 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Say Goodbye to RNN-T Loss: A Novel CIF-based Transducer Architecture for Automatic Speech Recognition
Jul 27, 2023
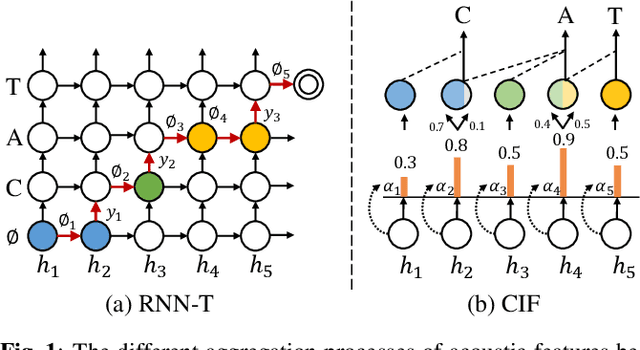

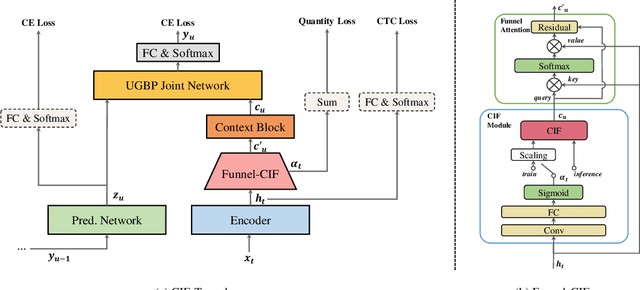
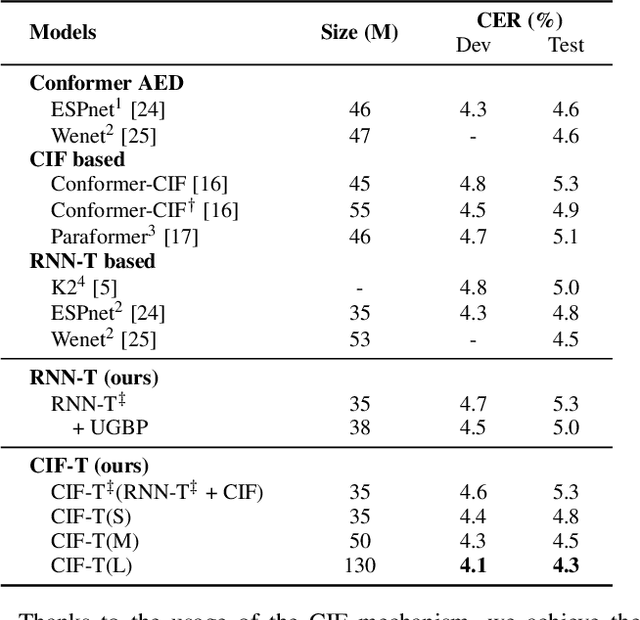
RNN-T models are widely used in ASR, which rely on the RNN-T loss to achieve length alignment between input audio and target sequence. However, the implementation complexity and the alignment-based optimization target of RNN-T loss lead to computational redundancy and a reduced role for predictor network, respectively. In this paper, we propose a novel model named CIF-Transducer (CIF-T) which incorporates the Continuous Integrate-and-Fire (CIF) mechanism with the RNN-T model to achieve efficient alignment. In this way, the RNN-T loss is abandoned, thus bringing a computational reduction and allowing the predictor network a more significant role. We also introduce Funnel-CIF, Context Blocks, Unified Gating and Bilinear Pooling joint network, and auxiliary training strategy to further improve performance. Experiments on the 178-hour AISHELL-1 and 10000-hour WenetSpeech datasets show that CIF-T achieves state-of-the-art results with lower computational overhead compared to RNN-T models.
