 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Embeddings With Weakly Supervised Voice Activity Detection For Efficient Speaker Diarization
May 15, 2024



Current speaker diarization systems rely on an external voice activity detection model prior to speaker embedding extraction on the detected speech segments. In this paper, we establish that the attention system of a speaker embedding extractor acts as a weakly supervised internal VAD model and performs equally or better than comparable supervised VAD systems. Subsequently, speaker diarization can be performed efficiently by extracting the VAD logits and corresponding speaker embedding simultaneously, alleviating the need and computational overhead of an external VAD model. We provide an extensive analysis of the behavior of the frame-level attention system in current speaker verification models and propose a novel speaker diarization pipeline using ECAPA2 speaker embeddings for both VAD and embedding extraction. The proposed strategy gains state-of-the-art performance on the AMI, VoxConverse and DIHARD III diarization benchmarks.
ECAPA2: A Hybrid Neural Network Architecture and Training Strategy for Robust Speaker Embeddings
Jan 16, 2024



In this paper, we present ECAPA2, a novel hybrid neural network architecture and training strategy to produce robust speaker embeddings. Most speaker verification models are based on either the 1D- or 2D-convolutional operation, often manifested as Time Delay Neural Networks or ResNets, respectively. Hybrid models are relatively unexplored without an intuitive explanation what constitutes best practices in regard to its architectural choices. We motivate the proposed ECAPA2 model in this paper with an analysis of current speaker verification architectures. In addition, we propose a training strategy which makes the speaker embeddings more robust against overlapping speech and short utterance lengths. The presented ECAPA2 architecture and training strategy attains state-of-the-art performance on the VoxCeleb1 test sets with significantly less parameters than current models. Finally, we make a pre-trained model publicly available to promote research on downstream tasks.
Behavioral Analysis of Pathological Speaker Embeddings of Patients During Oncological Treatment of Oral Cancer
Jul 10, 2023In this paper, we analyze the behavior of speaker embeddings of patients during oral cancer treatment. First, we found that pre- and post-treatment speaker embeddings differ significantly, notifying a substantial change in voice characteristics. However, a partial recovery to pre-operative voice traits is observed after 12 months post-operation. Secondly, the same-speaker similarity at distinct treatment stages is similar to healthy speakers, indicating that the embeddings can capture characterizing features of even severely impaired speech. Finally, a speaker verification analysis signifies a stable false positive rate and variable false negative rate when combining speech samples of different treatment stages. This indicates robustness of the embeddings towards other speakers, while still capturing the changing voice characteristics during treatment. To the best of our knowledge, this is the first analysis of speaker embeddings during oral cancer treatment of patients.
Margin-Mixup: A Method for Robust Speaker Verification in Multi-Speaker Audio
Apr 07, 2023



This paper is concerned with the task of speaker verification on audio with multiple overlapping speakers. Most speaker verification systems are designed with the assumption of a single speaker being present in a given audio segment. However, in a real-world setting this assumption does not always hold. In this paper, we demonstrate that current speaker verification systems are not robust against audio with noticeable speaker overlap. To alleviate this issue, we propose margin-mixup, a simple training strategy that can easily be adopted by existing speaker verification pipelines to make the resulting speaker embeddings robust against multi-speaker audio. In contrast to other methods, margin-mixup requires no alterations to regular speaker verification architectures, while attaining better results. On our multi-speaker test set based on VoxCeleb1, the proposed margin-mixup strategy improves the EER on average with 44.4% relative to our state-of-the-art speaker verification baseline systems.
