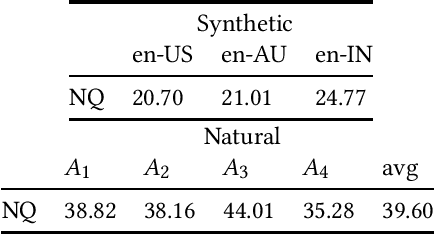

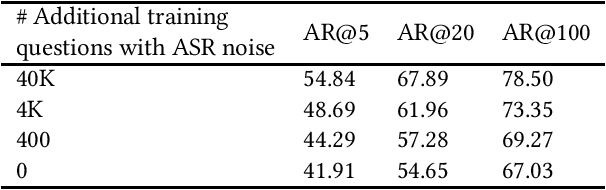
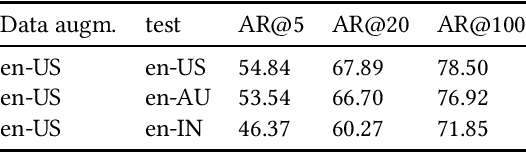
Interacting with a speech interface to query a Question Answering (QA) system is becoming increasingly popular. Typically, QA systems rely on passage retrieval to select candidate contexts and reading comprehension to extract the final answer. While there has been some attention to improving the reading comprehension part of QA systems against errors that automatic speech recognition (ASR) models introduce, the passage retrieval part remains unexplored. However, such errors can affect the performance of passage retrieval, leading to inferior end-to-end performance. To address this gap, we augment two existing large-scale passage ranking and open domain QA datasets with synthetic ASR noise and study the robustness of lexical and dense retrievers against questions with ASR noise. Furthermore, we study the generalizability of data augmentation techniques across different domains; with each domain being a different language dialect or accent. Finally, we create a new dataset with questions voiced by human users and use their transcriptions to show that the retrieval performance can further degrade when dealing with natural ASR noise instead of synthetic ASR noise.
An investigation into the adaptability of a diffusion-based TTS model
Mar 03, 2023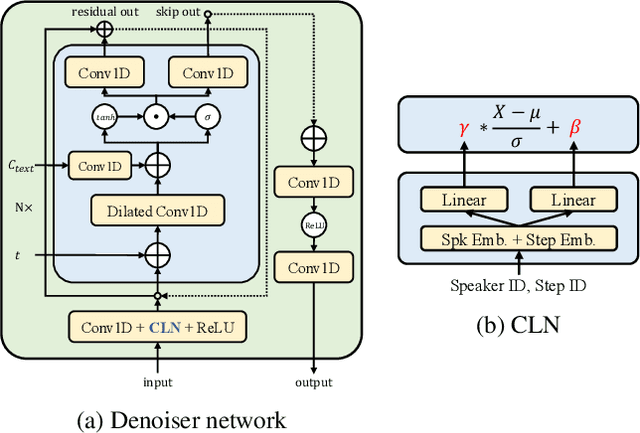
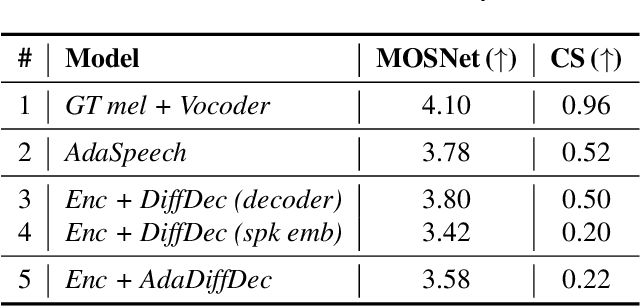
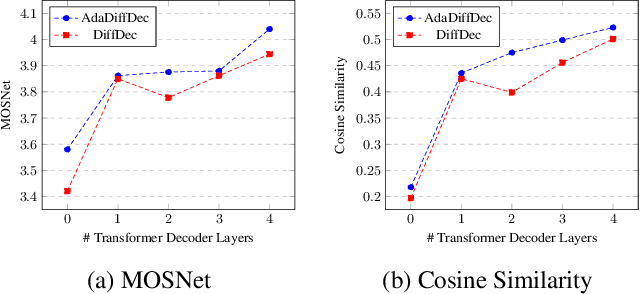
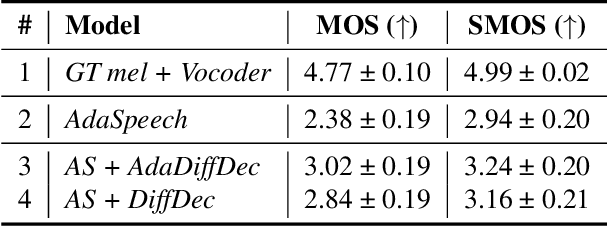
Given the recent success of diffusion in producing natural-sounding synthetic speech, we investigate how diffusion can be used in speaker adaptive TTS. Taking cues from more traditional adaptation approaches, we show that adaptation can be included in a diffusion pipeline using conditional layer normalization with a step embedding. However, we show experimentally that, whilst the approach has merit, such adaptation alone cannot approach the performance of Transformer-based techniques. In a second experiment, we show that diffusion can be optimally combined with Transformer, with the latter taking the bulk of the adaptation load and the former contributing to improved naturalness.
