 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentVoiceGrad: Nonparallel Voice Conversion with Latent Diffusion/Flow-Matching Models
Sep 10, 2025Previously, we introduced VoiceGrad, a nonparallel voice conversion (VC) technique enabling mel-spectrogram conversion from source to target speakers using a score-based diffusion model. The concept involves training a score network to predict the gradient of the log density of mel-spectrograms from various speakers. VC is executed by iteratively adjusting an input mel-spectrogram until resembling the target speaker's. However, challenges persist: audio quality needs improvement, and conversion is slower compared to modern VC methods designed to operate at very high speeds. To address these, we introduce latent diffusion models into VoiceGrad, proposing an improved version with reverse diffusion in the autoencoder bottleneck. Additionally, we propose using a flow matching model as an alternative to the diffusion model to further speed up the conversion process without compromising the conversion quality. Experimental results show enhanced speech quality and accelerated conversion compared to the original.
FasterVoiceGrad: Faster One-step Diffusion-Based Voice Conversion with Adversarial Diffusion Conversion Distillation
Aug 25, 2025A diffusion-based voice conversion (VC) model (e.g., VoiceGrad) can achieve high speech quality and speaker similarity; however, its conversion process is slow owing to iterative sampling. FastVoiceGrad overcomes this limitation by distilling VoiceGrad into a one-step diffusion model. However, it still requires a computationally intensive content encoder to disentangle the speaker's identity and content, which slows conversion. Therefore, we propose FasterVoiceGrad, a novel one-step diffusion-based VC model obtained by simultaneously distilling a diffusion model and content encoder using adversarial diffusion conversion distillation (ADCD), where distillation is performed in the conversion process while leveraging adversarial and score distillation training. Experimental evaluations of one-shot VC demonstrated that FasterVoiceGrad achieves competitive VC performance compared to FastVoiceGrad, with 6.6-6.9 and 1.8 times faster speed on a GPU and CPU, respectively.
Vocoder-Projected Feature Discriminator
Aug 25, 2025



In text-to-speech (TTS) and voice conversion (VC), acoustic features, such as mel spectrograms, are typically used as synthesis or conversion targets owing to their compactness and ease of learning. However, because the ultimate goal is to generate high-quality waveforms, employing a vocoder to convert these features into waveforms and applying adversarial training in the time domain is reasonable. Nevertheless, upsampling the waveform introduces significant time and memory overheads. To address this issue, we propose a vocoder-projected feature discriminator (VPFD), which uses vocoder features for adversarial training. Experiments on diffusion-based VC distillation demonstrated that a pretrained and frozen vocoder feature extractor with a single upsampling step is necessary and sufficient to achieve a VC performance comparable to that of waveform discriminators while reducing the training time and memory consumption by 9.6 and 11.4 times, respectively.
FastVoiceGrad: One-step Diffusion-Based Voice Conversion with Adversarial Conditional Diffusion Distillation
Sep 03, 2024



Diffusion-based voice conversion (VC) techniques such as VoiceGrad have attracted interest because of their high VC performance in terms of speech quality and speaker similarity. However, a notable limitation is the slow inference caused by the multi-step reverse diffusion. Therefore, we propose FastVoiceGrad, a novel one-step diffusion-based VC that reduces the number of iterations from dozens to one while inheriting the high VC performance of the multi-step diffusion-based VC. We obtain the model using adversarial conditional diffusion distillation (ACDD), leveraging the ability of generative adversarial networks and diffusion models while reconsidering the initial states in sampling. Evaluations of one-shot any-to-any VC demonstrate that FastVoiceGrad achieves VC performance superior to or comparable to that of previous multi-step diffusion-based VC while enhancing the inference speed. Audio samples are available at https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/fastvoicegrad/.
