 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHead-steered channel selection method for hearing aid applications using remote microphones
Aug 09, 2025We propose a channel selection method for hearing aid applications using remote microphones, in the presence of multiple competing talkers. The proposed channel selection method uses the hearing aid user's head-steering direction to identify the remote channel originating from the frontal direction of the hearing aid user, which captures the target talker signal. We pose the channel selection task as a multiple hypothesis testing problem, and derive a maximum likelihood solution. Under realistic, simplifying assumptions, the solution selects the remote channel which has the highest weighted squared absolute correlation coefficient with the output of the head-steered hearing aid beamformer. We analyze the performance of the proposed channel selection method using close-talking remote microphones and table microphone arrays. Through simulations using realistic acoustic scenes, we show that the proposed channel selection method consistently outperforms existing methods in accurately finding the remote channel that captures the target talker signal, in the presence of multiple competing talkers, without the use of any additional sensors.
Binaural Localization Model for Speech in Noise
Jul 26, 2025
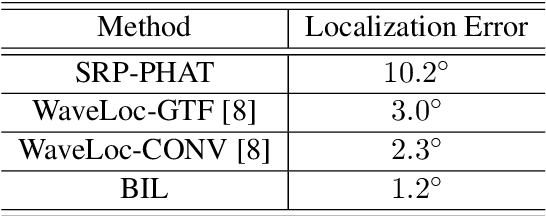
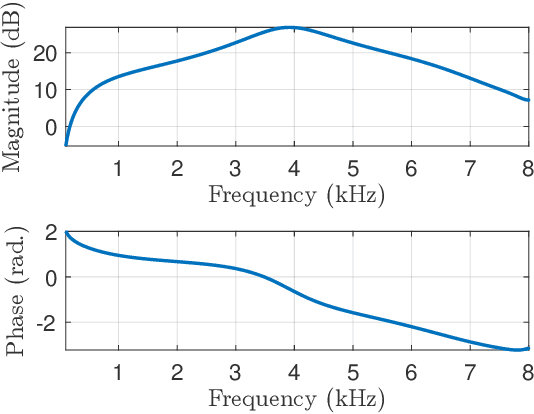

Binaural acoustic source localization is important to human listeners for spatial awareness, communication and safety. In this paper, an end-to-end binaural localization model for speech in noise is presented. A lightweight convolutional recurrent network that localizes sound in the frontal azimuthal plane for noisy reverberant binaural signals is introduced. The model incorporates additive internal ear noise to represent the frequency-dependent hearing threshold of a typical listener. The localization performance of the model is compared with the steered response power algorithm, and the use of the model as a measure of interaural cue preservation for binaural speech enhancement methods is studied. A listening test was performed to compare the performance of the model with human localization of speech in noisy conditions.
Zero Shot Text to Speech Augmentation for Automatic Speech Recognition on Low-Resource Accented Speech Corpora
Sep 17, 2024In recent years, automatic speech recognition (ASR) models greatly improved transcription performance both in clean, low noise, acoustic conditions and in reverberant environments. However, all these systems rely on the availability of hundreds of hours of labelled training data in specific acoustic conditions. When such a training dataset is not available, the performance of the system is heavily impacted. For example, this happens when a specific acoustic environment or a particular population of speakers is under-represented in the training dataset. Specifically, in this paper we investigate the effect of accented speech data on an off-the-shelf ASR system. Furthermore, we suggest a strategy based on zero-shot text-to-speech to augment the accented speech corpora. We show that this augmentation method is able to mitigate the loss in performance of the ASR system on accented data up to 5% word error rate reduction (WERR). In conclusion, we demonstrate that by incorporating a modest fraction of real with synthetically generated data, the ASR system exhibits superior performance compared to a model trained exclusively on authentic accented speech with up to 14% WERR.
XANE Background Acoustic Embeddings: Ablation and Clustering Analysis
Jul 08, 2024We explore the recently proposed explainable acoustic neural embedding~(XANE) system that models the background acoustics of a speech signal in a non-intrusive manner. The XANE embeddings are used to estimate specific parameters related to the background acoustic properties of the signal which allows the embeddings to be explainable in terms of those parameters. We perform ablation studies on the XANE system and show that estimating all acoustic parameters jointly has an overall positive effect. Furthermore, we illustrate the value of XANE embeddings by performing clustering experiments on unseen test data and show that the proposed embeddings achieve a mean F1 score of 92\% for three different tasks, outperforming significantly the WavLM based signal embeddings and are complimentary to speaker embeddings.
XANE: eXplainable Acoustic Neural Embeddings
Jun 07, 2024We present a novel method for extracting neural embeddings that model the background acoustics of a speech signal. The extracted embeddings are used to estimate specific parameters related to the background acoustic properties of the signal in a non-intrusive manner, which allows the embeddings to be explainable in terms of those parameters. We illustrate the value of these embeddings by performing clustering experiments on unseen test data and show that the proposed embeddings achieve a mean F1 score of 95.2\% for three different tasks, outperforming significantly the WavLM based signal embeddings. We also show that the proposed method can explain the embeddings by estimating 14 acoustic parameters characterizing the background acoustics, including reverberation and noise levels, overlapped speech detection, CODEC type detection and noise type detection with high accuracy and a real-time factor 17 times lower than an external baseline method.
Steered Response Power for Sound Source Localization: A Tutorial Review
May 05, 2024In the last three decades, the Steered Response Power (SRP) method has been widely used for the task of Sound Source Localization (SSL), due to its satisfactory localization performance on moderately reverberant and noisy scenarios. Many works have analyzed and extended the original SRP method to reduce its computational cost, to allow it to locate multiple sources, or to improve its performance in adverse environments. In this work, we review over 200 papers on the SRP method and its variants, with emphasis on the SRP-PHAT method. We also present eXtensible-SRP, or X-SRP, a generalized and modularized version of the SRP algorithm which allows the reviewed extensions to be implemented. We provide a Python implementation of the algorithm which includes selected extensions from the literature.
The Neural-SRP method for positional sound source localization
Mar 14, 2024