Cross-modal Contrastive Learning for Speech Translation
May 05, 2022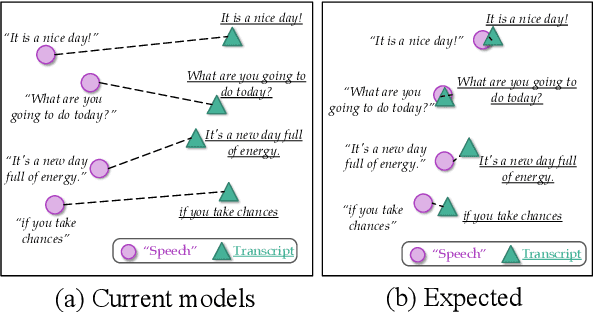
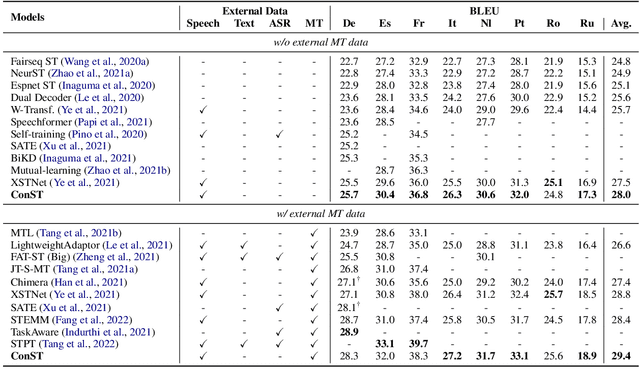
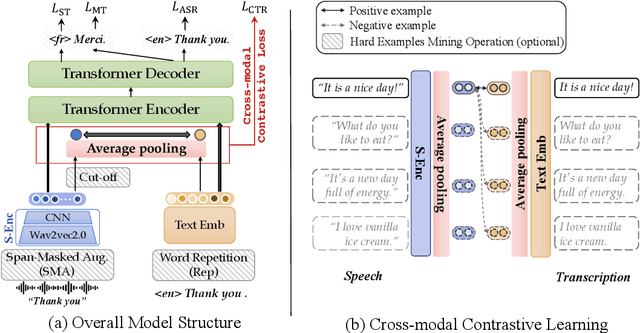
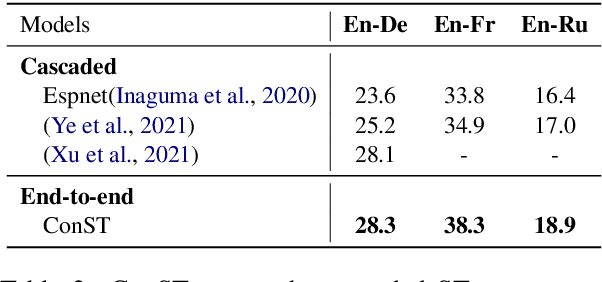
How can we learn unified representations for spoken utterances and their written text? Learning similar representations for semantically similar speech and text is important for speech translation. To this end, we propose ConST, a cross-modal contrastive learning method for end-to-end speech-to-text translation. We evaluate ConST and a variety of previous baselines on a popular benchmark MuST-C. Experiments show that the proposed ConST consistently outperforms the previous methods on, and achieves an average BLEU of 29.4. The analysis further verifies that ConST indeed closes the representation gap of different modalities -- its learned representation improves the accuracy of cross-modal speech-text retrieval from 4% to 88%. Code and models are available at https://github.com/ReneeYe/ConST.