Damage Control During Domain Adaptation for Transducer Based Automatic Speech Recognition
Oct 06, 2022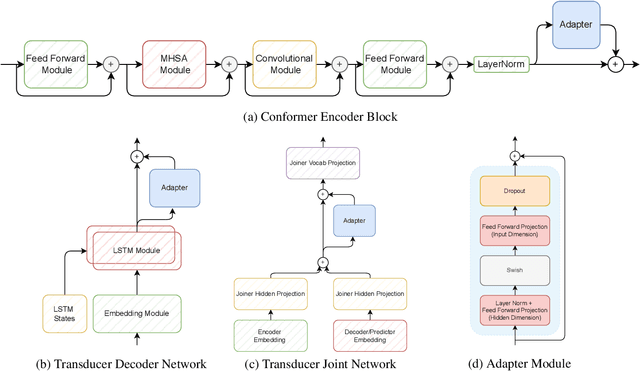
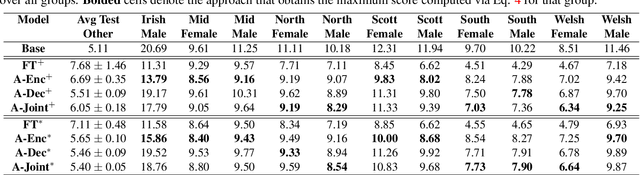
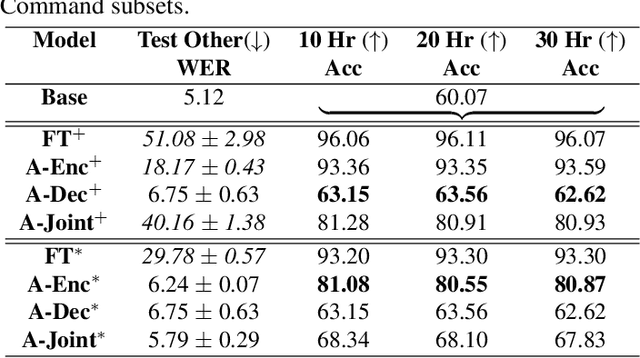
Automatic speech recognition models are often adapted to improve their accuracy in a new domain. A potential drawback of model adaptation to new domains is catastrophic forgetting, where the Word Error Rate on the original domain is significantly degraded. This paper addresses the situation when we want to simultaneously adapt automatic speech recognition models to a new domain and limit the degradation of accuracy on the original domain without access to the original training dataset. We propose several techniques such as a limited training strategy and regularized adapter modules for the Transducer encoder, prediction, and joiner network. We apply these methods to the Google Speech Commands and to the UK and Ireland English Dialect speech data set and obtain strong results on the new target domain while limiting the degradation on the original domain.
Watch or Listen: Robust Audio-Visual Speech Recognition with Visual Corruption Modeling and Reliability Scoring
Mar 20, 2023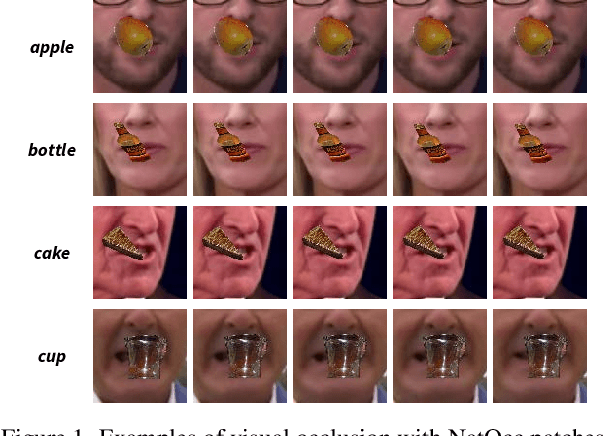
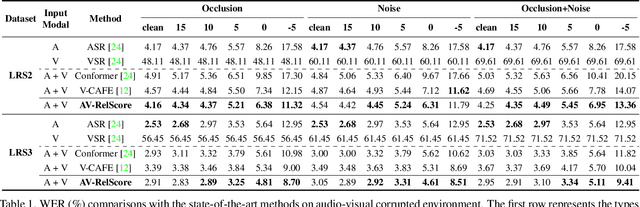


This paper deals with Audio-Visual Speech Recognition (AVSR) under multimodal input corruption situations where audio inputs and visual inputs are both corrupted, which is not well addressed in previous research directions. Previous studies have focused on how to complement the corrupted audio inputs with the clean visual inputs with the assumption of the availability of clean visual inputs. However, in real life, clean visual inputs are not always accessible and can even be corrupted by occluded lip regions or noises. Thus, we firstly analyze that the previous AVSR models are not indeed robust to the corruption of multimodal input streams, the audio and the visual inputs, compared to uni-modal models. Then, we design multimodal input corruption modeling to develop robust AVSR models. Lastly, we propose a novel AVSR framework, namely Audio-Visual Reliability Scoring module (AV-RelScore), that is robust to the corrupted multimodal inputs. The AV-RelScore can determine which input modal stream is reliable or not for the prediction and also can exploit the more reliable streams in prediction. The effectiveness of the proposed method is evaluated with comprehensive experiments on popular benchmark databases, LRS2 and LRS3. We also show that the reliability scores obtained by AV-RelScore well reflect the degree of corruption and make the proposed model focus on the reliable multimodal representations.
