 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
On the Relation between Internal Language Model and Sequence Discriminative Training for Neural Transducers
Sep 25, 2023
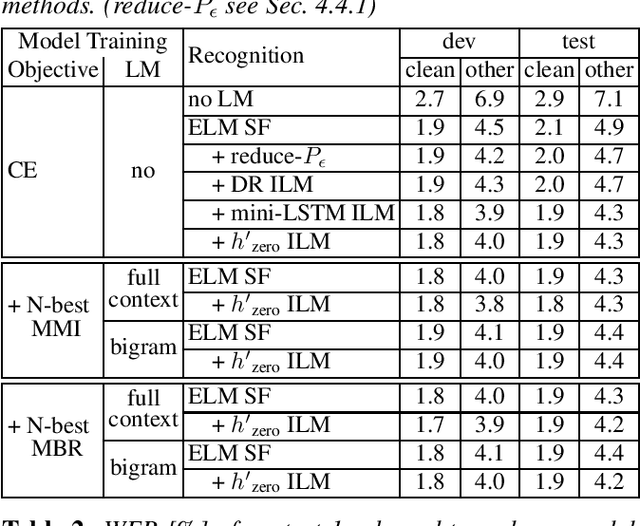
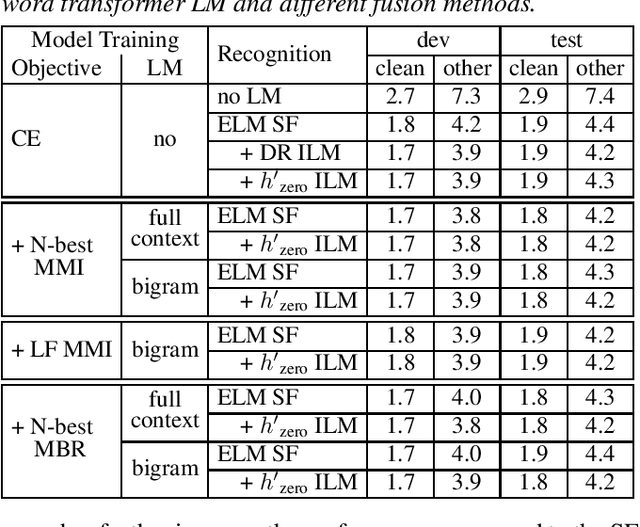
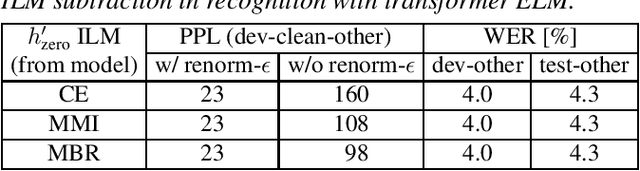
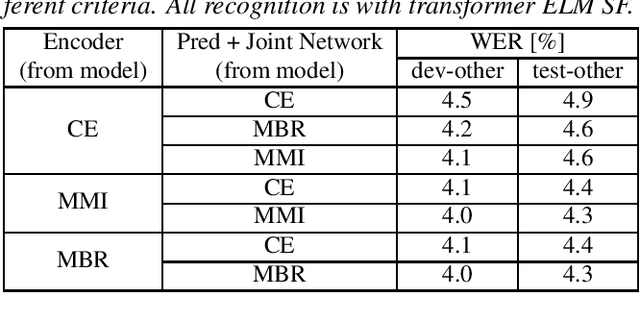
Internal language model (ILM) subtraction has been widely applied to improve the performance of the RNN-Transducer with external language model (LM) fusion for speech recognition. In this work, we show that sequence discriminative training has a strong correlation with ILM subtraction from both theoretical and empirical points of view. Theoretically, we derive that the global optimum of maximum mutual information (MMI) training shares a similar formula as ILM subtraction. Empirically, we show that ILM subtraction and sequence discriminative training achieve similar performance across a wide range of experiments on Librispeech, including both MMI and minimum Bayes risk (MBR) criteria, as well as neural transducers and LMs of both full and limited context. The benefit of ILM subtraction also becomes much smaller after sequence discriminative training. We also provide an in-depth study to show that sequence discriminative training has a minimal effect on the commonly used zero-encoder ILM estimation, but a joint effect on both encoder and prediction + joint network for posterior probability reshaping including both ILM and blank suppression.
