 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Audio-Visual Speech Separation in Noisy Environments with a Lightweight Iterative Model
May 31, 2023

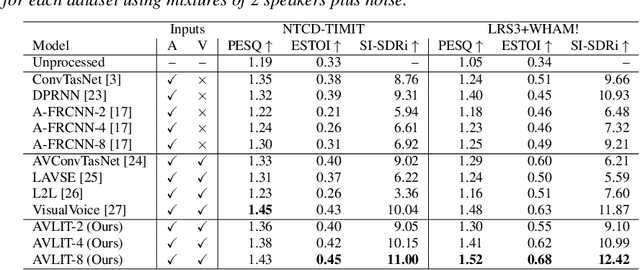
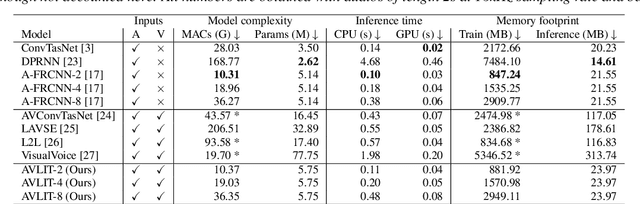
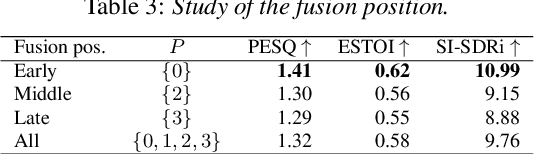
We propose Audio-Visual Lightweight ITerative model (AVLIT), an effective and lightweight neural network that uses Progressive Learning (PL) to perform audio-visual speech separation in noisy environments. To this end, we adopt the Asynchronous Fully Recurrent Convolutional Neural Network (A-FRCNN), which has shown successful results in audio-only speech separation. Our architecture consists of an audio branch and a video branch, with iterative A-FRCNN blocks sharing weights for each modality. We evaluated our model in a controlled environment using the NTCD-TIMIT dataset and in-the-wild using a synthetic dataset that combines LRS3 and WHAM!. The experiments demonstrate the superiority of our model in both settings with respect to various audio-only and audio-visual baselines. Furthermore, the reduced footprint of our model makes it suitable for low resource applications.
Emotions Beyond Words: Non-Speech Audio Emotion Recognition With Edge Computing
May 01, 2023

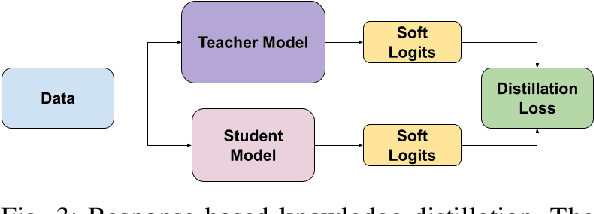
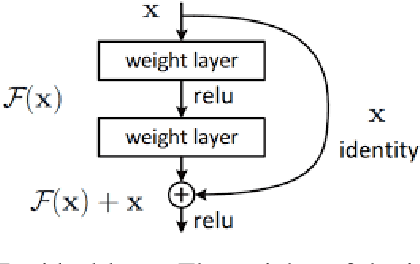
Non-speech emotion recognition has a wide range of applications including healthcare, crime control and rescue, and entertainment, to name a few. Providing these applications using edge computing has great potential, however, recent studies are focused on speech-emotion recognition using complex architectures. In this paper, a non-speech-based emotion recognition system is proposed, which can rely on edge computing to analyse emotions conveyed through non-speech expressions like screaming and crying. In particular, we explore knowledge distillation to design a computationally efficient system that can be deployed on edge devices with limited resources without degrading the performance significantly. We comprehensively evaluate our proposed framework using two publicly available datasets and highlight its effectiveness by comparing the results with the well-known MobileNet model. Our results demonstrate the feasibility and effectiveness of using edge computing for non-speech emotion detection, which can potentially improve applications that rely on emotion detection in communication networks. To the best of our knowledge, this is the first work on an edge-computing-based framework for detecting emotions in non-speech audio, offering promising directions for future research.