Automatic Speech Recognition of Non-Native Child Speech for Language Learning Applications
Jun 29, 2023
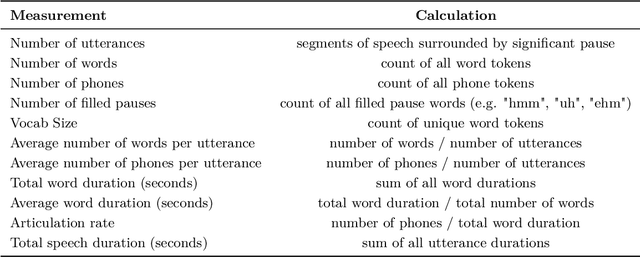
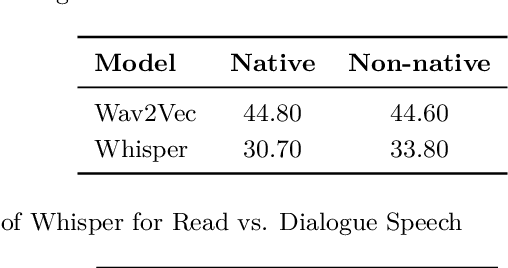
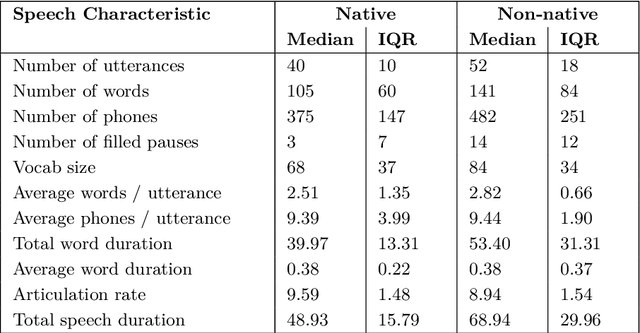
Voicebots have provided a new avenue for supporting the development of language skills, particularly within the context of second language learning. Voicebots, though, have largely been geared towards native adult speakers. We sought to assess the performance of two state-of-the-art ASR systems, Wav2Vec2.0 and Whisper AI, with a view to developing a voicebot that can support children acquiring a foreign language. We evaluated their performance on read and extemporaneous speech of native and non-native Dutch children. We also investigated the utility of using ASR technology to provide insight into the children's pronunciation and fluency. The results show that recent, pre-trained ASR transformer-based models achieve acceptable performance from which detailed feedback on phoneme pronunciation quality can be extracted, despite the challenging nature of child and non-native speech.