Transfer Learning for Robust Low-Resource Children's Speech ASR with Transformers and Source-Filter Warping
Jun 19, 2022
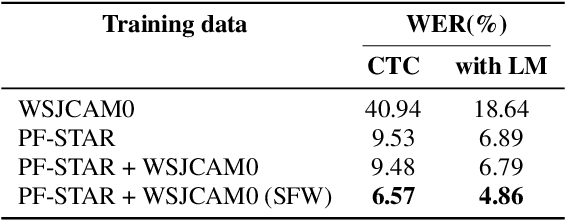
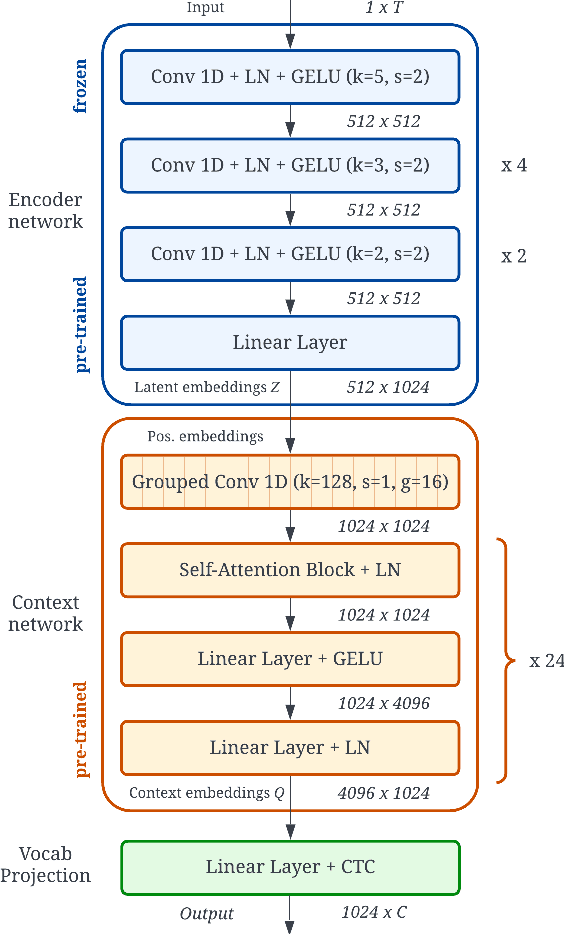
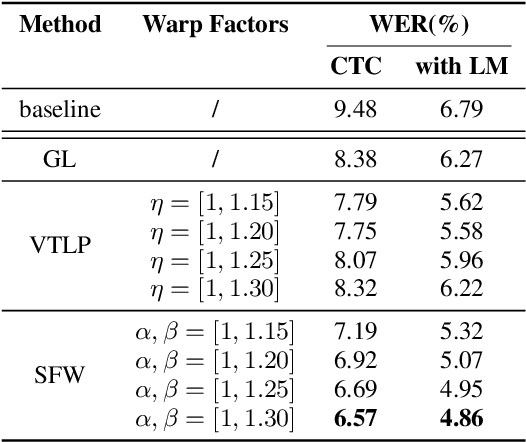
Automatic Speech Recognition (ASR) systems are known to exhibit difficulties when transcribing children's speech. This can mainly be attributed to the absence of large children's speech corpora to train robust ASR models and the resulting domain mismatch when decoding children's speech with systems trained on adult data. In this paper, we propose multiple enhancements to alleviate these issues. First, we propose a data augmentation technique based on the source-filter model of speech to close the domain gap between adult and children's speech. This enables us to leverage the data availability of adult speech corpora by making these samples perceptually similar to children's speech. Second, using this augmentation strategy, we apply transfer learning on a Transformer model pre-trained on adult data. This model follows the recently introduced XLS-R architecture, a wav2vec 2.0 model pre-trained on several cross-lingual adult speech corpora to learn general and robust acoustic frame-level representations. Adopting this model for the ASR task using adult data augmented with the proposed source-filter warping strategy and a limited amount of in-domain children's speech significantly outperforms previous state-of-the-art results on the PF-STAR British English Children's Speech corpus with a 4.86% WER on the official test set.