Exploring Hate Speech Detection with HateXplain and BERT
Aug 09, 2022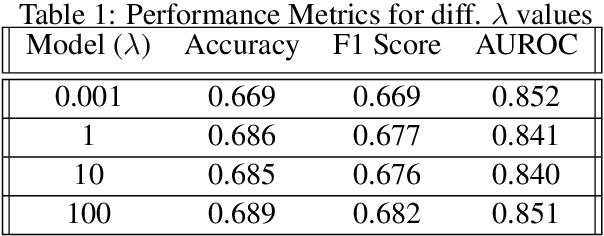
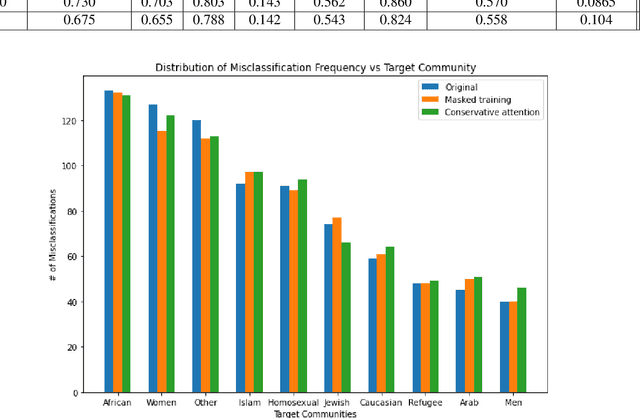
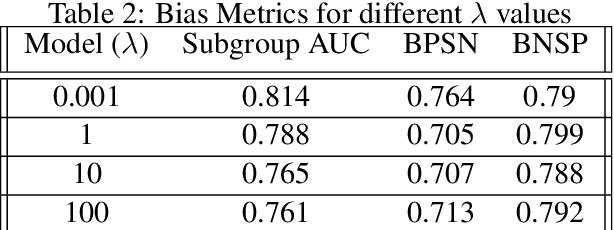
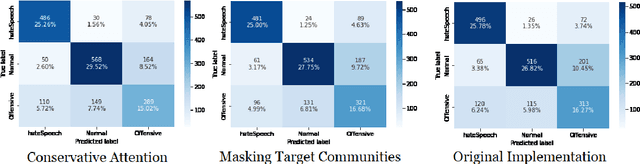
Hate Speech takes many forms to target communities with derogatory comments, and takes humanity a step back in societal progress. HateXplain is a recently published and first dataset to use annotated spans in the form of rationales, along with speech classification categories and targeted communities to make the classification more humanlike, explainable, accurate and less biased. We tune BERT to perform this task in the form of rationales and class prediction, and compare our performance on different metrics spanning across accuracy, explainability and bias. Our novelty is threefold. Firstly, we experiment with the amalgamated rationale class loss with different importance values. Secondly, we experiment extensively with the ground truth attention values for the rationales. With the introduction of conservative and lenient attentions, we compare performance of the model on HateXplain and test our hypothesis. Thirdly, in order to improve the unintended bias in our models, we use masking of the target community words and note the improvement in bias and explainability metrics. Overall, we are successful in achieving model explanability, bias removal and several incremental improvements on the original BERT implementation.