Variance-Preserving-Based Interpolation Diffusion Models for Speech Enhancement
Jun 14, 2023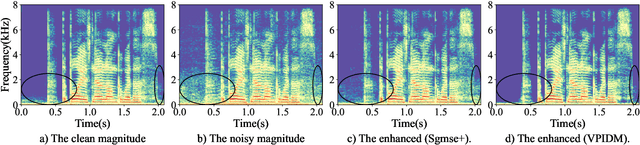
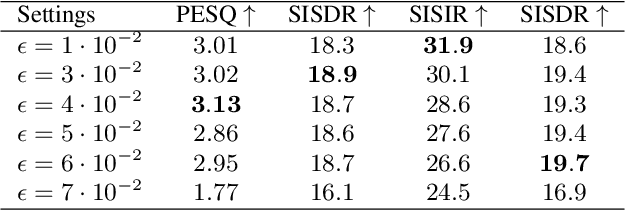
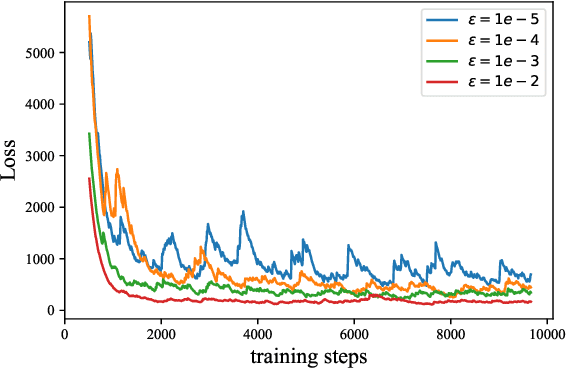
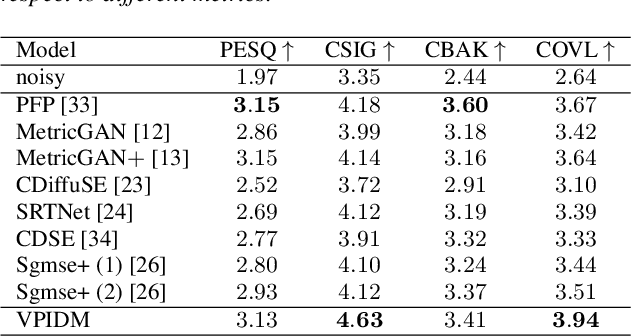
The goal of this study is to implement diffusion models for speech enhancement (SE). The first step is to emphasize the theoretical foundation of variance-preserving (VP)-based interpolation diffusion under continuous conditions. Subsequently, we present a more concise framework that encapsulates both the VP- and variance-exploding (VE)-based interpolation diffusion methods. We demonstrate that these two methods are special cases of the proposed framework. Additionally, we provide a practical example of VP-based interpolation diffusion for the SE task. To improve performance and ease model training, we analyze the common difficulties encountered in diffusion models and suggest amenable hyper-parameters. Finally, we evaluate our model against several methods using a public benchmark to showcase the effectiveness of our approach
iSTFTNet2: Faster and More Lightweight iSTFT-Based Neural Vocoder Using 1D-2D CNN
Aug 14, 2023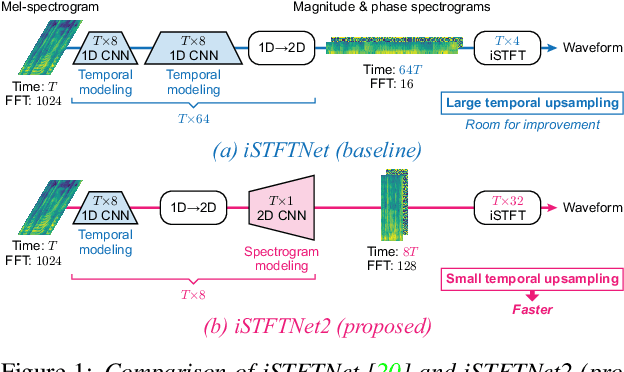
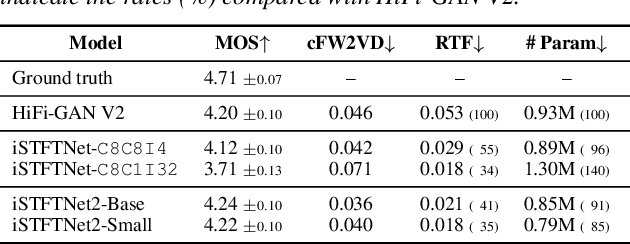
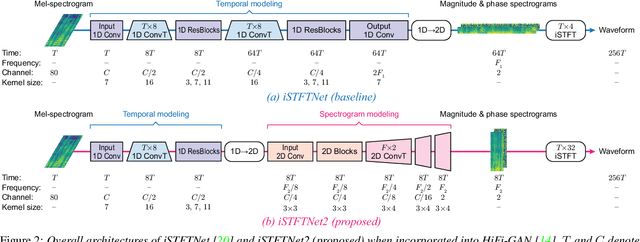
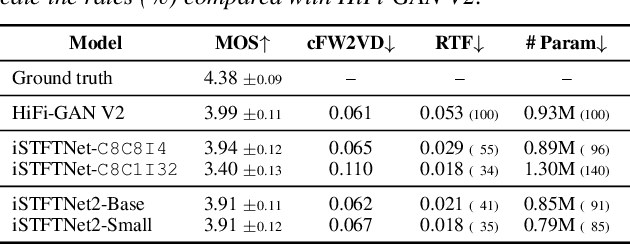
The inverse short-time Fourier transform network (iSTFTNet) has garnered attention owing to its fast, lightweight, and high-fidelity speech synthesis. It obtains these characteristics using a fast and lightweight 1D CNN as the backbone and replacing some neural processes with iSTFT. Owing to the difficulty of a 1D CNN to model high-dimensional spectrograms, the frequency dimension is reduced via temporal upsampling. However, this strategy compromises the potential to enhance the speed. Therefore, we propose iSTFTNet2, an improved variant of iSTFTNet with a 1D-2D CNN that employs 1D and 2D CNNs to model temporal and spectrogram structures, respectively. We designed a 2D CNN that performs frequency upsampling after conversion in a few-frequency space. This design facilitates the modeling of high-dimensional spectrograms without compromising the speed. The results demonstrated that iSTFTNet2 made iSTFTNet faster and more lightweight with comparable speech quality. Audio samples are available at https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/istftnet2/.
