 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLiP: Towards understanding and interpreting multimodal multilingual sentence embeddings
Apr 20, 2026This paper presents factorized linear projection (FLiP) models for understanding pretrained sentence embedding spaces. We train FLiP models to recover the lexical content from multilingual (LaBSE), multimodal (SONAR) and API-based (Gemini) sentence embedding spaces in several high- and mid-resource languages. We show that FLiP can recall more than 75% of lexical content from the embeddings, significantly outperforming existing non-factorized baselines. Using this as a diagnostic tool, we uncover the modality and language biases across the selected sentence encoders and provide practitioners with intrinsic insights about the encoders without relying on conventional downstream evaluation tasks. Our implementation is public https://github.com/BUTSpeechFIT/FLiP.
DeCRED: Decoder-Centric Regularization for Encoder-Decoder Based Speech Recognition
Aug 12, 2025



This paper presents a simple yet effective regularization for the internal language model induced by the decoder in encoder-decoder ASR models, thereby improving robustness and generalization in both in- and out-of-domain settings. The proposed method, Decoder-Centric Regularization in Encoder-Decoder (DeCRED), adds auxiliary classifiers to the decoder, enabling next token prediction via intermediate logits. Empirically, DeCRED reduces the mean internal LM BPE perplexity by 36.6% relative to 11 test sets. Furthermore, this translates into actual WER improvements over the baseline in 5 of 7 in-domain and 3 of 4 out-of-domain test sets, reducing macro WER from 6.4% to 6.3% and 18.2% to 16.2%, respectively. On TEDLIUM3, DeCRED achieves 7.0% WER, surpassing the baseline and encoder-centric InterCTC regularization by 0.6% and 0.5%, respectively. Finally, we compare DeCRED with OWSM v3.1 and Whisper-medium, showing competitive WERs despite training on much less data with fewer parameters.
Factors affecting the in-context learning abilities of LLMs for dialogue state tracking
Jun 10, 2025This study explores the application of in-context learning (ICL) to the dialogue state tracking (DST) problem and investigates the factors that influence its effectiveness. We use a sentence embedding based k-nearest neighbour method to retrieve the suitable demonstrations for ICL. The selected demonstrations, along with the test samples, are structured within a template as input to the LLM. We then conduct a systematic study to analyse the impact of factors related to demonstration selection and prompt context on DST performance. This work is conducted using the MultiWoZ2.4 dataset and focuses primarily on the OLMo-7B-instruct, Mistral-7B-Instruct-v0.3, and Llama3.2-3B-Instruct models. Our findings provide several useful insights on in-context learning abilities of LLMs for dialogue state tracking.
Approaching Dialogue State Tracking via Aligning Speech Encoders and LLMs
Jun 10, 2025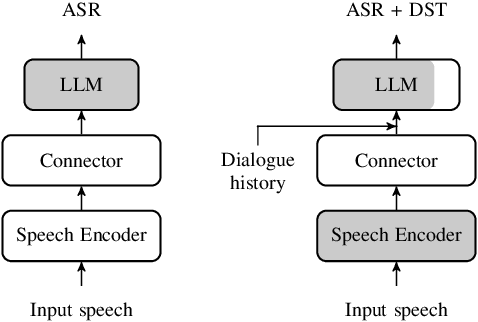
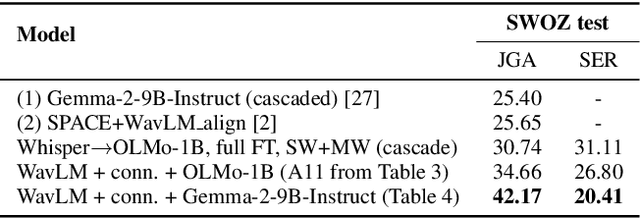
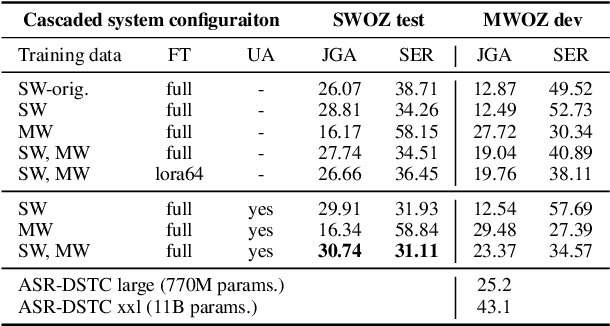
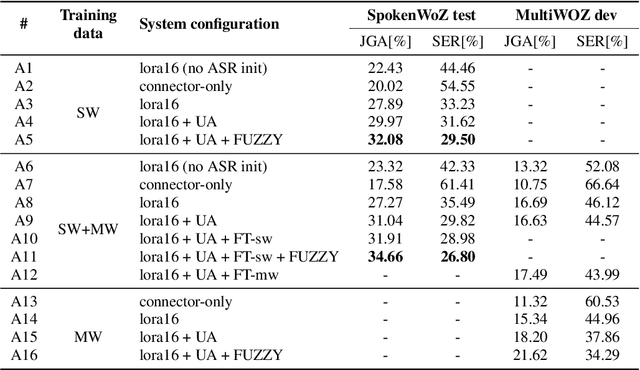
In this work, we approach spoken Dialogue State Tracking (DST) by bridging the representation spaces of speech encoders and LLMs via a small connector module, with a focus on fully open-sourced and open-data components (WavLM-large, OLMo). We focus on ablating different aspects of such systems including full/LoRA adapter fine-tuning, the effect of agent turns in the dialogue history, as well as fuzzy matching-based output post-processing, which greatly improves performance of our systems on named entities in the dialogue slot values. We conduct our experiments on the SpokenWOZ dataset, and additionally utilize the Speech-Aware MultiWOZ dataset to augment our training data. Ultimately, our best-performing WavLM + connector + OLMo-1B aligned models achieve state of the art on the SpokenWOZ test set (34.66% JGA), and our system with Gemma-2-9B-instruct further surpasses this result, reaching 42.17% JGA on SpokenWOZ test.
DiCoW: Diarization-Conditioned Whisper for Target Speaker Automatic Speech Recognition
Dec 30, 2024