In-Ear-Voice: Towards Milli-Watt Audio Enhancement With Bone-Conduction Microphones for In-Ear Sensing Platforms
Sep 05, 2023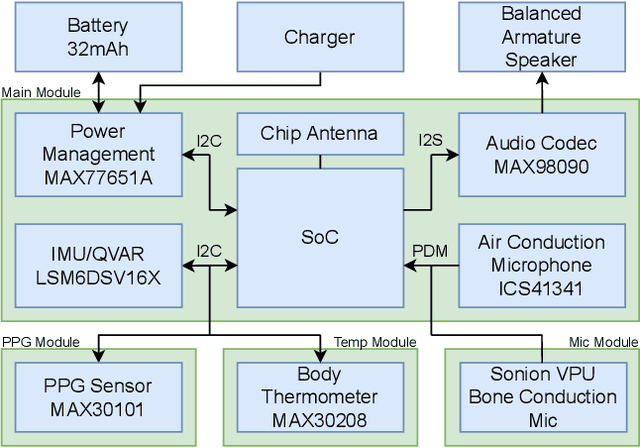
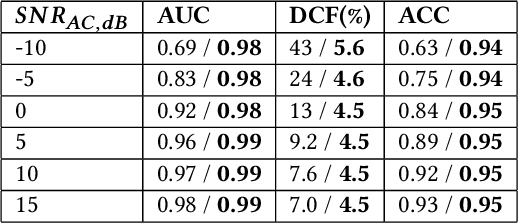
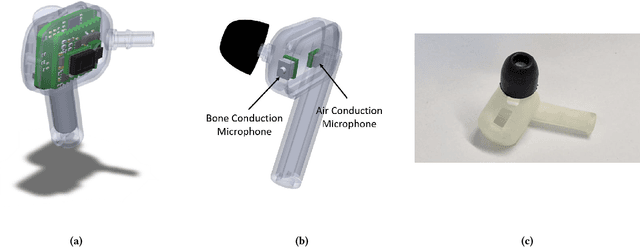
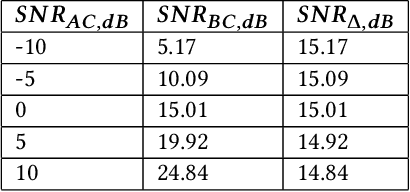
The recent ubiquitous adoption of remote conferencing has been accompanied by omnipresent frustration with distorted or otherwise unclear voice communication. Audio enhancement can compensate for low-quality input signals from, for example, small true wireless earbuds, by applying noise suppression techniques. Such processing relies on voice activity detection (VAD) with low latency and the added capability of discriminating the wearer's voice from others - a task of significant computational complexity. The tight energy budget of devices as small as modern earphones, however, requires any system attempting to tackle this problem to do so with minimal power and processing overhead, while not relying on speaker-specific voice samples and training due to usability concerns. This paper presents the design and implementation of a custom research platform for low-power wireless earbuds based on novel, commercial, MEMS bone-conduction microphones. Such microphones can record the wearer's speech with much greater isolation, enabling personalized voice activity detection and further audio enhancement applications. Furthermore, the paper accurately evaluates a proposed low-power personalized speech detection algorithm based on bone conduction data and a recurrent neural network running on the implemented research platform. This algorithm is compared to an approach based on traditional microphone input. The performance of the bone conduction system, achieving detection of speech within 12.8ms at an accuracy of 95\% is