Training Generative Adversarial Network-Based Vocoder with Limited Data Using Augmentation-Conditional Discriminator
Mar 25, 2024A generative adversarial network (GAN)-based vocoder trained with an adversarial discriminator is commonly used for speech synthesis because of its fast, lightweight, and high-quality characteristics. However, this data-driven model requires a large amount of training data incurring high data-collection costs. This fact motivates us to train a GAN-based vocoder on limited data. A promising solution is to augment the training data to avoid overfitting. However, a standard discriminator is unconditional and insensitive to distributional changes caused by data augmentation. Thus, augmented speech (which can be extraordinary) may be considered real speech. To address this issue, we propose an augmentation-conditional discriminator (AugCondD) that receives the augmentation state as input in addition to speech, thereby assessing the input speech according to the augmentation state, without inhibiting the learning of the original non-augmented distribution. Experimental results indicate that AugCondD improves speech quality under limited data conditions while achieving comparable speech quality under sufficient data conditions. Audio samples are available at https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/augcondd/.
iSTFTNet2: Faster and More Lightweight iSTFT-Based Neural Vocoder Using 1D-2D CNN
Aug 14, 2023The inverse short-time Fourier transform network (iSTFTNet) has garnered attention owing to its fast, lightweight, and high-fidelity speech synthesis. It obtains these characteristics using a fast and lightweight 1D CNN as the backbone and replacing some neural processes with iSTFT. Owing to the difficulty of a 1D CNN to model high-dimensional spectrograms, the frequency dimension is reduced via temporal upsampling. However, this strategy compromises the potential to enhance the speed. Therefore, we propose iSTFTNet2, an improved variant of iSTFTNet with a 1D-2D CNN that employs 1D and 2D CNNs to model temporal and spectrogram structures, respectively. We designed a 2D CNN that performs frequency upsampling after conversion in a few-frequency space. This design facilitates the modeling of high-dimensional spectrograms without compromising the speed. The results demonstrated that iSTFTNet2 made iSTFTNet faster and more lightweight with comparable speech quality. Audio samples are available at https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/istftnet2/.
Wave-U-Net Discriminator: Fast and Lightweight Discriminator for Generative Adversarial Network-Based Speech Synthesis
Mar 24, 2023



In speech synthesis, a generative adversarial network (GAN), training a generator (speech synthesizer) and a discriminator in a min-max game, is widely used to improve speech quality. An ensemble of discriminators is commonly used in recent neural vocoders (e.g., HiFi-GAN) and end-to-end text-to-speech (TTS) systems (e.g., VITS) to scrutinize waveforms from multiple perspectives. Such discriminators allow synthesized speech to adequately approach real speech; however, they require an increase in the model size and computation time according to the increase in the number of discriminators. Alternatively, this study proposes a Wave-U-Net discriminator, which is a single but expressive discriminator with Wave-U-Net architecture. This discriminator is unique; it can assess a waveform in a sample-wise manner with the same resolution as the input signal, while extracting multilevel features via an encoder and decoder with skip connections. This architecture provides a generator with sufficiently rich information for the synthesized speech to be closely matched to the real speech. During the experiments, the proposed ideas were applied to a representative neural vocoder (HiFi-GAN) and an end-to-end TTS system (VITS). The results demonstrate that the proposed models can achieve comparable speech quality with a 2.31 times faster and 14.5 times more lightweight discriminator when used in HiFi-GAN and a 1.90 times faster and 9.62 times more lightweight discriminator when used in VITS. Audio samples are available at https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/waveunetd/.
