 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Bottleneck Fusion For Noise Robust Audio-Visual Speech Recognition
Feb 09, 2026Audio-Visual Speech Recognition (AVSR) leverages both acoustic and visual cues to improve speech recognition under noisy conditions. A central question is how to design a fusion mechanism that allows the model to effectively exploit visual information when the audio signal is degraded, while maintaining strong performance on clean speech. We propose CoBRA (Cross-modal Bottleneck for Robust AVSR), a bottleneck-based fusion framework that introduces a compact set of learnable tokens to mediate cross-modal exchange. By regulating information flow through these tokens, the audio stream can reliably access essential visual cues even under adverse or out-of-domain noise. Despite limited training data, our model surpasses comparable baselines and remains competitive with large-scale systems through noise-adaptive fusion, demonstrating both efficiency and robustness. Ablation studies highlight that the depth of fusion is the most critical factor, underscoring its importance in designing robust AVSR systems.
Guiding Frame-Level CTC Alignments Using Self-knowledge Distillation
Jun 12, 2024



Transformer encoder with connectionist temporal classification (CTC) framework is widely used for automatic speech recognition (ASR). However, knowledge distillation (KD) for ASR displays a problem of disagreement between teacher-student models in frame-level alignment which ultimately hinders it from improving the student model's performance. In order to resolve this problem, this paper introduces a self-knowledge distillation (SKD) method that guides the frame-level alignment during the training time. In contrast to the conventional method using separate teacher and student models, this study introduces a simple and effective method sharing encoder layers and applying the sub-model as the student model. Overall, our approach is effective in improving both the resource efficiency as well as performance. We also conducted an experimental analysis of the spike timings to illustrate that the proposed method improves performance by reducing the alignment disagreement.
Debiased Automatic Speech Recognition for Dysarthric Speech via Sample Reweighting with Sample Affinity Test
May 22, 2023


Automatic speech recognition systems based on deep learning are mainly trained under empirical risk minimization (ERM). Since ERM utilizes the averaged performance on the data samples regardless of a group such as healthy or dysarthric speakers, ASR systems are unaware of the performance disparities across the groups. This results in biased ASR systems whose performance differences among groups are severe. In this study, we aim to improve the ASR system in terms of group robustness for dysarthric speakers. To achieve our goal, we present a novel approach, sample reweighting with sample affinity test (Re-SAT). Re-SAT systematically measures the debiasing helpfulness of the given data sample and then mitigates the bias by debiasing helpfulness-based sample reweighting. Experimental results demonstrate that Re-SAT contributes to improved ASR performance on dysarthric speech without performance degradation on healthy speech.
Improving Audio-Language Learning with MixGen and Multi-Level Test-Time Augmentation
Oct 31, 2022



In this paper, we propose two novel augmentation methods 1) audio-language MixGen (AL-MixGen) and 2) multi-level test-time augmentation (Multi-TTA) for audio-language learning. Inspired by MixGen, which is originally applied to vision-language learning, we introduce an augmentation method for the audio-language domain. We also explore the impact of test-time augmentations and present Multi-TTA which generalizes test-time augmentation over multiple layers of a deep learning model. Incorporating AL-MixGen and Multi-TTA into the baseline achieves 47.5 SPIDEr on audio captioning, which is an +18.2% over the baseline and outperforms the state-of-the-art approach with a 5x smaller model. In audio-text retrieval, the proposed methods surpass the baseline performance as well.
Representation Selective Self-distillation and wav2vec 2.0 Feature Exploration for Spoof-aware Speaker Verification
Apr 06, 2022
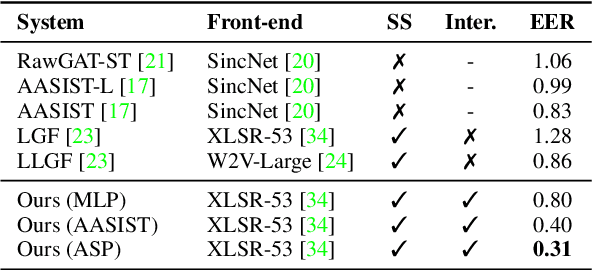
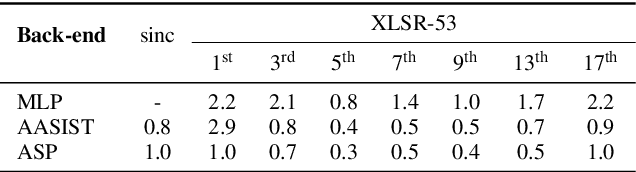
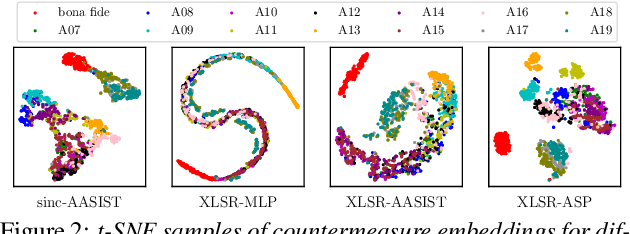
Text-to-speech and voice conversion studies are constantly improving to the extent where they can produce synthetic speech almost indistinguishable from bona fide human speech. In this regrad, the importance of countermeasures (CM) against synthetic voice attacks of the automatic speaker verification (ASV) systems emerges. Nonetheless, most end-to-end spoofing detection networks are black box systems, and the answer to what is an effective representation for finding artifacts still remains veiled. In this paper, we examine which feature space can effectively represent synthetic artifacts using wav2vec 2.0, and study which architecture can effectively utilize the space. Our study allows us to analyze which attribute of speech signals is advantageous for the CM systems. The proposed CM system achieved 0.31% equal error rate (EER) on ASVspoof 2019 LA evaluation set for the spoof detection task. We further propose a simple yet effective spoofing aware speaker verification (SASV) methodology, which takes advantage of the disentangled representations from our countermeasure system. Evaluation performed with the SASV Challenge 2022 database show 1.08% of SASV EER. Quantitative analysis shows that using the explored feature space of wav2vec 2.0 advantages both spoofing CM and SASV.