evaluated. Different SoC choices are contrasted, with the final implementation based on the cutting-edge Ambiq Apollo 4 Blue SoC achieving 2.64mW average power consumption at 14uJ per inference, reaching 43h of battery life on a miniature 32mAh li-ion cell and without duty cycling.
Enhancing Speech-to-Speech Translation with Multiple TTS Targets
Apr 10, 2023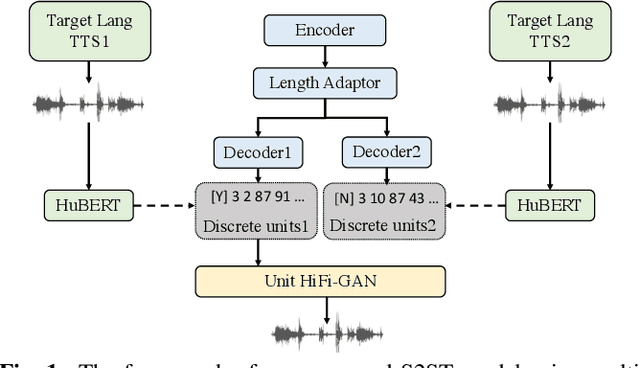
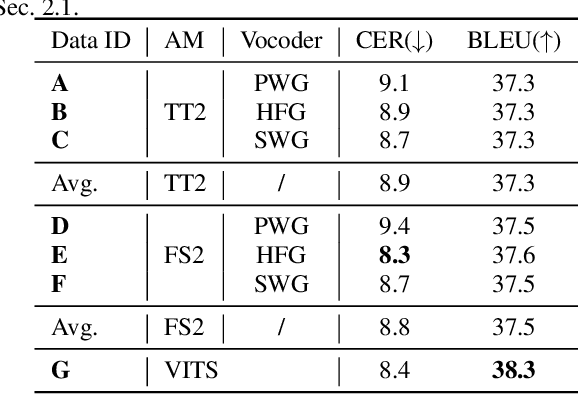
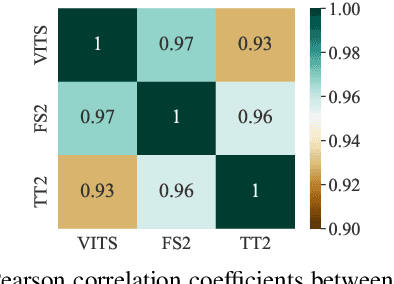
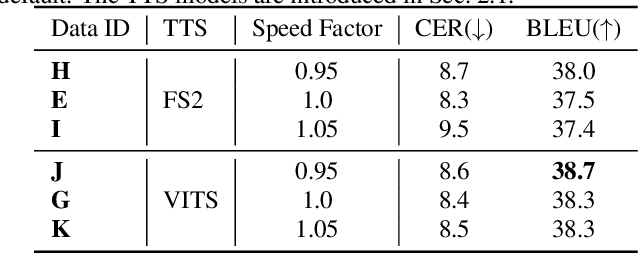
It has been known that direct speech-to-speech translation (S2ST) models usually suffer from the data scarcity issue because of the limited existing parallel materials for both source and target speech. Therefore to train a direct S2ST system, previous works usually utilize text-to-speech (TTS) systems to generate samples in the target language by augmenting the data from speech-to-text translation (S2TT). However, there is a limited investigation into how the synthesized target speech would affect the S2ST models. In this work, we analyze the effect of changing synthesized target speech for direct S2ST models. We find that simply combining the target speech from different TTS systems can potentially improve the S2ST performances. Following that, we also propose a multi-task framework that jointly optimizes the S2ST system with multiple targets from different TTS systems. Extensive experiments demonstrate that our proposed framework achieves consistent improvements (2.8 BLEU) over the baselines on the Fisher Spanish-English dataset.
LM-VC: Zero-shot Voice Conversion via Speech Generation based on Language Models
Jun 18, 2023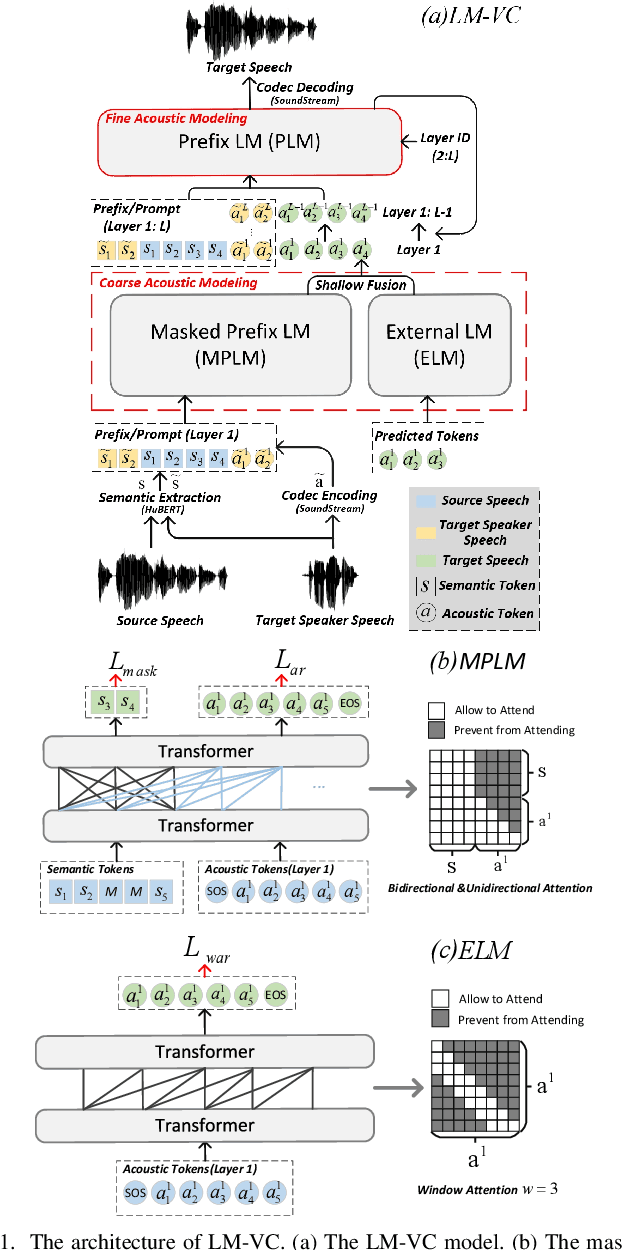
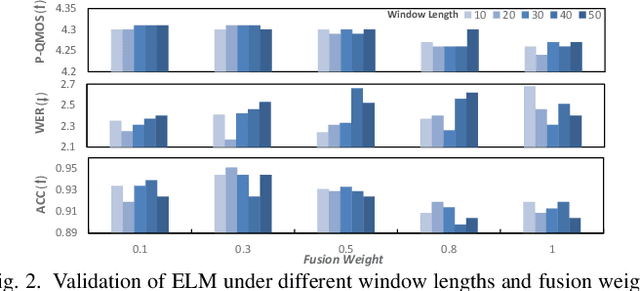
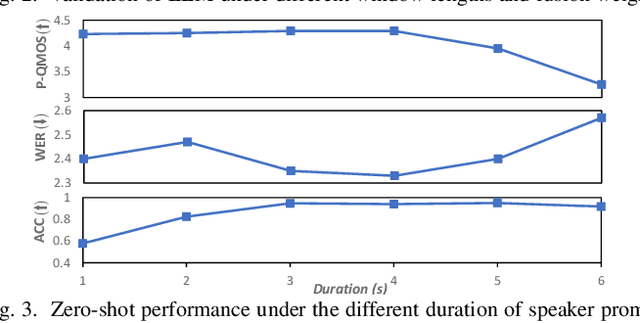
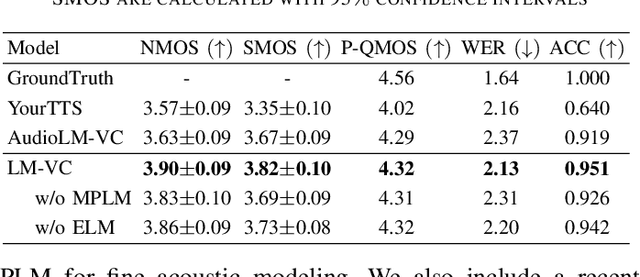