Steered Response Power (SRP) is a widely used method for the task of sound source localization using microphone arrays, showing satisfactory localization performance on many practical scenarios. However, its performance is diminished under highly reverberant environments. Although Deep Neural Networks (DNNs) have been previously proposed to overcome this limitation, most are trained for a specific number of microphones with fixed spatial coordinates. This restricts their practical application on scenarios frequently observed in wireless acoustic sensor networks, where each application has an ad-hoc microphone topology. We propose Neural-SRP, a DNN which combines the flexibility of SRP with the performance gains of DNNs. We train our network using simulated data and transfer learning, and evaluate our approach on recorded and simulated data. Results verify that Neural-SRP's localization performance significantly outperforms the baselines.
Binaural Speech Enhancement Using Deep Complex Convolutional Transformer Networks
Mar 08, 2024



Studies have shown that in noisy acoustic environments, providing binaural signals to the user of an assistive listening device may improve speech intelligibility and spatial awareness. This paper presents a binaural speech enhancement method using a complex convolutional neural network with an encoder-decoder architecture and a complex multi-head attention transformer. The model is trained to estimate individual complex ratio masks in the time-frequency domain for the left and right-ear channels of binaural hearing devices. The model is trained using a novel loss function that incorporates the preservation of spatial information along with speech intelligibility improvement and noise reduction. Simulation results for acoustic scenarios with a single target speaker and isotropic noise of various types show that the proposed method improves the estimated binaural speech intelligibility and preserves the binaural cues better in comparison with several baseline algorithms.
Uncertainty Quantification in Machine Learning for Joint Speaker Diarization and Identification
Dec 30, 2023



This paper studies modulation spectrum features ($\Phi$) and mel-frequency cepstral coefficients ($\Psi$) in joint speaker diarization and identification (JSID). JSID is important as speaker diarization on its own to distinguish speakers is insufficient for many applications, it is often necessary to identify speakers as well. Machine learning models are set up using convolutional neural networks (CNNs) on $\Phi$ and recurrent neural networks $\unicode{x2013}$ long short-term memory (LSTMs) on $\Psi$, then concatenating into fully connected layers. Experiment 1 shows models on both $\Phi$ and $\Psi$ have better diarization error rates (DERs) than models on either alone; a CNN on $\Phi$ has DER 29.09\%, compared to 27.78\% for a LSTM on $\Psi$ and 19.44\% for a model on both. Experiment 1 also investigates aleatoric uncertainties and shows the model on both $\Phi$ and $\Psi$ has mean entropy 0.927~bits (out of 4~bits) for correct predictions compared to 1.896~bits for incorrect predictions which, along with entropy histogram shapes, shows the model helpfully indicates where it is uncertain. Experiment 2 investigates epistemic uncertainties as well as aleatoric using Monte Carlo dropout (MCD). It compares models on both $\Phi$ and $\Psi$ with models trained on x-vectors ($X$), before applying Kalman filter smoothing on epistemic uncertainties for resegmentation and model ensembles. While the two models on $X$ (DERs 10.23\% and 9.74\%) outperform those on $\Phi$ and $\Psi$ (DER 17.85\%) after their individual Kalman filter smoothing, combining them using a Kalman filter smoothing method improves the DER to 9.29\%. Aleatoric uncertainties are higher for incorrect predictions. Both Experiments show models on $\Phi$ do not distinguish overlapping speakers as well as anticipated. However, Experiment 2 shows model ensembles do better with overlapping speakers than individual models do.
Subspace Hybrid MVDR Beamforming for Augmented Hearing
Nov 30, 2023



Signal-dependent beamformers are advantageous over signal-independent beamformers when the acoustic scenario - be it real-world or simulated - is straightforward in terms of the number of sound sources, the ambient sound field and their dynamics. However, in the context of augmented reality audio using head-worn microphone arrays, the acoustic scenarios encountered are often far from straightforward. The design of robust, high-performance, adaptive beamformers for such scenarios is an on-going challenge. This is due to the violation of the typically required assumptions on the noise field caused by, for example, rapid variations resulting from complex acoustic environments, and/or rotations of the listener's head. This work proposes a multi-channel speech enhancement algorithm which utilises the adaptability of signal-dependent beamformers while still benefiting from the computational efficiency and robust performance of signal-independent super-directive beamformers. The algorithm has two stages. (i) The first stage is a hybrid beamformer based on a dictionary of weights corresponding to a set of noise field models. (ii) The second stage is a wide-band subspace post-filter to remove any artifacts resulting from (i). The algorithm is evaluated using both real-world recordings and simulations of a cocktail-party scenario. Noise suppression, intelligibility and speech quality results show a significant performance improvement by the proposed algorithm compared to the baseline super-directive beamformer. A data-driven implementation of the noise field dictionary is shown to provide more noise suppression, and similar speech intelligibility and quality, compared to a parametric dictionary.