* Published on SLATE 2023, Esmad, Politecnico Do Porto, Portugal, 26-28 June, 2023, pp: 11:1-11:8
Towards Selection of Text-to-speech Data to Augment ASR Training
May 30, 2023
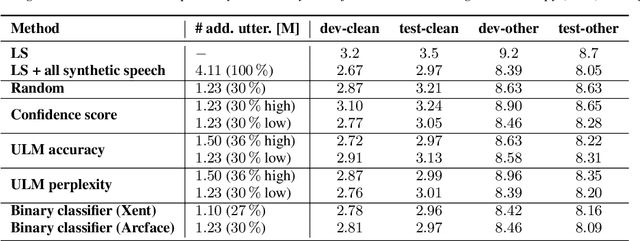
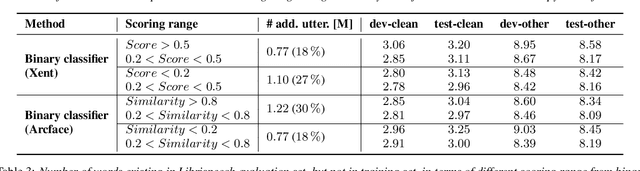

This paper presents a method for selecting appropriate synthetic speech samples from a given large text-to-speech (TTS) dataset as supplementary training data for an automatic speech recognition (ASR) model. We trained a neural network, which can be optimised using cross-entropy loss or Arcface loss, to measure the similarity of a synthetic data to real speech. We found that incorporating synthetic samples with considerable dissimilarity to real speech, owing in part to lexical differences, into ASR training is crucial for boosting recognition performance. Experimental results on Librispeech test sets indicate that, in order to maintain the same speech recognition accuracy as when using all TTS data, our proposed solution can reduce the size of the TTS data down below its $30\,\%$, which is superior to several baseline methods.
Long-term Conversation Analysis: Exploring Utility and Privacy
Jun 28, 2023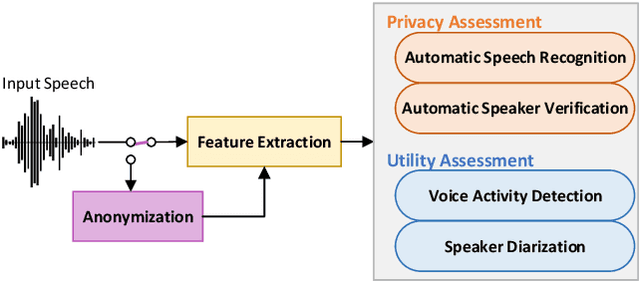
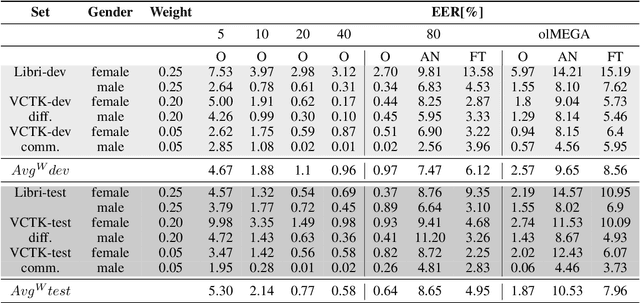
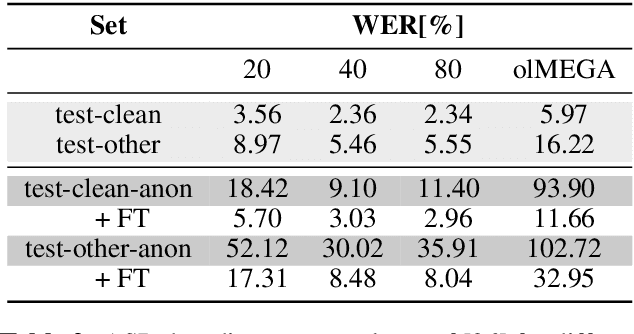
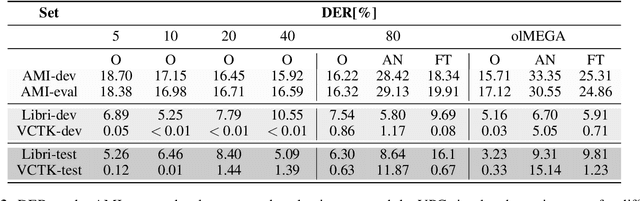
The analysis of conversations recorded in everyday life requires privacy protection. In this contribution, we explore a privacy-preserving feature extraction method based on input feature dimension reduction, spectral smoothing and the low-cost speaker anonymization technique based on McAdams coefficient. We assess the utility of the feature extraction methods with a voice activity detection and a speaker diarization system, while privacy protection is determined with a speech recognition and a speaker verification model. We show that the combination of McAdams coefficient and spectral smoothing maintains the utility while improving privacy.