Language model (LM) based audio generation frameworks, e.g., AudioLM, have recently achieved new state-of-the-art performance in zero-shot audio generation. In this paper, we explore the feasibility of LMs for zero-shot voice conversion. An intuitive approach is to follow AudioLM - Tokenizing speech into semantic and acoustic tokens respectively by HuBERT and SoundStream, and converting source semantic tokens to target acoustic tokens conditioned on acoustic tokens of the target speaker. However, such an approach encounters several issues: 1) the linguistic content contained in semantic tokens may get dispersed during multi-layer modeling while the lengthy speech input in the voice conversion task makes contextual learning even harder; 2) the semantic tokens still contain speaker-related information, which may be leaked to the target speech, lowering the target speaker similarity; 3) the generation diversity in the sampling of the LM can lead to unexpected outcomes during inference, leading to unnatural pronunciation and speech quality degradation. To mitigate these problems, we propose LM-VC, a two-stage language modeling approach that generates coarse acoustic tokens for recovering the source linguistic content and target speaker's timbre, and then reconstructs the fine for acoustic details as converted speech. Specifically, to enhance content preservation and facilitates better disentanglement, a masked prefix LM with a mask prediction strategy is used for coarse acoustic modeling. This model is encouraged to recover the masked content from the surrounding context and generate target speech based on the target speaker's utterance and corrupted semantic tokens. Besides, to further alleviate the sampling error in the generation, an external LM, which employs window attention to capture the local acoustic relations, is introduced to participate in the coarse acoustic modeling.