Tackling the Score Shift in Cross-Lingual Speaker Verification by Exploiting Language Information
Oct 18, 2021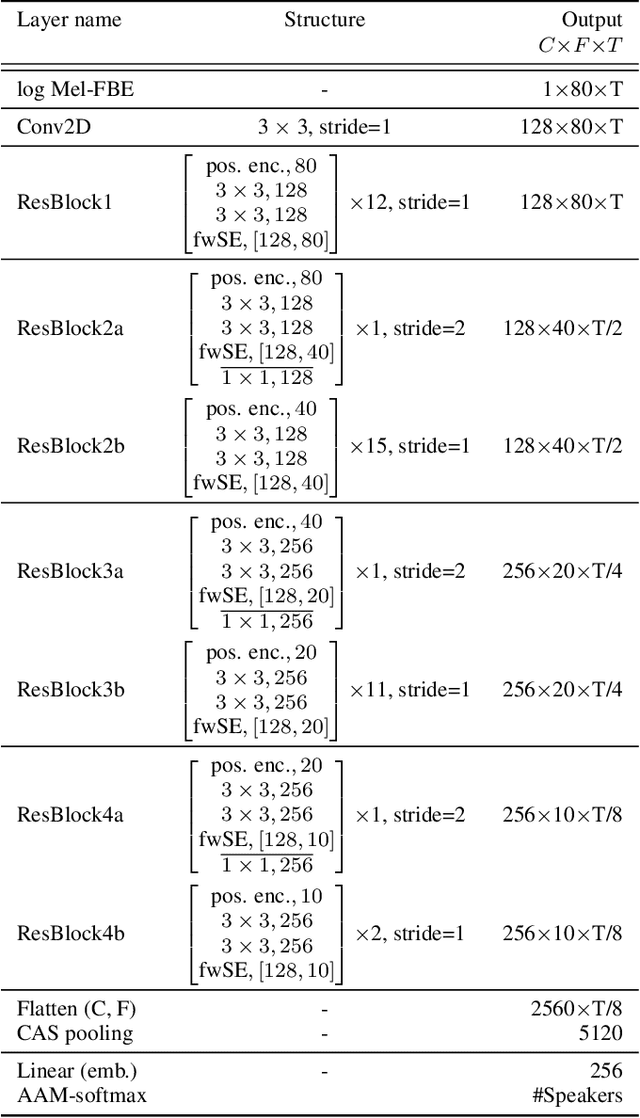
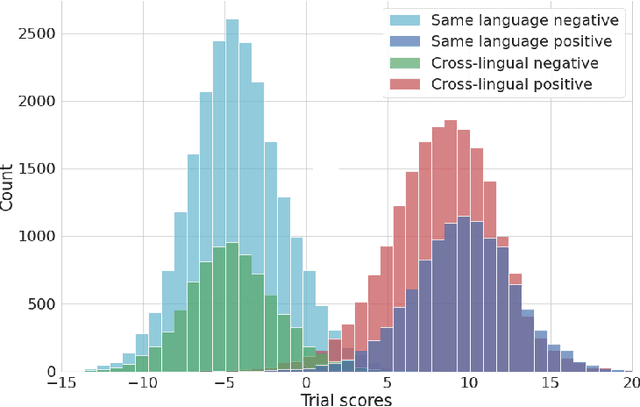
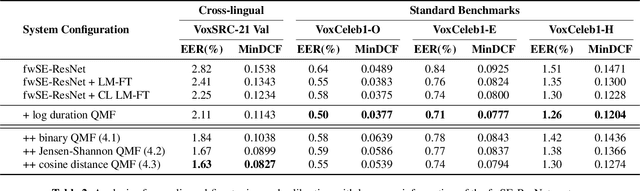
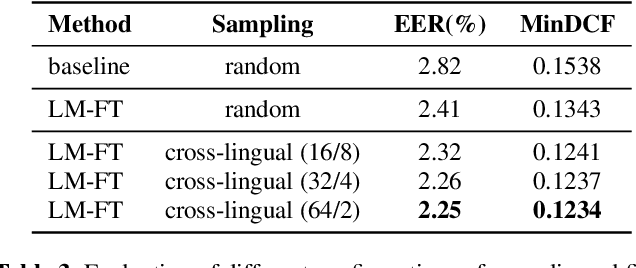
This paper contains a post-challenge performance analysis on cross-lingual speaker verification of the IDLab submission to the VoxCeleb Speaker Recognition Challenge 2021 (VoxSRC-21). We show that current speaker embedding extractors consistently underestimate speaker similarity in within-speaker cross-lingual trials. Consequently, the typical training and scoring protocols do not put enough emphasis on the compensation of intra-speaker language variability. We propose two techniques to increase cross-lingual speaker verification robustness. First, we enhance our previously proposed Large-Margin Fine-Tuning (LM-FT) training stage with a mini-batch sampling strategy which increases the amount of intra-speaker cross-lingual samples within the mini-batch. Second, we incorporate language information in the logistic regression calibration stage. We integrate quality metrics based on soft and hard decisions of a VoxLingua107 language identification model. The proposed techniques result in a 11.7% relative improvement over the baseline model on the VoxSRC-21 test set and contributed to our third place finish in the corresponding challenge.