iSTFTNet: Fast and Lightweight Mel-Spectrogram Vocoder Incorporating Inverse Short-Time Fourier Transform
Mar 04, 2022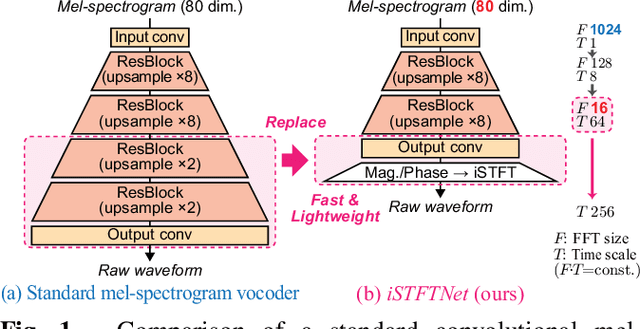
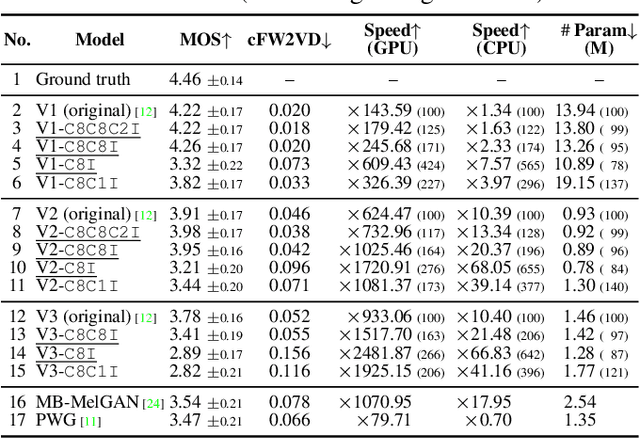
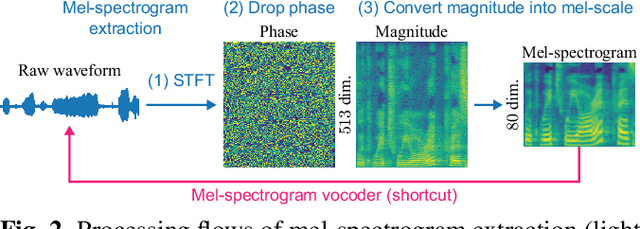

In recent text-to-speech synthesis and voice conversion systems, a mel-spectrogram is commonly applied as an intermediate representation, and the necessity for a mel-spectrogram vocoder is increasing. A mel-spectrogram vocoder must solve three inverse problems: recovery of the original-scale magnitude spectrogram, phase reconstruction, and frequency-to-time conversion. A typical convolutional mel-spectrogram vocoder solves these problems jointly and implicitly using a convolutional neural network, including temporal upsampling layers, when directly calculating a raw waveform. Such an approach allows skipping redundant processes during waveform synthesis (e.g., the direct reconstruction of high-dimensional original-scale spectrograms). By contrast, the approach solves all problems in a black box and cannot effectively employ the time-frequency structures existing in a mel-spectrogram. We thus propose iSTFTNet, which replaces some output-side layers of the mel-spectrogram vocoder with the inverse short-time Fourier transform (iSTFT) after sufficiently reducing the frequency dimension using upsampling layers, reducing the computational cost from black-box modeling and avoiding redundant estimations of high-dimensional spectrograms. During our experiments, we applied our ideas to three HiFi-GAN variants and made the models faster and more lightweight with a reasonable speech quality. Audio samples are available at https://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/istftnet/.