Text-to-Speech Pipeline for Swiss German -- A comparison
May 31, 2023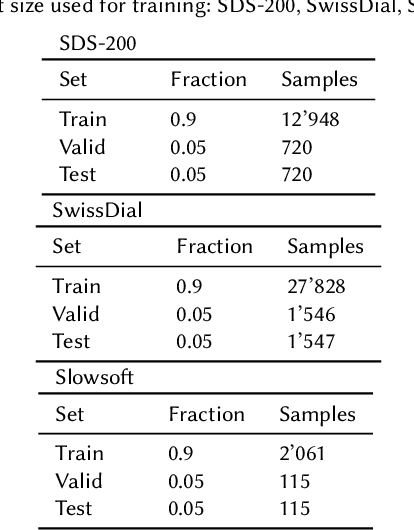
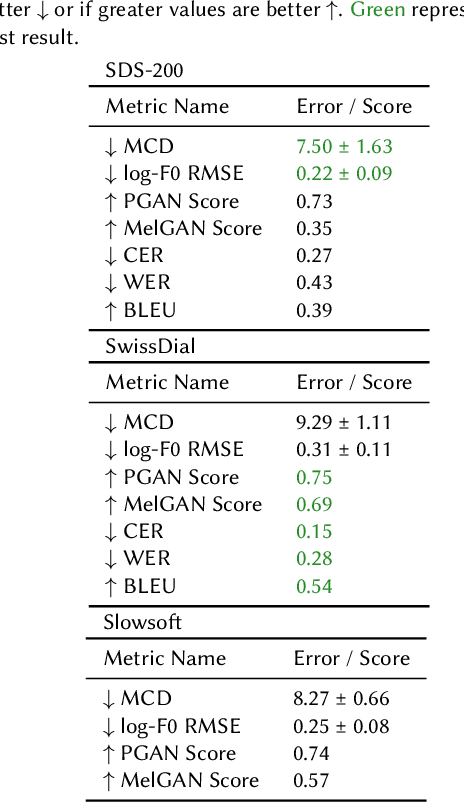
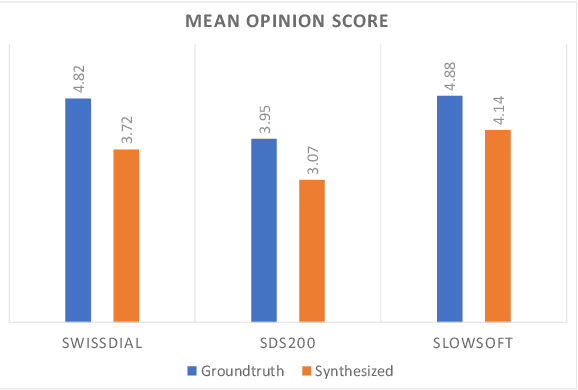
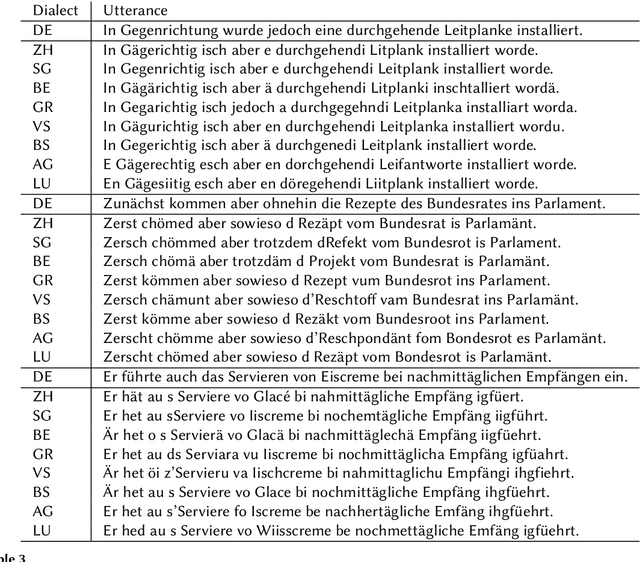
In this work, we studied the synthesis of Swiss German speech using different Text-to-Speech (TTS) models. We evaluated the TTS models on three corpora, and we found, that VITS models performed best, hence, using them for further testing. We also introduce a new method to evaluate TTS models by letting the discriminator of a trained vocoder GAN model predict whether a given waveform is human or synthesized. In summary, our best model delivers speech synthesis for different Swiss German dialects with previously unachieved quality.
Investigating End-to-End ASR Architectures for Long Form Audio Transcription
Sep 20, 2023
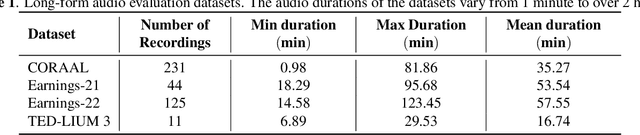


This paper presents an overview and evaluation of some of the end-to-end ASR models on long-form audios. We study three categories of Automatic Speech Recognition(ASR) models based on their core architecture: (1) convolutional, (2) convolutional with squeeze-and-excitation and (3) convolutional models with attention. We selected one ASR model from each category and evaluated Word Error Rate, maximum audio length and real-time factor for each model on a variety of long audio benchmarks: Earnings-21 and 22, CORAAL, and TED-LIUM3. The model from the category of self-attention with local attention and global token has the best accuracy comparing to other architectures. We also compared models with CTC and RNNT decoders and showed that CTC-based models are more robust and efficient than RNNT on long form audio.