The IDLAB VoxCeleb Speaker Recognition Challenge 2021 System Description
Sep 09, 2021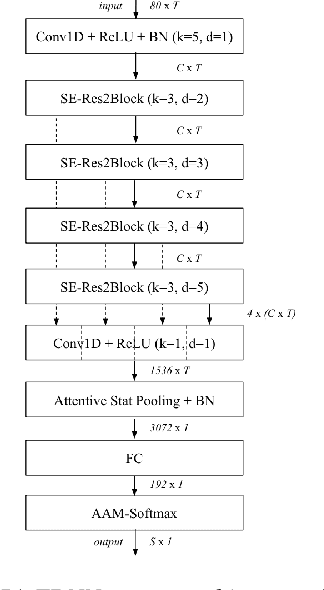
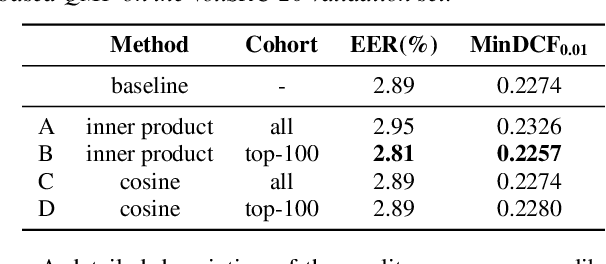
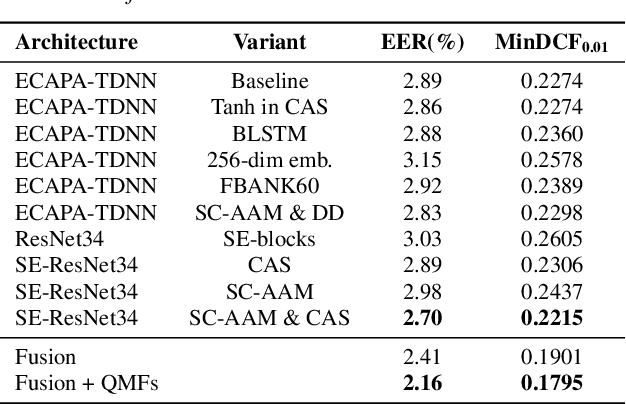
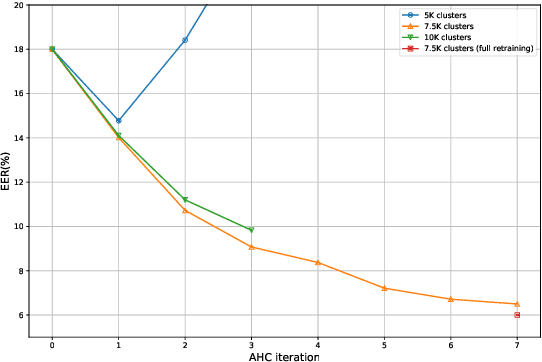
This technical report describes the IDLab submission for track 1 and 2 of the VoxCeleb Speaker Recognition Challenge 2021 (VoxSRC-21). This speaker verification competition focuses on short duration test recordings and cross-lingual trials. Currently, both Time Delay Neural Networks (TDNNs) and ResNets achieve state-of-the-art results in speaker verification. We opt to use a system fusion of hybrid architectures in our final submission. An ECAPA-TDNN baseline is enhanced with a 2D convolutional stem to transfer some of the strong characteristics of a ResNet based model to this hybrid CNN-TDNN architecture. Similarly, we incorporate absolute frequency positional information in the SE-ResNet architectures. All models are trained with a special mini-batch data sampling technique which constructs mini-batches with data that is the most challenging for the system on the level of intra-speaker variability. This intra-speaker variability is mainly caused by differences in language and background conditions between the speaker's utterances. The cross-lingual effects on the speaker verification scores are further compensated by introducing a binary cross-linguality trial feature in the logistic regression based system calibration. The final system fusion with two ECAPA CNN-TDNNs and three SE-ResNets enhanced with frequency positional information achieved a third place on the VoxSRC-21 leaderboard for both track 1 and 2 with a minDCF of 0.1291 and 0.1313 respectively.