FastS2S-VC: Streaming Non-Autoregressive Sequence-to-Sequence Voice Conversion
Apr 14, 2021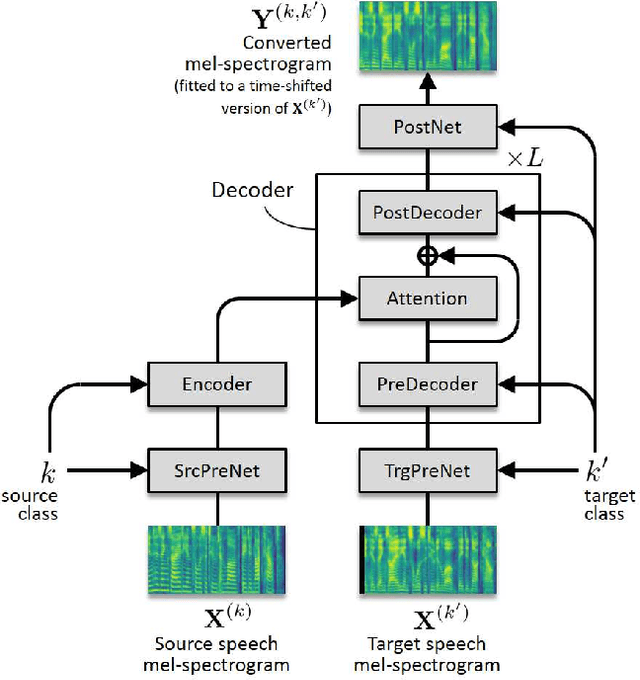
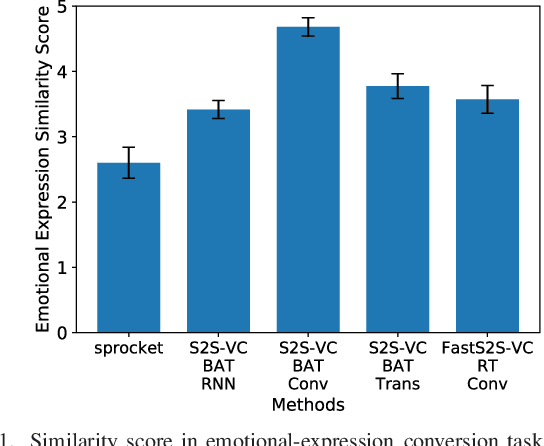
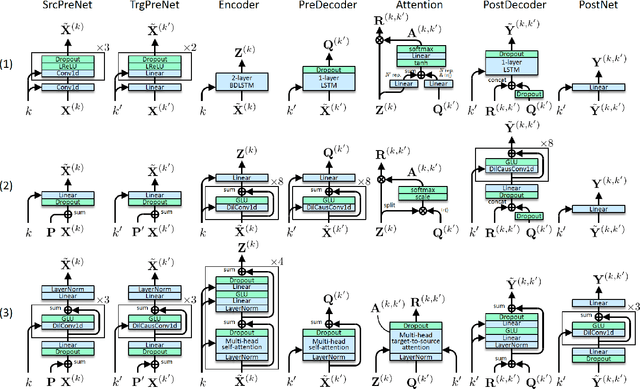
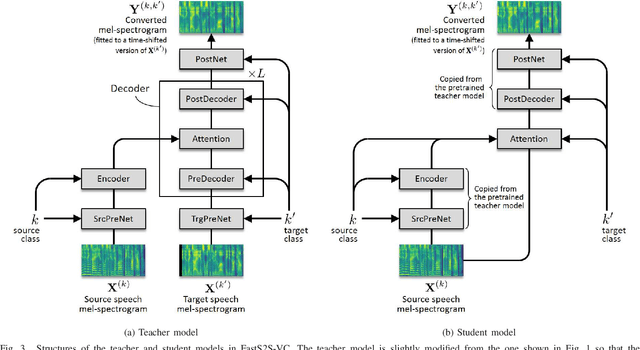
This paper proposes a non-autoregressive extension of our previously proposed sequence-to-sequence (S2S) model-based voice conversion (VC) methods. S2S model-based VC methods have attracted particular attention in recent years for their flexibility in converting not only the voice identity but also the pitch contour and local duration of input speech, thanks to the ability of the encoder-decoder architecture with the attention mechanism. However, one of the obstacles to making these methods work in real-time is the autoregressive (AR) structure. To overcome this obstacle, we develop a method to obtain a model that is free from an AR structure and behaves similarly to the original S2S models, based on a teacher-student learning framework. In our method, called "FastS2S-VC", the student model consists of encoder, decoder, and attention predictor. The attention predictor learns to predict attention distributions solely from source speech along with a target class index with the guidance of those predicted by the teacher model from both source and target speech. Thanks to this structure, the model is freed from an AR structure and allows for parallelization. Furthermore, we show that FastS2S-VC is suitable for real-time implementation based on a sliding-window approach, and describe how to make it run in real-time. Through speaker-identity and emotional-expression conversion experiments, we confirmed that FastS2S-VC was able to speed up the conversion process by 70 to 100 times compared to the original AR-type S2S-VC methods, without significantly degrading the audio quality and similarity to target speech. We also confirmed that the real-time version of FastS2S-VC can be run with a latency of 32 ms when run on a GPU.