NTT speaker diarization system for CHiME-7: multi-domain, multi-microphone End-to-end and vector clustering diarization
Sep 22, 2023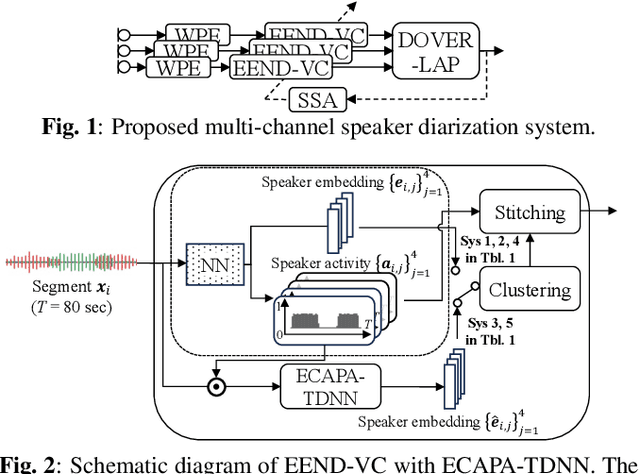
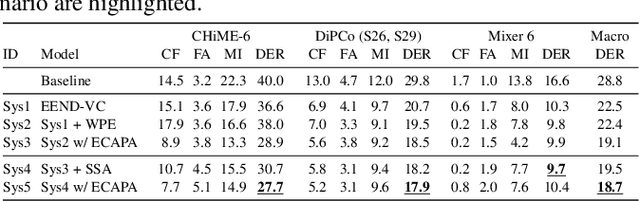
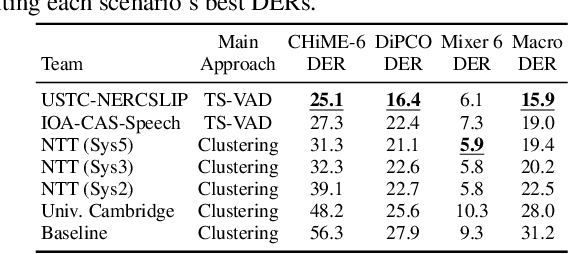
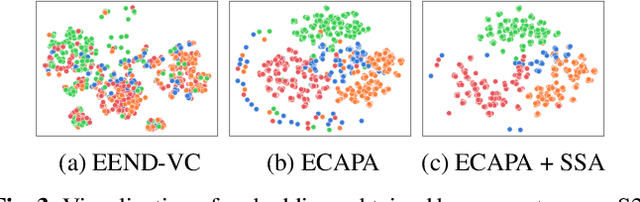
This paper details our speaker diarization system designed for multi-domain, multi-microphone casual conversations. The proposed diarization pipeline uses weighted prediction error (WPE)-based dereverberation as a front end, then applies end-to-end neural diarization with vector clustering (EEND-VC) to each channel separately. It integrates the diarization result obtained from each channel using diarization output voting error reduction plus overlap (DOVER-LAP). To harness the knowledge from the target domain and results integrated across all channels, we apply self-supervised adaptation for each session by retraining the EEND-VC with pseudo-labels derived from DOVER-LAP. The proposed system was incorporated into NTT's submission for the distant automatic speech recognition task in the CHiME-7 challenge. Our system achieved 65 % and 62 % relative improvements on development and eval sets compared to the organizer-provided VC-based baseline diarization system, securing third place in diarization performance.
Debiased Automatic Speech Recognition for Dysarthric Speech via Sample Reweighting with Sample Affinity Test
May 22, 2023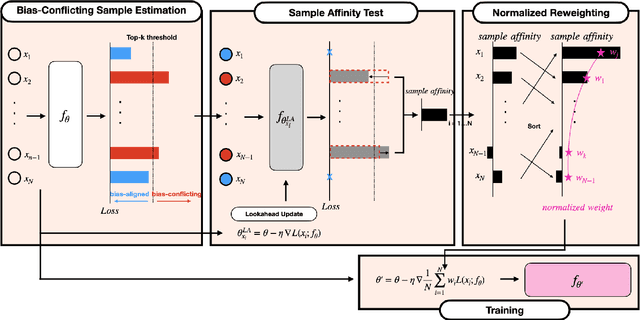
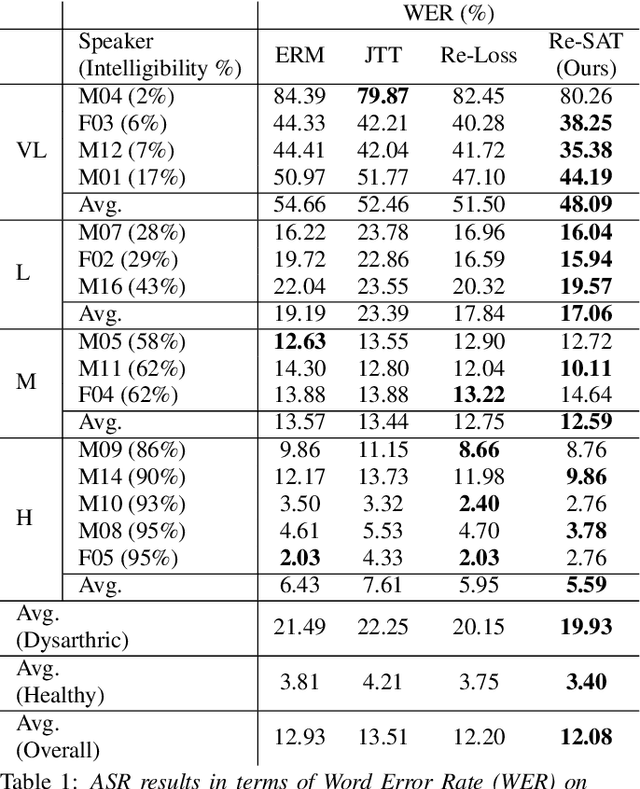
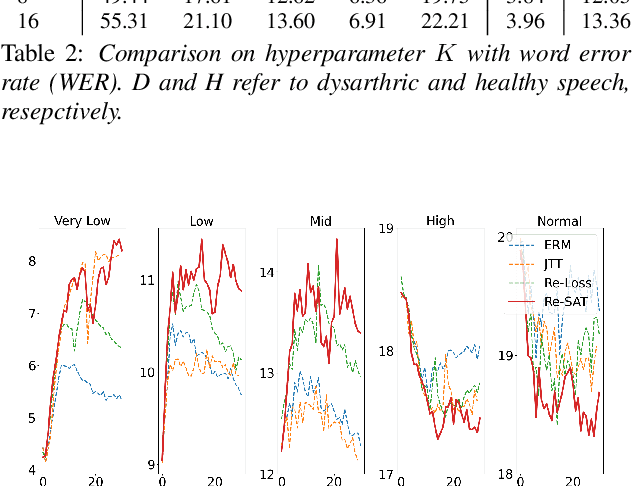
Automatic speech recognition systems based on deep learning are mainly trained under empirical risk minimization (ERM). Since ERM utilizes the averaged performance on the data samples regardless of a group such as healthy or dysarthric speakers, ASR systems are unaware of the performance disparities across the