Cascaded Cross-Modal Transformer for Request and Complaint Detection
Jul 27, 2023


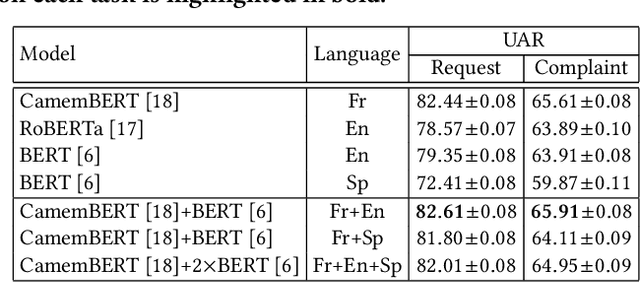
We propose a novel cascaded cross-modal transformer (CCMT) that combines speech and text transcripts to detect customer requests and complaints in phone conversations. Our approach leverages a multimodal paradigm by transcribing the speech using automatic speech recognition (ASR) models and translating the transcripts into different languages. Subsequently, we combine language-specific BERT-based models with Wav2Vec2.0 audio features in a novel cascaded cross-attention transformer model. We apply our system to the Requests Sub-Challenge of the ACM Multimedia 2023 Computational Paralinguistics Challenge, reaching unweighted average recalls (UAR) of 65.41% and 85.87% for the complaint and request classes, respectively.
Employing Hybrid Deep Neural Networks on Dari Speech
May 04, 2023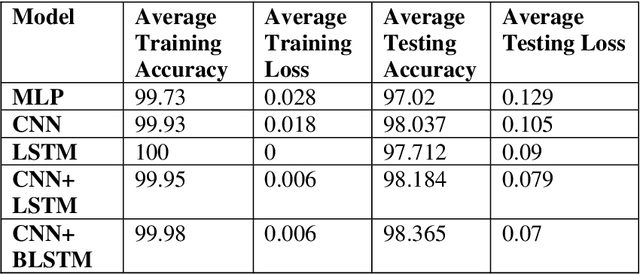
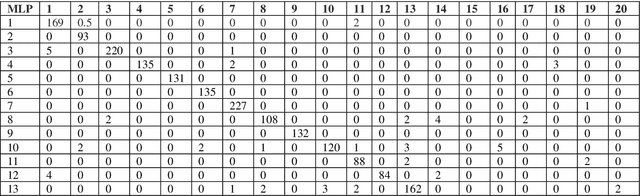

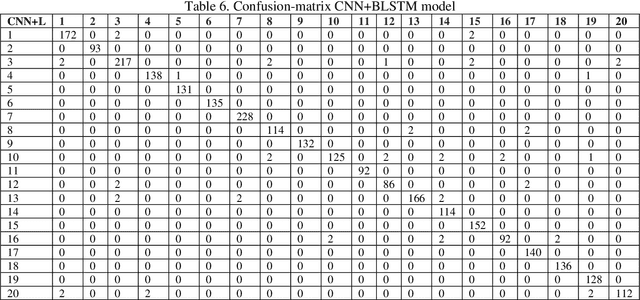
This paper is an extension of our previous conference paper. In recent years, there has been a growing interest among researchers in developing and improving speech recognition systems to facilitate and enhance human-computer interaction. Today, Automatic Speech Recognition (ASR) systems have become ubiquitous, used in everything from games to translation systems, robots, and more. However, much research is still needed on speech recognition systems for low-resource languages. This article focuses on the recognition of individual words in the Dari language using the Mel-frequency cepstral coefficients (MFCCs) feature extraction method and three different deep neural network models: Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), and Multilayer Perceptron (MLP), as well as two hybrid models combining CNN and RNN. We evaluate these models using an isolated Dari word corpus that we have created, consisting of 1000 utterances for 20 short Dari terms. Our study achieved an impressive average accuracy of 98.365%.