Integrating Frequency Translational Invariance in TDNNs and Frequency Positional Information in 2D ResNets to Enhance Speaker Verification
Apr 06, 2021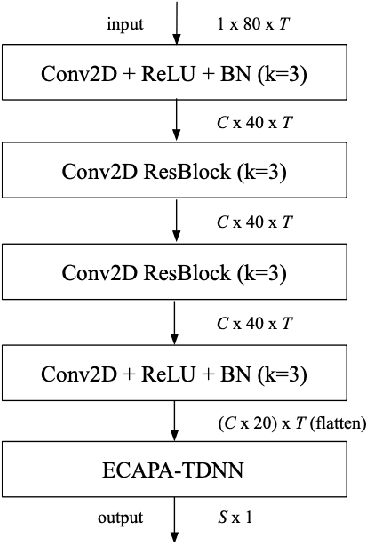
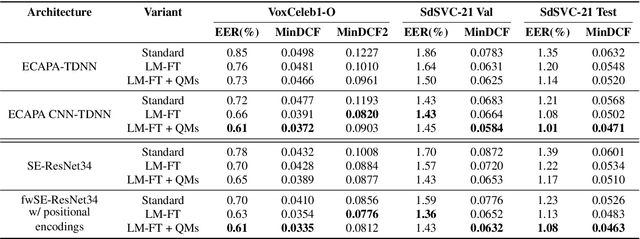

This paper describes the IDLab submission for the text-independent task of the Short-duration Speaker Verification Challenge 2021 (SdSVC-21). This speaker verification competition focuses on short duration test recordings and cross-lingual trials, along with the constraint of limited availability of in-domain DeepMine Farsi training data. Currently, both Time Delay Neural Networks (TDNNs) and ResNets achieve state-of-the-art results in speaker verification. These architectures are structurally very different and the construction of hybrid networks looks a promising way forward. We introduce a 2D convolutional stem in a strong ECAPA-TDNN baseline to transfer some of the strong characteristics of a ResNet based model to this hybrid CNN-TDNN architecture. Similarly, we incorporate absolute frequency positional encodings in an SE-ResNet34 architecture. These learnable feature map biases along the frequency axis offer this architecture a straightforward way to exploit frequency positional information. We also propose a frequency-wise variant of Squeeze-Excitation (SE) which better preserves frequency-specific information when rescaling the feature maps. Both modified architectures significantly outperform their corresponding baseline on the SdSVC-21 evaluation data and the original VoxCeleb1 test set. A four system fusion containing the two improved architectures achieved a third place in the final SdSVC-21 Task 2 ranking.
