Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards End-to-end Unsupervised Speech Recognition
Paper and Code
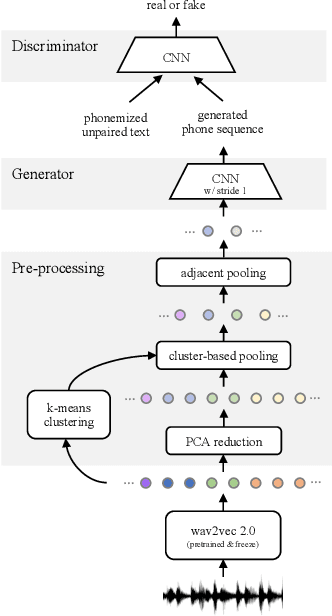

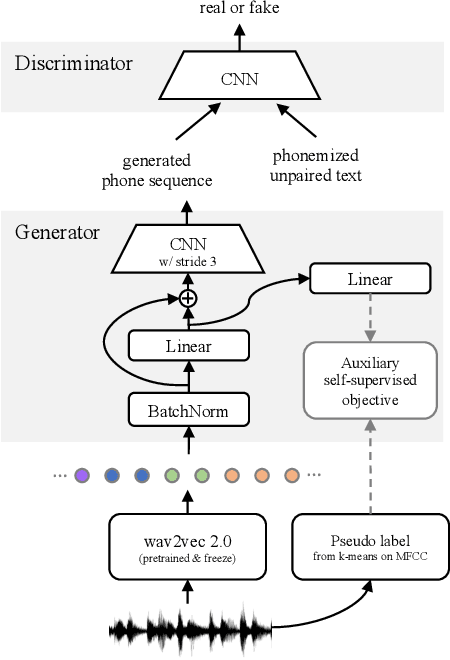
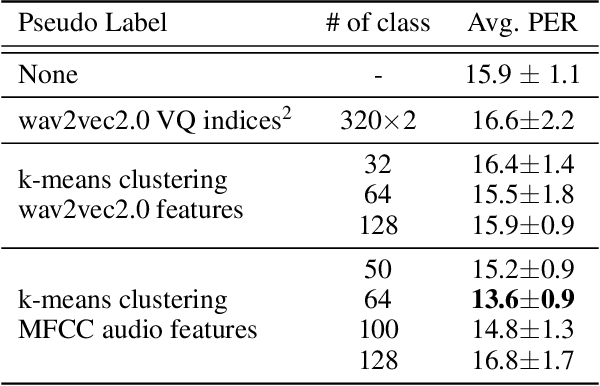
Unsupervised speech recognition has shown great potential to make Automatic Speech Recognition (ASR) systems accessible to every language. However, existing methods still heavily rely on hand-crafted pre-processing. Similar to the trend of making supervised speech recognition end-to-end, we introduce \wvu~which does away with all audio-side pre-processing and improves accuracy through better architecture. In addition, we introduce an auxiliary self-supervised objective that ties model predictions back to the input. Experiments show that \wvu~improves unsupervised recognition results across different languages while being conceptually simpler.
* Preprint
View paper on