Speaker-attributed automatic speech recognition (ASR) in multi-speaker environments remains a significant challenge, particularly when systems conditioned on speaker embeddings fail to generalize to unseen speakers. In this work, we propose Diarization-Conditioned Whisper (DiCoW), a novel approach to target-speaker ASR that leverages speaker diarization outputs as conditioning information. DiCoW extends the pre-trained Whisper model by integrating diarization labels directly, eliminating reliance on speaker embeddings and reducing the need for extensive speaker-specific training data. Our method introduces frame-level diarization-dependent transformations (FDDT) and query-key biasing (QKb) techniques to refine the model's focus on target speakers while effectively handling overlapping speech. By leveraging diarization outputs as conditioning signals, DiCoW simplifies the workflow for multi-speaker ASR, improves generalization to unseen speakers and enables more reliable transcription in real-world multi-speaker recordings. Additionally, we explore the integration of a connectionist temporal classification (CTC) head to Whisper and demonstrate its ability to improve transcription efficiency through hybrid decoding. Notably, we show that our approach is not limited to Whisper; it also provides similar benefits when applied to the Branchformer model. We validate DiCoW on real-world datasets, including AMI and NOTSOFAR-1 from CHiME-8 challenge, as well as synthetic benchmarks such as Libri2Mix and LibriCSS, enabling direct comparisons with previous methods. Results demonstrate that DiCoW enhances the model's target-speaker ASR capabilities while maintaining Whisper's accuracy and robustness on single-speaker data.
Written Term Detection Improves Spoken Term Detection
Jul 05, 2024