groups. This results in biased ASR systems whose performance differences among groups are severe. In this study, we aim to improve the ASR system in terms of group robustness for dysarthric speakers. To achieve our goal, we present a novel approach, sample reweighting with sample affinity test (Re-SAT). Re-SAT systematically measures the debiasing helpfulness of the given data sample and then mitigates the bias by debiasing helpfulness-based sample reweighting. Experimental results demonstrate that Re-SAT contributes to improved ASR performance on dysarthric speech without performance degradation on healthy speech.
Robust Self Supervised Speech Embeddings for Child-Adult Classification in Interactions involving Children with Autism
Jul 31, 2023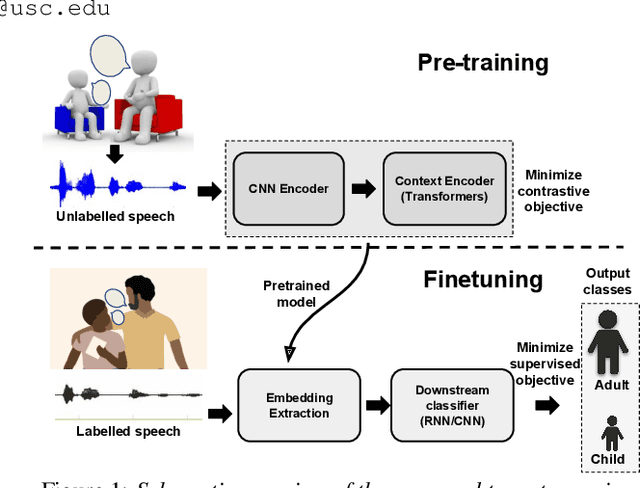

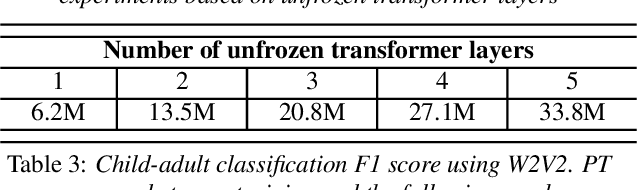
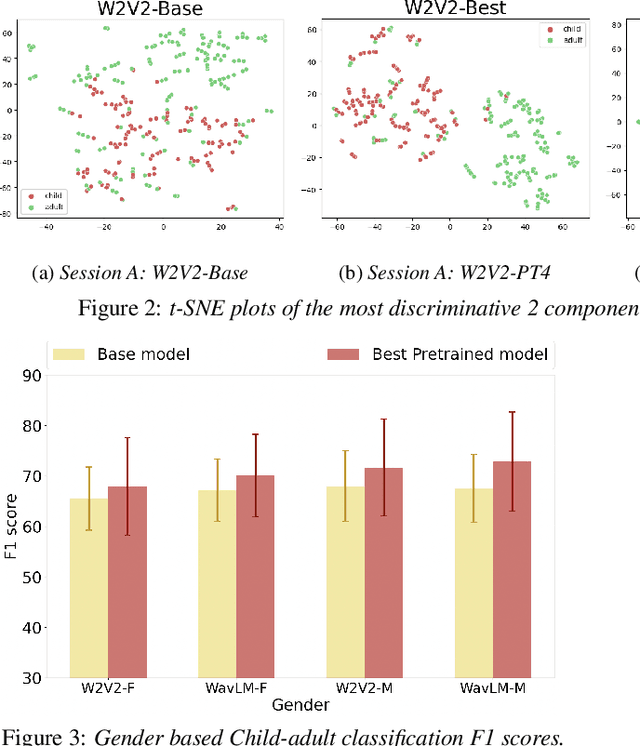
We address the problem of detecting who spoke when in child-inclusive spoken interactions i.e., automatic child-adult speaker classification. Interactions involving children are richly heterogeneous due to developmental differences. The presence of neurodiversity e.g., due to Autism, contributes additional variability. We investigate the impact of additional pre-training with more unlabelled child speech on the child-adult classification performance. We pre-train our model with child-inclusive interactions, following two recent self-supervision algorithms, Wav2vec 2.0 and WavLM, with a contrastive loss objective. We report 9 - 13% relative improvement over the state-of-the-art baseline with regards to classification F1 scores on two clinical interaction datasets involving children with Autism. We also analyze the impact of pre-training under different conditions by evaluating our model on interactions involving different subgroups of children based on various demographic factors.