DiscoverPath: A Knowledge Refinement and Retrieval System for Interdisciplinarity on Biomedical Research
Sep 04, 2023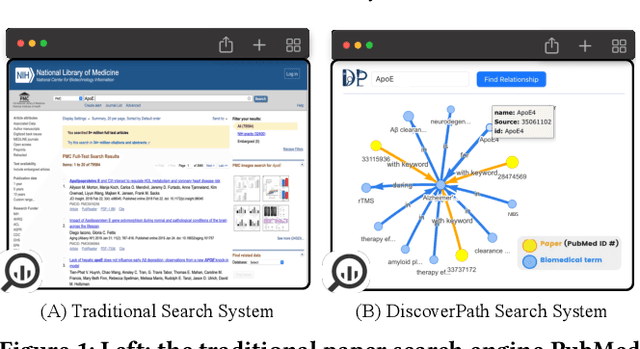
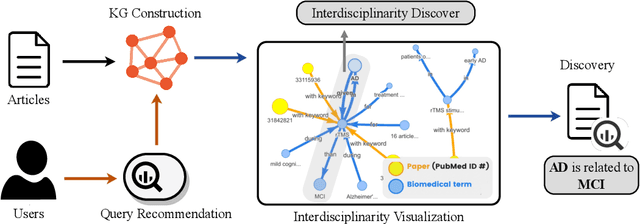
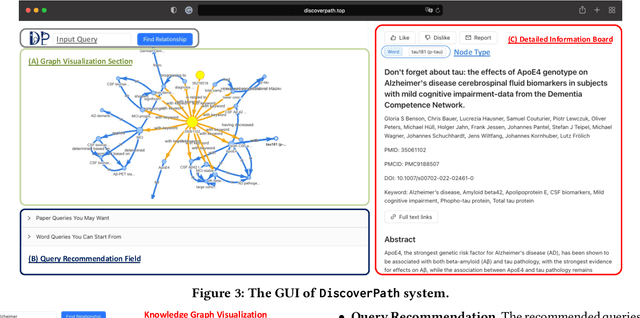
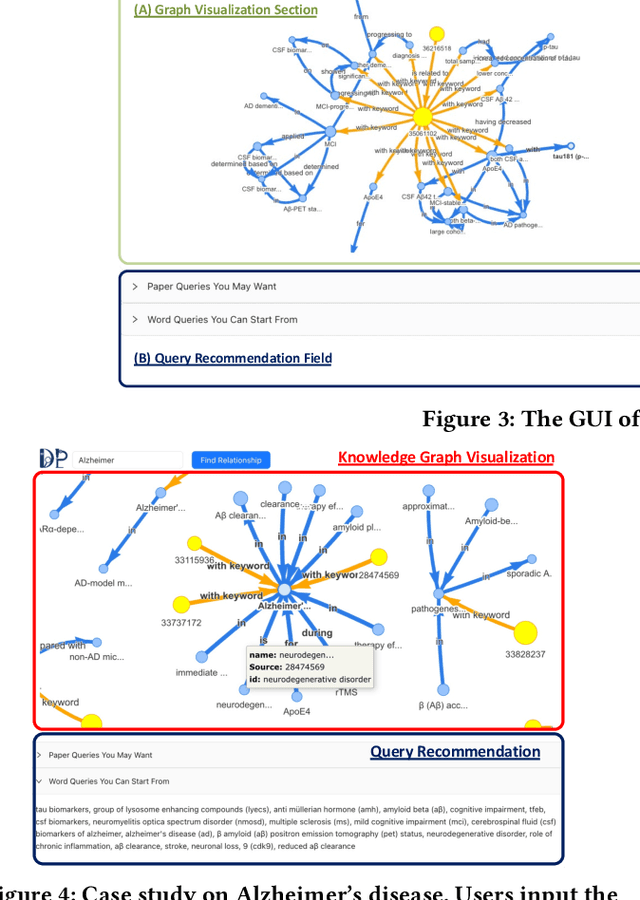
The exponential growth in scholarly publications necessitates advanced tools for efficient article retrieval, especially in interdisciplinary fields where diverse terminologies are used to describe similar research. Traditional keyword-based search engines often fall short in assisting users who may not be familiar with specific terminologies. To address this, we present a knowledge graph-based paper search engine for biomedical research to enhance the user experience in discovering relevant queries and articles. The system, dubbed DiscoverPath, employs Named Entity Recognition (NER) and part-of-speech (POS) tagging to extract terminologies and relationships from article abstracts to create a KG. To reduce information overload, DiscoverPath presents users with a focused subgraph containing the queried entity and its neighboring nodes and incorporates a query recommendation system, enabling users to iteratively refine their queries. The system is equipped with an accessible Graphical User Interface that provides an intuitive visualization of the KG, query recommendations, and detailed article information, enabling efficient article retrieval, thus fostering interdisciplinary knowledge exploration. DiscoverPath is open-sourced at https://github.com/ynchuang/DiscoverPath.