On-the-fly Text Retrieval for End-to-End ASR Adaptation
Mar 20, 2023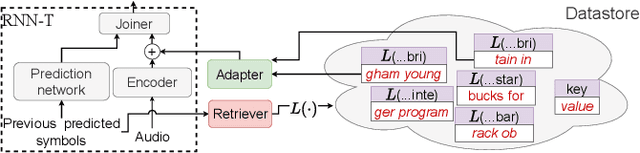
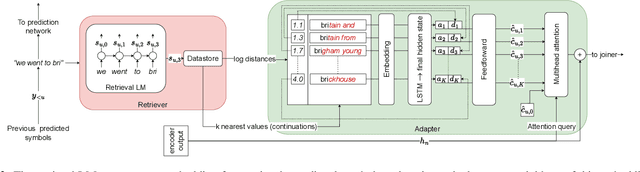
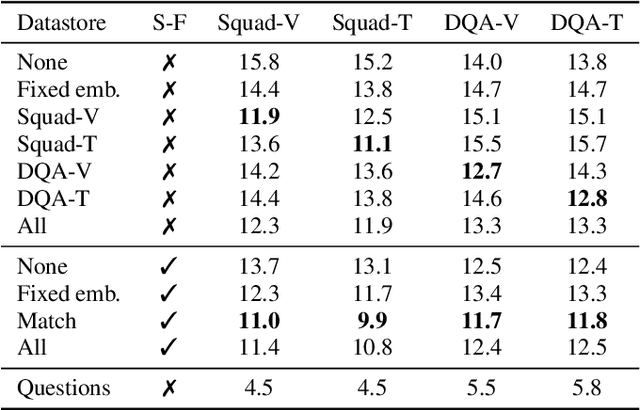
End-to-end speech recognition models are improved by incorporating external text sources, typically by fusion with an external language model. Such language models have to be retrained whenever the corpus of interest changes. Furthermore, since they store the entire corpus in their parameters, rare words can be challenging to recall. In this work, we propose augmenting a transducer-based ASR model with a retrieval language model, which directly retrieves from an external text corpus plausible completions for a partial ASR hypothesis. These completions are then integrated into subsequent predictions by an adapter, which is trained once, so that the corpus of interest can be switched without incurring the computational overhead of retraining. Our experiments show that the proposed model significantly improves the performance of a transducer baseline on a pair of question-answering datasets. Further, it outperforms shallow fusion on recognition of named entities by about 7 relative; when the two are combined, the relative improvement increases to 13%.
Exploring Representation Learning for Small-Footprint Keyword Spotting
Mar 20, 2023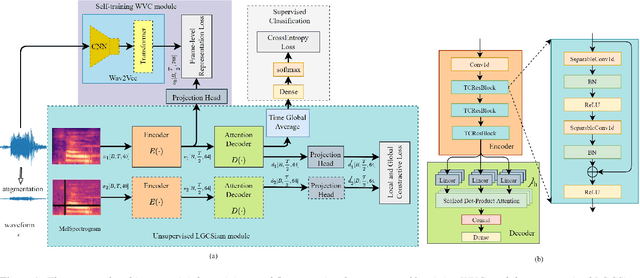

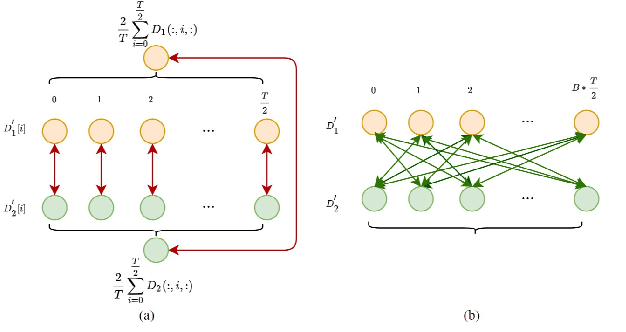

In this paper, we investigate representation learning for low-resource keyword spotting (KWS). The main challenges of KWS are limited labeled data and limited available device resources. To address those challenges, we explore representation learning for KWS by self-supervised contrastive learning and self-training with pretrained model. First, local-global contrastive siamese networks (LGCSiam) are designed to learn similar utterance-level representations for similar audio samplers by proposed local-global contrastive loss without requiring ground-truth. Second, a self-supervised pretrained Wav2Vec 2.0 model is applied as a constraint module (WVC) to force the KWS model to learn frame-level acoustic representations. By the LGCSiam and WVC modules, the proposed small-footprint KWS model can be pretrained with unlabeled data. Experiments on speech commands dataset show that the self-training WVC module and the self-supervised LGCSiam module significantly improve accuracy, especially in the case of training on a small labeled dataset.