Multi-blank Transducers for Speech Recognition
Nov 04, 2022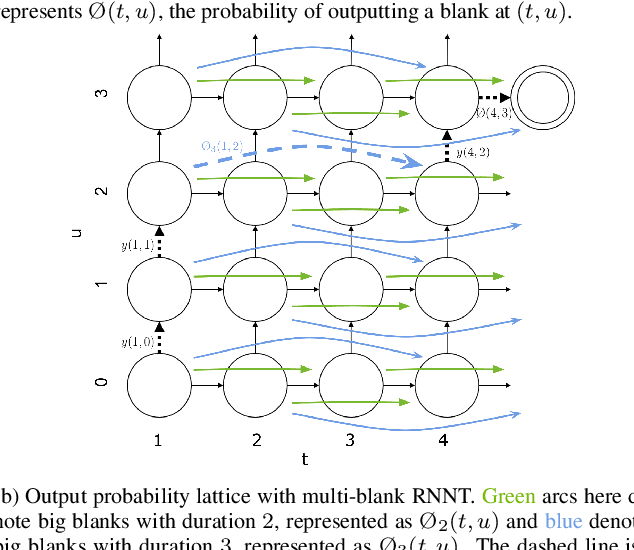
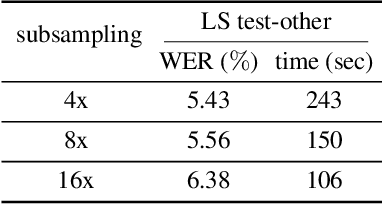
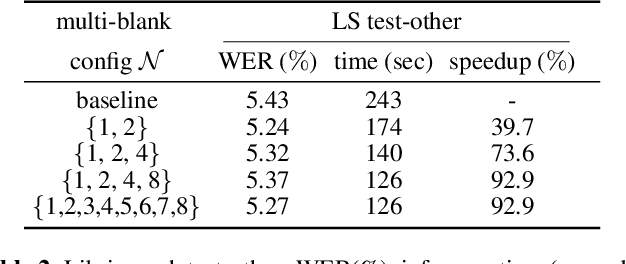
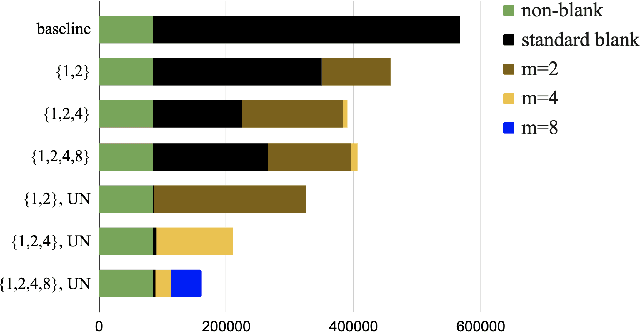
This paper proposes a modification to RNN-Transducer (RNN-T) models for automatic speech recognition (ASR). In standard RNN-T, the emission of a blank symbol consumes exactly one input frame; in our proposed method, we introduce additional blank symbols, which consume two or more input frames when emitted. We refer to the added symbols as big blanks, and the method multi-blank RNN-T. For training multi-blank RNN-Ts, we propose a novel logit under-normalization method in order to prioritize emissions of big blanks. With experiments on multiple languages and datasets, we show that multi-blank RNN-T methods could bring relative speedups of over +90%/+139% to model inference for English Librispeech and German Multilingual Librispeech datasets, respectively. The multi-blank RNN-T method also improves ASR accuracy consistently. We will release our implementation of the method in the NeMo (\url{https://github.com/NVIDIA/NeMo}) toolkit.