CIF-PT: Bridging Speech and Text Representations for Spoken Language Understanding via Continuous Integrate-and-Fire Pre-Training
May 27, 2023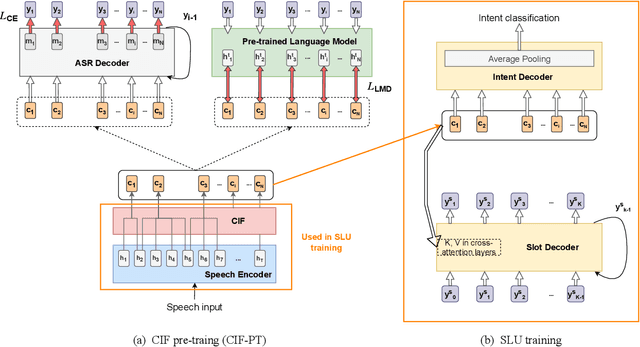
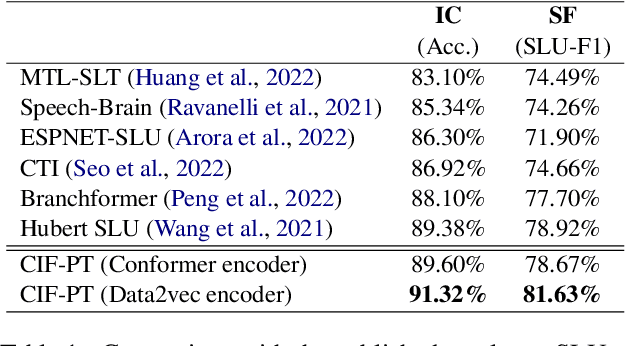
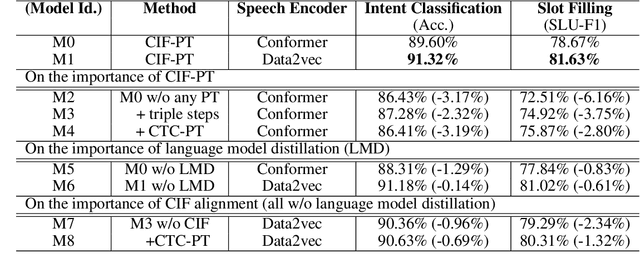
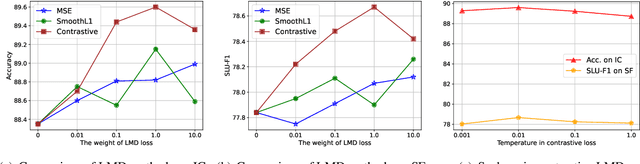
Speech or text representation generated by pre-trained models contains modal-specific information that could be combined for benefiting spoken language understanding (SLU) tasks. In this work, we propose a novel pre-training paradigm termed Continuous Integrate-and-Fire Pre-Training (CIF-PT). It relies on a simple but effective frame-to-token alignment: continuous integrate-and-fire (CIF) to bridge the representations between speech and text. It jointly performs speech-to-text training and language model distillation through CIF as the pre-training (PT). Evaluated on SLU benchmark SLURP dataset, CIF-PT outperforms the state-of-the-art model by 1.94% of accuracy and 2.71% of SLU-F1 on the tasks of intent classification and slot filling, respectively. We also observe the cross-modal representation extracted by CIF-PT obtains better performance than other neural interfaces for the tasks of SLU, including the dominant speech representation learned from self-supervised pre-training.