ECAPA-TDNN Embeddings for Speaker Diarization
Apr 03, 2021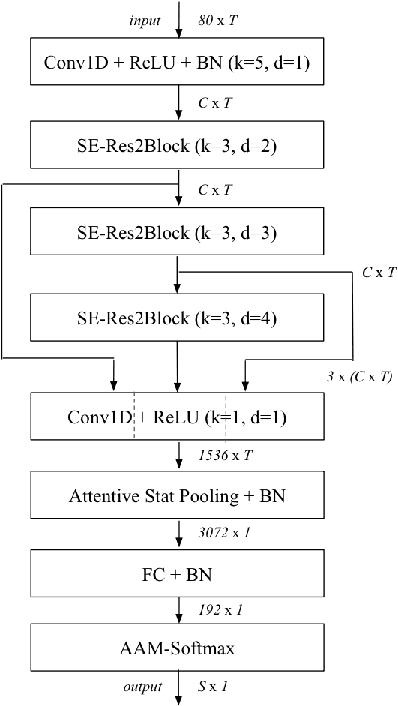
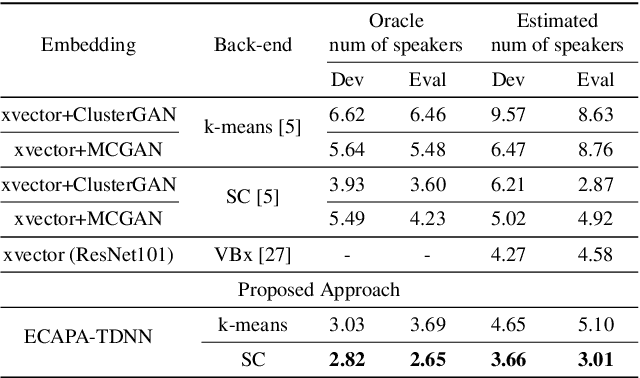
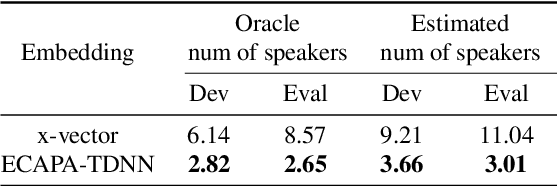
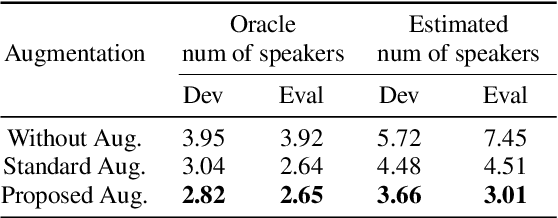
Learning robust speaker embeddings is a crucial step in speaker diarization. Deep neural networks can accurately capture speaker discriminative characteristics and popular deep embeddings such as x-vectors are nowadays a fundamental component of modern diarization systems. Recently, some improvements over the standard TDNN architecture used for x-vectors have been proposed. The ECAPA-TDNN model, for instance, has shown impressive performance in the speaker verification domain, thanks to a carefully designed neural model. In this work, we extend, for the first time, the use of the ECAPA-TDNN model to speaker diarization. Moreover, we improved its robustness with a powerful augmentation scheme that concatenates several contaminated versions of the same signal within the same training batch. The ECAPA-TDNN model turned out to provide robust speaker embeddings under both close-talking and distant-talking conditions. Our results on the popular AMI meeting corpus show that our system significantly outperforms recently proposed approaches.