Token-Level Serialized Output Training for Joint Streaming ASR and ST Leveraging Textual Alignments
Jul 07, 2023

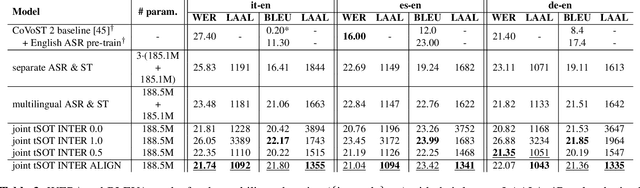
In real-world applications, users often require both translations and transcriptions of speech to enhance their comprehension, particularly in streaming scenarios where incremental generation is necessary. This paper introduces a streaming Transformer-Transducer that jointly generates automatic speech recognition (ASR) and speech translation (ST) outputs using a single decoder. To produce ASR and ST content effectively with minimal latency, we propose a joint token-level serialized output training method that interleaves source and target words by leveraging an off-the-shelf textual aligner. Experiments in monolingual (it-en) and multilingual (\{de,es,it\}-en) settings demonstrate that our approach achieves the best quality-latency balance. With an average ASR latency of 1s and ST latency of 1.3s, our model shows no degradation or even improves output quality compared to separate ASR and ST models, yielding an average improvement of 1.1 WER and 0.4 BLEU in the multilingual case.
Prompt Tuning of Deep Neural Networks for Speaker-adaptive Visual Speech Recognition
Feb 16, 2023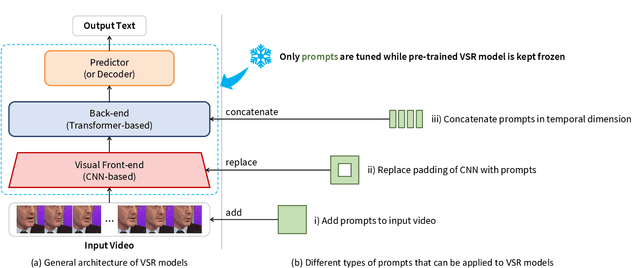
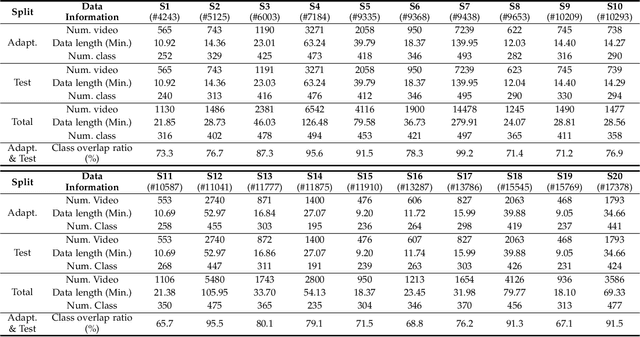
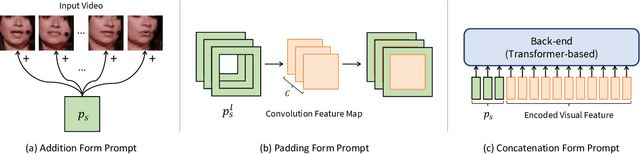
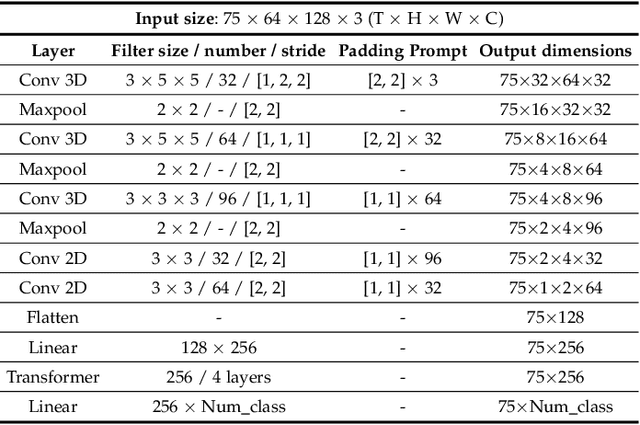
Visual Speech Recognition (VSR) aims to infer speech into text depending on lip movements alone. As it focuses on visual information to model the speech, its performance is inherently sensitive to personal lip appearances and movements, and this makes the VSR models show degraded performance when they are applied to unseen speakers. In this paper, to remedy the performance degradation of the VSR model on unseen speakers, we propose prompt tuning methods of Deep Neural Networks (DNNs) for speaker-adaptive VSR. Specifically, motivated by recent advances in Natural Language Processing (NLP), we finetune prompts on adaptation data of target speakers instead of modifying the pre-trained model parameters. Different from the previous prompt tuning methods mainly limited to Transformer variant architecture, we explore different types of prompts, the addition, the padding, and the concatenation form prompts that can be applied to the VSR model which is composed of CNN and Transformer in general. With the proposed prompt tuning, we show that the performance of the pre-trained VSR model on unseen speakers can be largely improved by using a small amount of adaptation data (e.g., less than 5 minutes), even if the pre-trained model is already developed with large speaker variations. Moreover, by analyzing the performance and parameters of different types of prompts, we investigate when the prompt tuning is preferred over the finetuning methods. The effectiveness of the proposed method is evaluated on both word- and sentence-level VSR databases, LRW-ID and GRID.