End-to-end (E2E) approaches to keyword search (KWS) are considerably simpler in terms of training and indexing complexity when compared to approaches which use the output of automatic speech recognition (ASR) systems. This simplification however has drawbacks due to the loss of modularity. In particular, where ASR-based KWS systems can benefit from external unpaired text via a language model, current formulations of E2E KWS systems have no such mechanism. Therefore, in this paper, we propose a multitask training objective which allows unpaired text to be integrated into E2E KWS without complicating indexing and search. In addition to training an E2E KWS model to retrieve text queries from spoken documents, we jointly train it to retrieve text queries from masked written documents. We show empirically that this approach can effectively leverage unpaired text for KWS, with significant improvements in search performance across a wide variety of languages. We conduct analysis which indicates that these improvements are achieved because the proposed method improves document representations for words in the unpaired text. Finally, we show that the proposed method can be used for domain adaptation in settings where in-domain paired data is scarce or nonexistent.
* IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 2024. Code at https://github.com/bolajiy/golden-retriever
Speculative Speech Recognition by Audio-Prefixed Low-Rank Adaptation of Language Models
Jul 05, 2024



This paper explores speculative speech recognition (SSR), where we empower conventional automatic speech recognition (ASR) with speculation capabilities, allowing the recognizer to run ahead of audio. We introduce a metric for measuring SSR performance and we propose a model which does SSR by combining a RNN-Transducer-based ASR system with an audio-prefixed language model (LM). The ASR system transcribes ongoing audio and feeds the resulting transcripts, along with an audio-dependent prefix, to the LM, which speculates likely completions for the transcriptions. We experiment with a variety of ASR datasets on which show the efficacy our method and the feasibility of SSR as a method of reducing ASR latency.
Pretraining End-to-End Keyword Search with Automatically Discovered Acoustic Units
Jul 05, 2024


End-to-end (E2E) keyword search (KWS) has emerged as an alternative and complimentary approach to conventional keyword search which depends on the output of automatic speech recognition (ASR) systems. While E2E methods greatly simplify the KWS pipeline, they generally have worse performance than their ASR-based counterparts, which can benefit from pretraining with untranscribed data. In this work, we propose a method for pretraining E2E KWS systems with untranscribed data, which involves using acoustic unit discovery (AUD) to obtain discrete units for untranscribed data and then learning to locate sequences of such units in the speech. We conduct experiments across languages and AUD systems: we show that finetuning such a model significantly outperforms a model trained from scratch, and the performance improvements are generally correlated with the quality of the AUD system used for pretraining.
End-to-End Open Vocabulary Keyword Search With Multilingual Neural Representations
Aug 15, 2023



Conventional keyword search systems operate on automatic speech recognition (ASR) outputs, which causes them to have a complex indexing and search pipeline. This has led to interest in ASR-free approaches to simplify the search procedure. We recently proposed a neural ASR-free keyword search model which achieves competitive performance while maintaining an efficient and simplified pipeline, where queries and documents are encoded with a pair of recurrent neural network encoders and the encodings are combined with a dot-product. In this article, we extend this work with multilingual pretraining and detailed analysis of the model. Our experiments show that the proposed multilingual training significantly improves the model performance and that despite not matching a strong ASR-based conventional keyword search system for short queries and queries comprising in-vocabulary words, the proposed model outperforms the ASR-based system for long queries and queries that do not appear in the training data.
* Accepted by IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 2023
On-the-fly Text Retrieval for End-to-End ASR Adaptation
Mar 20, 2023



End-to-end speech recognition models are improved by incorporating external text sources, typically by fusion with an external language model. Such language models have to be retrained whenever the corpus of interest changes. Furthermore, since they store the entire corpus in their parameters, rare words can be challenging to recall. In this work, we propose augmenting a transducer-based ASR model with a retrieval language model, which directly retrieves from an external text corpus plausible completions for a partial ASR hypothesis. These completions are then integrated into subsequent predictions by an adapter, which is trained once, so that the corpus of interest can be switched without incurring the computational overhead of retraining. Our experiments show that the proposed model significantly improves the performance of a transducer baseline on a pair of question-answering datasets. Further, it outperforms shallow fusion on recognition of named entities by about 7 relative; when the two are combined, the relative improvement increases to 13%.