Cross-Lingual Speaker Verification with Domain-Balanced Hard Prototype Mining and Language-Dependent Score Normalization
Aug 10, 2020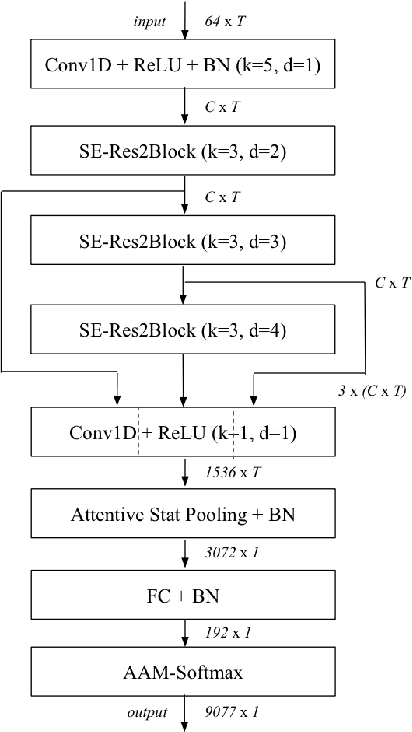
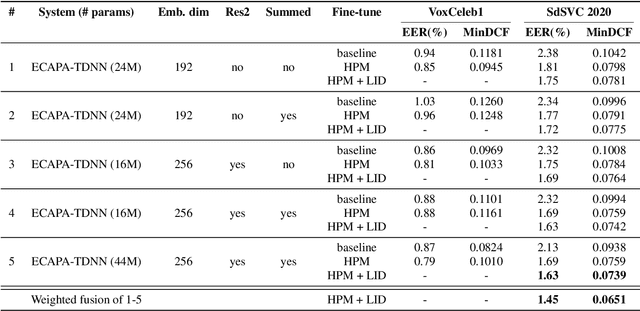
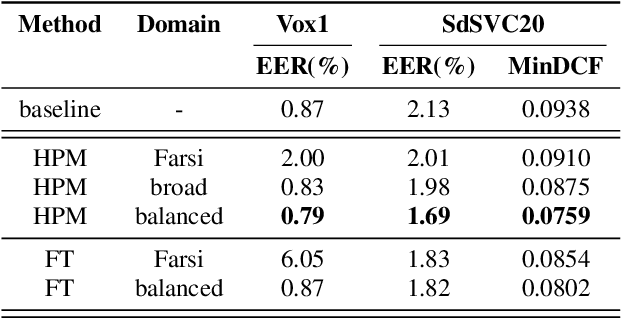
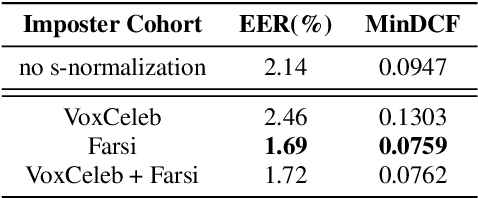
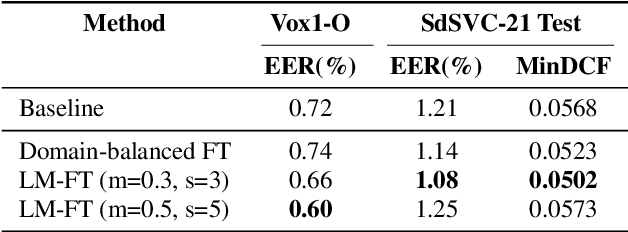
In this paper we describe the top-scoring IDLab submission for the text-independent task of the Short-duration Speaker Verification (SdSV) Challenge 2020. The main difficulty of the challenge exists in the large degree of varying phonetic overlap between the potentially cross-lingual trials, along with the limited availability of in-domain DeepMine Farsi training data. We introduce domain-balanced hard prototype mining to fine-tune the state-of-the-art ECAPA-TDNN x-vector based speaker embedding extractor. The sample mining technique efficiently exploits speaker distances between the speaker prototypes of the popular AAM-softmax loss function to construct challenging training batches that are balanced on the domain-level. To enhance the scoring of cross-lingual trials, we propose a language-dependent s-norm score normalization. The imposter cohort only contains data from the Farsi target-domain which simulates the enrollment data always being Farsi. In case a Gaussian-Backend language model detects the test speaker embedding to contain English, a cross-language compensation offset determined on the AAM-softmax speaker prototypes is subtracted from the maximum expected imposter mean score. A fusion of five systems with minor topological tweaks resulted in a final MinDCF and EER of 0.065 and 1.45% respectively on the SdSVC evaluation set.