Improving Fairness and Robustness in End-to-End Speech Recognition through unsupervised clustering
Jun 06, 2023
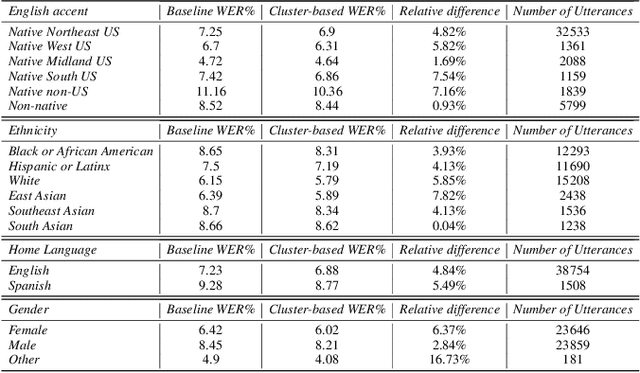
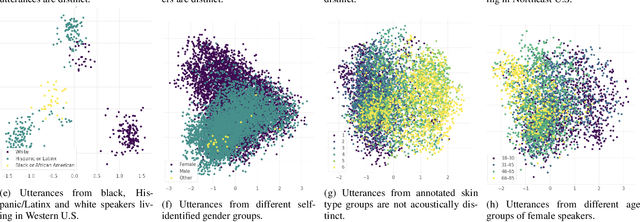
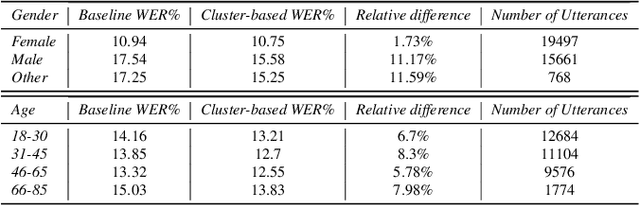
The challenge of fairness arises when Automatic Speech Recognition (ASR) systems do not perform equally well for all sub-groups of the population. In the past few years there have been many improvements in overall speech recognition quality, but without any particular focus on advancing Equality and Equity for all user groups for whom systems do not perform well. ASR fairness is therefore also a robustness issue. Meanwhile, data privacy also takes priority in production systems. In this paper, we present a privacy preserving approach to improve fairness and robustness of end-to-end ASR without using metadata, zip codes, or even speaker or utterance embeddings directly in training. We extract utterance level embeddings using a speaker ID model trained on a public dataset, which we then use in an unsupervised fashion to create acoustic clusters. We use cluster IDs instead of speaker utterance embeddings as extra features during model training, which shows improvements for all demographic groups and in particular for different accents.
XPhoneBERT: A Pre-trained Multilingual Model for Phoneme Representations for Text-to-Speech
May 31, 2023

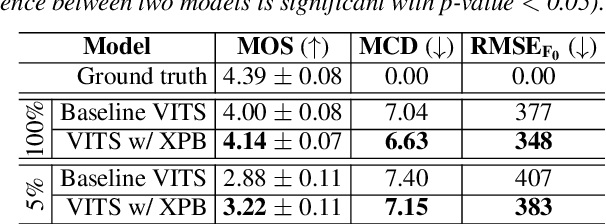
We present XPhoneBERT, the first multilingual model pre-trained to learn phoneme representations for the downstream text-to-speech (TTS) task. Our XPhoneBERT has the same model architecture as BERT-base, trained using the RoBERTa pre-training approach on 330M phoneme-level sentences from nearly 100 languages and locales. Experimental results show that employing XPhoneBERT as an input phoneme encoder significantly boosts the performance of a strong neural TTS model in terms of naturalness and prosody and also helps produce fairly high-quality speech with limited training data. We publicly release our pre-trained XPhoneBERT with the hope that it would facilitate future research and downstream TTS applications for multiple languages. Our XPhoneBERT model is available at https://github.com/VinAIResearch/XPhoneBERT