Speech Translation with Foundation Models and Optimal Transport: UPC at IWSLT23
Jun 02, 2023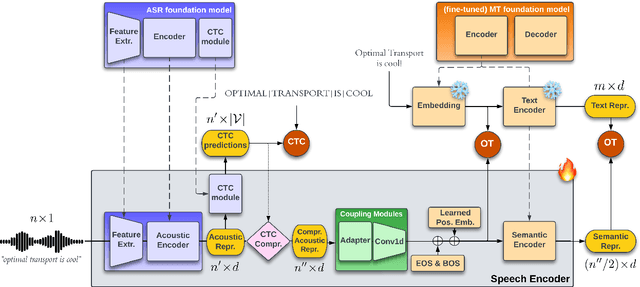
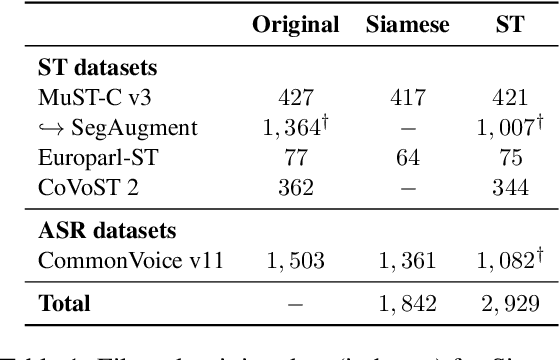
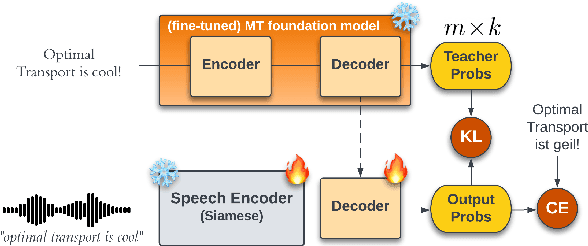
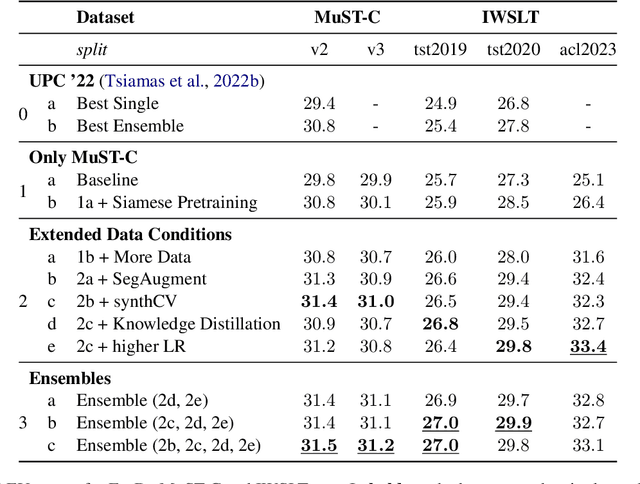
This paper describes the submission of the UPC Machine Translation group to the IWSLT 2023 Offline Speech Translation task. Our Speech Translation systems utilize foundation models for speech (wav2vec 2.0) and text (mBART50). We incorporate a Siamese pretraining step of the speech and text encoders with CTC and Optimal Transport, to adapt the speech representations to the space of the text model, thus maximizing transfer learning from MT. After this pretraining, we fine-tune our system end-to-end on ST, with Cross Entropy and Knowledge Distillation. Apart from the available ST corpora, we create synthetic data with SegAugment to better adapt our models to the custom segmentations of the IWSLT test sets. Our best single model obtains 31.2 BLEU points on MuST-C tst-COMMON, 29.8 points on IWLST.tst2020 and 33.4 points on the newly released IWSLT.ACLdev2023.