MaskCycleGAN-VC: Learning Non-parallel Voice Conversion with Filling in Frames
Feb 25, 2021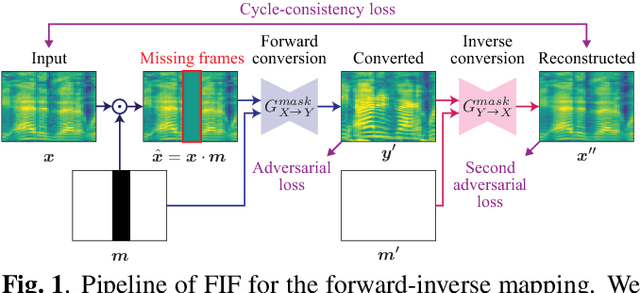
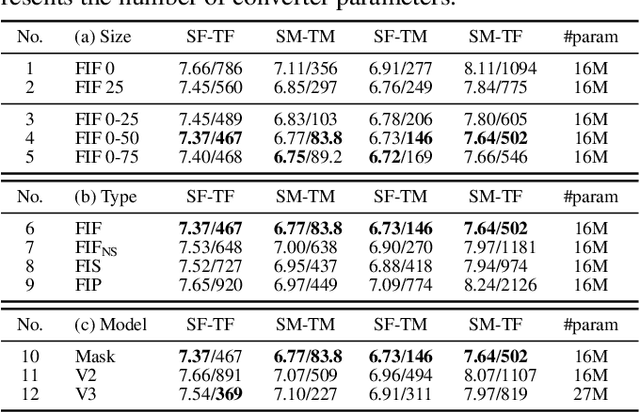
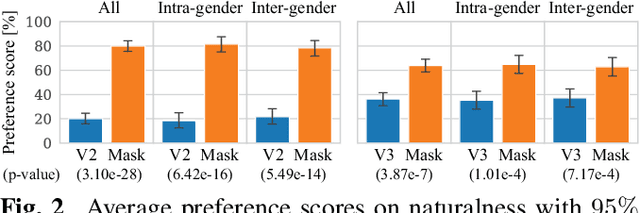
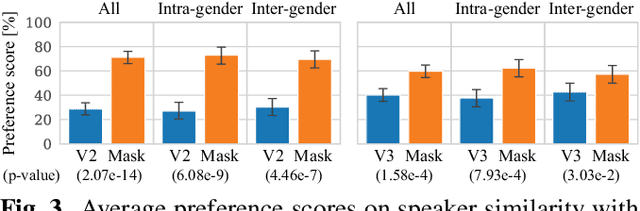
Non-parallel voice conversion (VC) is a technique for training voice converters without a parallel corpus. Cycle-consistent adversarial network-based VCs (CycleGAN-VC and CycleGAN-VC2) are widely accepted as benchmark methods. However, owing to their insufficient ability to grasp time-frequency structures, their application is limited to mel-cepstrum conversion and not mel-spectrogram conversion despite recent advances in mel-spectrogram vocoders. To overcome this, CycleGAN-VC3, an improved variant of CycleGAN-VC2 that incorporates an additional module called time-frequency adaptive normalization (TFAN), has been proposed. However, an increase in the number of learned parameters is imposed. As an alternative, we propose MaskCycleGAN-VC, which is another extension of CycleGAN-VC2 and is trained using a novel auxiliary task called filling in frames (FIF). With FIF, we apply a temporal mask to the input mel-spectrogram and encourage the converter to fill in missing frames based on surrounding frames. This task allows the converter to learn time-frequency structures in a self-supervised manner and eliminates the need for an additional module such as TFAN. A subjective evaluation of the naturalness and speaker similarity showed that MaskCycleGAN-VC outperformed both CycleGAN-VC2 and CycleGAN-VC3 with a model size similar to that of CycleGAN-VC2. Audio samples are available at http://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/maskcyclegan-vc/index.html.