Towards End-to-end Unsupervised Speech Recognition
Apr 05, 2022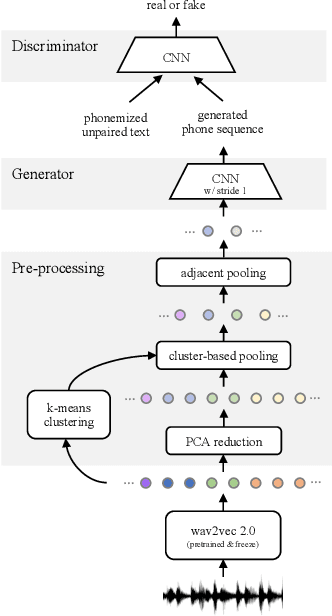

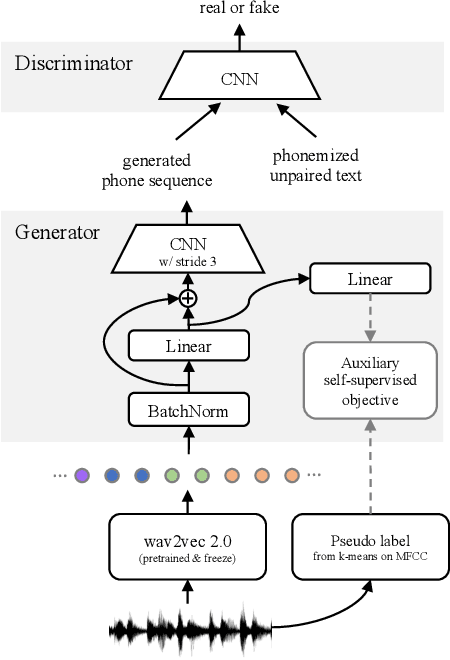
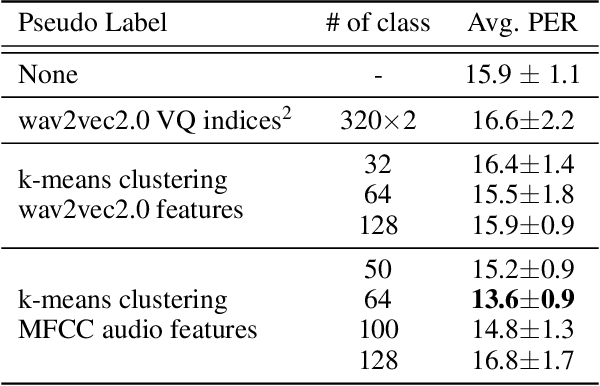
Unsupervised speech recognition has shown great potential to make Automatic Speech Recognition (ASR) systems accessible to every language. However, existing methods still heavily rely on hand-crafted pre-processing. Similar to the trend of making supervised speech recognition end-to-end, we introduce \wvu~which does away with all audio-side pre-processing and improves accuracy through better architecture. In addition, we introduce an auxiliary self-supervised objective that ties model predictions back to the input. Experiments show that \wvu~improves unsupervised recognition results across different languages while being conceptually simpler.